目录
Dubbo SPI使用
SPI简介
SPI源码分析
配置文件
源码解析
getExtensionLoader
getExtensionClasses
自适应扩展
文件命名及配置
接口定义
测试类
源码分析
Dubbo SPI使用
SPI简介
SPI 全称为 Service Provider Interface,是一种服务发现机制,刚好与java jdk的类加载机制进行了一个互补。SPI 的本质是将接口实现类的全限定名配置在文件中,并由服务加载器读取配置文件,加载实现类。这样可以在运行时,动态为接口替换实现类。正因此特性,我们可以很容易的通过 SPI 机制为我们的程序提供拓展功能。SPI 机制在第三方框架中也有所应用,比如 Dubbo 就是通过 SPI 机制加载所有的组件。不过,Dubbo 并未使用 Java 原生的 SPI 机制,而是对其进行了增强,使其能够更好的满足需求。在 Dubbo 中,SPI 是一个非常重要的模块。基于 SPI,我们可以很容易的对 Dubbo 进行拓展。如果大家想要学习 Dubbo 的源码,SPI 机制务必弄懂。接下来,我们先来了解一下 Java SPI 与 Dubbo SPI 的用法,然后再来分析 Dubbo SPI 的源码。
Dubbo 并未使用 Java SPI,而是重新实现了一套功能更强的 SPI 机制。Dubbo SPI 的相关逻辑被封装在了 ExtensionLoader 类中,通过 ExtensionLoader,我们可以加载指定的实现类。
SPI源码分析
配置文件
Dubbo SPI所需的配置文件需要放在META-INF/dubbo路径下,与java SPI类似,dubbo SPI的文件名称也是取的是接口的全路径:com.yangfan.spi.dubbo.api.Robot;
optimusPrime = com.yangfan.spi.dubbo.impl.OptimusPrime
bumblebee = com.yangfan.spi.dubbo.impl.Bumblebee
com.yangfan.spi.dubbo.impl.RobotWrapper与java SPI所不同的是它需要通过键值得方式进行配置,这样我们可以按需加载指定的实现类,具体实现是通过流的方式一行行读取然后根据“=”将具体的实现类信息缓存起来,详情见下面的loadResource及loadClass
流程分析
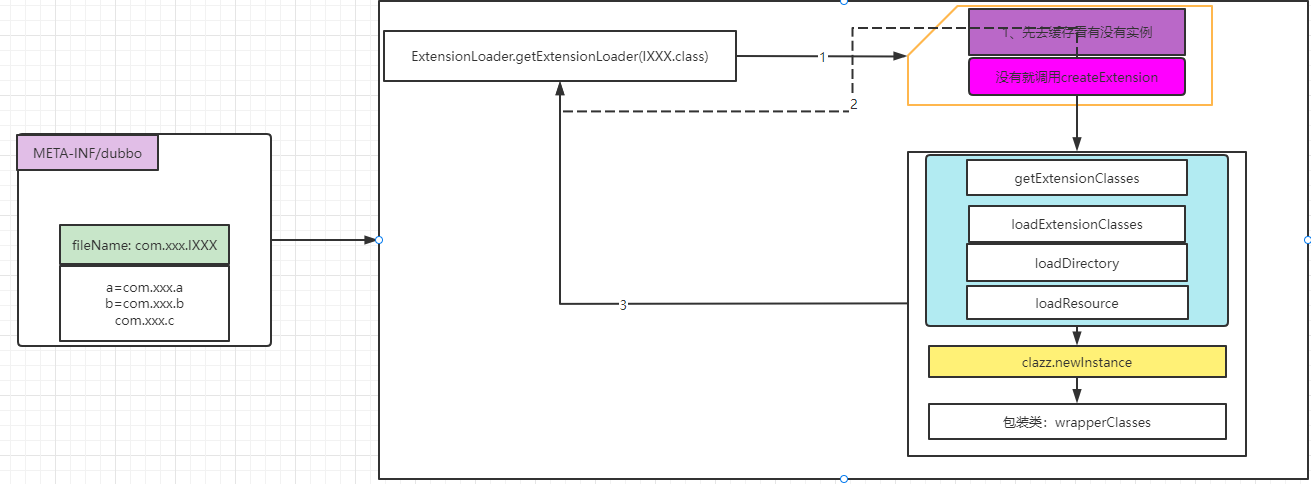
源码解析
private void loadResource(Map<String, Class<?>> extensionClasses, ClassLoader classLoader, java.net.URL resourceURL) {
try {
try (BufferedReader reader = new BufferedReader(new InputStreamReader(resourceURL.openStream(), StandardCharsets.UTF_8))) {
String line;
while ((line = reader.readLine()) != null) {
final int ci = line.indexOf('#');
if (ci >= 0) {
line = line.substring(0, ci);
}
line = line.trim();
if (line.length() > 0) {
try {
String name = null;
int i = line.indexOf('=');
if (i > 0) {
name = line.substring(0, i).trim();
line = line.substring(i + 1).trim();
}
if (line.length() > 0) {
loadClass(extensionClasses, resourceURL, Class.forName(line, true, classLoader), name);
}
} catch (Throwable t) {
IllegalStateException e = new IllegalStateException("Failed to load extension class (interface: " + type + ", class line: " + line + ") in " + resourceURL + ", cause: " + t.getMessage(), t);
exceptions.put(line, e);
}
}
}
}
} catch (Throwable t) {
logger.error("Exception occurred when loading extension class (interface: " +
type + ", class file: " + resourceURL + ") in " + resourceURL, t);
}private void loadClass(Map<String, Class<?>> extensionClasses, java.net.URL resourceURL, Class<?> clazz, String name) throws NoSuchMethodException {
if (!type.isAssignableFrom(clazz)) {
throw new IllegalStateException("Error occurred when loading extension class (interface: " +
type + ", class line: " + clazz.getName() + "), class "
+ clazz.getName() + " is not subtype of interface.");
}
if (clazz.isAnnotationPresent(Adaptive.class)) {
cacheAdaptiveClass(clazz);
} else if (isWrapperClass(clazz)) {
cacheWrapperClass(clazz);
} else {
clazz.getConstructor();
if (StringUtils.isEmpty(name)) {
name = findAnnotationName(clazz);
if (name.length() == 0) {
throw new IllegalStateException("No such extension name for the class " + clazz.getName() + " in the config " + resourceURL);
}
}
String[] names = NAME_SEPARATOR.split(name);
if (ArrayUtils.isNotEmpty(names)) {
cacheActivateClass(clazz, names[0]);
for (String n : names) {
cacheName(clazz, n);
saveInExtensionClass(extensionClasses, clazz, n);
}
}
}
}
由源码可知,loadClass之前已经加载了类,loadClass只是根据类上面的情况做不同的缓存。缓存的情况又分为Adaptive、WrapperClass和普通类,普通类也将Activate记录一下,
在测试类中我们可以通过配置文件配置的键值的键来加载指定的实现类,具体的操作代码如下,
@Test
public void testDubboSPI() {
ExtensionLoader<Robot> extensionLoader = ExtensionLoader.getExtensionLoader(Robot.class);
Robot optimusPrime = extensionLoader.getExtension("optimusPrime");
optimusPrime.sayHello();
Robot bumblebee = extensionLoader.getExtension("bumblebee");
bumblebee.sayHello();
}运行结果如下:
Hello,I am OptimusPrime
Hello,I am BumblebeegetExtensionLoader
上面简单演示了 Dubbo SPI 的使用方法。我们首先通过 ExtensionLoader 的 getExtensionLoader 方法获取一个 ExtensionLoader 实例,然后再通过 ExtensionLoader 的 getExtension 方法获取拓展类对象。这其中,getExtensionLoader 方法用于从缓存中获取与拓展类对应的 ExtensionLoader,若缓存未命中,则创建一个新的实例。该方法的逻辑比较简单,本章就不进行分析了。下面我们从 ExtensionLoader 的 getExtension 方法作为入口,对拓展类对象的获取过程进行详细的分析。
public T getExtension(String name) {
if (StringUtils.isEmpty(name)) {
throw new IllegalArgumentException("Extension name == null");
}
//获取more的扩展实现类
if ("true".equals(name)) {
return getDefaultExtension();
}
final Holder<Object> holder = getOrCreateHolder(name);
Object instance = holder.get();
//单例模式的实现:双锁检查模式
if (instance == null) {
synchronized (holder) {
instance = holder.get();
if (instance == null) {
//创建扩展实例
instance = createExtension(name);
holder.set(instance);
}
}
}
return (T) instance;
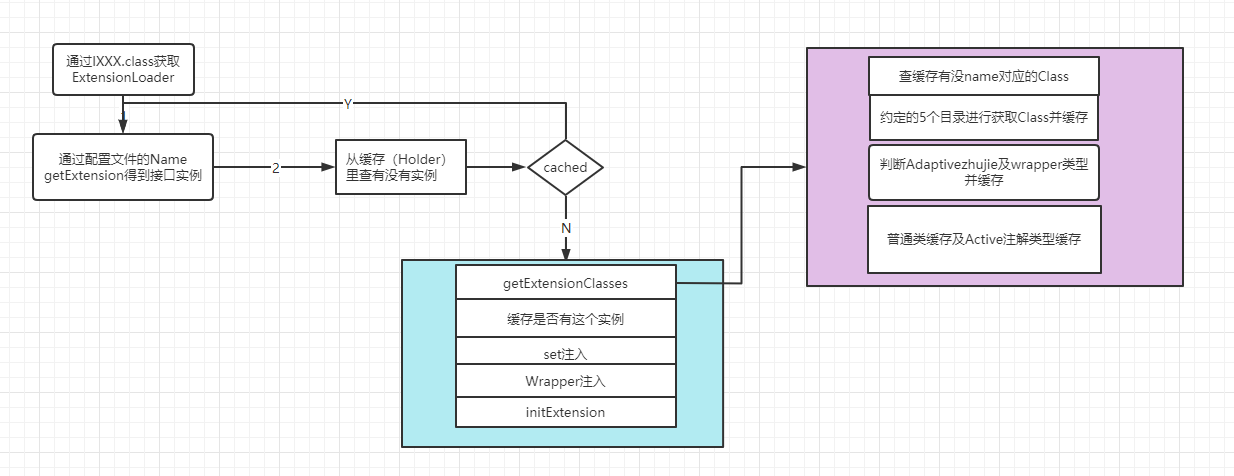
}上面的代码首先是检查缓存,如果缓存未命中,则创建扩展对象,下面分析一下扩展对象的创建过程
private T createExtension(String name) {
//从配置文件中夹在所有的扩展类,得到接口及实现类的键值,下面会着重分析这行代码
Class<?> clazz = getExtensionClasses().get(name);
if (clazz == null) {
throw findException(name);
}
try {
T instance = (T) EXTENSION_INSTANCES.get(clazz);
if (instance == null) {
//通过反射创建实例,并放入缓存
EXTENSION_INSTANCES.putIfAbsent(clazz, clazz.newInstance());
instance = (T) EXTENSION_INSTANCES.get(clazz);
}
//向实例中注入依赖
injectExtension(instance);
//判断是否有包装类
Set<Class<?>> wrapperClasses = cachedWrapperClasses;
if (CollectionUtils.isNotEmpty(wrapperClasses)) {
//循环创建包装类
for (Class<?> wrapperClass : wrapperClasses) {
// 将当前 instance 作为参数传给 Wrapper 的构造方法,并通过反射创建 Wrapper 实例。
// 然后向 Wrapper 实例中注入依赖,最后将 Wrapper 实例再次赋值给 instance 变量
instance = injectExtension((T) wrapperClass.getConstructor(type).newInstance(instance));
}
}
initExtension(instance);
return instance;
} catch (Throwable t) {
throw new IllegalStateException("Extension instance (name: " + name + ", class: " +
type + ") couldn't be instantiated: " + t.getMessage(), t);
}
}核心流程如下图,我习惯把总结为“委托模式aop”,因为实际方法调用仍然是调用作为属性传给包装类的具体的接口实现类。这也是Dubbo IOC与AOP的具体实现
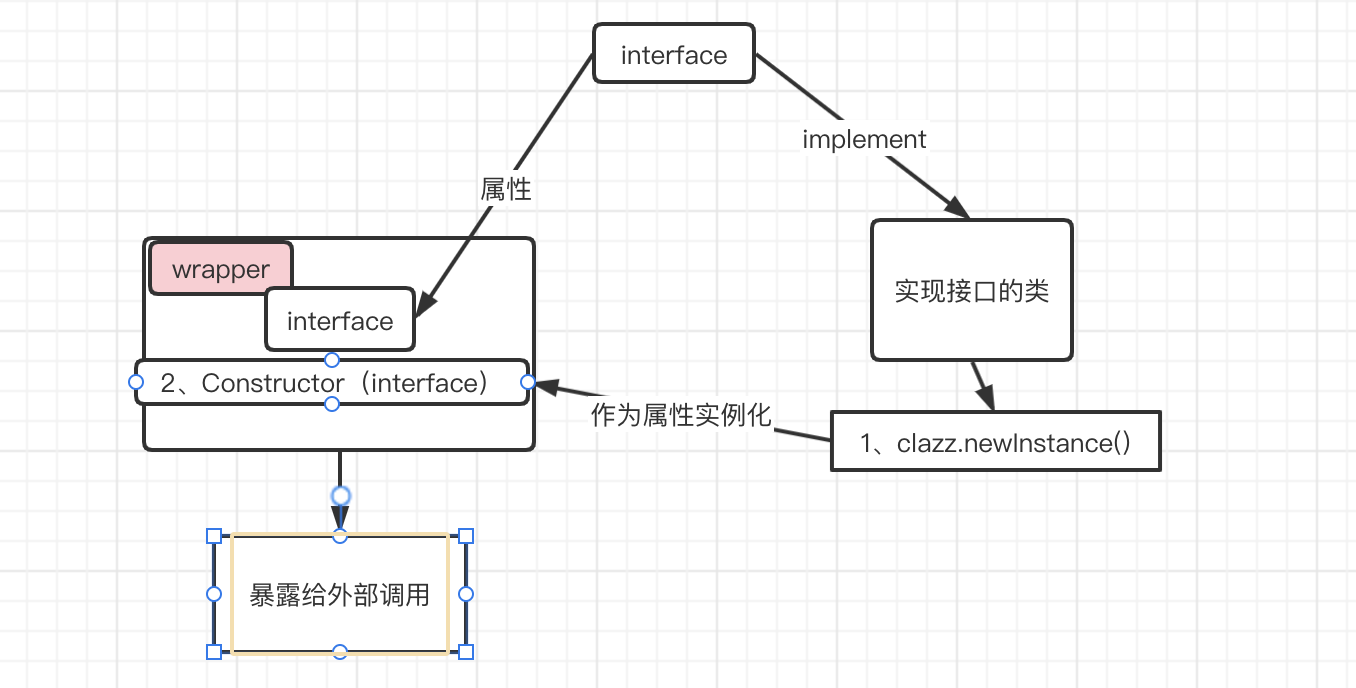
总结一下,createExtension主要做了四件事情:
- 通过 getExtensionClasses 获取所有的拓展类
- 通过反射创建拓展对象
- 向拓展对象中注入依赖
- 将拓展对象包裹在相应的 Wrapper 对象中
getExtensionClasses
首先需要根据配置文件解析出拓展项名称到拓展类的映射关系,数据存储方式为:Map<名称,拓展类>,后续都是通过拓展类的名称获取到相应的拓展类,源码如下:
private Map<String, Class<?>> getExtensionClasses() {
//先判断缓存中是否存在
Map<String, Class<?>> classes = cachedClasses.get();
//双重检查模式
if (classes == null) {
synchronized (cachedClasses) {
classes = cachedClasses.get();
if (classes == null) {
classes = loadExtensionClasses();
//加载拓展类
cachedClasses.set(classes);
}
}
}
return classes;
}这里也是先检查缓存,若缓存未命中,则通过 synchronized 加锁。加锁后再次检查缓存,并判空。此时如果 classes 仍为 null,则通过 loadExtensionClasses 加载拓展类。下面分析 loadExtensionClasses 方法的逻辑。
private Map<String, Class<?>> loadExtensionClasses() {
//默认的拓展类名,主要是通过SPI注解的方式,详情自己研究下
cacheDefaultExtensionName();
Map<String, Class<?>> extensionClasses = new HashMap<>();
// internal extension load from ExtensionLoader's ClassLoader first
//加载指定文件夹下的配置文件
loadDirectory(extensionClasses, DUBBO_INTERNAL_DIRECTORY, type.getName(), true);
loadDirectory(extensionClasses, DUBBO_INTERNAL_DIRECTORY, type.getName().replace("org.apache", "com.alibaba"), true);
loadDirectory(extensionClasses, DUBBO_DIRECTORY, type.getName());
loadDirectory(extensionClasses, DUBBO_DIRECTORY, type.getName().replace("org.apache", "com.alibaba"));
loadDirectory(extensionClasses, SERVICES_DIRECTORY, type.getName());
loadDirectory(extensionClasses, SERVICES_DIRECTORY, type.getName().replace("org.apache", "com.alibaba"));
return extensionClasses;
}loadExtensionClasses 方法总共做了两件事情,一是对 SPI 注解进行解析,二是调用 loadDirectory 方法加载指定文件夹配置文件。
下面研究下 loadDirectory方法
private void loadDirectory(Map<String, Class<?>> extensionClasses, String dir) {
// fileName = 文件夹路径 + type 全限定名
String fileName = dir + type.getName();
try {
Enumeration<java.net.URL> urls;
ClassLoader classLoader = findClassLoader();
// 根据文件名加载所有的同名文件
if (classLoader != null) {
urls = classLoader.getResources(fileName);
} else {
urls = ClassLoader.getSystemResources(fileName);
}
if (urls != null) {
while (urls.hasMoreElements()) {
java.net.URL resourceURL = urls.nextElement();
// 加载资源
loadResource(extensionClasses, classLoader, resourceURL);
}
}
} catch (Throwable t) {
logger.error("...");
}
}loadDirectory 方法先通过 classLoader 获取所有资源链接,然后再通过 loadResource 方法加载资源。我们继续跟下去,看一下 loadResource 方法的实现。
private void loadResource(Map<String, Class<?>> extensionClasses,
ClassLoader classLoader, java.net.URL resourceURL) {
try {
BufferedReader reader = new BufferedReader(
new InputStreamReader(resourceURL.openStream(), "utf-8"));
try {
String line;
// 按行读取配置内容
while ((line = reader.readLine()) != null) {
// 定位 # 字符
final int ci = line.indexOf('#');
if (ci >= 0) {
// 截取 # 之前的字符串,# 之后的内容为注释,需要忽略
line = line.substring(0, ci);
}
line = line.trim();
if (line.length() > 0) {
try {
String name = null;
int i = line.indexOf('=');
if (i > 0) {
// 以等于号 = 为界,截取键与值
name = line.substring(0, i).trim();
line = line.substring(i + 1).trim();
}
if (line.length() > 0) {
// 加载类,并通过 loadClass 方法对类进行缓存
loadClass(extensionClasses, resourceURL,
Class.forName(line, true, classLoader), name);
}
} catch (Throwable t) {
IllegalStateException e = new IllegalStateException("Failed to load extension class...");
}
}
}
} finally {
reader.close();
}
} catch (Throwable t) {
logger.error("Exception when load extension class...");
}
}loadResource 方法用于读取和解析配置文件,并通过反射加载类,最后调用 loadClass 方法进行其他操作。loadClass 方法用于主要用于操作缓存,该方法的逻辑如下:
private void loadClass(Map<String, Class<?>> extensionClasses, java.net.URL resourceURL,
Class<?> clazz, String name) throws NoSuchMethodException {
if (!type.isAssignableFrom(clazz)) {
throw new IllegalStateException("...");
}
// 检测目标类上是否有 Adaptive 注解
if (clazz.isAnnotationPresent(Adaptive.class)) {
if (cachedAdaptiveClass == null) {
// 设置 cachedAdaptiveClass缓存
cachedAdaptiveClass = clazz;
} else if (!cachedAdaptiveClass.equals(clazz)) {
throw new IllegalStateException("...");
}
// 检测 clazz 是否是 Wrapper 类型
} else if (isWrapperClass(clazz)) {
Set<Class<?>> wrappers = cachedWrapperClasses;
if (wrappers == null) {
cachedWrapperClasses = new ConcurrentHashSet<Class<?>>();
wrappers = cachedWrapperClasses;
}
// 存储 clazz 到 cachedWrapperClasses 缓存中
wrappers.add(clazz);
// 程序进入此分支,表明 clazz 是一个普通的拓展类
} else {
// 检测 clazz 是否有默认的构造方法,如果没有,则抛出异常
clazz.getConstructor();
if (name == null || name.length() == 0) {
// 如果 name 为空,则尝试从 Extension 注解中获取 name,或使用小写的类名作为 name
name = findAnnotationName(clazz);
if (name.length() == 0) {
throw new IllegalStateException("...");
}
}
// 切分 name,就是为什么文件要用“=”分割实现类名与类的全路径
String[] names = NAME_SEPARATOR.split(name);
if (names != null && names.length > 0) {
Activate activate = clazz.getAnnotation(Activate.class);
if (activate != null) {
// 如果类上有 Activate 注解,则使用 names 数组的第一个元素作为键,
// 存储 name 到 Activate 注解对象的映射关系
cachedActivates.put(names[0], activate);
}
for (String n : names) {
if (!cachedNames.containsKey(clazz)) {
// 存储 Class 到名称的映射关系
cachedNames.put(clazz, n);
}
Class<?> c = extensionClasses.get(n);
if (c == null) {
// 存储名称到 Class 的映射关系
extensionClasses.put(n, clazz);
} else if (c != clazz) {
throw new IllegalStateException("...");
}
}
}
}
}如上,loadClass 方法操作了不同的缓存,比如 cachedAdaptiveClass、cachedWrapperClasses 和 cachedNames 等等。除此之外,该方法没有其他什么逻辑了。
自适应扩展
自适应扩展主要是为了完成dubbo的aop机制,其核心是@Adaptive注解,该注解主要应用在接口和方法上,同时也应用了dubbo的核心重要类(URL总线型概念),通过接口定义方法(注解为@Adaptive、入参为URL),调用类使用构造的URL参数,动态的去生成@Adptive代理类,动态的编译并生成.Class文件加载到JVM里面,最后就能轻松的使用Dubbo SPI提供的AOP功能,参考如下demo;
文件命名及配置
red = com.yangfan.spi.dubbo.impl.RedCar
black = com.yangfan.spi.dubbo.impl.BlackCar
com.yangfan.spi.dubbo.impl.CarWrappertrucker = com.yangfan.spi.dubbo.impl.Trucker接口定义
@SPI
public interface Car {
@Adaptive(value = "carType")
void getColor(URL url);
}
@SPI
public interface Driver {
void driver(URL url);
}实现类定义
public class Trucker implements Driver {
private Car car;
public void setCar(Car car) {
this.car = car;
}
@Override
public void driver(URL url) {
car.getColor(url);
}
}public class BlackCar implements Car {
@Override
public void getColor(URL url) {
System.out.println("I am drivering black");
}
}
public class RedCar implements Car {
@Override
public void getColor(URL url) {
System.out.println("I am drivering red");
}
}测试类
@Test
public void testAdaptive() {
ExtensionLoader<Driver> carExtensionLoader = ExtensionLoader.getExtensionLoader(Driver.class);
Driver driver= carExtensionLoader.getExtension("trucker");
Map<String,String> map= new HashMap<>();
map.put("carType","red");
URL url = new URL("","",0,map);
driver.driver(url);
}源码分析
获取Trucker时会动用org.apache.dubbo.common.extension.ExtensionLoader#injectExtension方法进行属性注入,而属性注入需要从objectFactory工厂里获取(org.apache.dubbo.common.extension.factory.SpiExtensionFactory#getExtension),此时会发现
objectFactory并不存在该name对应的实例,因此会调用getAdaptiveExtension方法中的createAdaptiveExtension去创建实例,核心代码是createAdaptiveExtensionClass;
private Class<?> getAdaptiveExtensionClass() {
getExtensionClasses();
if (cachedAdaptiveClass != null) {
return cachedAdaptiveClass;
}
//创建实例
return cachedAdaptiveClass = createAdaptiveExtensionClass();
}在createAdaptiveExtensionClass中会动态的生成接口的代理类Car$Adaptive,其主要逻辑是在
org.apache.dubbo.common.extension.AdaptiveClassCodeGenerator#generate中完成的,生成代理类如下:
public class Car$Adaptive implements com.yangfan.spi.dubbo.api.Car {
public void getColor(org.apache.dubbo.common.URL arg0) {
if (arg0 == null) throw new IllegalArgumentException("url == null");
org.apache.dubbo.common.URL url = arg0;
String extName = url.getParameter("carType");
if (extName == null)
throw new IllegalStateException("Failed to get extension (com.yangfan.spi.dubbo.api.Car) name from url (" + url.toString() + ") use keys([carType])");
com.yangfan.spi.dubbo.api.Car extension = (com.yangfan.spi.dubbo.api.Car) ExtensionLoader.getExtensionLoader(com.yangfan.spi.dubbo.api.Car.class).getExtension(extName);
extension.getColor(arg0);
}
}上面生成的Car$Adaptive会使用java assistant技术动态的去编译加载到jvm里面;
生成的Ca$Adaptive会通过Trucker的set注入到Trucker的Car属性里面;
String property = getSetterProperty(method);
Object object = objectFactory.getExtension(pt, property);
if (object != null) {
method.invoke(instance, object);
}那么后面调用的car.getColor(url)便是调用Car$Adaptive类里面的方法,显而易见,会首先根据carType获取到将要调用的类的名称,然后再根据Dubbo的SPI机制从容器里面获取carType所对应类的都实例,此时会获取到blackCar对应的类信息,再通过反射机制获取到实例,如前面讲到的SPI一致,也会通过Set属性注入调用到Wrapper类,从而实现aop功能;
大致的流程如下:

上图标红色是自适应的核心逻辑也是Dubbo SPI 中URL总线型的具体体现,其实现过程比较绕,但围绕着一个核心:所有的调用都是基于
ExtensionLoader<Driver> carExtensionLoader = ExtensionLoader.getExtensionLoader(IXXX.class);
Driver driver= carExtensionLoader.getExtension("XXX");
这两行代码实现的,比较关键的是动态生成的那部分代码,其参数是URL,从URL里面获取CarType的name,再调动上面两行代码完成动态代理,再贴一下动态生成的代码
package com.yangfan.spi.dubbo.impl;
import org.apache.dubbo.common.extension.ExtensionLoader;
public class Car$Adaptive implements com.yangfan.spi.dubbo.api.Car {
public void getColor(org.apache.dubbo.common.URL arg0) {
if (arg0 == null) throw new IllegalArgumentException("url == null");
org.apache.dubbo.common.URL url = arg0;
String extName = url.getParameter("carType");
if (extName == null)
throw new IllegalStateException("Failed to get extension (com.yangfan.spi.dubbo.api.Car) name from url (" + url.toString() + ") use keys([carType])");
com.yangfan.spi.dubbo.api.Car extension = (com.yangfan.spi.dubbo.api.Car) ExtensionLoader.getExtensionLoader(com.yangfan.spi.dubbo.api.Car.class).getExtension(extName);
extension.getColor(arg0);
}
}有些人估计有这样的疑问,在下面代码完成car的属性注入时
ExtensionLoader<Driver> carExtensionLoader = ExtensionLoader.getExtensionLoader(Driver.class);
Driver driver= carExtensionLoader.getExtension("trucker");
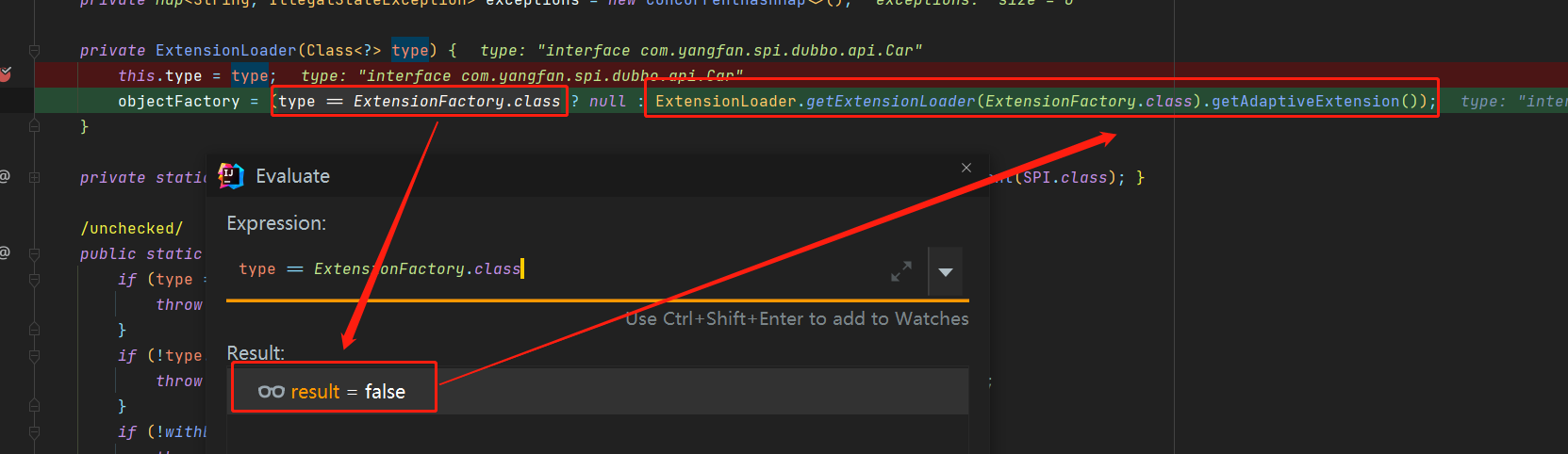
明明我在META-INF目录下已经配置了Car的系列实现类,为什么在loadExtensionClasses中的loadDIrectory的缓存中获取不到呢?这是因为Dubbo会为每个接口对应的文件生成一个ExtensionLoader<Driver>
最后
以上就是开朗仙人掌最近收集整理的关于Dubbo SPIDubbo SPI使用的全部内容,更多相关Dubbo内容请搜索靠谱客的其他文章。








发表评论 取消回复