文章目录
- 一、前言
- 二、JDK 中的 SPI
- 1 简单使用
- 2 SPI的实现原理
- 2.1 获取当前线程的类加载器
- 2.2 创建ServiceLoader 对象
- 3. Driver 的加载
- 五、Dubbo 的增强SPI
一、前言
本系列为个人Dubbo学习笔记衍生篇,是正文篇之外的衍生内容,内容来源于《深度剖析Apache Dubbo 核心技术内幕》, 过程参考官方源码分析文章。仅用于个人笔记记录。本文分析基于Dubbo2.7.0版本,由于个人理解的局限性,若文中不免出现错误,感谢指正。
SPI, 全名 service provider interface,是JDK内置的中服务发现机制, 是一种动态替换发现的机制。JDK 中的 SPI 是面向接口编程的,服务规则提供者会在JRE 的核心中提供访问接口,而具体实现则由其他开发商提供。
人话 : JDK 提供了一些功能的接口类,谁想提供这个功能,谁就实现这个接口。
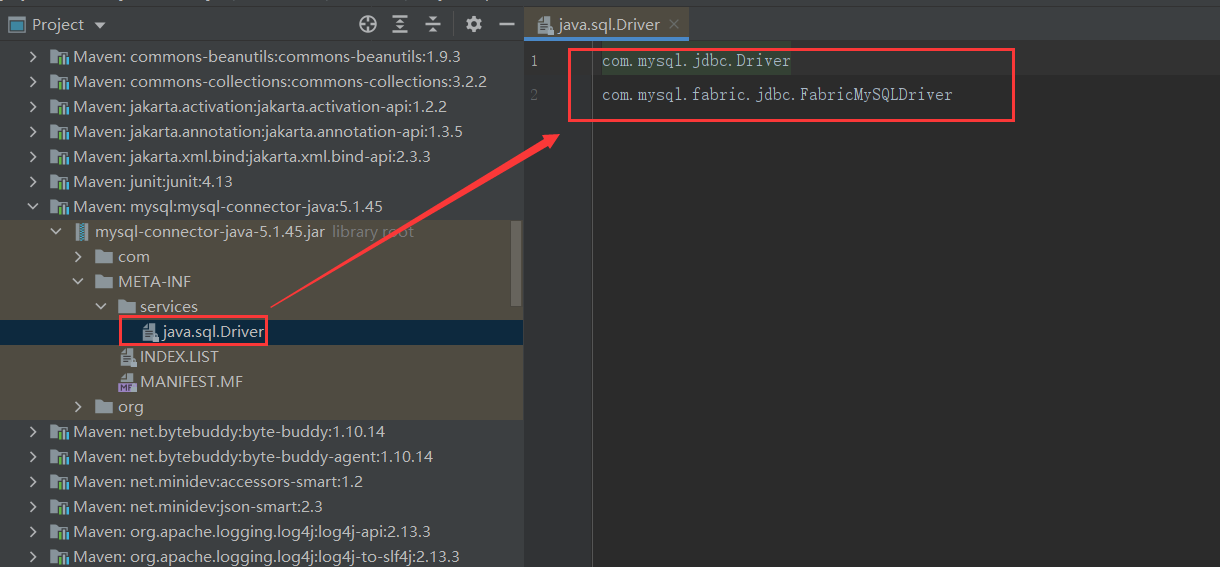
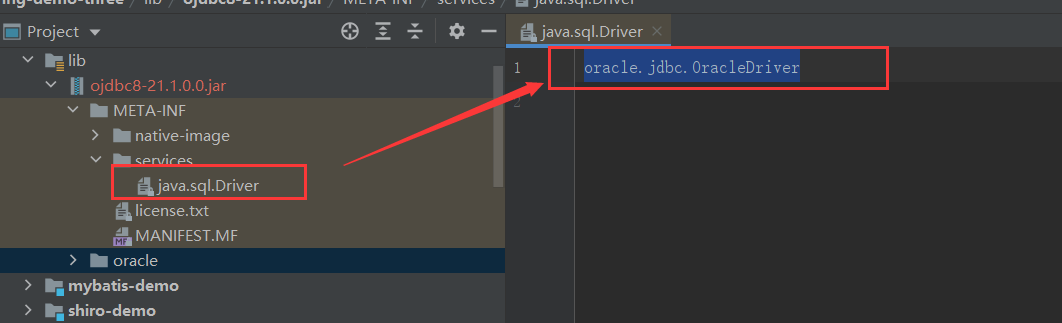
比如对于我们常用的数据库驱动接口,我们在连接不同的数据库时需要使用不同的驱动类,而规范开发者在 rt.jar 中定义了数据库驱动接口 java.sql.Driver,对于不同的厂商(比如Mysql 和 Oracle),他们的驱动实现肯定不同,这时就由他们自己去实现这个接口。开发者只管调用,不管底层如何实现。
但是JDK 如何知道哪个类是java.sql.Driver 的实现类呢?总不能全局扫描判断,费时费力。所以JDK 提供了一个规则:实现了驱动类的厂商在自己Jar包的 META-INF/services 目录下建立名称为SPI 接口类(这里指是 Java.sql.Driver )的文件,文件内容就是SPI 接口类的实现类的全路径名(这里指Mysql 针对java.sql.Driver 接口的实现类)。
比如下面的Mysql 和 Oracle :
在 Spring 中也有类似的SPI 扩展机制,不同的是 Spring是通过 META-INF/spring.factories 文件实现,这个文件很容易让人联想到 Springboot的自动装配机制,个人认为Spring 的自动装配就是在 SPI 机制上的一直延伸的用法。
二、JDK 中的 SPI
上面介绍了SPI 的基本概念,下面我们来写一个简单Demo 来演示:
1 简单使用
-
创建需要对外提供的接口类,以及他的两个实现类
// SPI 接口类 public interface SpiDemoService { String sayName(); } // 厂商A 对 SPI 接口的实现 public class ASpiDemoServiceImpl implements SpiDemoService { @Override public String sayName() { return "ASpiDemoServiceImpl.sayName"; } } // 厂商B 对 SPI 接口的实现 public class BSpiDemoServiceImpl implements SpiDemoService { @Override public String sayName() { return "BSpiDemoServiceImpl.sayName"; } } -
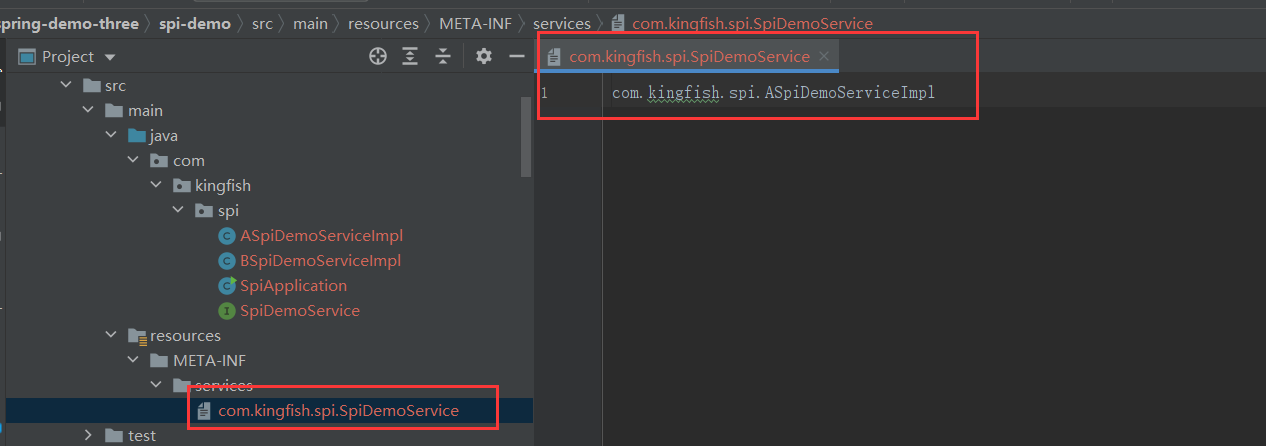
在 META-INF/services 目录下创建文件,文件名为 对外提供的接口类 的全路径名,内容是选择使用的实现类的全路径名。即,我们这里指定了 使用A厂商的实现方式 ASpiDemoServiceImpl
-
通过 ServiceLoader 加载使用
public class SpiApplication { public static void main(String[] args) { /** * 输出 * s = ASpiDemoServiceImpl.sayName */ ServiceLoader<SpiDemoService> load = ServiceLoader.load(SpiDemoService.class); for (SpiDemoService spiDemoService : load) { String s = spiDemoService.sayName(); System.out.println("s = " + s); } } }
2 SPI的实现原理
我们以上面的Demo为例,需要关注的是 ServiceLoader<SpiDemoService> load = ServiceLoader.load(SpiDemoService.class);,其代码如下:
public static <S> ServiceLoader<S> load(Class<S> service) {
// 1. 获取当前线程的类加载器
ClassLoader cl = Thread.currentThread().getContextClassLoader();
// 2. 创建ServiceLoader 对象
return ServiceLoader.load(service, cl);
}
public static <S> ServiceLoader<S> load(Class<S> service,
ClassLoader loader)
{
return new ServiceLoader<>(service, loader);
}
private ServiceLoader(Class<S> svc, ClassLoader cl) {
service = Objects.requireNonNull(svc, "Service interface cannot be null");
loader = (cl == null) ? ClassLoader.getSystemClassLoader() : cl;
acc = (System.getSecurityManager() != null) ? AccessController.getContext() : null;
reload();
}
public void reload() {
// 清空缓存信息
providers.clear();
// 初始化懒加载迭代器
lookupIterator = new LazyIterator(service, loader);
}
2.1 获取当前线程的类加载器
Java 核心API(比如 rt.jar) 是通过 Bootstrap ClassLoader 类加载器加载的。而ServiceLoader 正是 rt.jar 提供的类,然而一个类由类加载器加载,那么这个类依赖的类也是由相同的类加载器加载的,按照这个道理用户提供的SPI 扩展实现类则应该也是通过 Bootstrap ClassLoader 类加载器加载。然而 用户提供的类都应使用AppClassLoader 进行加载。所以此时采用了一种违反双亲委派模式的方法:JDK通过获取当前当线程上下文类加载器来解决这个问题。并且可以看到的是 cl 随着 ServiceLoader.load(service, cl)传递了下去。具体使用场景,我们下面会说到。
2.2 创建ServiceLoader 对象
上面可以看到 ServiceLoader.load(service, cl) 经过了多层跳转,最终落到了 lookupIterator = new LazyIterator(service, loader); 中。
LazyIterator 看名字就知道是一个懒加载迭代器,猜测就是只有在实际获取迭代器中的对象时才会初始化。我们这里先按下不表
先来看一看 ServiceLoader,SpiApplication 在编译后会变成如下代码(因为迭代器的for循环本质上只是一种语法糖而已,编译后就"原形毕露"),而
public class SpiApplication {
public SpiApplication() {
}
public static void main(String[] args) {
ServiceLoader<SpiDemoService> load = ServiceLoader.load(SpiDemoService.class);
Iterator var2 = load.iterator();
while(var2.hasNext()) {
SpiDemoService spiDemoService = (SpiDemoService)var2.next();
String s = spiDemoService.sayName();
System.out.println("s = " + s);
}
}
}
而ServiceLoader 实现了Iterable接口,所以这里的 Iterator 实际实现是 ServiceLoader#iterator 方法的返回,如下,我们这里只看 ServiceLoader#iterator 方法的实现,可以看到ServiceLoader#iterator 方法将逻辑都委托给了 lookupIterator 来处理,而lookupIterator 则是我们一开始初始化的 LazyIterator。
public Iterator<S> iterator() {
return new Iterator<S>() {
// 将缓存的信息,转换成迭代器。
Iterator<Map.Entry<String,S>> knownProviders
= providers.entrySet().iterator();
public boolean hasNext() {
if (knownProviders.hasNext())
return true;
return lookupIterator.hasNext();
}
public S next() {
// 首先从缓存中尝试获取。
if (knownProviders.hasNext())
return knownProviders.next().getValue();
// 这里的 lookupIterator 就是上面 初始化时的 LazyIterator
return lookupIterator.next();
}
public void remove() {
throw new UnsupportedOperationException();
}
};
}
所以我们这里看一下 ServiceLoader.LazyIterator 的具体实现:
private static final String PREFIX = "META-INF/services/";
private class LazyIterator
implements Iterator<S>
{
// SPI 接口类
Class<S> service;
// 上面获取到的 当前上下文线程的类加载器。
ClassLoader loader;
Enumeration<URL> configs = null;
// 用来保存SPI 文件解析出来的 SPI 实现类的全路径名
Iterator<String> pending = null;
String nextName = null;
private LazyIterator(Class<S> service, ClassLoader loader) {
this.service = service;
this.loader = loader;
}
private boolean hasNextService() {
if (nextName != null) {
return true;
}
if (configs == null) {
try {
// 拼接 META-INF/services/ 路径,获取到SPI 接口文件路径,并进行加载获取
String fullName = PREFIX + service.getName();
if (loader == null)
configs = ClassLoader.getSystemResources(fullName);
else
configs = loader.getResources(fullName);
} catch (IOException x) {
fail(service, "Error locating configuration files", x);
}
}
// 如果 pending 还没有加载过,或者不存在元素,则进行加载
while ((pending == null) || !pending.hasNext()) {
if (!configs.hasMoreElements()) {
return false;
}
pending = parse(service, configs.nextElement());
}
// 保存下一个 SPI 实现类的 全路径名
nextName = pending.next();
return true;
}
// 返回SPI 实现类
private S nextService() {
// 判断是否存在下一个实现类,这里给 nextName 进行赋值
if (!hasNextService())
throw new NoSuchElementException();
// 获取下一个SPI 实现类的全路径类名
String cn = nextName;
nextName = null;
Class<?> c = null;
try {
// 通过反射获取到SPI 实现类的实例,这里需要注意的是,这里指定了类加载器为线程上下文的类加载器,也就是 AppClassLoader
c = Class.forName(cn, false, loader);
} catch (ClassNotFoundException x) {
fail(service,
"Provider " + cn + " not found");
}
if (!service.isAssignableFrom(c)) {
fail(service,
"Provider " + cn + " not a subtype");
}
try {
S p = service.cast(c.newInstance());
// 将SPI 实现类缓存到providers中,providers 是一个 LinkedHashMap
providers.put(cn, p);
return p;
} catch (Throwable x) {
fail(service,
"Provider " + cn + " could not be instantiated",
x);
}
throw new Error(); // This cannot happen
}
public boolean hasNext() {
if (acc == null) {
return hasNextService();
} else {
PrivilegedAction<Boolean> action = new PrivilegedAction<Boolean>() {
public Boolean run() { return hasNextService(); }
};
return AccessController.doPrivileged(action, acc);
}
}
public S next() {
if (acc == null) {
return nextService();
} else {
PrivilegedAction<S> action = new PrivilegedAction<S>() {
public S run() { return nextService(); }
};
return AccessController.doPrivileged(action, acc);
}
}
public void remove() {
throw new UnsupportedOperationException();
}
}
解析完LazyIterator,我们基本就能把整个逻辑猜测的八九不离十了。
即:
ServiceLoader.load指定SPI 接口类后获取当前线程上下文的类加载器- 依赖于根据SPI 接口类 生成一个 ServiceLoader 返回。此时
ServiceLoader中初始化了一个懒加载迭代器LazyIterator。 - 当我们调用
ServiceLoader迭代时,ServiceLoader会调用LazyIterator来进行迭代。 LazyIterator在判断是否有元素时会去加载 META-INF/services 下SPI 接口文件 来获取SPI 实现类,并缓存(第二次判断则不会再重新加载)。- 在通过 next 方法获取 SPI 实现类时才会真正通过反射去创建实现类(这也是为什么叫懒加载迭代器的原因)。
3. Driver 的加载
结合上面的分析,我们再来简单看看 数据库驱动 Driver的加载。
我们依稀记得最原始的驱动加载:
// 加载驱动
Class.forName("com.mysql.jdbc.Driver");
// 获取连接
Connection connection = DriverManager.getConnection("url", "user", "password");
这里我们直接来看 DriverManager,下面代码精简了部分
public class DriverManager {
....
// 静态代码块
static {
loadInitialDrivers();
println("JDBC DriverManager initialized");
}
....
private static void loadInitialDrivers() {
.....
AccessController.doPrivileged(new PrivilegedAction<Void>() {
public Void run() {
// 通过SPI 加载 Driver
ServiceLoader<Driver> loadedDrivers = ServiceLoader.load(Driver.class);
Iterator<Driver> driversIterator = loadedDrivers.iterator();
// 因为是懒加载迭代器,所以这里需要通过next 将其实例化。
try{
while(driversIterator.hasNext()) {
driversIterator.next();
}
} catch(Throwable t) {
// Do nothing
}
return null;
}
});
.....
}
五、Dubbo 的增强SPI
对于SDK 的SPI,Spring 通过 spring.factories 文件实现了增强,但这不是本文重点,所以暂且不表,如有需要,详参: Spring源码分析十一:Springboot 自动装配。
Dubbo 的扩展点机制是基于SDK 中的SPI 增强而来,解决了以下问题:
- JDK标准的SPI 会一次性实例化扩展点的所有实现,如果有些扩展点实现初始化很耗时,但又没用上,那么加载就很浪费资源。比如上面所说的Mysql 和Oracle 数据库驱动,当引入这两个包时,即使我们只需要使用其中一个驱动,另一个驱动实现类也会初始化。
- 如果扩展点加载失败,是不会友好的向用户通知具体异常,异常提示信息可能并不正确。
- 增加了对扩展点 Ioc 和 Aop 的支持,一个扩展点可以直接使用setter() 方法注入其他扩展点,也可以对扩展点使用Wrapper 类进行功能增强。
篇幅所限,详参: Dubbo笔记衍生篇②:Dubbo SPI 原理
以上:内容部分参考
《深度剖析Apache Dubbo 核心技术内幕》
https://my.oschina.net/kipeng/blog/1789849
https://www.cnblogs.com/helloz/p/10961026.html
https://www.cnblogs.com/LUA123/p/12460869.html
如有侵扰,联系删除。 内容仅用于自我记录学习使用。如有错误,欢迎指正
最后
以上就是寒冷柠檬最近收集整理的关于Dubbo笔记衍生篇①:JDK SPI机制一、前言二、JDK 中的 SPI五、Dubbo 的增强SPI的全部内容,更多相关Dubbo笔记衍生篇①:JDK内容请搜索靠谱客的其他文章。






![[总结]Dubbo 自适应扩展学习笔记](https://www.shuijiaxian.com/files_image/reation/bcimg6.png)

发表评论 取消回复