文章目录
- 前言
- SPI的主要目录
- 开始分析
- 1. DubboBootstrap类的设计
- 2. 触发 ExtensionLoader.getExtension(name)
- 3. Holder 缓存
- 4. 缓存中没有实例,创建
- 使用时
- 1. SPI注解
- 2. 关于SPI注解的操作
- 3. AdaptiveExtensionFactory 类
- 4. 从缓存中取、到缓存中去
前言
本篇文章基于 Dubbo (版本:2.7.8)源码的SPI部分。
代码下载:https://github.com/apache/dubbo/releases
SPI的主要目录
开始分析
先上个图:
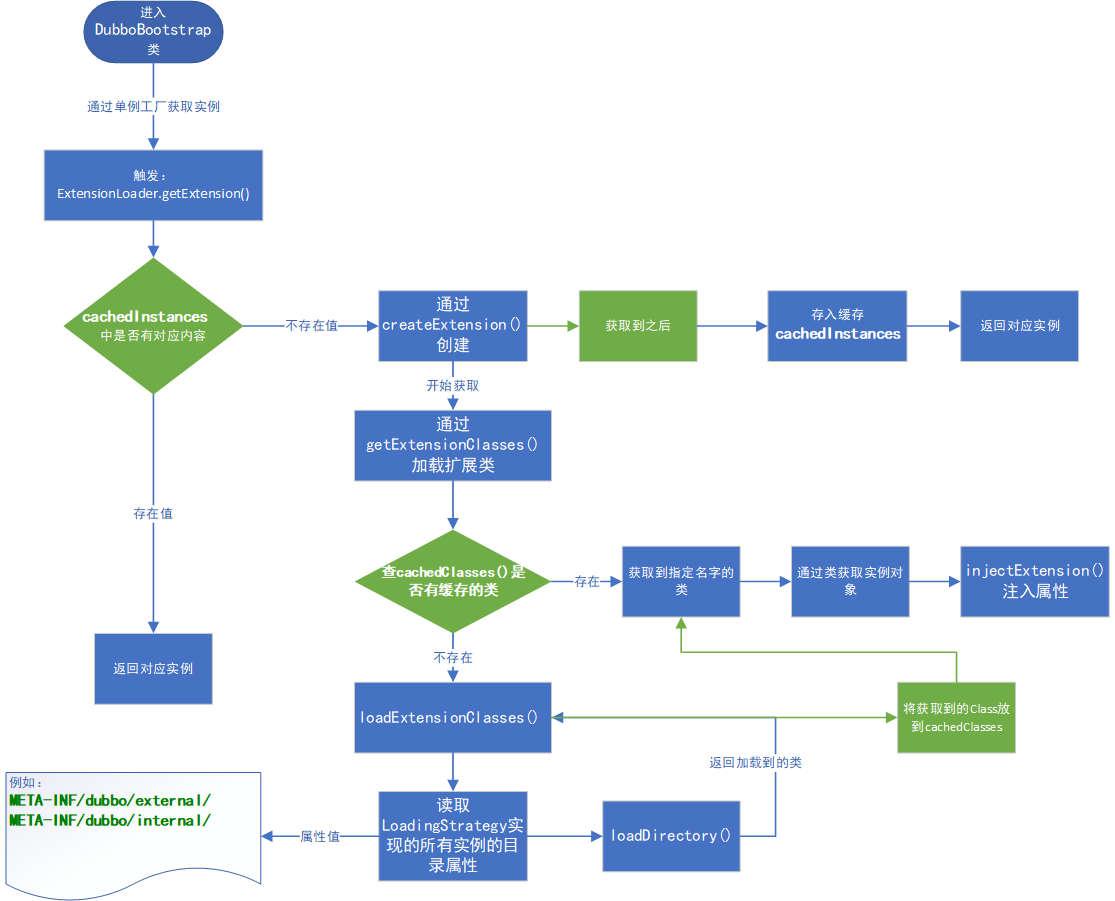
然后我们继续看各个部分的内容。
1. DubboBootstrap类的设计
这个类被设计为了单例。
官方文档给出的解释是,Dubbo中的一些类,是在每个线程下只有一个实例的。其中就包含了今天的主角: ExtensionLoader。它里边有大量的 static 修饰的方法。
这是该类的初始化:
public static DubboBootstrap getInstance() {
if (instance == null) {
synchronized (DubboBootstrap.class) {
if (instance == null) {
instance = new DubboBootstrap();
}
}
}
return instance;
}
private DubboBootstrap() {
configManager = ApplicationModel.getConfigManager();
environment = ApplicationModel.getEnvironment();
DubboShutdownHook.getDubboShutdownHook().register();
ShutdownHookCallbacks.INSTANCE.addCallback(new ShutdownHookCallback() {
@Override
public void callback() throws Throwable {
DubboBootstrap.this.destroy();
}
});
}
2. 触发 ExtensionLoader.getExtension(name)
可以看到在构造器中有ApplicationModel.getXXXX()方法。
在我点进去看了之后,发现在ApplicationModel中,初始化了ExtensionLoader,然后通过它触发了 ExtensionLoader中的:
public T getExtension(String name) {
return getExtension(name, true);
}
public T getExtension(String name, boolean wrap) {
if (StringUtils.isEmpty(name)) {
throw new IllegalArgumentException("Extension name == null");
}
if ("true".equals(name)) {
return getDefaultExtension();
}
final Holder<Object> holder = getOrCreateHolder(name);
Object instance = holder.get();
if (instance == null) {
synchronized (holder) {
instance = holder.get();
if (instance == null) {
instance = createExtension(name, wrap);
holder.set(instance);
}
}
}
return (T) instance;
}
通过它获取一个扩展类的实例。即通过一个指定的 @SPI(name) 中的 name 值获取指定的扩展类实例。
3. Holder 缓存
Holder 其实就是存储在一个Map中。
key=之前传入的name
value=对应名字的一个扩展类的承载类实例。
private final ConcurrentMap<String, Holder<Object>> cachedInstances = new ConcurrentHashMap<>();
当尝试从这个缓存取值时,如果取到值了,就会直接用。
没取到就会触发创建指定扩展实例的方法。
4. 缓存中没有实例,创建
调用 createExtension()这个方法来创建。
该方法的职责是:
从外部默认位置(比如:META-INF/dubbo/internal/)加载一个文件,通过该文件获取完整类名,然后通过反射 clazz.newInstance()创建实例。
(注意,在加载Class时,也使用了缓存)
在获取到实例后,对实例属性注入值。
随后将该实例存放到缓存中,随后返回。
使用时
1. SPI注解
首先需要实现带有SPI注解的接口。
比如:
@SPI(RandomLoadBalance.NAME)
public interface LoadBalance {
@Adaptive("loadbalance")
<T> Invoker<T> select(List<Invoker<T>> invokers, URL url, Invocation invocation) throws RpcException;
}
这里的 RandomLoadBalance.NAME实际上就是random,然后在文件列表中:
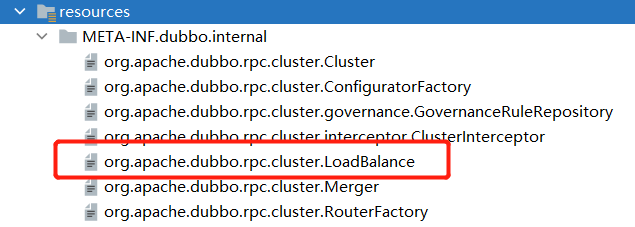
这个接口名的文件中定义了该接口的一些实现:
random=org.apache.dubbo.rpc.cluster.loadbalance.RandomLoadBalance
roundrobin=org.apache.dubbo.rpc.cluster.loadbalance.RoundRobinLoadBalance
leastactive=org.apache.dubbo.rpc.cluster.loadbalance.LeastActiveLoadBalance
consistenthash=org.apache.dubbo.rpc.cluster.loadbalance.ConsistentHashLoadBalance
shortestresponse=org.apache.dubbo.rpc.cluster.loadbalance.ShortestResponseLoadBalance
没错, @SPI(name)这里的name实际就是这个文件中的key值(等号左边)。
那么通过这个注解是怎么来加载这个类的呢?
2. 关于SPI注解的操作
public class SpiExtensionFactory implements ExtensionFactory {
@Override
public <T> T getExtension(Class<T> type, String name) {
if (type.isInterface() && type.isAnnotationPresent(SPI.class)) {
ExtensionLoader<T> loader = ExtensionLoader.getExtensionLoader(type);
if (!loader.getSupportedExtensions().isEmpty()) {
return loader.getAdaptiveExtension();
}
}
return null;
}
}
可以看到,这个工厂最终是调用了ExtensionLoader.getAdaptiveExtension()。
然而工厂在dubbo中也有俩实现:
@Adaptive
public class AdaptiveExtensionFactory implements ExtensionFactory{}
public class SpiExtensionFactory implements ExtensionFactory {}
因为AdaptiveExtensionFactory带有了@Adaptive注解,在使用时,会返回它。
在上一节分析的开始时,我的那张图中,有一个loadExtensionClasses()这个加载类的操作。
那么在这个方法的内部,实际上就对这个进行了判断实现:
private Map<String, Class<?>> loadExtensionClasses() {
cacheDefaultExtensionName();
Map<String, Class<?>> extensionClasses = new HashMap<>();
for (LoadingStrategy strategy : strategies) {
loadDirectory(extensionClasses, strategy.directory(), type.getName(), strategy.preferExtensionClassLoader(), strategy.overridden(), strategy.excludedPackages());
loadDirectory(extensionClasses, strategy.directory(), type.getName().replace("org.apache", "com.alibaba"), strategy.preferExtensionClassLoader(), strategy.overridden(), strategy.excludedPackages());
}
return extensionClasses;
}
这里有调用 loadDirectory方法,这个方法中调用了loadResource(),loadResource()调用了loadClass(),在loadClass中:
private void loadClass(Map<String, Class<?>> extensionClasses, java.net.URL resourceURL, Class<?> clazz, String name,
boolean overridden) throws NoSuchMethodException {
if (!type.isAssignableFrom(clazz)) {
throw new IllegalStateException("Error occurred when loading extension class (interface: " +
type + ", class line: " + clazz.getName() + "), class "
+ clazz.getName() + " is not subtype of interface.");
}
if (clazz.isAnnotationPresent(Adaptive.class)) {
cacheAdaptiveClass(clazz, overridden);
} else if (isWrapperClass(clazz)) {
cacheWrapperClass(clazz);
} else {
clazz.getConstructor();
if (StringUtils.isEmpty(name)) {
name = findAnnotationName(clazz);
if (name.length() == 0) {
throw new IllegalStateException("No such extension name for the class " + clazz.getName() + " in the config " + resourceURL);
}
}
String[] names = NAME_SEPARATOR.split(name);
if (ArrayUtils.isNotEmpty(names)) {
cacheActivateClass(clazz, names[0]);
for (String n : names) {
cacheName(clazz, n);
saveInExtensionClass(extensionClasses, clazz, n, overridden);
}
}
}
}
这里判断了类是否带有Adaptive注解,存在就放到缓存中。
剩下就是取值了。主要在AdaptiveExtensionFactory 中。
3. AdaptiveExtensionFactory 类
@Adaptive
public class AdaptiveExtensionFactory implements ExtensionFactory {
private final List<ExtensionFactory> factories;
public AdaptiveExtensionFactory() {
ExtensionLoader<ExtensionFactory> loader = ExtensionLoader.getExtensionLoader(ExtensionFactory.class);
List<ExtensionFactory> list = new ArrayList<ExtensionFactory>();
for (String name : loader.getSupportedExtensions()) {
list.add(loader.getExtension(name));
}
factories = Collections.unmodifiableList(list);
}
@Override
public <T> T getExtension(Class<T> type, String name) {
for (ExtensionFactory factory : factories) {
T extension = factory.getExtension(type, name);
if (extension != null) {
return extension;
}
}
return null;
}
}
这个工厂实现,在构造器中加载了所有的工厂实现,在后提供获取实例的getExtension()方法。
这样就实现了套娃。可以从SpiExtensionFactory的getExtension()方法获取值。最终调用的是ExtensionLoader.getAdaptiveExtension()。
4. 从缓存中取、到缓存中去
ExtensionLoader.getAdaptiveExtension()中,对private final Holder<Object> cachedAdaptiveInstance = new Holder<>();进行了操作。
值得一提的是,这个 Holder的属性,是用的原子变量private volatile T value;定义的,线程间可见。
public T getAdaptiveExtension() {
Object instance = cachedAdaptiveInstance.get();
if (instance == null) {
if (createAdaptiveInstanceError != null) {
throw new IllegalStateException("Failed to create adaptive instance: " +
createAdaptiveInstanceError.toString(),
createAdaptiveInstanceError);
}
synchronized (cachedAdaptiveInstance) {
instance = cachedAdaptiveInstance.get();
if (instance == null) {
try {
instance = createAdaptiveExtension();
cachedAdaptiveInstance.set(instance);
} catch (Throwable t) {
createAdaptiveInstanceError = t;
throw new IllegalStateException("Failed to create adaptive instance: " + t.toString(), t);
}
}
}
}
return (T) instance;
}
最后
以上就是背后心锁最近收集整理的关于Dubbo源码解析之SPI加载机制前言SPI的主要目录开始分析使用时的全部内容,更多相关Dubbo源码解析之SPI加载机制前言SPI内容请搜索靠谱客的其他文章。








发表评论 取消回复