jdk和dubbo的SPI机制
前言:开闭原则一直是软件开发领域中所追求的,开闭原则中的"开"是指对于组件功能的扩展是开放的,是允许对其进行功能扩展的,“闭”,是指对于原有代码的修改是封闭的,即不应该修改原有的代码。对于一个高度集成化的、成熟、稳健的系统来讲,永远不是封闭、固守的,它需要向外提供一定的可扩展的能力,外部的实现类或者jar包都可以调用它。在面向对象的开发领域中,接口是对系统功能的高度抽象,因为SPI可谓是"应运而生",本篇博客就开始走进SPI,探究java自身的SPI和Dubbo的SPI到底是什么原理
目录
一:SPI是什么
二:jdk的SPI
三:dubbo的SPI
四:总结
正文
一:SPI是什么?
spi全称英文是service provider Interface,翻译成中文也就是服务提供接口,在jdk 1.6开始,就已经提供了SPI.它的使用比较简单。即在项目的类路径下提供一个META/services/xx文件,配置一个文件,文件名为接口的全路径的名称,内容为具体的实现类全路径名。jdk将会使用ServiceLoader.load()方法去解析和加载接口和其中的实现类,按需执行不同的方法。
举个简单的例子:在jdbc中,jdk提供了driver(数据库)接口,但是不同的厂商实现起来的方式不同,比如mysql、oracle、sqlLite等厂商底层的实现逻辑都是不同的,因此在对数据库驱动driver实现方式上,可以采用SPI机制。比如在mysql-contactor.jar包中会在META/services路径下,这里相当于扩展了java.sql.Driver接口,jdk会在META/services路径下扫描该文件,然后加载mysql的diver实现类com.mysql.cj.jdbc.Driver,就相当于扩展了Driver的接口能力,按需加载mysql的实现类。oracle的连接jar包会有oracle的配置文件,这样不同的数据库根据自身的不同逻辑按需扩展了Driver的能力,这就是SPI的最大好处。
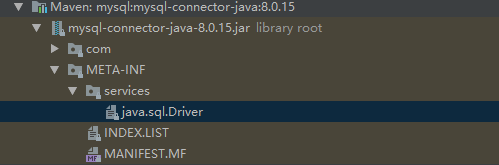
java.sql.Driver的内容:
![]()
二:java的SPI机制
从jdk1.6开始,java就提供了spi机制的支持,接下来我们就从一个例子来说明jdk的spi是如何实现的?
2.1:设计一个接口
public interface Animal {
void sound();
}
2.2:有两个实现类:
public class Cat implements Animal {
public void sound() {
System.out.println("小猫在叫");
}
}
public class Dog implements Animal {
public void sound() {
System.out.println("小狗在叫");
}
}
2.3:配置META-INF类


2.4:读取配置
public static void main(String[] args) {
ServiceLoader<Animal> serviceLoader = ServiceLoader.load(Animal.class);
final Iterator<Animal> iterator = serviceLoader.iterator();
while (iterator.hasNext()) {
Animal next = iterator.next();
next.sound();
}
}
}
2.5:原理
在上面的例子中:定义了一个接口Animal,然后有两个实现类:Cat和Dog,在META-INF的文件目录下,两个接口都进行了相关的配置,接口实现类模块要同时加载两个类,具体的调用逻辑在客户端的ServiceLoader中来通过迭代器遍历来调用具体的配置实现类,那么代码具体的原理是什么呢?跟着我一起走进源码来分析一下jdk:
在ServiceLoader的load方法中首先会获取上下文类加载器,然后构造一个ServiceLoader,在ServiceLoader中有一个懒加载器,懒加载器会通过BufferedReader来从META-INF/services路径下读取对应的接口名的全路径名文件,也就是我们配置的文件,然后通过文件的类解析器读取文件中的内容,再通过类加载器加载类的全路径
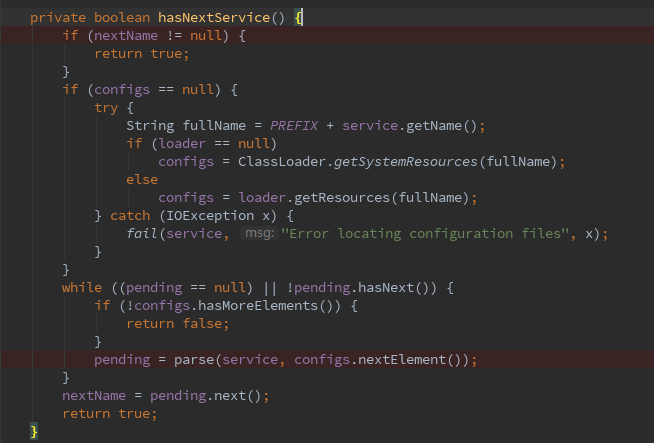
仔细分析下java的spi具有以下缺点:
①无法按需加载。虽然 ServiceLoader 做了延迟载入,使用了LazyIterator,但是基本只能通过遍历全部获取,接口的实现类得全部载入并实例化一遍。如果你并不想用某些实现类,或者某些类实例化很耗时,它也被载入并实例化了,假如我只需要其中一个,其它的并不需要这就形成了一定的资源消耗浪费
②不具有IOC的功能,假如我有一个实现类,如何将它注入到我的容器中呢,类之间依赖关系如何完成呢?
③serviceLoader不是线程安全的,会出现线程安全的问题
三:dubbo的SPI
dubbo在原有的spi基础上主要有以下的改变,①配置文件采用键值对配置的方式,使用起来更加灵活和简单 ② 增强了原本SPI的功能,使得SPI具备ioc和aop的功能,这在原本的java中spi是不支持的。dubbo的spi是通过ExtensionLoader来解析的,通过ExtensionLoader来加载指定的实现类,配置文件的路径在META-INF/dubbo路径下,我们通过一个例子来了解dubbo的SPI运行机制:
3.1:dubbo的负载均衡机制其中就采用了spi机制,选择哪个负载均衡策略是通过@SPI注解来实现的:
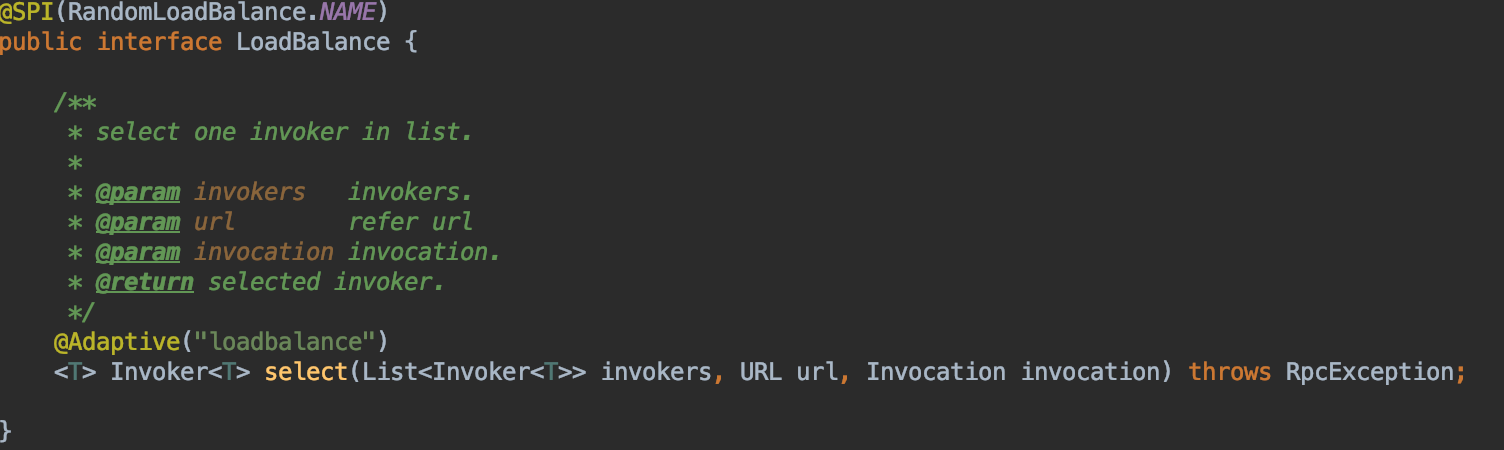
利用ExtensionLoader.getExtensionLoader(LoadBalance.class).getExtension(name)来获取具体的LoadBalance的实现类,其中name是对应配置文件(见下文)中的键;

其中用了@SPI来指定了dubbo的负载均衡策略为随机(random),我们再来了解一下@SPI注解和@Adaptive是如何工作的?
3.2:在dubbo的META_INF.dubbo.internal路径下存在一个文件:
com.alibaba.dubbo.rpc.cluster.LoadBalance文件,文件内容是这样的:
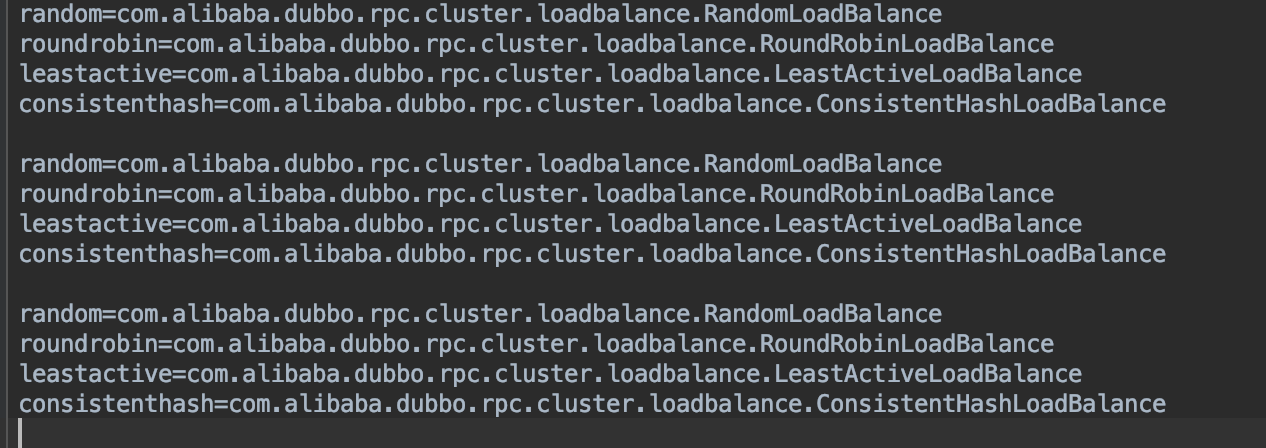
可以看出dubbo的spi配置是采用键值对的方式,键值对最大的好处就是可以以键来获取值,取值比较简单和方便。这点和java的spi配置方式是不同的,java的spi只有全路径名;
3.3:@SPI和@Adaptive注解的作用是什么?
Dubbo通过注解@Adaptive作为标记实现了一个适配器类,dubbo将会为这个类动态生成代理对象;ExtensionLoader中获取默认实现类或者通过实现类名称(由@SPI注解指定的名称)来获取实现类
为什么会出现@Adaptive这个注解呢?主要原因是因为dubbo的加载扩展了是从配置文件加载的,是很动态的,但是实现类却要固定写死或者灵活实现,所以就得区分开。用@Adaptive就是表示由框架自己生成,不需要人为实现.
在dubbo加载SPI时会动态创建SPI Adaptive实现ExtensionLoader。从URL获取密钥,该密钥将通过@Adaptive由接口方法定义的注释提供
3.4:dubbo的spi读取配置和实现类原理
3.4.1:从解析加载配置类的源码开始分析
ExtensionLoader.getExtensionLoader(LoadBalance.class).getExtension(Constants.DEFAULT_LOADBALANCE)
上面的源码比较简单,首先是根据传入的接口从缓存(一个以class为键,ExtensionLoader为值的concurrentHashMap)中获取,如果拿不到就放入到缓存中;逻辑比较简单,这里就不做详细分析了。接下来主要是分析:ExtensionLoader.getExtension(name)
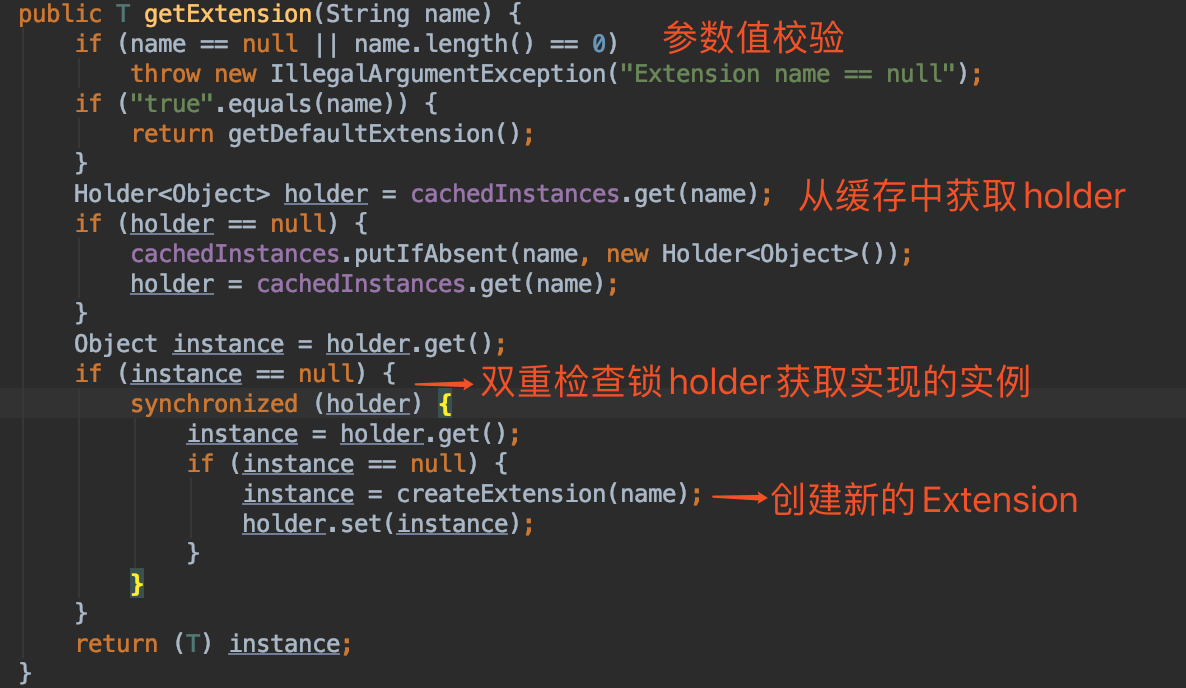
我们来看下具体的createExtension方法的源码:
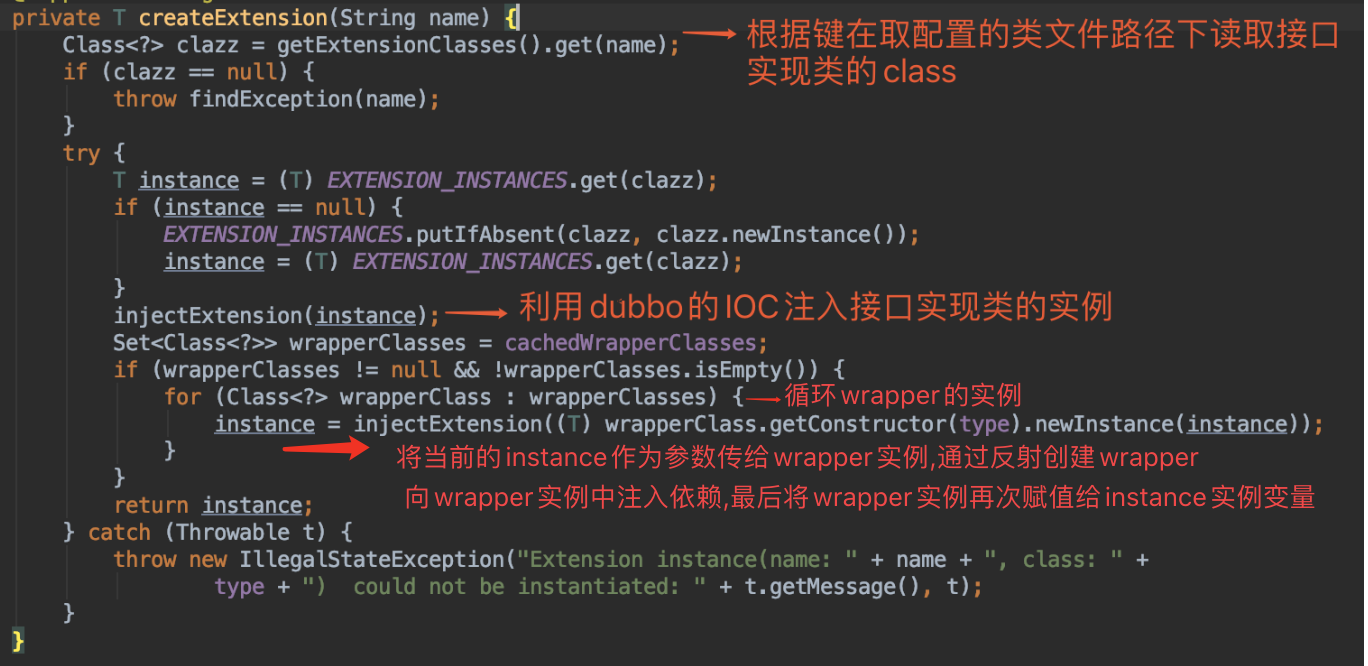
createExtension 方法的逻辑稍复杂一下,包含了如下的步骤:
①通过 getExtensionClasses 获取所有的拓展类,也就是所有META-INF下的配置文件中的键值对名
②通过反射创建拓展对象
③向拓展对象中注入依赖
④将拓展对象包裹在相应的 Wrapper 对象中,后面需要从wrapper中取
来具体看一下dubbo是如何解析配置文件的:

上面可以看出三个路径,这和我们刚才上面看到的路径是一致的,dubbo就是读取该路径下的的文件 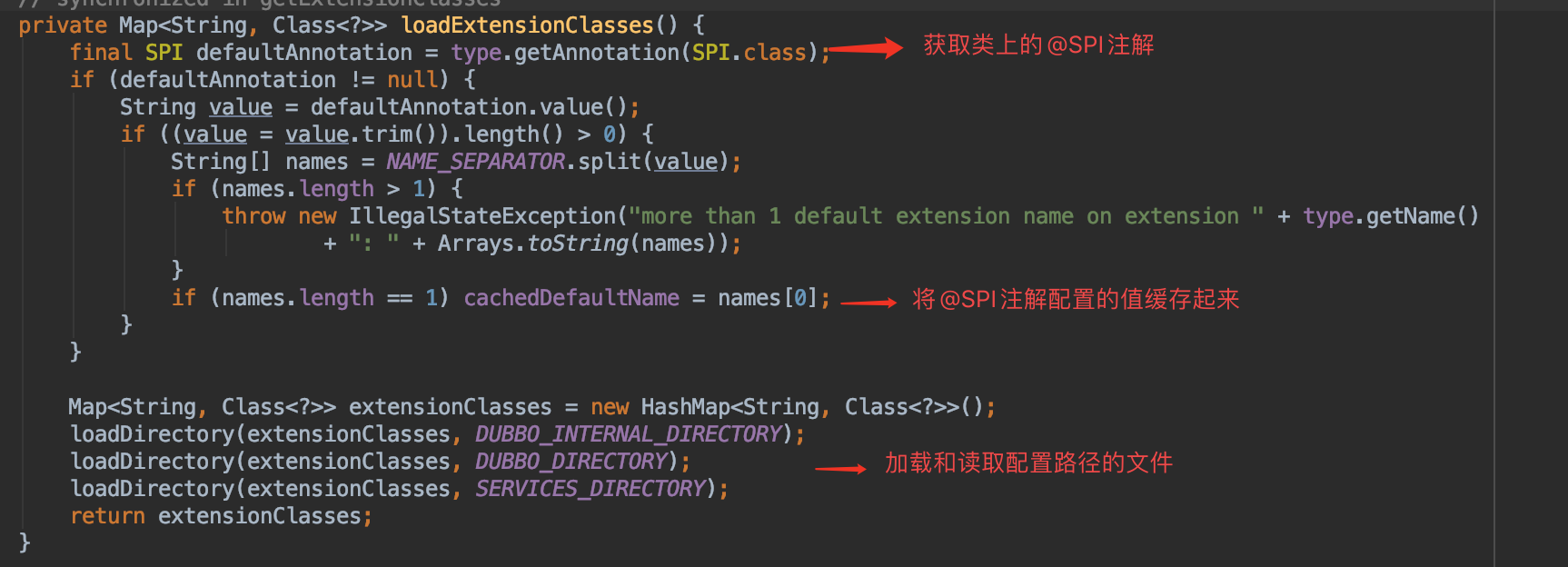
加载配置文件下的文件内容,也就是上面的com.alibaba.dubbo.rpc.cluster.LoadBalance文件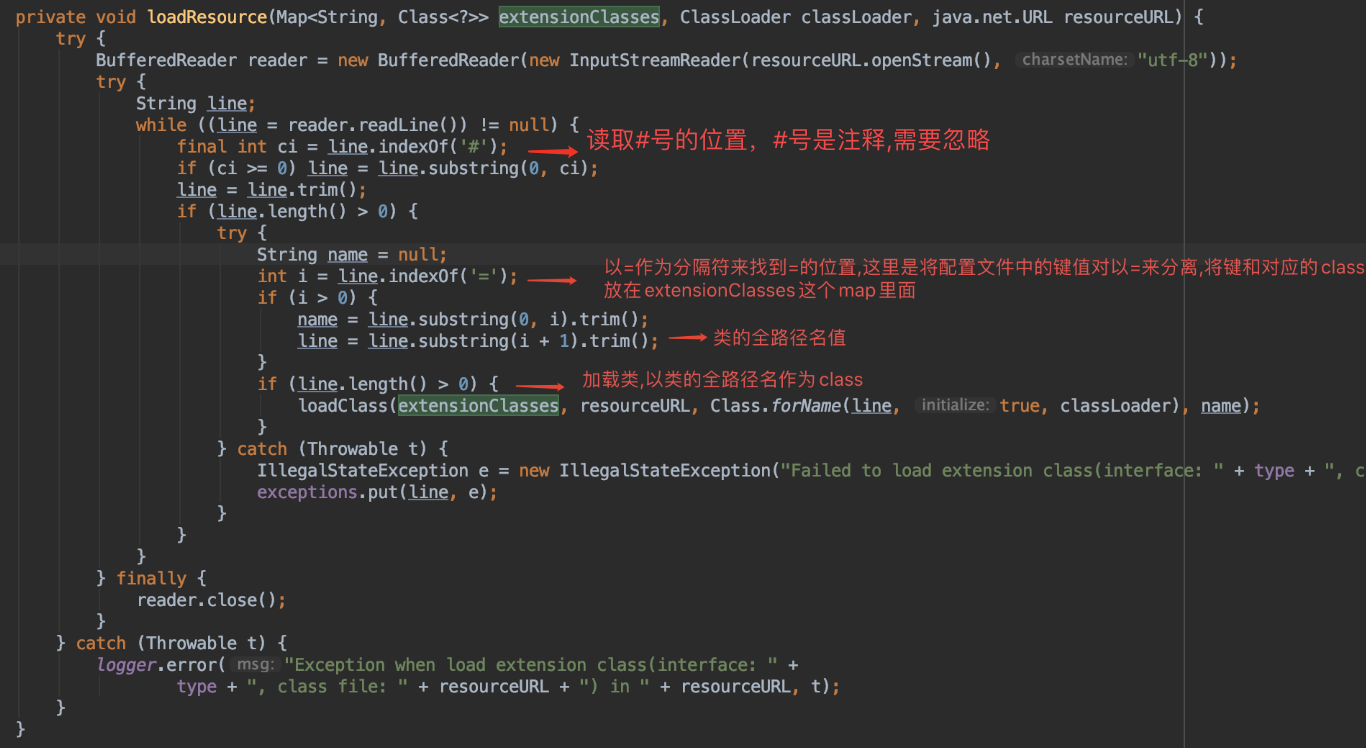
3.5:dubbo的IOC机制
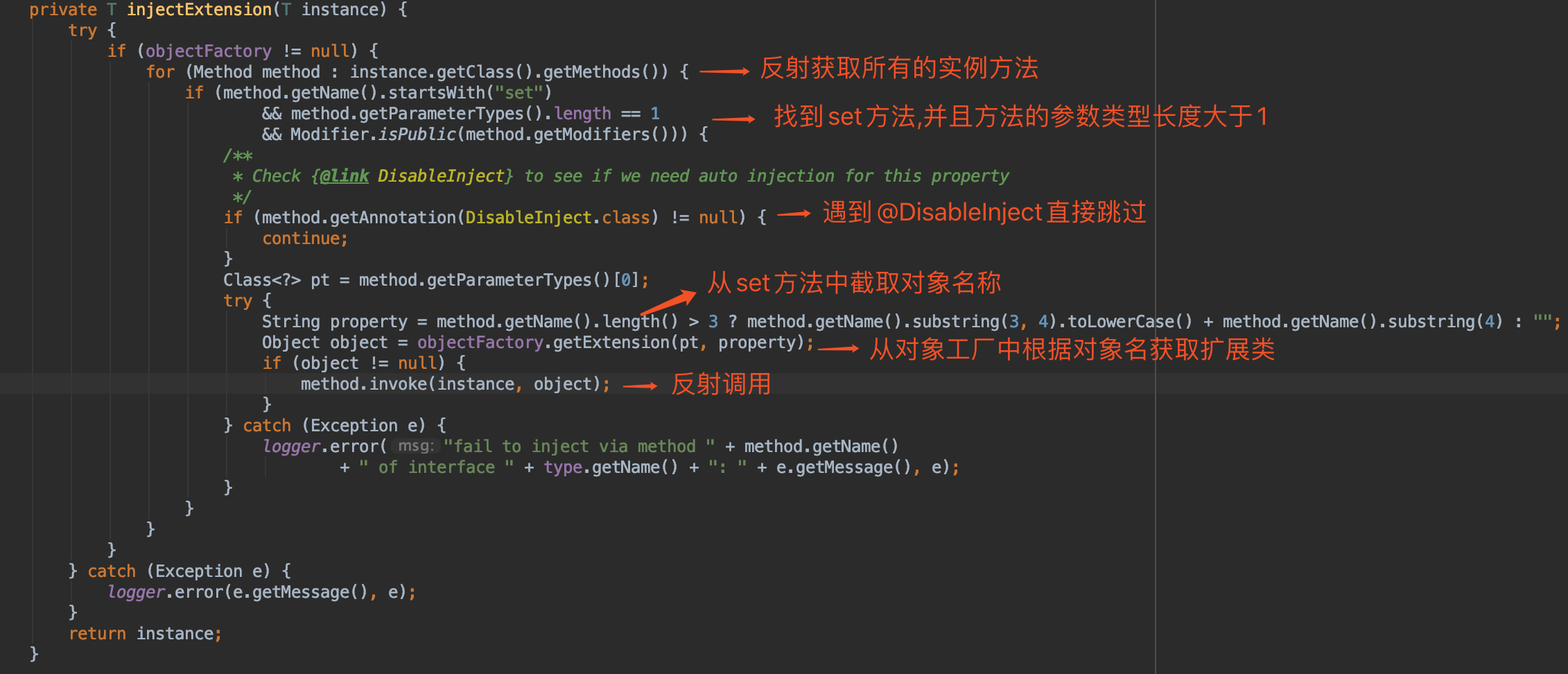
dubbo的IOC是通过setter方法来实现注入的,通过遍历对象实例的所有方法,找到其setter方法在进行截取,从objectFactory中获取扩展类再进行反射执行。这样的话,就算实现实例中有依赖的扩展实例,都可以注入完成,是dubbo的IOC体现。ojectFactory 变量的类型为 AdaptiveExtensionFactory,AdaptiveExtensionFactory 内部维护了一个 ExtensionFactory 列表,用于存储其他类型的 ExtensionFactory。
四:总结
本篇博客简单分别介绍了 Java SPI 与 Dubbo SPI 用法,java的spi举了个简单的例子来进行了说明。并仔细分析了jdk的spi不足,dubbo是如何面对jdk的不足之处,然后自己定制开发出一套更加合理和更好的dubbo自我实现。以及详细分析了 Dubbo SPI 的加载拓展类的过程和源码的分析。其中可以看出来dubbo中对于缓存和反射的利用是相当之多的.SPI是软件设计中高扩展性的一个体现,通过spi机制可以灵活地实现厂商的规范订制和不同企业的具体规范自己实现.高度扩展了原程序,使得我们设计出来的程序更加具有扩展力。
最后
以上就是清秀手套最近收集整理的关于jdk和dubbo的SPI机制jdk和dubbo的SPI机制四:总结 的全部内容,更多相关jdk和dubbo内容请搜索靠谱客的其他文章。








发表评论 取消回复