一、shuffle文件拉取失败的背景介绍
我们知道Executor是一个JVM进程,在其内部有一个BlockManager用于管理该executor的一些数据。 Map端的task在往磁盘里写文件的时候,会通过BlockManager来维护底层的数据,同时也会将数据的元信息写入到Driver中。 下一个stage的task拉取数据的时候会从Driver获取拉取数据的元信息,找到executor并从BlockManager拉取属于自己的文件里的数据。如下:
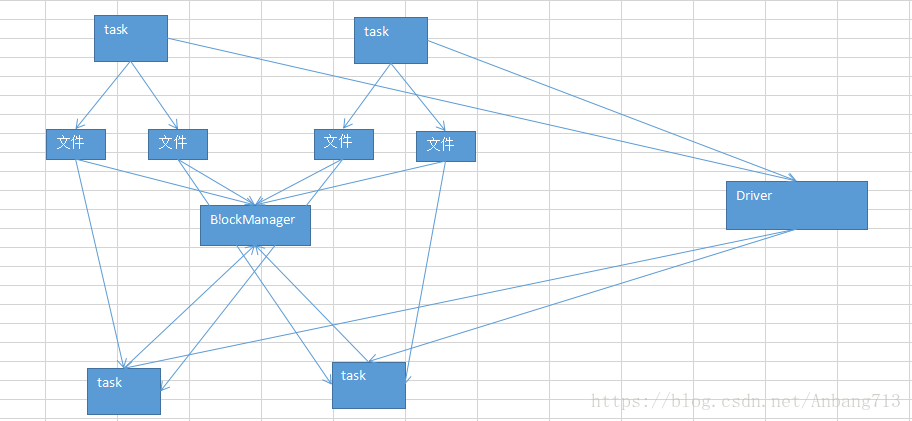
但是有时会出现的一种非常普遍的情况,在spark的作业中报shuffle file not found的异常。而且,它是偶尔才会出现的一种情况。有的时候,出现这种情况以后,会重新去提交stage、task。重新执行一遍发现就好了,没有这种错误了。
为什么会出现这种情况?我们知道executor是一个JVM进程,可能内存不是很够用了。那么此时可能就会执行GC(minor GC or full GC)。总之一旦发生了JVM之后,就会导致executor内所有的工作线程全部停止,比如BlockManager、基于netty的网络通信。那么此时下一个stage的executor可能还没有停止掉,task想要去上一个stage的task所在的exeuctor,去拉取属于自己的数据,结果由于对方正在gc,就导致拉取了半天没有拉取到。就很可能会报出:shuffle file not found。但是可能下一个stage又重新提交了stage或task以后,再执行就没有问题了,因为可能第二次就没有碰到JVM在gc了。
二、如何解决shuffle file not found异常?
2.1、spark.shuffle.io.maxRetries配置
该配置的意思是说,shuffle文件拉取的时候,如果没有拉取到(拉取失败),最多或重试几次(会重新拉取几次文件),默认是3次。
2.2、spark.shuffle.io.retryWait配置
该配置的意思是说,每一次重试拉取文件的时间间隔,默认是5s钟。默认情况下,假如说第一个stage的executor正在进行漫长的full gc。第二个stage的executor尝试去拉取文件,结果没有拉取到,默认情况下,会反复重试拉取3次,每次间隔是五秒钟。最多只会等待3 * 5s = 15s。如果15s内,没有拉取到shuffle file,就会报出shuffle file not found。
针对这种情况,我们完全可以进行预备性的参数调节。增大上述两个参数的值,达到比较大的一个值,尽量保证第二个stage的task一定能够拉取到上一个stage的输出文件,避免报shuffle file not found。然后可能会重新提交stage和task去执行。那样反而对性能也不好。
spark.shuffle.io.maxRetries 60
spark.shuffle.io.retryWait 60s 最多可以忍受1个小时没有拉取到shuffle file。只是去设置一个最大的可能的值,full gc不可能1个小时都没结束吧。
最后
以上就是耍酷画板最近收集整理的关于Spark项目实战-troubleshooting之解决JVM GC导致的shuffle文件拉取失败一、shuffle文件拉取失败的背景介绍二、如何解决shuffle file not found异常?的全部内容,更多相关Spark项目实战-troubleshooting之解决JVM内容请搜索靠谱客的其他文章。








发表评论 取消回复