本文将按照以下几点描述:
- 基本数据类型
- 字节序
- 数据对齐
- 指针检查
- 链表
基本数类型:
先看下面基本数据类型占用空间情况:
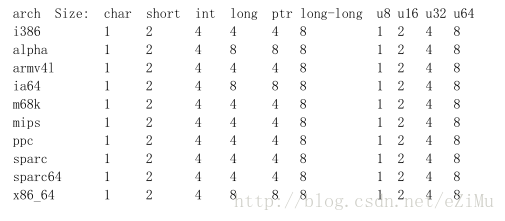
可以看出各体系CPU有差异,而使用u8,u16,u32,u64没有差异。
因此,我们在定义基本数据类型时,要比较清楚一个类型站有几个字节,尽量养成用内核定义的,类似u32这种符号。当然,sizeof()给定一个变量,就可以返回占用空间字节数。
在使用类似u32…的只需要包含头文件:
#include <linux/types.h>如在types.h里面定义的:
#ifndef __BIT_TYPES_DEFINED__
#define __BIT_TYPES_DEFINED__
typedef __u8 u_int8_t;
typedef __s8 int8_t;
typedef __u16 u_int16_t;
typedef __s16 int16_t;
typedef __u32 u_int32_t;
typedef __s32 int32_t;
#endif /* !(__BIT_TYPES_DEFINED__) */
typedef __u8 uint8_t;
typedef __u16 uint16_t;
typedef __u32 uint32_t;
#if defined(__GNUC__)
typedef __u64 uint64_t;
typedef __u64 u_int64_t;
typedef __s64 int64_t;
#endif或者int-ll64.h(被types.h包含进去了)
typedef signed char s8;
typedef unsigned char u8;
typedef signed short s16;
typedef unsigned short u16;
typedef signed int s32;
typedef unsigned int u32;
typedef signed long long s64;
typedef unsigned long long u64;以及:
typedef __u16 __bitwise __le16;//定义小端模式存储16位数据类型
typedef __u16 __bitwise __be16;//定义大端模式存储16位数据类型
typedef __u32 __bitwise __le32;//定义小端模式存储32位数据类型
typedef __u32 __bitwise __be32;//定义大端模式存储32位数据类型
typedef __u64 __bitwise __le64;//定义小端模式存储64位数据类型
typedef __u64 __bitwise __be64;//定义大端模式存储64位数据类型还有其他,详细看types.h文件。
字节序
字节序,就是指大端模式和小端模式。
当存取变量时,不知道是按照大端还是小端。那么我们先包含下面头文件:
#include <asm/byteorder.h>然后,有头文件声明的接口,如:
//将当前__u64转换成,小端模式的64位(不管当前__u64是大端还是小端)
#define __cpu_to_le64(x) ((__force __le64)(__u64)(x))
//将小端模式__le64转换成,当前__u64(不管当前__u64是大端还是小端)
#define __le64_to_cpu(x) ((__force __u64)(__le64)(x))
#define __cpu_to_le32(x) ((__force __le32)(__u32)(x))
#define __le32_to_cpu(x) ((__force __u32)(__le32)(x))
#define __cpu_to_le16(x) ((__force __le16)(__u16)(x))
#define __le16_to_cpu(x) ((__force __u16)(__le16)(x))
#define __cpu_to_be64(x) ((__force __be64)__swab64((x)))
#define __be64_to_cpu(x) __swab64((__force __u64)(__be64)(x))
#define __cpu_to_be32(x) ((__force __be32)__swab32((x)))
#define __be32_to_cpu(x) __swab32((__force __u32)(__be32)(x))
#define __cpu_to_be16(x) ((__force __be16)__swab16((x)))
#define __be16_to_cpu(x) __swab16((__force __u16)(__be16)(x))
__le64 __cpu_to_le64p(const __u64 *p);//变量地址做为参数,来转换值
__u64 __le64_to_cpup(const __le64 *p);
__le32 __cpu_to_le32p(const __u32 *p);
__u32 __le32_to_cpup(const __le32 *p);
__u32 __le32_to_cpup(const __le32 *p);
__le16 __cpu_to_le16p(const __u16 *p);
__u16 __le16_to_cpup(const __le16 *p);
__be64 __cpu_to_be64p(const __u64 *p);
__u64 __be64_to_cpup(const __be64 *p);
__be32 __cpu_to_be32p(const __u32 *p);
__u32 __be32_to_cpup(const __be32 *p);
__be16 __cpu_to_be16p(const __u16 *p);
__u16 __be16_to_cpup(const __be16 *p);数据对齐:
数据对齐,是指字节对齐,字对齐等。
linux提供访问各种数据对齐的统一接口。
用接口前,先包含头文件:
#include <linux/unaligned.h>接口:
get_unaligned(ptr);
put_unaligned(val, ptr);ptr是指针,
返回指针指向空间的值。
如果ptr指针是按照字节对齐的,当然返回的是一个byte。
如果ptr指针是按照字对齐的,当然返回的是字,即4个byte。
指针检查:
linux里面指针检查,对驱动来说,就是检查指针指向的数据地址,是否在内核空间。
有三个接口,先包含头文件:
#include <linux/err.h>接口:
void * __must_check ERR_PTR(long error);//error是错误码,返回错误码对应的错误地址
long __must_check PTR_ERR(const void *ptr);//ptr是错误地址,返回错误地址对应的错误码
long __must_check IS_ERR(const void *ptr);//ptr是地址,用来判断地址是否错误,错误返回1,没有错误返回0一般先用IS_ERR判断是否有错误(这里错误,是指是否为内核空间地址),然后用PTR_ERR返回错误码。如:
if(IS_ERR(P))
return PTR_ERR(P);错误码定义在include/linux/errno.h。
链表:
用linux链表前,包含头文件:
#include <linux/list.h>链表结构体:
struct list_head {
struct list_head *next, *prev;
};一些接口:
//在紧接着链表 head 后面增加新入口项
list_add(struct list_head *new, struct list_head *head);
//在给定链表头前面增加一个新入口项
list_add_tail(struct list_head *new, struct list_head *head);
//给定的项从队列中去除,如果还需要用entry,就用list_del_init。
list_del(struct list_head *entry);
list_del_init(struct list_head *entry);
//将list删除,然后加入到head后面
list_move(struct list_head *list, struct list_head *head);
//将list删除,然后加入到head前面
list_move_tail(struct list_head *list, struct list_head *head);
//判断head是否为空,为空返回1,不是返回0
list_empty(struct list_head *head);
//将 list 紧接在 head 之后来连接 2 个链表.
list_splice(struct list_head *list, struct list_head *head);
/*通过嵌入到结构体链表的地址(链表是结构体的一个成员),推算结构体首地址。list_entry其实也是用container_of来实现的*/
list_entry(struct list_head *ptr, type_of_struct, field_name);
//遍历整个链表。这个宏创建一个 for 循环, 执行一次, cursor 指向链表中的每个连续的入口项.
list_for_each(struct list_head *cursor, struct list_head *list);
//是list_for_each反方向的遍历
list_for_each_prev(struct list_head *cursor, struct list_head *list)
/*如果你的循环可能删除列表中的项, 使用这个版本. 它简单的存储列表 next 中下
一个项, 在循环的开始, 因此如果 cursor 指向的入口项被删除, 它不会被搞乱.list_for_each的安全版本*/
list_for_each_safe(struct list_head *cursor, struct list_head *next, struct
list_head *list)
//是list_entry和list_for_each的结合
list_for_each_entry(type *cursor, struct list_head *list, member)
//list_entry和list_for_each_safe的结合
list_for_each_entry_safe(type *cursor, type *next, struct list_head *list,
member)用好链表,将结构体联系在一起很方便,特别是list_entry,或者container_of。
使用链表前,先定义一个头,并初始化,然后其他链表链接上来,只要又这个头,连在上面的,用以上接口非常容易找到。
#define LIST_HEAD(name)
struct list_head name = LIST_HEAD_INIT(name)
void INIT_LIST_HEAD(struct list_head *list);最后
以上就是心灵美手机最近收集整理的关于linux驱动-内核中的数据类型的全部内容,更多相关linux驱动-内核中内容请搜索靠谱客的其他文章。








发表评论 取消回复