GC有两种模型:分带模型、分区模型。默认使用分带模型·
分带模型 常用垃圾回收器 6个分为3对(一般情况下)。
分带模型:把整个内存分成两个部分 新生代、 老年代

判断垃圾对象:
- 引用计数 有引用值向他 他就不是垃圾(循环引用,abc循环引用 会导致分不出那三个已经变成垃圾)
- 根可达算法 能找到的根的的
垃圾回收算法:
- 标记清除(内存碎片化)
- 拷贝(把空间一分为二,一直使用其中一半,把另一半用于前一班有用拷过来,浪费空间)
- 标记压缩(把有用的往前挪,压缩在最前面;效率最低)
垃圾回收器综合了三种算法;内存一分为二,新诞生的对象放在新生代,清除一次没有清到age加1,当到一定年龄转到老年代(一定年龄默认是15,但是 可以自己设置);
新生代又分为三个 伊甸园(eden)、survivor(幸存者)、survivor(幸存者);
年轻带用拷贝算法【一次垃圾回收会收掉大概90%,把有用的拷贝到survivor-1中把整个伊甸园拿掉,第二次gc时 伊甸园有用的就放到survivor2中,s-1有用的也放在s-2中,干掉伊甸园和s-1,第三次gc就把伊甸园有用的和s-2有用的放在s-1中,干掉其余】;
老年带用标记压缩 标记清除【老年代块要装满的时候继续拧一次标记压缩 标记清除 会产生STW(stop the world)现象】;
现在大多的生产环境JVM用的为1.8,默认的垃圾回收机器ps( Parallel
Scavenge)+po (Parallel Old)
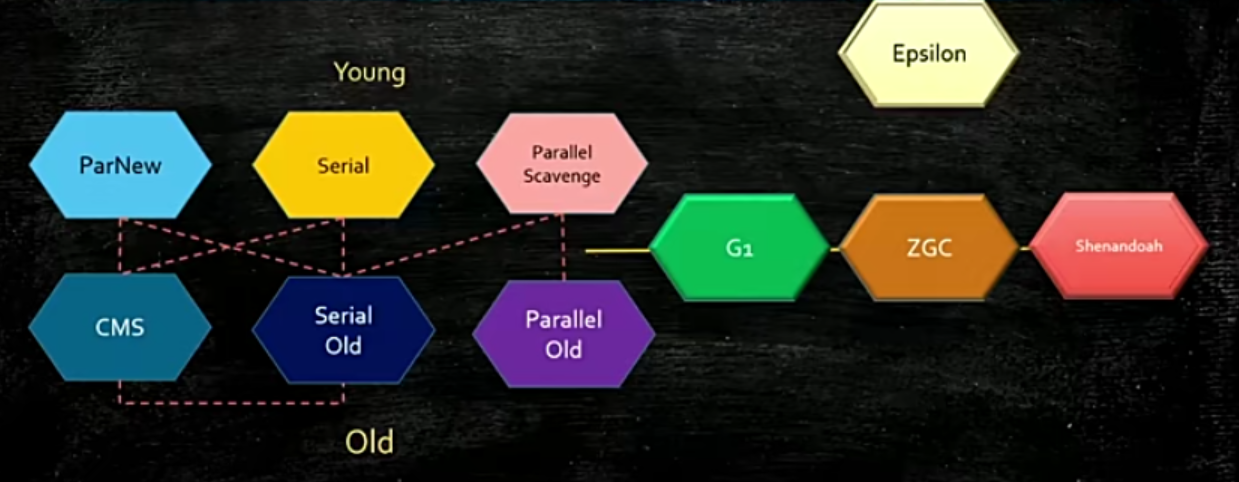
serial - serial old:会让工作的一直在工作,但是达到 垃圾回收的时候,就要停止工作这边的线程(被称为stop the world stw),然后进行垃圾回收的清理线程,这种方式为单线程的gc(随着业务的增多单线程的gc时间变长)
Parallel Scavenge - Parallel Old:在stw的时,增多了垃圾回收GC的线程(但并不是一个好的解决办法,线程数与工作效率并不是呈一个线性的增长,越多的线程数,cpu就会花时间处理切换线程上)
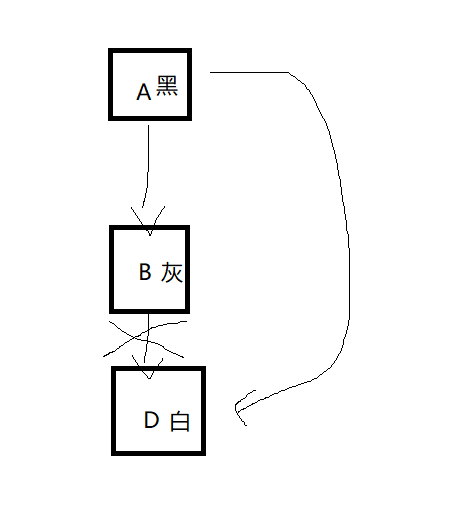
所以出来了CMS,这是不带STW的 工作线程和垃圾回收线程一起运行的垃圾回收机器,采用三色标记算法(用触达算法来对要回收的对象进行标记,但是存在一个很严重的bug),改进办法cms的remark阶段,必须从头扫描一遍,但是时间很慢效率低。
所以在java1.9默认的垃圾回收机制变成了G1
实战的jvm调优有以下几点:
1、根据需求进行jvm预调优
2、优化jvm的运行环境
3、解决jvm中的各种问题(OOM)
常用jvm调优工具:
1、linux自带命令 jdk 自带
2、arthas 阿里
3、图形界面远程
内存溢出可能产生的:
1、list 一只添加没有释放
2、分页取数据,但是一下子取出来
3、c++裁掉转java,错误比较多(java没找到析构函数,对finalize进行操作,减慢了gc的时间)
4、从数据库每3秒取拿100数据 放在线程池中,线程池有50个在运行,最后导致了OOM
最后
以上就是阳光发夹最近收集整理的关于关于GC的理解与整理的全部内容,更多相关关于GC内容请搜索靠谱客的其他文章。








发表评论 取消回复