GPU加速是深度学习最常用的操作之一。尤其在数量级较大时GPU的速度会远超CPU获得奇效。

比如我们拿i7-9970K和一个普通的GPU做一个简单的对比。各自生成一个10000乘10000的矩阵算一个伪逆,可以看到速度相差近7倍。
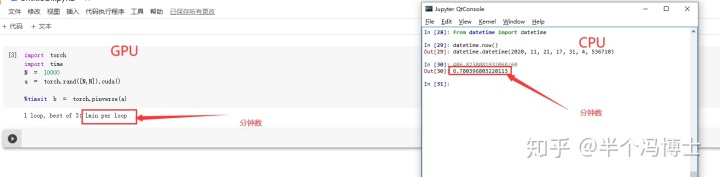
注意,这里咱们只用了一个非常普通的GPU,来自GOOGLE的COLAB。我们之前对比过这种设置下它的性能相比GTX 1070甚至RTX 2060都还略差一点。

从价格上看之前买的时候这个i7大概接近3000(某东价),而GTX 那时只有2000出头了。那么显然同价位GPU在做这种浮点运算时明显是优于CPU的。
不过对于多数新手,尤其是还没用惯GPU的同学而言,在刚开始用pytorch的cuda时总会有一个挺烦的事儿,那就是把CPU的代码迁移到GPU时,总会觉得挨个去改变量很麻烦。所以这里咱们介绍一点小技巧来处理一下这个问题。
首先要明确,要将模型迁移至CUDA需要做哪些事情
在pytorch上这个操作其实非常简单,就是在训练之前把所有需要用到的变量放入cuda,同时也将模型自身放到cuda即可。这个操作也很简单。

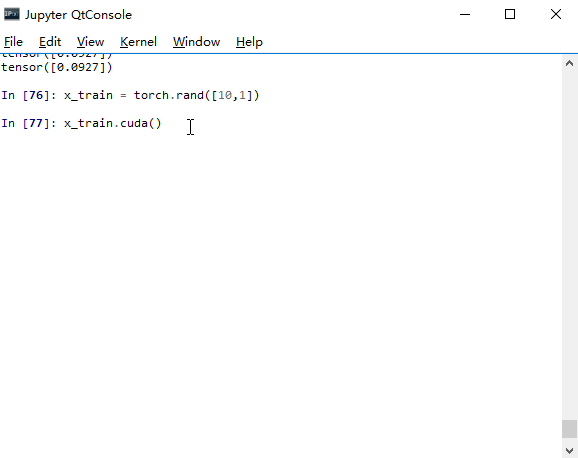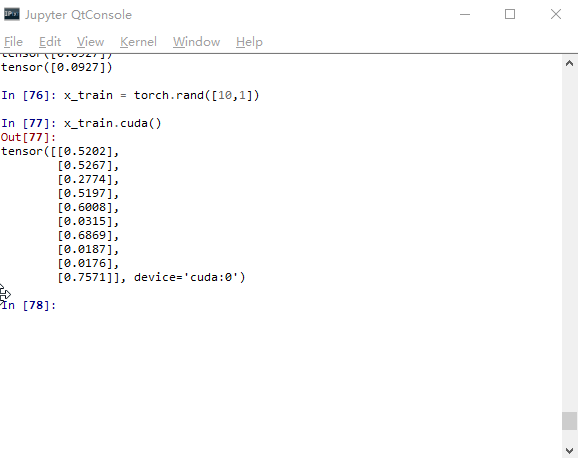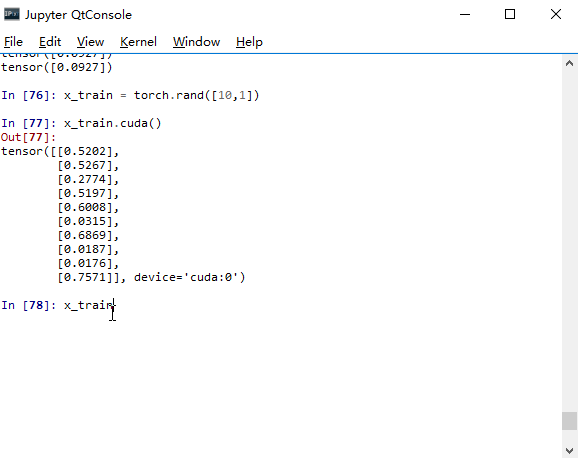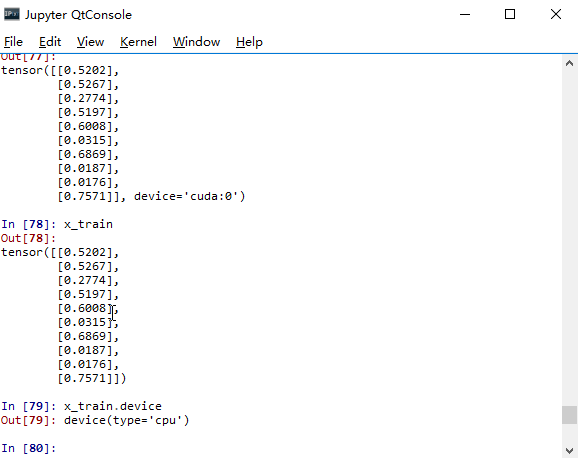
不过需要注意的是,模型的操作model.cuda()和 model = model.cuda()是等效的。但变量如果只用类似 x_train.cuda()的命令的话,变量本身仍然还是在CPU上。所以这时只能用 x_train = x_train.cuda()这样的命令才能将变量全放到GPU上。
这时通常有个很讨厌的事情。如果原来的程序是CPU版的,那么所有相关的变量都是在CPU上的变量,不仅包括训练数据集、测试集,还包括许多参数,那么这时又得把所有参数找到挨个去敲代码。所以这里咱们想个办法来尽量简化一下这个过程。
当涉及训练的参数全是tensor时
这个时候其实比较简单,我们直接利用python自带的函数locals()将现有的tensor全部找出来,然后统一做一次处理。比如我们这里先生成了5个随机的tensor,并把它们命名为 a, b, c, d, e 。
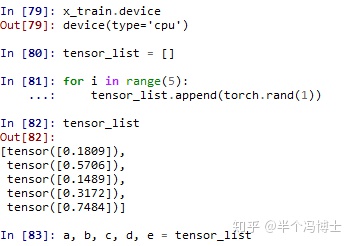
先用 dd = locals() 把所有的变量放入 dd 这个字典里面。由于它们的类型都是torch.tensor,因此我们写个简单的循环就可以把它们全部找出来:
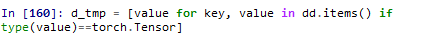
那么既然能把它们都找出来,就可以进行批量处理了。直接上面的代码里对第一个value使用一次 .cuda()就把所有tensor全部放到cuda上去了。
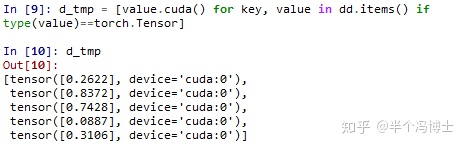
方便起见我们仍然用原来的变量名来接收这些值就可以了。这样做的目的是为了让后面所有代码都不再需要修改了。

当变量中存在一些不是tensor的变量时
这种变量通常是我们用到的一些参数,比如如果用了正则化,那么正则参数在CPU编程习题的话可能直接就是按照 r = 0.1 这样的形式给出的。此时就只好用r = torch.tensor(r) 这种命令来处理了。另外,这种参数通常不外乎int或者float,所以也可以用类似上面的方式将它们找出来再进行批量处理即可。
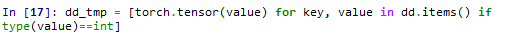
PS:之前我们试过采用动态变量的方式直接对现有变量真行赋值
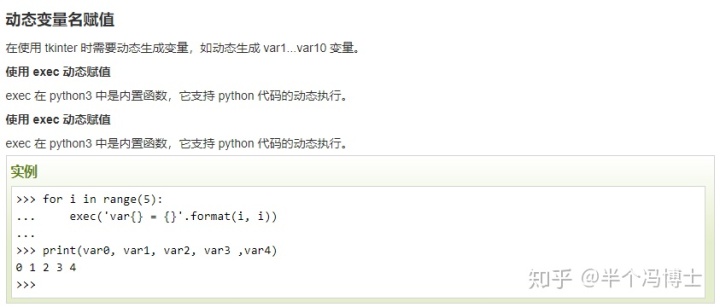
但这种方式不支持变量值为tensor类型,目前我们也没有找到更好的办法。如果各位有更好的解决方案,欢迎指教!~
关注我们获取更多有趣有用的内容:

最后
以上就是多情康乃馨最近收集整理的关于pytorch设置l2正则_如何在Pytorch中将变量批量放入GPU?的全部内容,更多相关pytorch设置l2正则_如何在Pytorch中将变量批量放入GPU内容请搜索靠谱客的其他文章。








发表评论 取消回复