文章目录
- ???? 写在前面
- 1.题目描述
- 2.算法设计思路
- ==思路一:纵向遍历==
- ==思路二:字符串按字典排序==
- 3.算法实现(思路一,C语言)
- 4.运行结果
- 结束语:
???? 写在前面
???? 该专栏作为算法题笔记,记录算法的思路、遇到的问题,以及能跑的代码,持续更新中!
???? 推荐一款面试、刷题神器牛客网:????开始刷题学习????
1.题目描述
描述
给你一个大小为 n 的字符串数组 strs ,其中包含n个字符串 , 编写一个函数来查找字符串数组中的最长公共前缀,返回这个公共前缀。
数据范围:
0
≤
n
≤
5000
0 le n le 5000
0≤n≤5000,
0
≤
l
e
n
(
s
t
r
s
i
)
≤
5000
0 le len(strs_i) le 5000
0≤len(strsi)≤5000
进阶:空间复杂度
O
(
1
)
O
(
1
)
O(1)O(1)
O(1)O(1),时间复杂度
O
(
n
∗
l
e
n
)
O
(
n
∗
l
e
n
)
O(n*len)O(n∗len)
O(n∗len)O(n∗len)
示例
输入:[“abca”,“abc”,“abca”,“abc”,“abcc”]
输出"abc"
2.算法设计思路
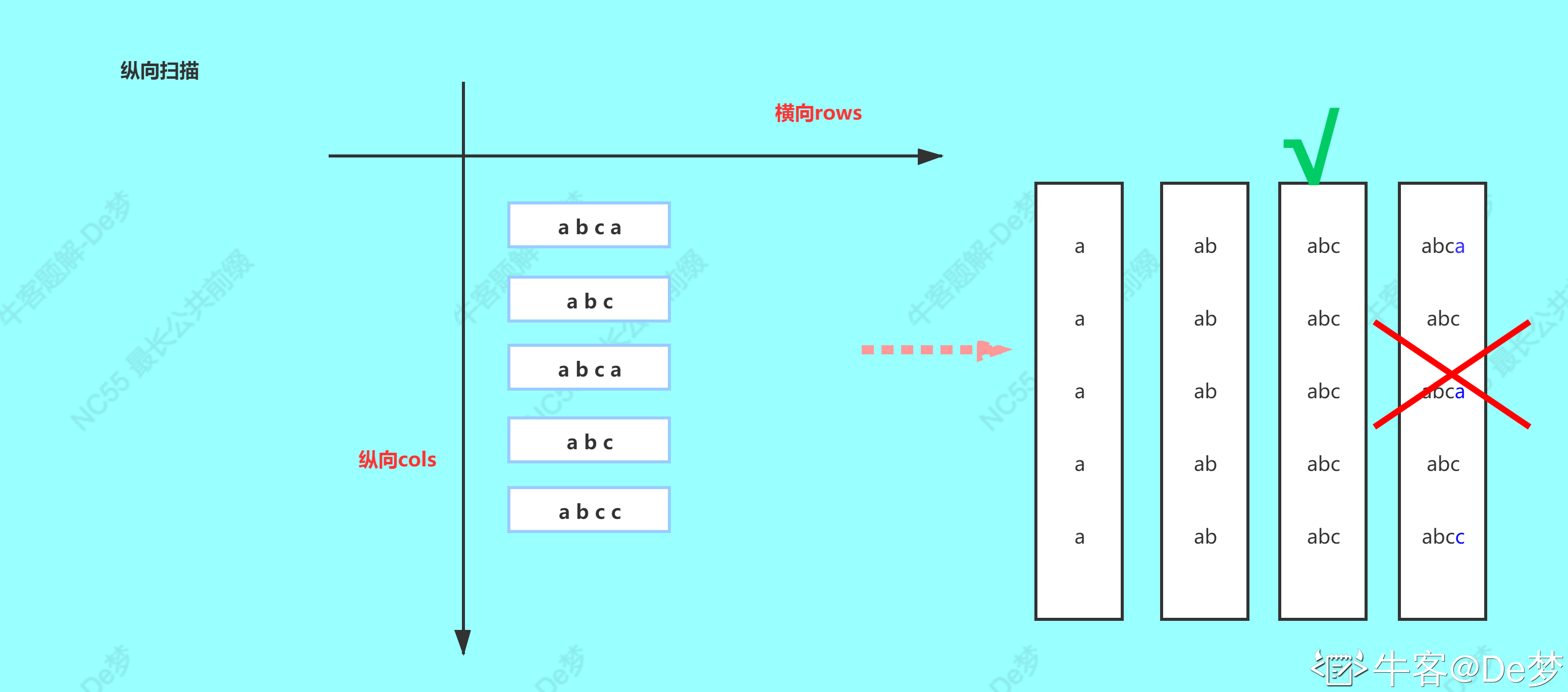
思路一:纵向遍历
我一开始对这题毫无头绪,怎么办呢?看题解呗!发现了一个纵向遍历的思路挺好。
时间复杂度:
O
(
n
∗
l
e
n
)
Omicron(n*len)
O(n∗len),n 为字符串的数量,len 为字符串的平均长度。
图片来自:题解 | 最长公共前缀
思路二:字符串按字典排序
后面我又发现了一个挺新奇的思路,来自:题解 | #最长公共前缀#
- 将字符串按字典顺序进行排序
- 比较排序后的第一个字符串和最后一个字符串,它们的最长公共前缀即为所有字符串的最长公共前缀
我花了好一会儿才勉强意会这个思路,为什么别人可以这么聪明?
他提出时间复杂度为: O ( n ∗ l o g ( n ) ) Omicron(n*log(n)) O(n∗log(n)),n 为字符串的数量。我后面发现还是有问题的,因为排序就要对字符串进行比较,而字符串本身有长度,每次比较都是在对两个字符串进行遍历。
因此,时间复杂度应为: O ( n ∗ l o g ( n ) ∗ l e n ) Omicron(n*log(n)*len) O(n∗log(n)∗len),n 为字符串的数量,len 为字符串的平均长度。
3.算法实现(思路一,C语言)
/**
* @param strs string字符串一维数组
* @param strsLen int strs数组长度
* @return string字符串
*/
char* longestCommonPrefix(char** strs, int strsLen ) {
if(strsLen == 0){return "";}
char* str_all = (char*)malloc(5000*sizeof(char));//公共前缀
int it = 0;//str_all的迭代器
// write code here
for(int j = 0; ; j++){
if(strs[0][j] == '�'){break;}//发现空串
char ch = strs[0][j];
bool flag = false;//为true时,结束循环
for(int i = 0; i < strsLen; i++){
if(ch != strs[i][j]){
flag = true;
break;}
ch = strs[i][j];
}
if(flag){break;}
str_all[it++] = ch;
}
str_all[it] = '�';//遇到 bug,返回的字符串尾部出现乱七八糟的字符
return str_all;
}
4.运行结果
成功通过!
结束语:
今天的分享就到这里啦,快来一起刷题叭!
????开始刷题学习????
个人主页:CSDN清风莫追
最后
以上就是灵巧未来最近收集整理的关于【牛客-算法】NC55 最长公共前缀???? 写在前面1.题目描述2.算法设计思路3.算法实现(思路一,C语言)4.运行结果结束语:的全部内容,更多相关【牛客-算法】NC55内容请搜索靠谱客的其他文章。








发表评论 取消回复