文章目录
- 24.1 数据通信量
- 24.1.1 通信量描述符
- 1. 平均数据速率
- 2. 峰值数据速率
- 3. 最大突发长度
- 4. 有效带宽
- 24.1.2 通信量特征值
- 1. 恒定比特率
- 2. 可变比特率
- 3. 突发性数据
- 24.2 拥塞
- 24.3 拥塞控制
- 24.3.1 开环拥塞控制
- 1. 重传策略
- 2. 窗口策略
- 3. 确认策略
- 4. 丢弃策略
- 5. 许可策略
- 24.3.2 闭环拥塞控制
- 1. 背压
- 2. 抑制分组
- 3. 隐含信令
- 4. 显式信令
- 24.4 两个示例
- 24.4.1 TCP中的拥塞控制
- 1. 拥塞窗口
- 2. 拥塞策略
- (1) 慢速启动:指数增长
- (2) 拥塞避免:加性增加
- (3) 拥塞检测:乘性减少
- (4) 总结
- 24.4.2 帧中继中的拥塞控制
- 24.5 服务质量
- 24.5.1 数据流特性
- 1. 可靠性
- 2. 延迟
- 3. 抖动
- 4. 带宽
- 24.5.2 数据流类型
- 24.6 改进QoS的技术
- 24.6.1 调度
- 1. 先进先出队列
- 2. 优先权队列
- 3. 加权公平队列
- 24.6.2 通信量整形
- 1. 漏桶
- 2. 令牌桶
- 3. 令牌桶和漏桶的结合使用
- 24.6.3 资源预留
- 24.6.4 许可控制
- 24.7 综合业务
- 24.7.1 信令
- 24.7.2 数据流规范
- 24.7.3 许可
- 24.7.4 业务类型
- 24.7.5 RSVP
- 1. 多播树
- 2. 基于接收方的预留
- 3. RSVP报文
- 4. 预留合并
- 5. 预留方式
- 24.7.6 综合业务所存在的问题
- 24.8 差分业务
- 1. DS字段
- 2. 逐跳行为
- 3. 通信量调节器
- 24.9 交换网络中的QoS
- 24.9.1 帧中继中的QoS
- 1. 访问速率
- 2. 提交突发业务量
- 3. 提交信息速率
- 4. 超突发长度
- 5. 用户速率
- 24.9.2 ATM 中的QoS
- 1. 类
- 2. 用户相关属性
- 3. 网络相关属性
拥塞控制和服务质量 congestion control and quality of service 是紧密联系在一起的两个问题:改进了其中的一个问题,则另一个问题也会有所改善;忽视了其中的一个问题,则通常意味着另一个也被忽视。在一个网络中,大多数防止或消除拥塞的技术,也能改进网络的服务质量。
之所以推迟到现在才讨论这些问题,是因为这些问题不止涉及到一层,而是涉及到三层:数据链路层、网络层和传输层。而且现在才讨论它们,也是为了能一次性地对这些问题做集中探讨、而不需要多次讨论同一主题。这里也给出了一些不同层中的拥塞控制和服务质量的示例。
24.1 数据通信量
对拥塞控制和服务质量要关注的重要方面是数据通信量 data traffic 。在拥塞控制中,要设法避免通信量拥塞;在服务质量中,要设法为通信量创造合理的环境。因此,在讨论拥塞控制和服务质量之前,首先讨论数据通信量本身。
24.1.1 通信量描述符
通信量描述符 traffic descriptors 是描述数据流的定性值。图24.1用这些值描述了通信量。
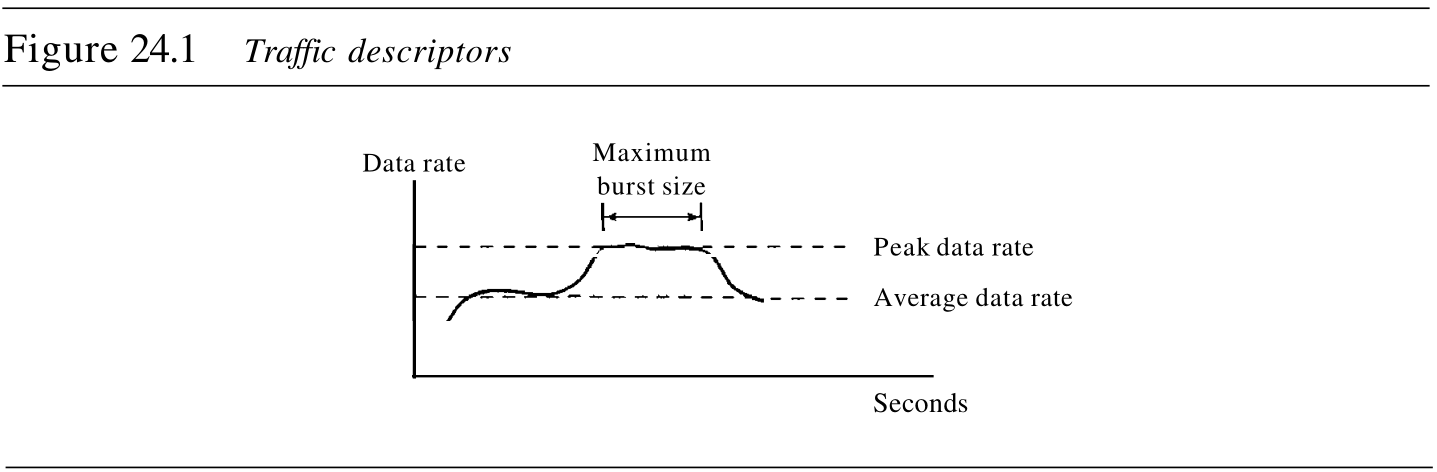
1. 平均数据速率
平均数据速率 average data rate 是在一段时间内发送的数据位数除以该时段所含的秒数。我们使用如下的等式:
Average data rate
=
amount of data
time
textrm{Average data rate} = dfrac{ textrm {amount of data} }{ textrm{time} }
Average data rate=timeamount of data
平均数据速率是通信量的一个非常有用的特性,因为它表明通信量所需要的平均带宽。
2. 峰值数据速率
峰值数据速率 peak data rate 定义了通信量的最大数据速率,如图24.1所示,它是
y
y
y 轴方向上的最大值。峰值数据速率是一个很重要的概念,因为它表明让通信量通过网络、且无须改变数据流的情况下,网络所需的峰值带宽。
3. 最大突发长度
虽然峰值数据速率是很关键的,但是如果峰值持续时间很短,那么它通常可忽略不计。例如,如果数据正
1
Mbps
1textrm{Mbps}
1Mbps 的速率稳定地传送,而突然以
2
Mbps
2textrm{Mbps}
2Mbps 的峰值数据率传送了
1
ms
1textrm{ms}
1ms ,网络也许可以处理这种情况。但是如果峰值速率持续
60
ms
60textrm{ms}
60ms ,那么网络可能会出问题。最大突发长度 maximum burst size 一般是指以峰值速率传输通信量的最大时间长度 the maximum length of time the traffic is generated at the peak rate 。
4. 有效带宽
有效带宽 effective bandwidth 是指网络需要分配给通信流的带宽。有效带宽是三个值的函数:平均数据速率、峰值数据速率和最大突发长度。有效带宽的计算过程非常复杂。
24.1.2 通信量特征值
根据需要,数据流可以用以下通信量特征值 traffic profiles 之一来表述:恒定比特率、可变比特率或突发性。如图24.2所示。
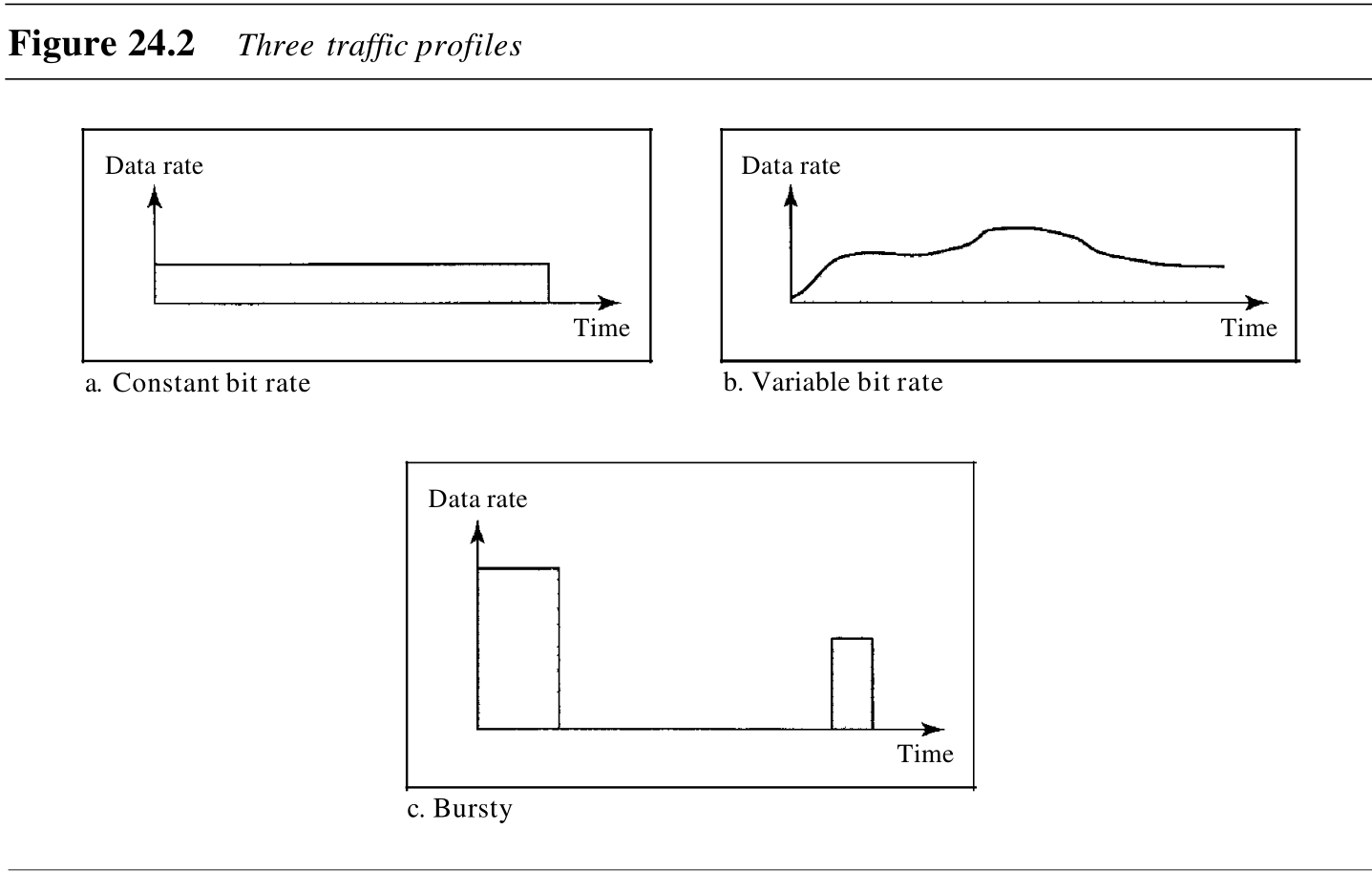
1. 恒定比特率
在恒定比特率 constant-bit-rate, CBR 或固定速率的通信量模型中,具有恒定不变的数据速率。在这种类型的流中,平均数据速率和峰值数据速率是相同的,最大突发长度是无效的。对于一个网络而言,这种类型的通信量是可预知的,因而很容易处理。网络可以提前知道,要分配多少带宽给这种类型的流。
2. 可变比特率
在可变比特率 variable-bit-rate, VBR 类型中,数据流的速率随时间发生平滑的、而非突然的或急剧的变化。在这种类型的流中,平均数据速率和峰值数据速率是不同的。最大突发长度通常是一个很小的值。与恒定比特率的通信量相比,这种类型的通信量更难处理,但是它一般不需要重新整形,这将在后面可以看到。
3. 突发性数据
突发性数据 bursty data 是指在很短的时间内数据速率突然发生了变化。例如,它可能在几微秒内从零猛增到
1
Mbps
1textrm{Mbps}
1Mbps ,或从
1
Mbps
1textrm{Mbps}
1Mbps 猛降为零。它也可能在这个值上保持一会儿。在这种类型的数据流中,平均比特率和峰值比特率非常不同,最大突发长度非常重要。对于网络,这是最难处理的一种通信量类型,因为其特征值是不可预知的。为了处理这种类型的通信量,网络通常需要使用重新整形技术 reshaping techniques ,对其进行重新整形。这种技术稍后将会看到。突发性通信量是网络中发生拥塞的主要原因之一。
24.2 拥塞
拥塞 congestion 是分组交换网络 packet-switched network 中的一个重要问题。如果网络中的载荷 load(发送到网络中的分组数量),超过了网络的容量 capacity(网络中能处理的分组数量),那么在网络中就可能发生拥塞。拥塞控制 congestion control 指的是控制拥塞、使载荷低于网络容量的机制和技术。
为什么在网络中会发生拥塞?事实上,拥塞可能发生在任何涉及等待机制的系统之中 Congestion happens in any system that involves waiting 。例如,发生在高速公路上的拥塞是因为车流的某些异常,如在高峰期的事故,可能造成交通阻塞。在网络或者互联网络中也会发生拥塞,这是因为路由器和交换机中存在队列——在处理前、后保存分组的缓冲区。例如,路由器的每个接口中,都有输入队列和输出队列。当分组到达输入接口时,在将其转发前要经历三个步骤,如图24.3所示。
- 在等待检验时,将分组置于输入队列的尾部。
- 一旦分组到达了队列的前端,路由器的处理模块就将其从输入队列中移除,并运用路由表和目的地址来查找其路由。
- 将分组置于适当的输出队列中,等待发送。
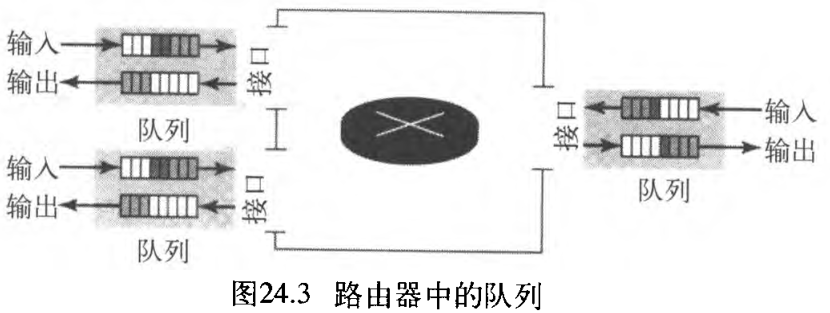
这里需要注意两个问题。第一 ,如果分组的到达速率高于分组的处理速率,那么输入列会变得越来越长。第二,如果分组的转发速率低于分组的处理速率,输出队列也会变得越来越长。
拥塞控制包括了两个测试网络性能的要素:延迟 delay 和吞吐量 throughput 。图24.4说明了作为载荷函数的这两个性能度量。
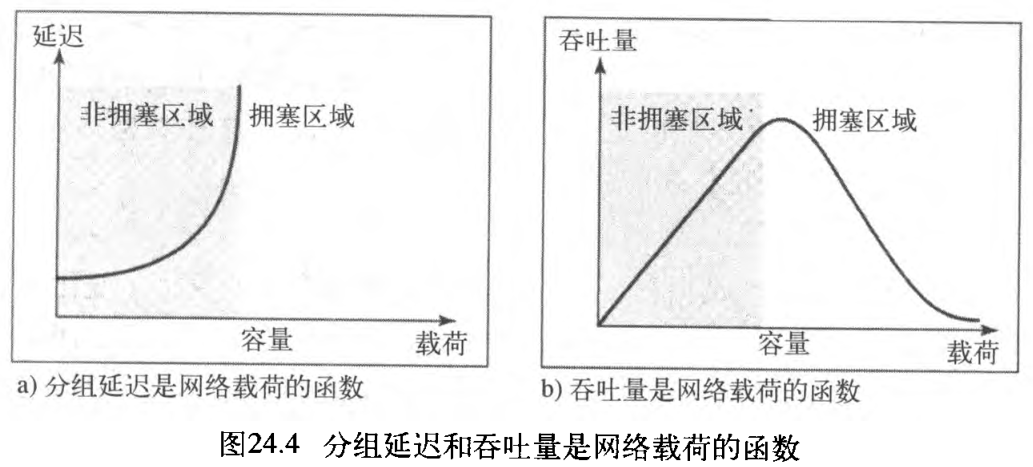
- 延迟和载荷:注意,当载荷比网络容量小得多时,延迟
delay最小。最小延迟是由传播延迟和处理延迟所组成的,并且它们都可以忽略不计。然而,当载荷达到网络容量时,延迟就会急剧增加,因为我们现在需要将 队列中的等待时间(对于路径中的所有路由器) 添加到总延迟中。注意,当载荷大于网络容量时,延迟会变为无穷大。
如果这还不能说明问题,请考虑一下,在「几乎没有分组到达目的端」或「经过无穷大的延迟到达目的端」时队列的长度,此时队列变得越来越长。延迟会加重载荷,并因此会导致拥塞现象发生。当分组被延迟时,源端就会在没有收到确认的情况下重发分组,这个过程则会加重延迟和拥塞。 - 吞吐量和载荷:在【计算机网络】第二部分 物理层和介质(3) 数据和信号中,将吞吐量定义为在
1
1
1 秒内通过一个节点的位数。可以将位换成分组、将节点换成网络,从而扩展这个定义,将网络吞吐量
throughput定义为单位时间内通过网络的分组数量。
注意,当载荷小于网络容量时,吞吐量随载荷的增加成比例地增长。当载荷达到网络容量后,期望吞吐量保持恒定。但是实际情况恰好相反,吞吐量会急剧下降。原因是路由器丢弃了分组。当载荷超过网络容量时,队列饱和了,此时路由器不得不丢弃一些分组。丢弃分组并不能减少网络中分组的数量,因为当分组没有到达目的端时,源端就运用超时机制重发它们。
24.3 拥塞控制
拥塞控制是指在拥塞发生之前预防拥塞、或在拥塞发生之后消除拥塞的技术和机制。通常,我们把拥塞控制分为两大类:开环拥塞控制(预防)和闭坏拥塞控制(消除)。如图24.5所示。
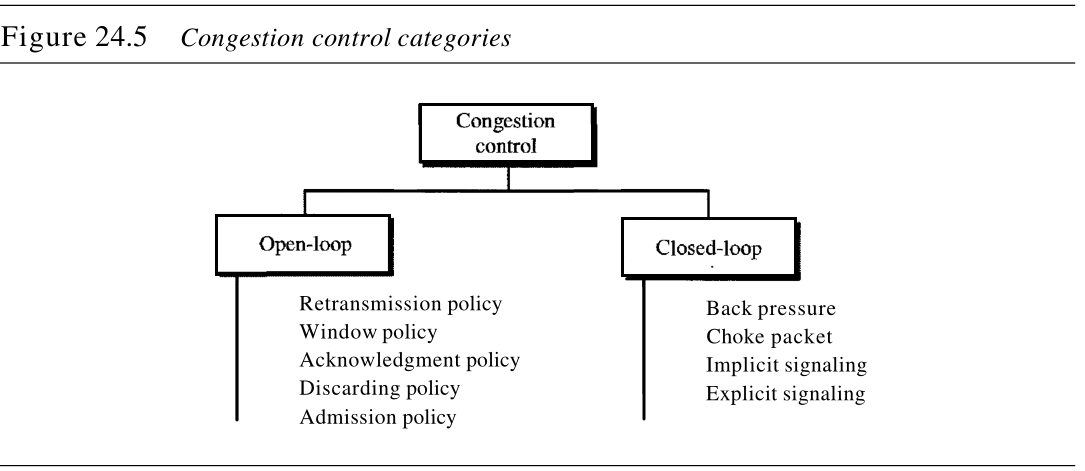
24.3.1 开环拥塞控制
在开环拥塞控制 open-loop congestion control 中,在拥塞发生之前,应用某种策略来预防拥塞现象的发生。在这些机制中,源端或目的端都可以处理拥塞控制。下面简要列出能预防拥塞的几种策略。
1. 重传策略
有时重发是不可避免的。如果发送方认为一个发送分组丢失或损坏,则该分组就需要重发。重发一般在网络上会增加拥塞现象,然而一个好的重传策略 retransmission policy 能预防拥塞,必须优化设计重传策略和重传定时器,使之具有高效率,并用来预防拥塞。例如,TCP所用的重传策略被设计用来防止和减轻拥塞。
2. 窗口策略
发送方窗口的类型也会影响拥塞。对拥塞控制而言,选择性重复窗口 Selective Repeat window 要优于回退N帧窗口 Go-Back-N window。在回退N帧窗口中,当一个分组的计时器到时,可以重发多个分组,尽管其中一些分组可能已安全与可靠地到达接收方,但这种重复会使拥塞更加严重。而选择性重复窗口试图发送那些被丢失或损坏的特定分组。
3. 确认策略
接收方使用的确认策略 acknowledgment policy 也可能影响拥塞。
- 如果接收方并不对它所接收的每一个分组进行确认,则它会使发送方放慢发送速度,从而有助于预防拥塞。有些协议就是采用这种办法。
- 接收方有一个要发送的分组或一个特定的计时器到时,接收方才发送一个确认。
- 接收端可以决定每次对 N N N 个分组仅发送一个确认。
我们要知道确认也是网络中负载的一个部分,发送确认越少意味着网络的负载 load 越轻。
4. 丢弃策略
路由器使用好的丢弃策略 discarding policy 可以预防拥塞,同时不破坏传输的完整性。例如,在声音传输中,如果在可能发生拥塞时丢弃那些不敏感的分组,则仍可保证声音的质量,并且还能预防或减轻拥塞现象的发生。
5. 许可策略
在虚电路网络 virtual-circuit networks 中,许可策略 admission policy 是一种服务质量机制,也能预防拥塞。在允许数据流进入网络之前,与数据流通路相连的交换机首先检查其资源需求,如果网络有拥塞或可能出现拥塞,路由器将拒绝建立虚电路。
24.3.2 闭环拥塞控制
在拥塞发生之后,采用闭环拥塞控制 closed-loop congestion control 可以缓解拥塞状况。不同的协议采用了多种机制,下面对这几种机制进行介绍。
1. 背压
背压 backpressure 技术是一种拥塞控制机制。在这种技术中,一个拥塞点停止接收来自直接上行节点、或一些近邻节点的数据。这会引起上行节点或一些近邻节点发生拥塞,它们依此拒绝它们的上行节点或一些近邻节点的数据,依此类推。
背压是点到点拥塞控制,它从一点开始,然后传播,沿着数据流反方向到达源端。背压技术仅用于虚电路网络——在虚电路网络中,每个节知道数据的流是来自它的上行节点。图24.6表示了背压的思想。
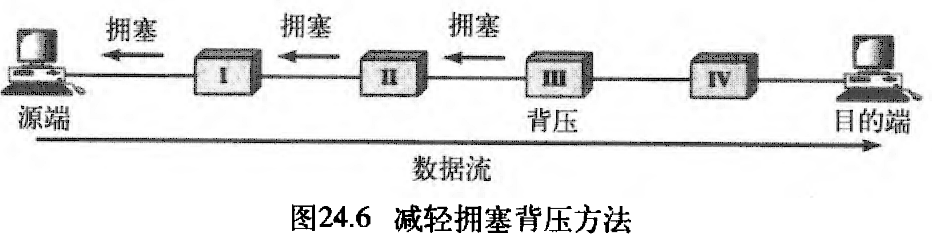
在图24.6中,节点 III 有了超出它处理能力的输入数据,它停止将某些分组放入输入缓存区中,并通知节点 II 降低传输速率。节点 II 由于降低输出数据流的速率,可能会拥塞。如果节点 II 拥塞,则它通知节点 I 降低传输速率,它也可能会形成拥塞。如果是如此,则节点 I 通知源端降低数据传输速率。这样可以及时减轻拥塞。注意:为了消除阻塞,对节点 III 的压力反向移动到摞端。
我们讨论过的 一些虚电路网络不使用背压策略。但是,在第一个虚电路网络X.25,使用过这策略。这种技术在数据报网络不可能实现,因为在这种类型的网络中,一个节点(路由器)没有关于上行节点的知识。
2. 抑制分组
抑制分组 choke packet 是一个分组,该分组由节点发送给源端,通知它发生拥塞的情况。注意背压和抑制分组方法的不同:
- 在背压方法中,警告从一个节点到它的上行节点,虽然警告可能最后到达源端。
- 在抑制分组方法中,警告从已经发生拥塞的路由器直接传到源端,该分组经过的那些中间节点没被警告。
在ICMP中已看到过这种控制类型。当因特网中一个路由器被大量的IP数据报淹没时,它可能丢弃一些数据报,但它使用一个ICMP源站抑制报文通告源主机。警告报文直接发送给源站点,中间的路由器不进行任何处理。图24 .7表示抑制分组的思想。
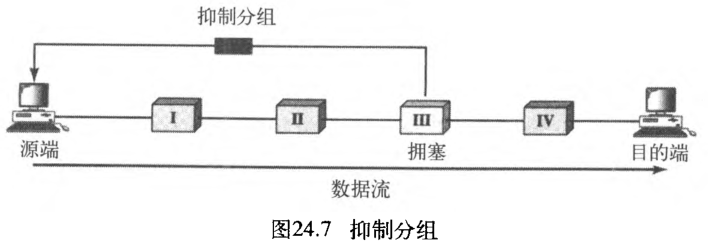
3. 隐含信令
在隐含信令 implicit signaling 中,拥塞节点或节点们 the congested node or nodes 与源端之间没有通信。源端能从其他有关征兆中,察觉出在网络某处有拥塞。例如,当源端发送多个分组,暂时还没有收到确认时,一种设想是网络发生了拥塞。在接收确认过程中发生的延迟现象,就可以认为网络发生了拥塞:源端应该降低发送速率。在后面讨论TCP拥塞控制时,将看到这种类型的信令。
4. 显式信令
发生拥塞的节点能发送一种显式信令 explicit signaling 通知源端或目的端发生了拥塞。但是,显式信令方法与抑制分组方法是不同的:
- 在抑制分组方法中,有一个单独的分组用于此目的;
- 而在显式信令方法中,信号包含在携带数据的分组中。
就像在帧中继拥塞控制中所看到的那样,显式信令也具有前向或后向特征。
- 后向信令
backward signaling:将一个位设置在分组中,并使之向与拥塞发生方向相反的方向移动。该位提示源端网络发生了拥塞,并提示它需要放慢发送速度,以避免分组的丢失。 - 前向信令
forward signaling:将一个位设置在分组中,并使之向发生拥塞的方向移动。该位提示目的端网络发生了拥塞。在此情况下,接收端能使用诸如「放慢确认发送速度的策略」来减轻拥塞。
24.4 两个示例
为了更好地理解拥塞控制的概念,我们举两个例子:一个是TCP中的拥塞控制(重传、窗口、确认、隐含信令),另一个是帧中继中的拥塞控制(显式信令)。
24.4.1 TCP中的拥塞控制
在【计算机网络】第五部分 传输层(23) UDP、TCP和SCTP中已讨论过TCP,现在说明TCP如何利用阻塞控制,避免或减轻网络中的拥塞。
1. 拥塞窗口
在(23) UDP、TCP和SCTP中,曾提到过流量控制,并试图讨论「如何解决接收方由于大量数据的到来而陷入瘫痪」的情况。须知,发送方窗口大小取决于接收方可用的缓冲空间 rwnd ,即假设只有接收方能够规定发送方的发送方窗口大小。在这里完全忽视了另一个实体——网络。如果网络无法以发送方创建的速度传递数据,它必须告诉发送方减慢发送速率。也就是说,除了接收方之外,网络应当是确定发送方窗口大小的第二个实体。
现在,发送方窗口大小不仅取决于接收方,而且还取决于网络拥塞的情况。发送方有两种信息:接收方通告的窗口大小 receiver-advertised window, rwnd 和拥塞窗口大小 congestion window, cwnd ,实际的窗口大小是这两者中的最小者(实际的窗口大小 = min(rwnd, cwnd))。我们简要说明如何确定拥塞窗口大小。
2. 拥塞策略
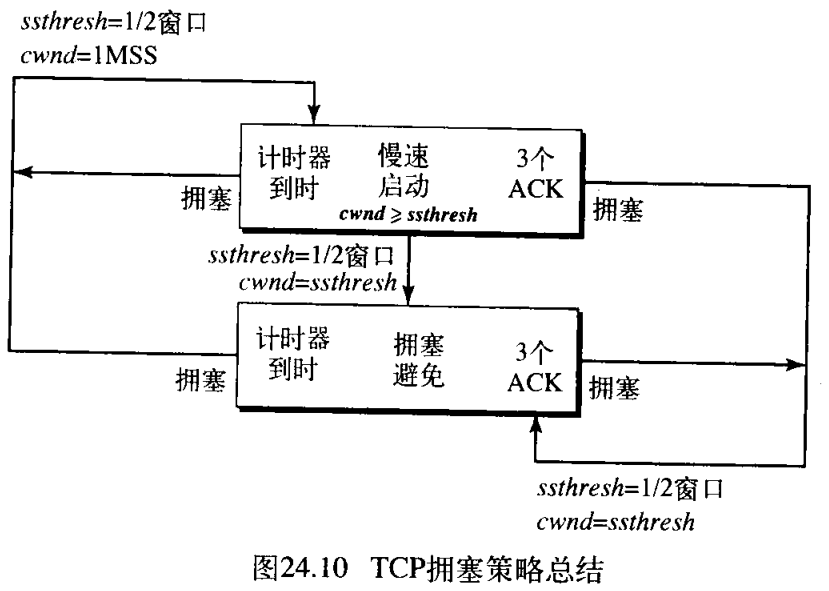
TCP处理拥塞的一般策略基于三个阶段:慢速启动(指数增长)、拥塞避免(加性增加)和拥塞检测(乘性减少)。在慢速启动阶段,发送方用很慢的传输速率开始,但迅速地增加到阈值 threshold 。在达到阈值时,为了避免拥塞而降低数据速率。最后,如果检测到拥塞,则发送方根据检测到拥塞的方式,返回慢启动或拥塞避免阶段 the sender goes back to the slow-start or congestion avoidance phase based on how the congestion is detected 。
(1) 慢速启动:指数增长
TCP拥塞控制所使用的一种算法称为慢速启动 Slow Start: Exponential increase 。这种算法也是基于「拥塞窗口的大小 cwnd 从一个最大段长度MSS开始」的思想。MSS是在连接建立期间,由「相同名称的选项 an option of the same name 」所确定的(最大段长度选项)。每次接收到一个确认时,窗口大小增加一个MSS值。正如其名,窗口是慢速启动,但是按指数规则增长的。
为了说明这个思想,让我们观察图24.8。注意:为了使讨论更清晰,这里进行了三个简化。使用段的个数而不是字节的个数(好像每段仅有一个字节);假定 rwnd 比 cwnd 大得多,这样发送方窗口大小永远等于 cwnd ;还假定每段都是单独进行确认。
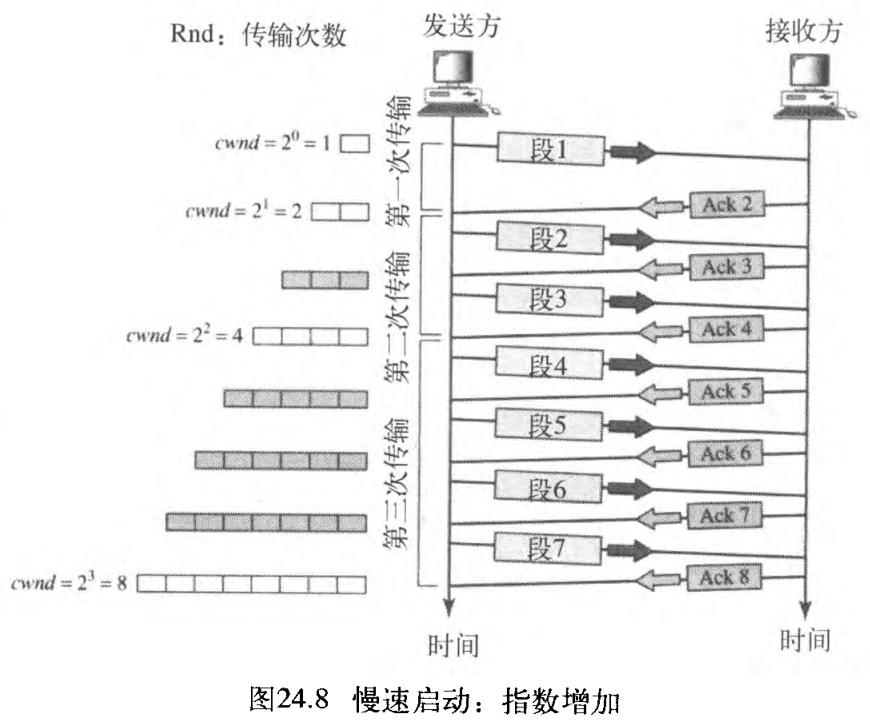
- 发送方以
cwnd= 1MSS开始,这意味着发送方仅能发送一个段。 - 接收到段
1
1
1 的确认后,拥塞窗口增加
1
1
1 ,
cwnd是 2 2 2 。这意味着现在可发送另外两个段。当接收到每一个确认时,窗口大小都增加1MSS。 - 接收到段
2
,
3
2, 3
2,3 的确认后,拥塞窗口增加
2
2
2 ,
cwnd是 4 4 4 。这意味着现在可发送另外四个段。 - 接收到段
4
,
5
,
6
,
7
4, 5, 6, 7
4,5,6,7 的确认后,拥塞窗口增加
4
4
4 ,
cwnd是 8 8 8 。这意味着现在可发送另外八个段。 - 当所有
7
7
7 个段都被确认时,
cwnd = 8MSS。
如果我们按照(整个窗口中的所有段被确认的)传输次数观察 cwnd 的大小,则发现其速率是按指数规律增长如下所示:
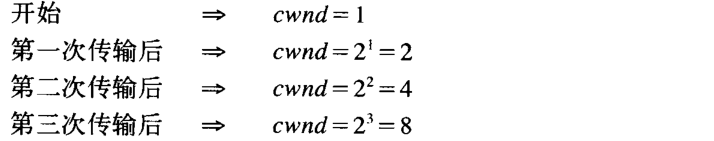
需要指出的是,如果有被延迟的 ACK ,则窗口大小的增长小于
2
2
2 的幂 if there is delayed ACKs, the increase in the size of the window is less than power of 2 。
慢速启动不能一直继续下去,拥塞窗口大小按指数规律增长,直到到达阈值,就必须停止该阶段。发送方保存一个称为慢速启动阈值 slow-start threshold, ssthresh 的变量,当「拥塞窗口中的字节(这里简化为段数)」达到这个阈值时,慢速启动阶段结束、而下一个阶段开始。在大多数实现中,ssthresh 一直是
65535
65535
65535 字节。
(2) 拥塞避免:加性增加
如果我们以慢速启动算法开始,则拥塞窗口大小按指数规律增长。为了在拥塞发生之前避免拥塞,必须降低指数增长的速度。TCP定义了另一个算法,称为拥塞避免 congestion avoidance ,这个算法是加性增加 additive increase 、而非指数增加。当拥塞窗口的大小达到慢速启动的阈值时,慢速启动阶段停止,加性增加阶段开始。
在这个算法中,每次整个窗口所有段都被确认(一次传输)时,拥塞窗口才增加
1
1
1 。为了说明这个概念,将这个算法应用到与慢速启动相同的情况中,尽管我们将看到,拥塞避免算法通常在窗口的大小远远大于
1
1
1 时启动 the congestion avoidance algorithm usually starts when the size of the window is much greater than 1 。图24.9表示这个思想。在这种情况下,发送方接收到「对一个完整窗口大小段的那些确认」后,窗口大小才增加一个段。即在拥塞避免算法中,拥塞窗口大小是加性增加的,直到检测到拥塞。
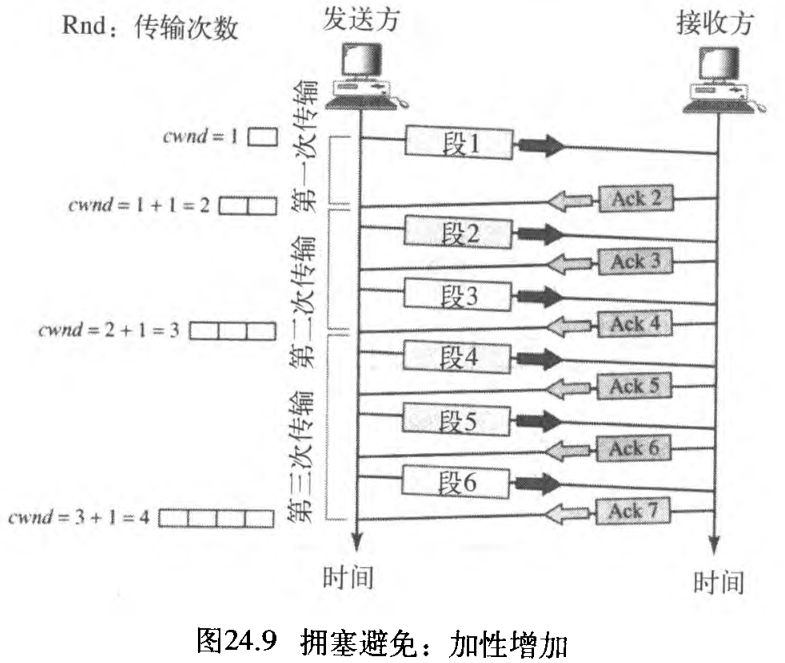
如果我们按照传输次数观察 çwnd 的大小,则发现其速率是按加性规律增长,如下所示:
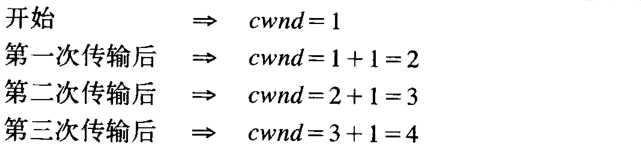
(3) 拥塞检测:乘性减少
如果发生拥塞,拥塞窗口的大小必须减小。发送方能推测出发生拥塞现象的唯一方法,是需要重传段 The only way the sender can guess that congestion has occurred is by the need to retransmit a segment 。可是重传是在两种情况下发生:重传计时器到时或接收到了三个 ACK 。在这两种情况下,阈值就下降一半,即乘性减少 multiplicative decrease 。大多数TCP实现包含两个反应:
- 如果计时器到时,那么存在着非常严重的拥塞的可能性——一个段可能己在网络中丢失,并且没有关于该发送段的消息。在这种情况下,TCP做出强烈的反应:
a. 设置阈值为当前拥塞窗口大小的一半ssthresh = cwnd / 2;
b. 设置cwnd为一个段的大小cwnd = MSS / 2;
c. 启动慢速启动阶段。 - 如果接收到三个
ACK,那么存在着轻度拥塞的可能性——一个段可能已丢失,但自从接收到三个ACK后,有一些段可能已安全到达。这称为快速传送和快速恢复fast transmission and fast recovery。在这种情况下,TCP做出轻度的反应:
a. 设置阈值为当前拥塞窗口大小的一半ssthresh = cwnd / 2;
b. 设置cwnd为阈值(有些实现是阈值加上三个段),注意先后顺序;
c. 启动拥塞避免阶段。
用下列方法之一对拥塞检测做出反应:
- 如果检测出计时器到时,那么一个新的慢速启动阶段开始。
- 如果检测出三个
ACK,那么一个新的拥塞避免阶段开始。
(4) 总结
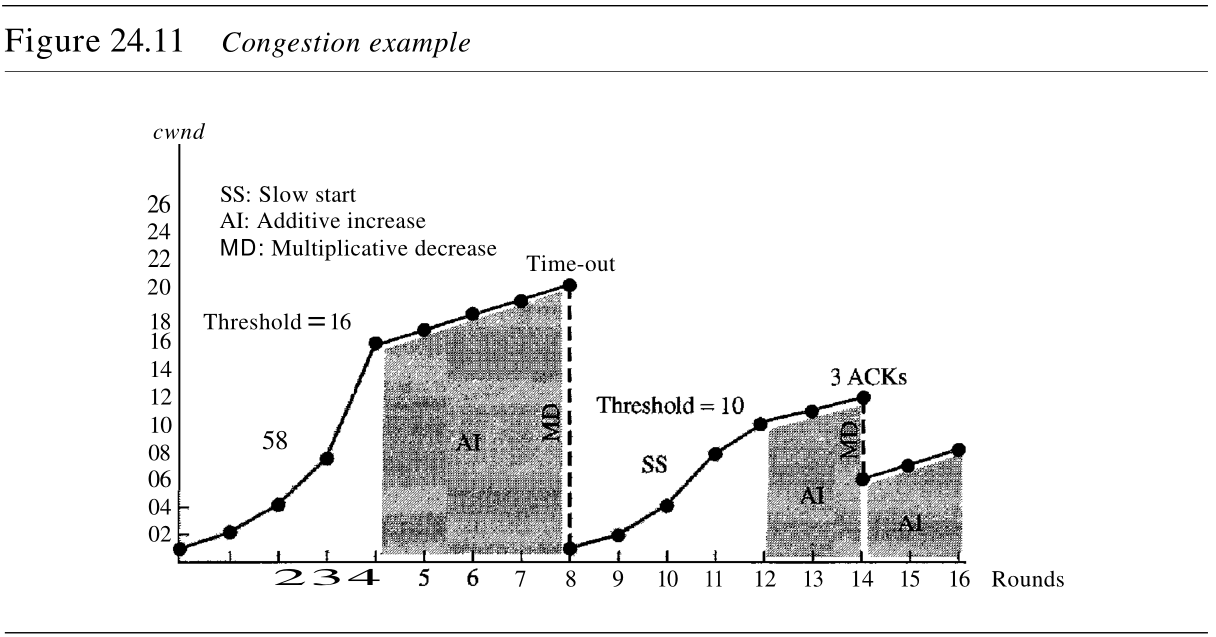
在图24.10中,概括了TCP的拥塞策略与三个阶段之间的关系。
在图24.11中给出了一个例子。假定最大窗口大小 ssthresh 是
32
32
32 个段,阈值设置为
16
16
16 个段(最大窗口的一半)。在慢速启动阶段,窗口大小从
1
1
1 开始按指数规律增长,直到它达到阈值。当它达到阈值后,拥塞避免(加性增加)过程允许窗口大小线性增长,直到计时器到时或到达最大窗口大小。
在图24.11中,当窗口大小为
20
20
20 时,计时器到时。此时,进入乘性减少过程,将阈值设置为当前窗口大小的一半。当计时器到时,当前窗口大小是
20
20
20 ,因此现在阈值是
10
10
10 。TCP再次进入慢速启动,并置窗口大小为
1
1
1 。当到达新的阈值时,TCP进入加性增加阶段。当窗口大小为
12
12
12 时,三个 ACK 事件发生。再次进入乘性减少过程,阈值和窗口大小设置为
6
6
6 ,这时TCP进入加性增加阶段,该阶段一直维持到另一个计时器到时、或者另外三个 ACK 事件发生为止。
24.4.2 帧中继中的拥塞控制
帧中继网络中的拥塞,会导致吞吐量降低和延迟增加,高吞吐量和低延迟是帧中继协议的主要目标。帧中继协议没有流量控制机制。另外,帧中继允许用户传送突发性数据。这意味着,帧中继网络有可能因为通信量过大、而发生拥塞现象,因此需要有拥塞控制机制。
为了避免拥塞,帧中继协议在帧中利用 2 2 2 个位,明确地提示源端和目的端拥塞的发生(显式信令)。
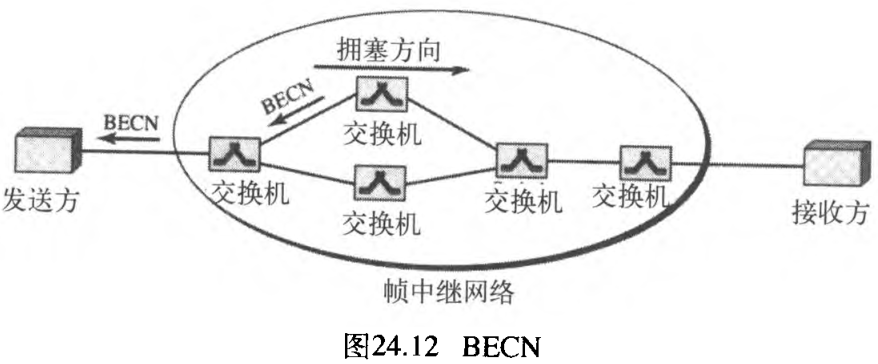
- 后向显式拥塞通知
backward explicit congestion notification, BECN位提示发送方网络中的拥塞情况。因为帧是从发送方传送出来的,有人可能问这是如何实现的。实际上有两种方法:交换机利用来自接收方的响应帧(全双工模式);或者为了特定的目的,交换机可使用一个预定义连接DLCI=1023来发送专门的帧。发送方仅通过减小数据速率,对该提示信息做出响应。图24.12说明了运用BECN的情况。
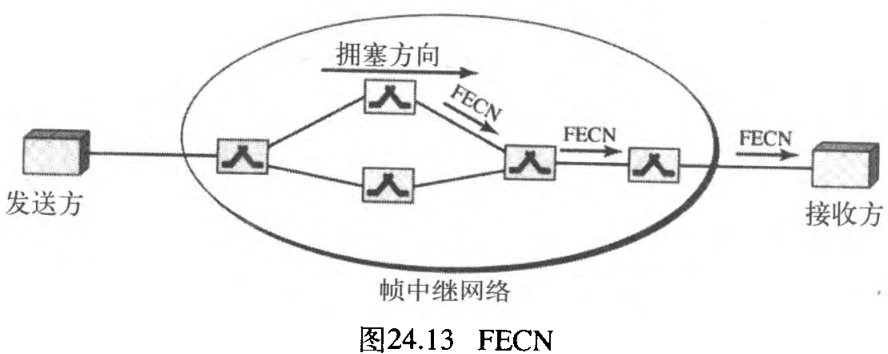
- 前向显式拥塞通知
forward explicit congestion notification, FECN位是用来提示接收方网络中拥塞的情况。有可能会出现「接收方不能采取任何措施来减轻拥塞」的情况。但是,帧中继协议假定:发送方和接收方能相互通信,并在较高层使用某种类型的流量控制机制。例如,如果在较高层有确认机制,接收方就能延迟发送确认,这样就可以迫使发送方放慢发送速度。图24.13说明了运用FECN的情况。
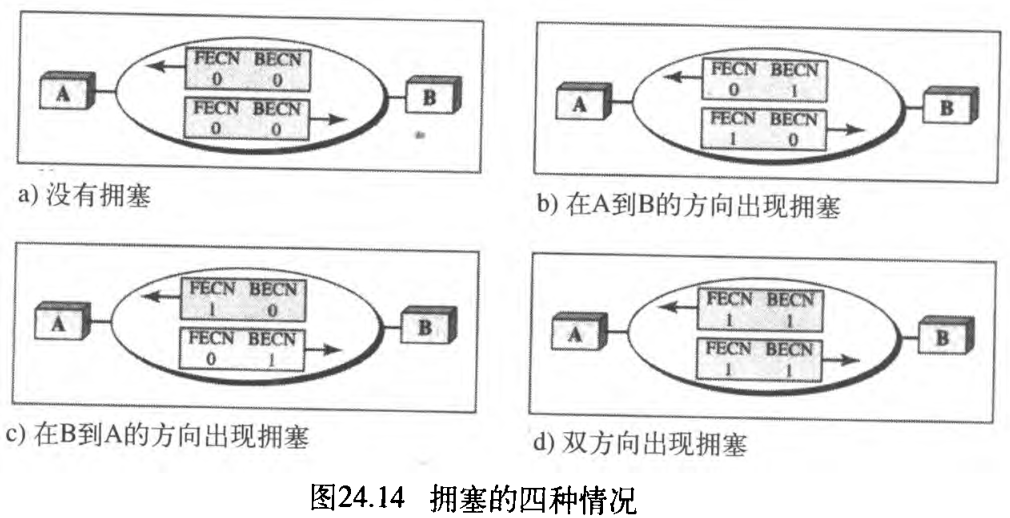
当两个端点运用帧中继网络进行通信时,可能会出现四种与拥塞有关的情况。图24.14说明了这四种情况、以及FECN和BECN的值。
24.5 服务质量
服务质量 quality of service , QoS 是一个网络互联问题,对该问题的讨论已经远远超出对它的定义。可以非形式地、将服务质量定义为数据流所追求的某种目标。
24.5.1 数据流特性
按传统的观点,数据流具有四种特性:可靠性、延迟、抖动和带宽,如图24.15所示。
1. 可靠性
可靠性 reliability 是数据流所需要的一个特性。缺乏可靠性意味着分组或确认的丢失,这些都必须通过重传来弥补。然而,应用层程序对可靠性的敏感程度是不同的。例如,电子邮件、文件传输和因特网访问与电话或音频会议相比,保证其可靠传输更为重要。
2. 延迟
源端到目的端的延迟 delay 是另一个数据流特性。此外,不同的应用对延迟的容许程度是不同的。在此情况下,电话、音频会议、视频会议和远程登录都需要最小的延迟,但是在文件传输或电子邮件中,延迟并不那么重要。
3. 抖动
抖动 jitter 是属于同一数据流的分组延迟的变化。抖动被定义为分组延迟的变化,较高的抖动意味着在延迟之间的差异较大,而低的抖动意味着差异很小。
例如,如果 4 4 4 个分组离开的时间分别是 0 , 1 , 2 , 3 0, 1, 2, 3 0,1,2,3 ,而到达的时间分别是 20 , 21 , 22 , 23 20, 21, 22, 23 20,21,22,23 ,则它们都有相同的延迟为 20 20 20 。另一方面,如果上述 4 4 4 个分组的到达时间分别是 21 , 23 , 21 , 28 21, 23, 21, 28 21,23,21,28 。则它们延迟是不同的: 21 , 22 , 19 , 24 21, 22,19, 24 21,22,19,24 。对于音频和视频的应用,前者是完全可接受的,而后者是不能接受的。只要延迟对所有的分组都是相同的,分组以短或者长的延迟到达,无关紧要。
在(29)中,将看到多媒体通信如何处理抖动。如果抖动高,那么为了使用接收到的数据,就需要执行一些动作。
4. 带宽
不同的应用需要不同的带宽。在视频会议中需要发送数百万比特率来刷新彩色屏幕,但在一封电子邮件中的全部位的个数,甚至都不到一百万。
24.5.2 数据流类型
基于数据流的特性,可将数据流分成不同的组,每组都有相似的特性。这种分类方法既不够规范也不够普遍。一些诸如ATM之类的协议定义了类型的概念,稍后可以看到这一点。
24.6 改进QoS的技术
在第24.5节中,根据数据流的特性对QoS进行了定义。本节将讨论一些用于改进服务质量的方法。这里简要地讨论四种常用方法:调度、通信量整形、许可控制和资源预留。
24.6.1 调度
来自不同数据流的分组到达交换机或路由器,并由它进行处理。一种好的调度技术,会以公平合理的方式来对待不同的数据流。现在已经设计了多种调度技术用来改进服务质量,在这里讨论其中的三种技术:FIFO队列、优先权队列和加权公平队列。
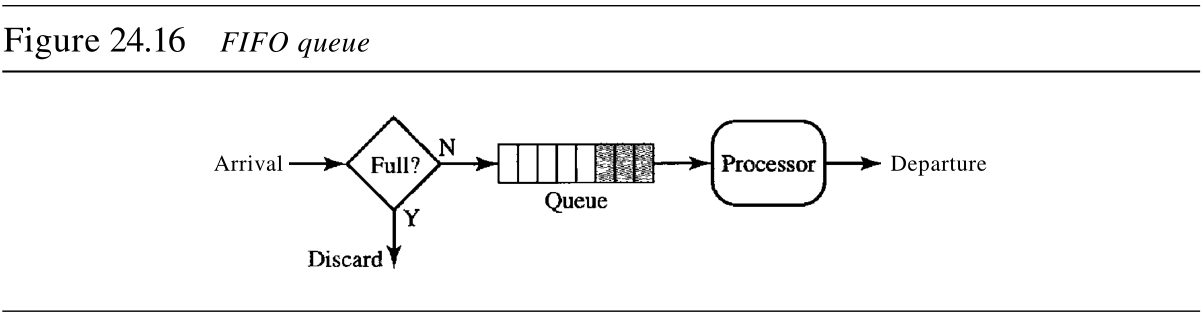
1. 先进先出队列
在先进先出 first-in first-out, FIFO 队列中,分组在缓冲区(队列)中等待,直到节点(路由器或交换机)准备处理它们为止。如果平均到达速率高于平均处理速率,那么队列将被填满,新的分组将被丢弃。FIFO队列和那些必须在公共汽车站等待汽车的人类似。图24.16说明了FIFO队列的概念。
2. 优先权队列
在优先权队列 priority queuing 中,首先给不同的分组分配一个不同的
到达的优先权类。每个优先权类都有自己的队列,在最高优先权队列中的分组首先得到处理,而最后才对最低优先权队列中的分组进行处理。注意:系统不停地为一个队列提供服务,直到它变空为止。图24.17说明了,具有两个优先权级别的优先权队列(为了简单起见)。
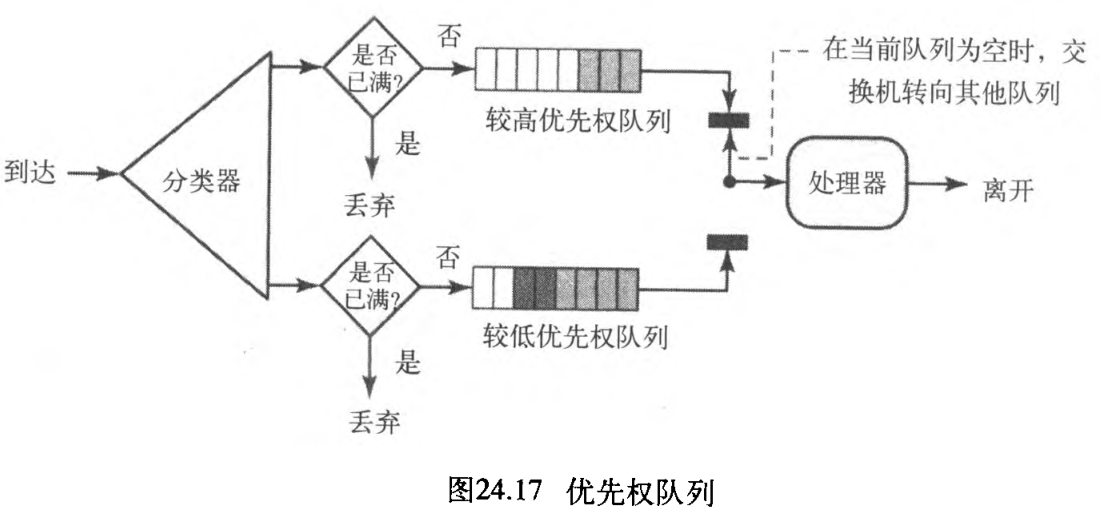
与FIFO队列相比,优先权队列能提供更好的QoS,因为具有较高优先权的通信量(如多媒体),能用较少的延迟到达目的端。但是,优先权队列也有潜在的缺点——如果在高优先权队列中有持续的通信量,那么处于较低优先权队列中的分组将永远得不到处理,这种情形称为"饥饿" starvation 。
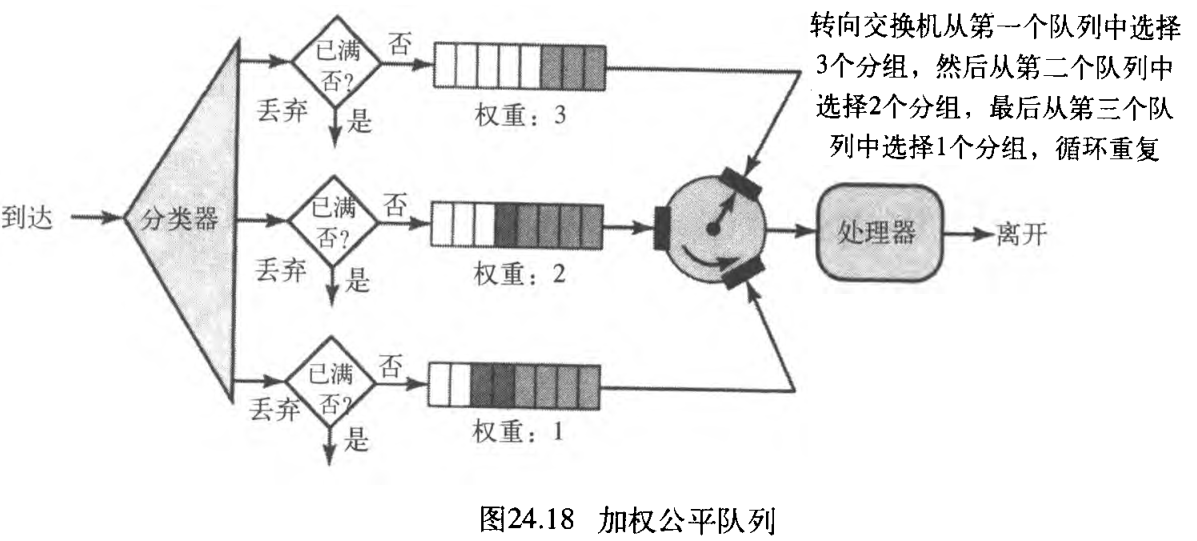
3. 加权公平队列
较好的调度算法是加权公平队列 weighted fair queuing 。在这种技术中,分组仍然被分成不同的类,并且属于不同的队列。然而,队列是基于队列的优先权来分配权重的,较高的优先权就意味着具有较高的权重。系统以轮换方式来处理每个队列中的分组,所处理的分组的数量等于相应队列的权重。例如,如果这些权重是
3
,
2
,
1
3, 2, 1
3,2,1 ,那么就对第一个队列中的
3
3
3 个分组、第二个队列中的
2
2
2 个分组和第三个队列中的
1
1
1 个分组进行处理。如果系统并没有给不同类指定不同的权重,那么所有的权重就是相等的。这就是加权公平队列的原理。图24.18以三个类为例说明了这种技术。
24.6.2 通信量整形
通信量整形 traffic shaping 是一种控制「发送到网络中的通信量和速率」的机制。通信量整形有两种技术:漏桶和令牌桶。
1. 漏桶
如果桶在底部有一个小洞,只要桶中有水,水便从桶中以不变的速率漏下。如果桶中有水,水漏的速率并不依赖于将水倒入桶中的速率,即输入速率可以发生变化,但是输出速率保持恒定。同样,在网络中一种被称为漏桶 leaky bucket 的技术,能消除突发性通信量。将突发性大块数据存储到桶中,然后以平均速率发送出去。图24.19说明了漏桶和其效果。
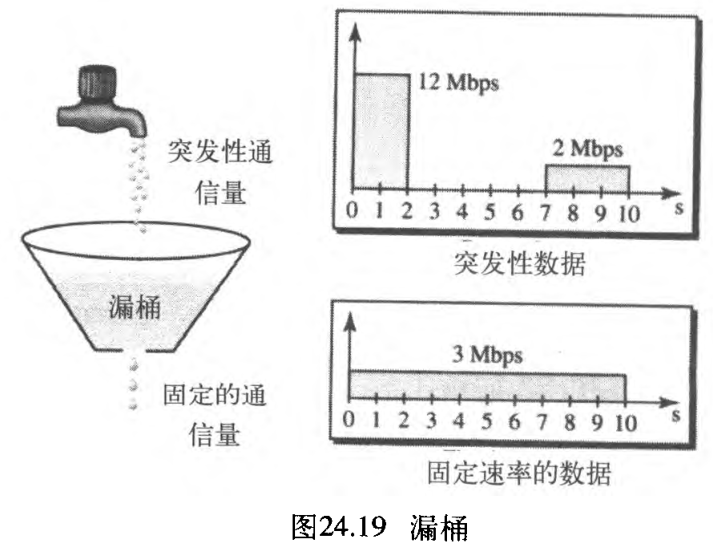
在图24.19中,假设网络为每台主机都设定了
3
Mbps
3textrm{Mbps}
3Mbps 的带宽。使用漏桶对输入通信量进行整形,是为了使通信量符合这个设定的带宽。在图24.19中,主机以
12
Mbps
12textrm{Mbps}
12Mbps 的速率发送了
2
2
2 秒的突发性数据,数据一共是
24
M
24textrm{M}
24M 位。主机在之后的
5
5
5 秒内没有任何反应,然后以
2
Mbps
2textrm{Mbps}
2Mbps 的速率发送数据,持续时间为
3
3
3 秒,此时的全部数据为
6
M
6textrm{M}
6M 位。主机在
10
10
10 秒内总共发送了
30
M
30 textrm{M}
30M 位的数据。在这同样的
10
10
10 秒内,漏桶以
3
Mbps
3textrm{Mbps}
3Mbps 的速率发送数据来使通信量保持平稳。
如果没有漏桶,因为该主机占用了比分配给它的更大的带宽,它开始所发送的突发性数据可能已经导致网络拥塞。漏桶还可以避免拥塞。做个类比,以高峰期间(突发性通信量)的高速公路为例,如果往返者们能错开他们的工作时间,那么高速公路上的拥塞状况就可以得到避免。
简单的漏桶实现过程如图24.20所示。FIFO队列保存了分组。如果这个通信量由固定大小的分组(例如 ATM 网中的信元)组成,那么在每个时钟单位时间内,进程从队列中移除固定数量的分组。
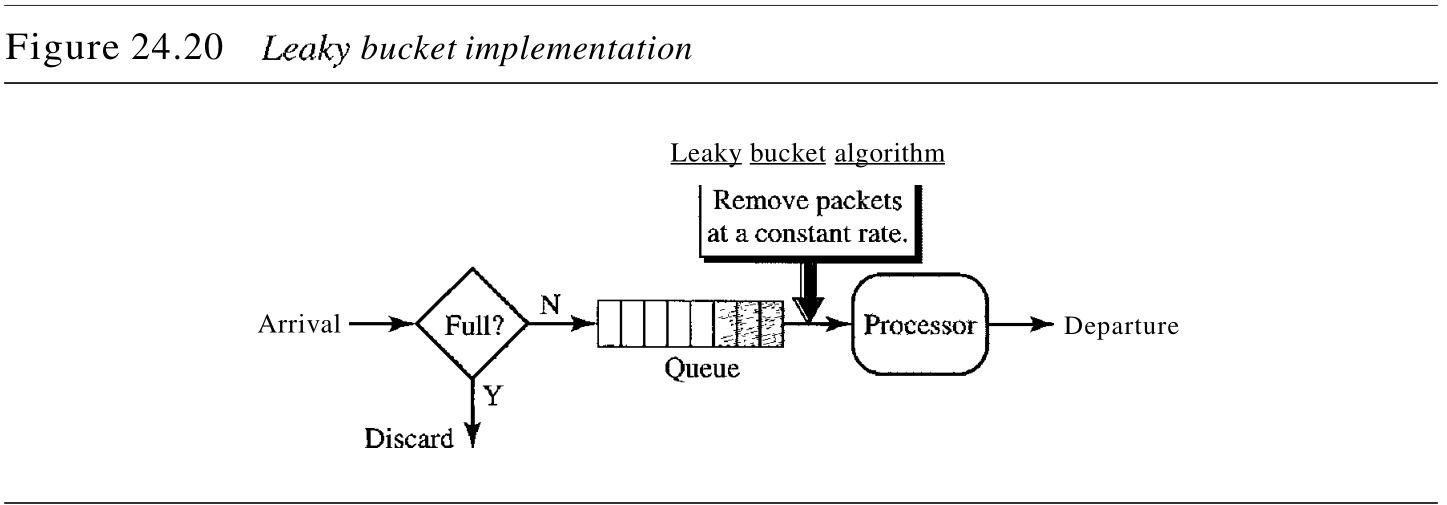
如果通信量是由变长分组组成的,那么固定输出速率必须是基于字节个数或位个数。以下是变长分组的算法:
- 在计时开始时,将计数器初始化为 n n n ;
- 如果 n n n 比分组的长度大,就发送分组,并将计数器的值减去分组的长度。重复该步骤,直到 n n n 值小于分组的长度;
- 重新设置计数器,并返回到步骤 1 1 1 。
总的来说,漏桶算法通过均分数据速率,将突发性通信量整形为固定速率的通信量。如果桶已满,就可能丢失分组。
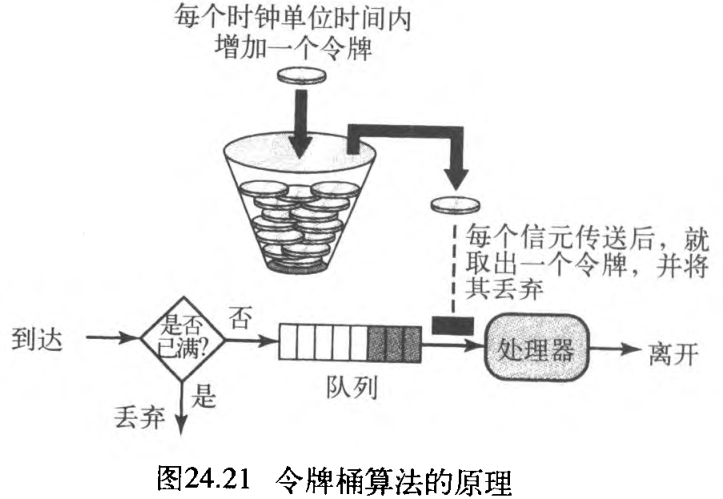
2. 令牌桶
漏桶算法有很大的局限性,它不能给空闲的主机提供信用。例如,如果一台主机在一 段时间内没有发送数据,其漏桶就变为空桶了。现在即使主机发送高突发性数据,漏桶也只能允许平均速率的数据。此时并没有考虑主机空闲时间。
另一方面,令牌桶 token bucket 算法允许空闲主机以令牌的形式为未来累积信用。在每个时钟单位时间内,系统发送
n
n
n 个令牌到桶中。在每个数据信元(或字节)发送后,系统就从中去掉一个令牌。 例如,假设
n
n
n 是
100
100
100 ,主机空闲了
100
100
100 个时钟单位时间,那么令牌桶便收集了
10000
10000
10000 个令牌。主机可以在一个时钟单位时间,消费所有这些令牌来发送
10000
10000
10000 个信元,或者花去
1000
1000
1000 个时钟单位时间,每个时钟单位时间内发送
10
10
10 个信元。换句话说,只要令牌桶不是空的,主机就能发送突发性数据。图24.21说明了该算法的原理。
使用计数器可以很容易地实现令牌桶算法。令牌初始化为
0
0
0 。每次增加
1
1
1 个令牌,计数器就加
1
1
1 ,每次发送一个数据单元,计数器就减
1
1
1 。当计数器为
0
0
0 时,主机不能发送数据。
令牌桶允许以规定的最大速率发送突发性通信量。
3. 令牌桶和漏桶的结合使用
可将两种技术结合起来给空闲主机提供信用,同时调整通信量。在令牌桶之后应用漏桶;漏桶的速率需要高于将令牌放入桶中的速率 The leaky bucket is applied after the token bucket; the rate of the leaky bucket needs to be higher than the rate of tokens dropped in the bucket 。
24.6.3 资源预留
数据流需要诸如缓冲区、带宽、CPU时间等资源。如果提前对这些资源进行预留,将会提高服务质量。在这一节将讨论一个称为综合业务的QoS模型,该模型极大地依赖资源预留来提高服务质量。
24.6.4 许可控制
许可控制指的是由路由器或交换机使用的一种机制,它基于一个称为数据流规范 flow specifications 的预定义参数 predefined parameters 来接收或拒绝数据流。在路由器接收数据流并对其进行处理之前,它检查数据流规范,查看它的性能(根据带宽、缓冲区大小及CPU速度等)、以及之前它对其他数据流的约定,是否可以处理新的数据流 Before a router accepts a flow for processing, it checks the flow specifications to see if its capacity and its previous commitments to other flows can handle the new flow 。
24.7 综合业务
根据24.5节和24.6节的讨论,在因特网中已经设计出了两种用于提供服务质量的模型 two models have been designed to provide quality of service in the Internet :综合业务和差分业务。两个模型都强调服务质量在网络层(lP)的使用,尽管这些模型也可以用于诸如数据链路层的其他层。本节讨论综合业务,第24.8节讨论差分业务方面的内容。
正如在第20章中所了解到的,IP最初是为尽力传递而设计的。这意味着每个用户接受同样级别的服务。这种类型的传递不能保证一项业务的最低要求,例如实时音频和视频应用所需的带宽。即使这样的应用偶然获得了额外的带宽,也可能对其他应用造成不利影响,并导致拥塞现象发生。
综合业务 integrated service 有时称为 IntServ ,它是设计用于IP的、基于数据流的QoS模型 flow-based QoS model 。这意味着,用户需要创建一条从源端到目的端的流,即一种虚电路,并将资源需求通知给所有的路由器。
24.7.1 信令
IP是一种无连接的、数据报、分组交换协议。如何在一种无连接的协议上实现一个基于数据流的模型呢?解决办法是在IP上使用信令协议 signaling protocol ,它为资源预留提供信令机制 provides the signaling mechanism for making a reservation 。这个协议称为资源预留协议 Resource Reservation Protocol, RSVP ,稍后会讨论到它。
24.7.2 数据流规范
当源端做资源预留时,需要定义数据流规范。数据流规范包括两个部分:资源规范 resource specification, Rspec 和通信量规范 traffic specification, Tspec 。Rspec 定义数据流需要预留的资源(如缓冲区、带宽等),Tspec 定义数据流的通信量特征。
24.7.3 许可
在路由器从一个应用接收到数据流规范后,它决定许可或拒绝这个业务。所做出的决定基于路由器的先前约定和资源的当前有效性 the previous commitments of the router and the current availability of the resource 。
24.7.4 业务类型
综合业务已经定义了两种类型的业务:保证型业务和受控载荷型业务。
- 保证型业务
guaranteed service:这种类型的业务用于实时传输,这种传输需要保证端到端延迟最小。端到端延迟是指在各路由器中的延迟之和、在介质中的传播延迟和设置机制the delays in the routers, the propagation delay in the media, and the setup mechanism。只有第一项,即在各路由器中的延迟之和可由路由器来保证。
这类业务保证分组在一定的传递时间内到达,并且只要数据流通信量在Tspec边界范围之内,即可保证不丢弃分组。可以说保证型业务就是定量业务,在这种业务中,端到端延迟量和数据速率必须由应用来定义。 - 受控载荷型业务
controlled-load service:这种类型的业务用于「可以接受一定延迟、但对超载网络和丢失分组的危险很敏感」的应用。
这些类型应用的较好实例有文件传输、电子邮件和因特网访问。受控载荷型业务是一种定性业务,因为应用要求较低的分组丢失率或零分组丢失率。
24.7.5 RSVP
在综合业务模型中,应用程序需要资源预留。正如在 IntServ 模型中所讨论的那样,为数据流进行资源预留。这意味着,如果要在IP层使用 IntServ ,则需要在IP层之外创建一条数据流通路,它是一种虚电路网络,最初被设计为一种数据报分组交换网络。在数据传输可以启动之前,虚电路网络需要信令系统来建立虚电路。资源预留协议 RSVP 是一种信令协议,它帮助IP创建一条数据流通路,从而实现资源预留。在讨论 RSVP 之前,需要指出的是,它是一种与综合业务模型分开的独立协议,可以用于其他模型中。
1. 多播树
RSVP 不同于以前看到的一些其他信令系统,因为它是一种用于多播的信令系统。但是,RSVP 也能用于单播,因为单播仅仅是在多播组中只有一个成员的多播的一个特例。这样设计的原因是,使RSVP能够为各种通信量提供资源预留,包括经常使用多播的多媒体。
2. 基于接收方的预留
在 RSVP 中,由接收方(而不是发送方)建立预留。这种策略和其他多播协议相匹配。例如,根据多播路由选择协议,由接收方而非发送方来决定加入或离开多播组。
3. RSVP报文
RSVP 有多种类型的报文。然而根据需要,下面只讨论其中的两种:路径 Path 和预留 Resv 。
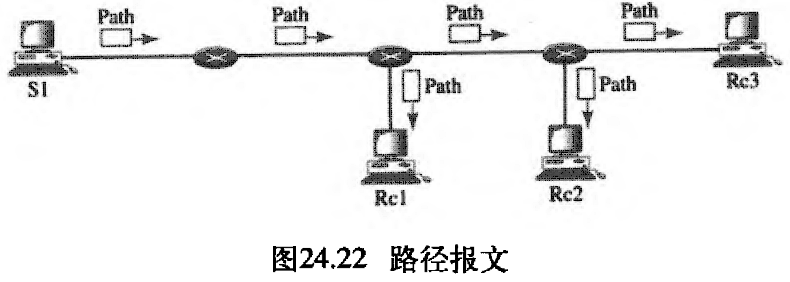
- 路径
Path报文:回想一下,在RSVP中数据流中的接收方预留资源。但在预留资源之前,接收方并不知道分组经过的路径,而预留资源是需要知道路径的。为了解决这个问题,RSVP使用路径报文。路径报文从发送方传送出来,到达多播路径中的所有接收方。在整个路径中,路径报文为接收方存储必要的信息。在多播环境中,将路径报文发送出去,并且在路径分叉时会产生新的报文。图24.22说明了路径报文。
- 预留
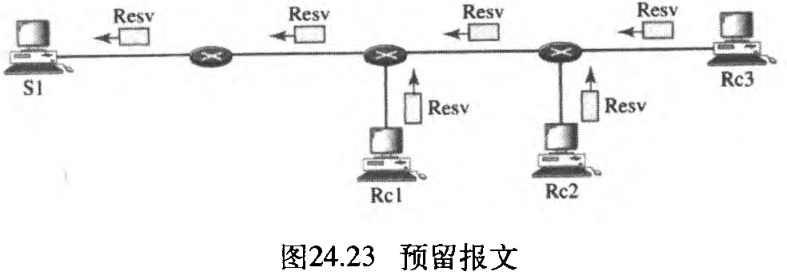
Resv报文:在接收方已经收到路径报文之后,它发送预留报文。预留报文朝着发送方传送(上行),并且在支持RSVP的路由器上预留资源。如果路由器不支持路径中的RSVP,它将使用以前所讨论的尽力传递方法对分组进行路由。图24.23说明了预留报文。
4. 预留合并
在 RSVP 中,并没有为数据流中的每个接收方预留资源,而是将资源预留进行了合并 reservation merge 。在图24.24中,
R
c
3
Rc3
Rc3 请求
2
Mbps
2textrm{Mbps}
2Mbps 带宽,而
R
c
2
Rc2
Rc2 请求
1
Mbps
1textrm{Mbps}
1Mbps 的带宽,需要建立带宽预留的路由器
R
3
R3
R3 将这两个请求合并,只对
2
Mbps
2textrm{Mbps}
2Mbps 带宽的那个请求(即两个中较大的那个请求)做预留,这是因为
2
Mbps
2textrm{Mbps}
2Mbps 的输入预留就能处理这两个请求。这种情况对
R
2
R2
R2 也是适用的。
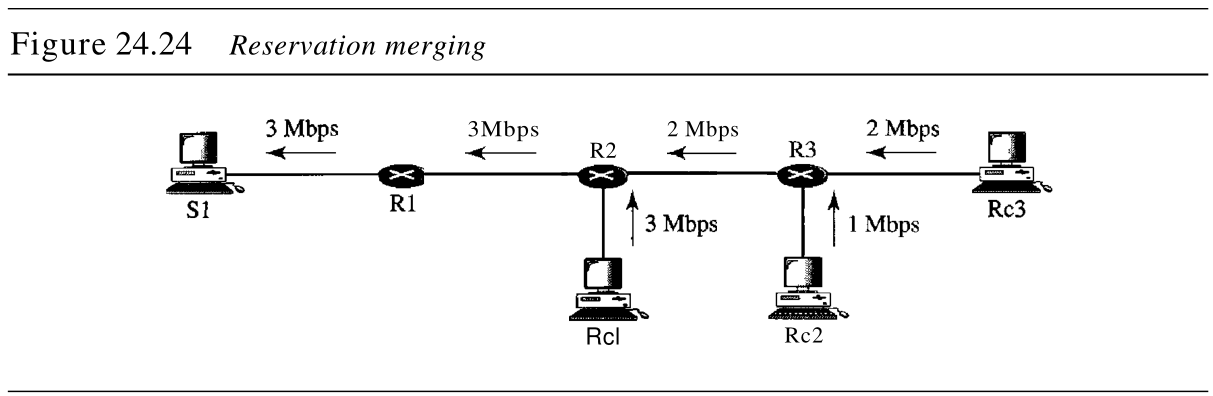
可能问,为什么 R c 2 Rc2 Rc2 和 R c 3 Rc3 Rc3(两者都属于一个单一数据流)要请求不同的带宽值呢?答案是,在多媒体环境中,不同的接收方可以处理不同的质量等级。例如, R c 2 Rc2 Rc2 或许只能以 1 Mbps 1textrm{Mbps} 1Mbps(较低质量)的速率接收视频信息,而 R c 3 Rc3 Rc3 或许可以 2 Mbps 2textrm{Mbps} 2Mbps(较高质量)的速率接收视频信息。
5. 预留方式
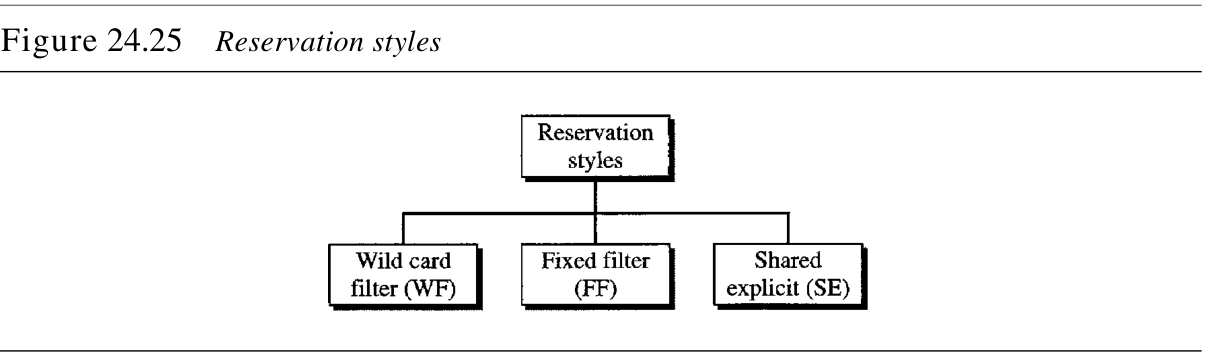
当存在多条数据流通路时,路由器需要预留资源来接收所有的数据流。RSVP 定义了三种预留方式,如图24.25所示。
- 通配过滤器方式
Wild Card Filter Style:在这种方式中,路由器为所有发送方创建一个预留。这个预留是基于最大的请求。这种方式用于「来自不同发送方的数据流不同时出现」的情况。 - 固定过滤器方式
Fixed Filter Style:在这种方式中,路由器为每个数据流创建一个不同的预留。这意味着如果有 n n n 个数据流,就要建立 n n n 个不同的预留。这种方式用于「来自不同发送方的数据流同时出现的概率很高」的情况。 - 共享显式方式
Shared Explicit Style:在这种方式中,路由器只创建一个预留,该预留可以被一组数据流共享。
软状态
soft state:为数据流而存储在每个节点中的预留信息(状态),需要定期进行刷新。与用于其他诸如ATM或帧中继这类虚电路协议的硬状态hard state相比,这种状态称为软状态。在硬状态中,有关数据流的信息被一直保留着,直到这些信息被擦除为止。目前默认的刷新间隔是 30 30 30 秒。
24.7.6 综合业务所存在的问题
在综合业务中至少存在两个问题,这可能会妨碍它在因特网中的实现。它们是可伸缩性和服务类型限制。
- 可伸缩性
scalability:综合业务模型要求每台路由器都要为每个数据流保存信息。但随着因特网规模的日益增长,这是一个严重的问题。 - 业务类型限制
service-type limitation:综合业务只提供了两种类型的业务,即保证型业务和受控载荷型业务。那些反对该模型的人指出,应用可能需要比这两种业务类型更多的业务类型。
24.8 差分业务
差分业务 Differentiated Services, DS or Diffserv 是由因特网工程任务组 Internet Engineering Task Force , IETF 提出的用于弥补综合业务缺陷的一种业务。与综合业务相比,它有两个基本变化:
- 主要处理过程从网络核心转移到网络边缘。这就解决了可伸缩性的问题,路由器不需要存储有关数据流的信息。每次发送分组时,应用程序或主机定义它们所需要的业务类型。
- 将「针对每条数据流的业务
per-flow service」改变为「针对每种类型的业务per-class service」。路由器根据在分组中定义的业务类型、而非根据数据流来发送分组The router routes the packet based on the class of service defined in the packet, not the flow。这就解决了业务类型限制的问题,可根据应用程序的需要定义不同的业务类型。
差分业务是用于IP的、基于类的QoS模型 class-based QoS model designed for IP 。
1. DS字段
在 Diffserv 中,每个分组都包含一个称为 DS 的字段。该字段的值是在网络边界,由主机或用作边界路由器的第一台路由器来设置的。
IETF提议用 DS 字段,替换现存的IPv4中的服务类型 type of service, TOS 字段或IPV6中的类字段,如图24.26所示。

DS 字段包含两个子字段:DSCP 和 CU 。差分业务编码点 Differentiated Services Code Point , DSCP 是一个
6
6
6 位的子字段,它定义了逐跳行为 perhop behavior, PHB 。长度为
2
2
2 位的当前未用 currently unused , CU 子字段,当前还未使用。
支持 Diffserv 的节点(路由器)使用 DSCP 的
6
6
6 位作为一个表的索引,该表定义了分组处理机制 packet-handling mechanism ,用于当前正在处理的分组。
2. 逐跳行为
Diffserv 模型为接收到分组的每个节点定义了逐跳行为 PHB 。到目前为止已定义了三种 PHB : 默认逐跳行为 default PHB, DE PHB 、加速转发逐跳行为 expedited forwarding PHB, EF PHB 和保证转发逐跳行为 assured forwarding PHB, AF PHB 。
DE PHB:默认PHB和尽力传递是相同的,它与TOS相兼容。EF PHB:加速转发PNB提供如下的服务:低丢失率;低等待时间;可保证的带宽。这与源端和目的端之间使用的虚连接是相同的。AF PHB:只要类通信量class traffic不超过节点的通信量规范,AF PHB就能以较高可靠性传送分组。网络用户要意识到一些分组可能会丢失。
3. 通信量调节器
为了实现 Diffserv ,DS 节点使用了几种调节器,如测量器 meters 、标记器 markers 、整形器 shapers 和丢弃器 droppers 。如图24.27所示。
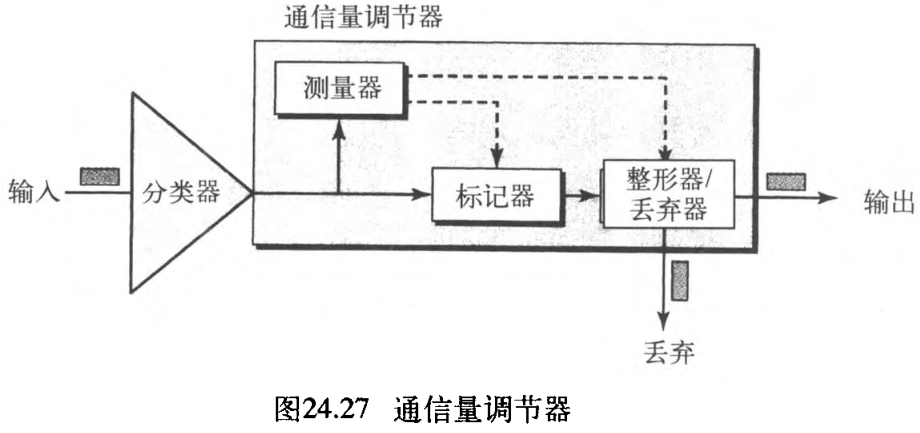
- 测量器: 测量器检查输入数据流和协商的通信量规范是否匹配,并将这个结果发送给其他组件。测量器也能利用「诸如令牌桶之类的工具」来检查配置文件。
- 标记器:标记器能重新标记正使用尽力传递的分组(
DSCP: 000000),或依据接收自测量器的信息给分组作降标记down-mark。如果数据流与其对应的规范不匹配,就会对其作降标记(降低数据流的等级)。标记器不对分组作升标记(提升等级)。 - 整形器:当通信量与协商的规范不匹配时,整形器使用接收自测量器的信息,对该通信量进行重新整形。
- 丢弃器:丢弃器的运作过程就像没有缓冲区的整形器。 如果数据流严重违反协商的规范,那么丢弃器就要丢弃这些分组。
24.9 交换网络中的QoS
讨论了IP协议中提出的QoS模型之后,现在来讨论一下用于两个交换网络中的QoS:帧中继和ATM。 这两个网络都是虚电路网络,它们需要一个诸如 RSVP 的信令协议。
24.9.1 帧中继中的QoS
在帧中继中已经设计了控制通信量的四个不同的属性指标:访问速率、提交突发业务量
B
c
B_c
Bc 、 提交信息速率
C
I
R
CIR
CIR 和超突发长度
B
e
B_e
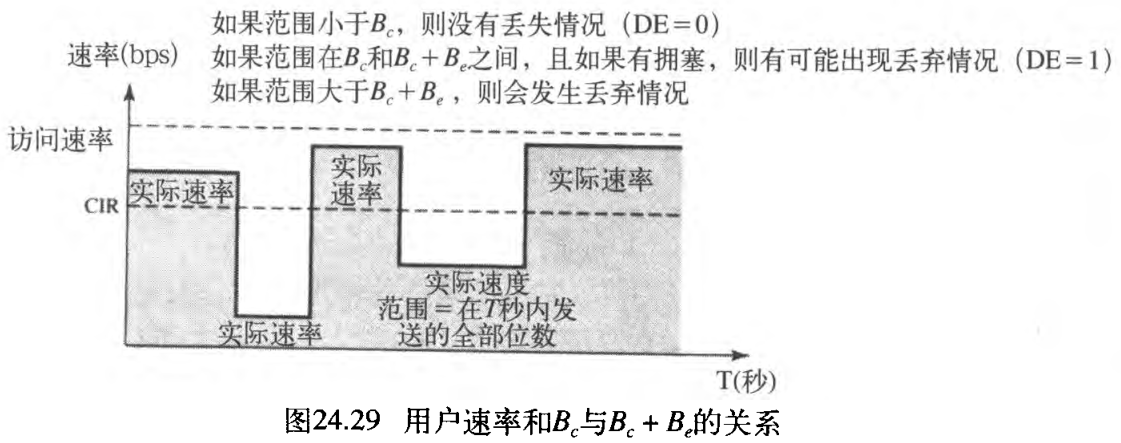
Be 。它们是在用户和网络进行协商期间设置的。对于 PVC 连接而言,它们需协商一次,而对于 SVC 连接而言,要为每个连接在(它的)连接建立期间进行协商。图24.28说明了这四个属性指标间的关系。

1. 访问速率
每个连接都要定义访问速率 access rate(以每秒位为单位)。访问速率实际上是由「连接用户与网络的通道的带宽」来决定的,用户永远不能超过这个速率。例如,如果用T-1线路将用户连接到帧中继网络,则访问速率是
1.544
Mbps
1.544textrm{Mbps}
1.544Mbps ,并且用户永远无法超过这个速率。
2. 提交突发业务量
对于每个连接而言,帧中继定义了提交突发业务量 committed burst size
B
c
B_c
Bc 。该值是在一段预定义的时间内,在没有丢弃任何帧或设置 DE 位的条件下,网络所传输的最大比特数。
例如,在 4 4 4 秒的时间段内 B c B_c Bc 的值为 400 kbit 400textrm{kbit} 400kbit 是可以的,因为用户能在 4 4 4 秒的间隔内传送 400 400 400 千位的数据,而不用担心会出现任何帧丢失的情况。注意这个量并不是针对每 1 1 1 秒而定义的速率,而是一个累积的度量。用户可以在第一个 1 1 1 秒发送 300 kbit 300textrm{kbit} 300kbit ,在第二个和第三个 1 1 1 秒期间不发送任何数据,而最后在第四个 1 1 1 秒期间发送 100 kbit 100textrm{kbit} 100kbit 。
3. 提交信息速率
提交信息速率 committed information rate, CIR 除了定义了以每秒比特为单位的平均速率之外,它和提交突发业务量在概念上类似。如果用户持续地以该速率发送数据,那么网络就能一直发送帧。但是,因为它是一个平均度量,因此用户有时可以发送高于
C
I
R
CIR
CIR 的数据、而在其他时间里发送低于
C
I
R
CIR
CIR 的数据。只要预定义期间的平均速率符合要求,就会发送这些帧。
在预定义期间,发送的累积比特数不能够超过
B
c
B_c
Bc 。注意,CIR不是一个独立的度量,可使用如下的公式对它进行计算:
C
I
R
=
B
c
T
(
bps
)
CIR = dfrac{B_c} {T} (textrm{bps})
CIR=TBc(bps)
例如,如果在 5 5 5 秒内, B c B_c Bc 是 5 kbit 5textrm{kbit} 5kbit ,那么 C I R CIR CIR 就是 5000 / 5 = 1 kbps 5 000/5 = 1textrm{kbps} 5000/5=1kbps 。
4. 超突发长度
对于每个连接而言,帧中继都定义了超突发长度 excess burst size
B
e
B_e
Be 。该值是在一段预定义的时间内,用户发送的超过
B
c
B_c
Bc 的最大位数。如果网络中没有拥塞,网络就保证传输这些比特。注意,这种约定实现的可能性比在
B
c
B_c
Bc 情况下要低,因为网络本身实现这种约定是有条件的。
5. 用户速率
图24.29说明了用户如何才能发送突发性数据。如果用户发送的数据没超过 B c B_c Bc ,那么网络就能保证传送帧、而不会出现丢弃帧的情况。如果用户发送的数据超过了 B c B_c Bc 而小于 B B B(也就是全部比特数小于 B c + B e B_c + B_e Bc+Be), 那么在网络中没有拥塞的条件下,它就能保证传送所有的帧。如果出现拥塞情况,将会丢失一些帧。
从用户接收帧的第一台交换机有一个计数器,它可为超过
B
c
B_c
Bc 的帧设置 DE 位。如果网络出现拥塞情况,那么其余的交换机将会丢弃这些帧。注意,需要较快发送数据的用户可能超过
B
c
B_c
Bc 。只要该指标不超过
B
c
+
B
e
B_c + B_e
Bc+Be ,那么这些帧就有可能到达目的端而不丢失。然而,要记住的是,当在某一时刻用户发送的数据超过了
B
c
+
B
e
B_c + B_e
Bc+Be ,那么第一台交换机就会丢弃此后用户所发送的所有帧。
24.9.2 ATM 中的QoS
ATM中的QoS是基于类、与用户相关的属性和与网络相关的属性 based on the class, user-related attributes, and network-related attributes 。
1. 类
ATM论坛定义四种服务类型:恒定比特率 CBR 、可变比特率 VBR 、可用比特率 ABR 和未指定比特率 UBR 。见图24.30所示。
- 恒定比特率
constant-bit-rate, CBR, CBR类用于需要实时音频或视频服务的客户。这个服务与诸如T线之类的专线提供的服务类似。 - 可变比特率
variable-bit-rate, VBR类分为两个子类:实时VBR-RT和非实时VBR-NRT。VBR-RT用于需要实时服务(如声音和视频传输)和使用压缩技术来生成可变比特率的用户 。VBR-NRT用于不需要实时服务,但是使用压缩技术生成可变比特率的那些用户。 - 可用比特率
available-bit-rate, ABR类以最小的速率发送信元。如果有更多的网络资源可用的话,那么就能突破这个最小比特率。ABR特别适用于突发性的应用。 - 未指定比特率
unspecified-bit-rate, UBR类是一种尽力传递、但没有任何保证的服务。
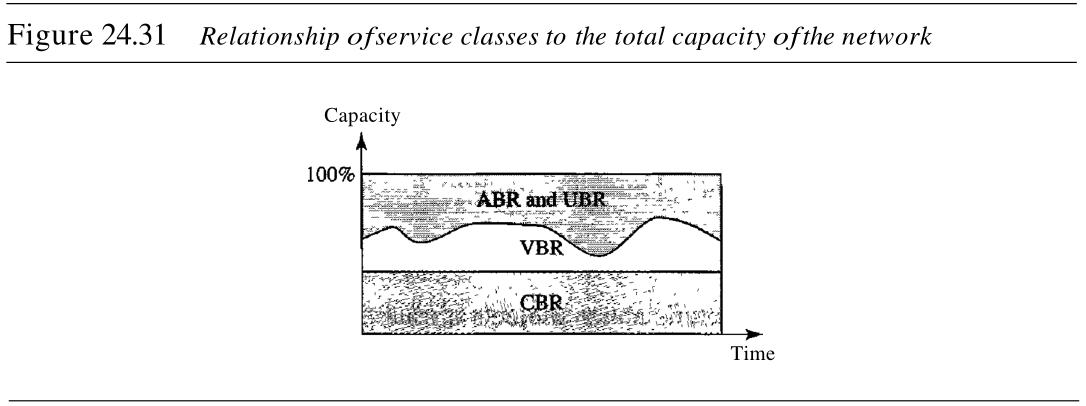
图24.31说明了不同类的服务与网络总容量的关系。
2. 用户相关属性
ATM定义了两组属性。用户相关属性是定义用户要以多快的速率发送数据的属性,是在用户和网络之间约定时协商而定的。下面是一些用户相关属性:
- 持续信元速率
sustained cell rate, SCR是一段较长时间间隔的平均信元速率。实际信元速率可能低于或高于这个值,但是平均值应该等于或小于SCR。 - 峰值信元速率
peak cell rate, PCR定义了发送方的最大信元速率。只要能维持SCR,用户的信元速率有时就能达到该峰值。 - 最小信元速率
minimum cell rate, MCR定义了发送方能接受的最小信元速率。例如,如果MCR是 50000 50000 50000 ,那么网络必须保证发送方至少每秒发送 50000 50000 50000 个信元。 - 信元可变延迟极值
cell variation delay tolerance, CVDT是表示信元传输时间变化量的一个量。例如,如果CVDT是 5 ns 5textrm{ns} 5ns ,则表示在传递信元的过程中,最大延迟和最小延迟之差不能超过 5 ns 5textrm{ns} 5ns 。
3. 网络相关属性
网络相关属性定义了网络的特性。下面是一些网络相关属性:
- 信元丢失率
cell ross ratio, CLR定义的是在传输期间信元丢失(或传递得太迟、以致于它们被视为丢失)的比率。例如,如果发送方发送了 100 100 100 个信元,丢失了 1 1 1 个信元,则CLR是 1 100 dfrac{1}{100} 1001 。 - 信元传送延迟
cell transfer delay, CTD是一个信元从源端传输到目的端所需要的平均时间。最大CTD和最小CTD也属于网络相关属性。 - 信元延迟变化量
cell delay variation, CDV是CTD的最大值和最小值之差。 - 信元差错率
cell eπor ratio, CER定义错误传递信元的比率。
最后
以上就是无私战斗机最近收集整理的关于【计算机网络】第五部分 传输层(24) 拥塞控制和服务质量24.1 数据通信量24.2 拥塞24.3 拥塞控制24.4 两个示例24.5 服务质量24.6 改进QoS的技术24.7 综合业务24.8 差分业务24.9 交换网络中的QoS的全部内容,更多相关【计算机网络】第五部分内容请搜索靠谱客的其他文章。








发表评论 取消回复