Base64编解码
1、应用目的
在计算机中任何数据都是按ascii码存储的,而ascii码的128~255之间的值是不可见字符。将数据先做一个Base64编码,统统变成可见字符,在多设备数据传输的过程中,可以降低数据出错的可能性。
2、解决问题
- 使用Base64可以解决客户端与服务器数据传输中文本乱码问题
- 解决编解码过程中,由于传输数据过程中数据转化为二进制导致文本数据长度改变,导致签名过程中
RSA_verify函数出现段错误。
const unsigned char *sigbuf, unsigned int siglen, RSA *rsa);
3、算法原理
- 把3个8位字节(3*8=24)转化为4个6位的字节(4*6=24)
- 假设有一个字符串, 需要对这个字符串分组, 每3个字节为一组, 分成N组
- 将每一组的3个字节拆分, 拆成4个字节, 每个字节有6bit
- 在6位的前面补两个0,形成8位一个字节的形式
- 每个组就从3个字节变成了4个字节
- 结论: base64编码之后的字符串变大了,
- 如果剩下的字符不足3个字节,则用0填充,输出字符使用’=’,因此编码后输出的文本末尾可能会出现1或2个’=’, 表示补了多少字节,解码的时候,会自动去掉。

4、openssl 中base64的使用
OpenSSL中文手册之BIO库详解: https://blog.csdn.net/liao20081228/article/details/77193729
// 创建BIO对象
BIO *BIO_new(const BIO_METHOD *type);
// 封装了base64编码方法的BIO,写的时候进行编码,读的时候解码
BIO_METHOD* BIO_f_base64();
// 封装了内存操作的BIO接口,包括了对内存的读写操作
BIO_METHOD* BIO_s_mem();
// 创建一个内存型的BIO对象
// BIO * bio = BIO_new(BIO_s_mem());
BIO *BIO_new_mem_buf(void *buf, int len);
// 创建一个磁盘文件操作的BIO对象
BIO* BIO_new_file(const char* filename, const char* mode);
// 从BIO接口中读出len字节的数据到buf中。
// 成功就返回真正读出的数据的长度,失败返回0或-1,如果该BIO没有实现本函数则返回-2。
int BIO_read(BIO *b, void *buf, int len);
- buf: 存储数据的缓冲区地址
- len: buf的最大容量
// 往BIO中写入长度为len的数据。
// 成功返回真正写入的数据的长度,失败返回0或-1,如果该BIO没有实现本函数则返回-2。
int BIO_write(BIO *b, const void *buf, int len);
- buf: 要写入的数据, 写入到b对应的设备(内存/磁盘文件)中
- len: 要写入的数据的长度
// 将BIO内部缓冲区的数据都写出去, 成功: 1, 失败: 0或-1
int BIO_flush(BIO *b);
- 在使用BIO_write()进行写操作的时候, 数据有时候在openssl提供的缓存中
- 将openssl提供的缓存中的数据刷到设备(内存/磁盘文件)中
// 把参数中名为append的BIO附加到名为b的BIO上,并返回b
// 连接两个bio对象到链表中
// 在链表中的关系: b->append
BIO * BIO_push(BIO *b, BIO *append);
- b: 要插入到链表中的头结点
- append: 头结点的后继
// 把名为b的BIO从一个BIO链中移除并返回下一个BIO,如果没有下一个BIO,那么就返回NULL。
BIO * BIO_pop(BIO *b);
typedef struct buf_mem_st BUF_MEM;
struct buf_mem_st {
size_t length; /* current number of bytes */
char *data;
size_t max; /* size of buffer */
unsigned long flags;
};
// 该函数也是一个宏定义函数,它将b底层的BUF_MEM结构放在指针pp中。
BUF_MEM* ptr;
long BIO_get_mem_ptr(BIO *b, BUF_MEM **pp);
// 释放整个bio链
void BIO_free_all(BIO *a);
BIO内部维护了一条双向链表,这使得构造好一个BIO链表之后,具体的业务操作会变的非常方便,整个BIO链会自动将数据进行指定操作的系列处理。
下图描述了一条读写的BIO链。
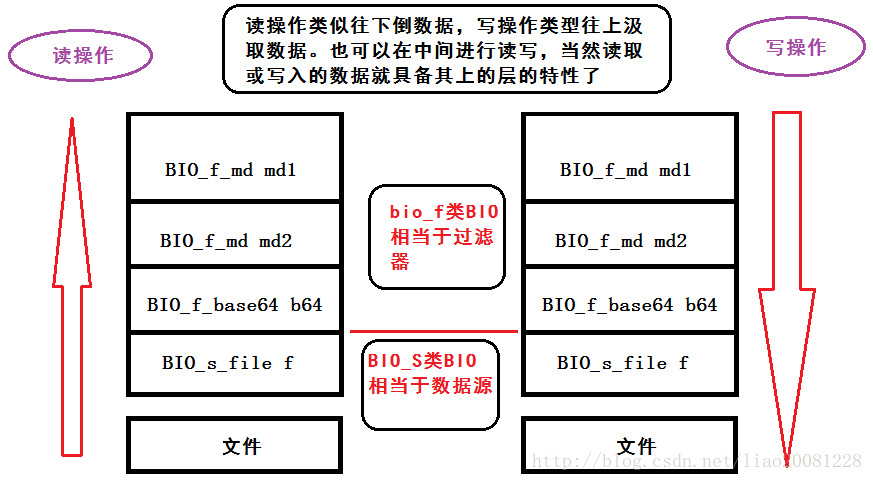
5、 BIO链的写操作
char* data = "hello, world";
// 创建base64编码的bio对象
BIO* b64 = BIO_new(BIO_f_base64());
// 最终在内存中得到一个base64编码之后的字符串
BIO* mem = BIO_new(BIO_s_mem());
// 将两个bio对象串联, 结构: b64->mem
BIO_push(b64, mem);
// 将要编码的数据写入到bio对象中
BIO_write(b64, data, strlen(data)+1);
// 将数据从bio对象对应的内存中取出 -> char*
BUF_MEM* ptr;
// 数据通过ptr指针传出
long BIO_get_mem_ptr(b64, &ptr);
char* buf = new char[ptr->length];
memcpy(buf, ptr->data, ptr->length);
printf("编码之后的数据: %sn", buf);
6、 BIO链的读操作
// 要解码的数据
char* data = "xxxxxxxxxxxxxxxxxxxx";
// 创建base64解码的bio对象
BIO* b64 = BIO_new(BIO_f_base64());
#if 0
// 存储要解码的数据
BIO* mem = BIO_new(BIO_s_mem());
// 将数据写入到mem对应的内存中
BIO_write(mem, data, strlen(data));
#else
BIO *mem = BIO_new_mem_buf(data, strlen(data));
#endif
// 组织bio链
BIO_push(b64, mem);
// 读数据
char buf[1024];
int BIO_read(b64, buf, 1024);
printf("base64解码的数据: %sn", buf);
7、总结
- Base64编解码可以有效的降低数据传输中出错的可能性
- Base64编解码可以解决数据传输过程中,数据长度发生变化,导致
Openssl库中的接口API报错的情况(作为函数参数传递)。 BIO内部维护了一条双向链表,构造好一套BIO链之后,指定头节点后,BIO链会自动将数据进行指定操作的系列处理。- 封装Base64思想编解码(待续)。
最后
以上就是健壮冥王星最近收集整理的关于Base64编解码Base64编解码的全部内容,更多相关Base64编解码Base64编解码内容请搜索靠谱客的其他文章。
本图文内容来源于网友提供,作为学习参考使用,或来自网络收集整理,版权属于原作者所有。








发表评论 取消回复