消费者物联网设备的信息暴露:一种多维的、网络知情的测量方法
摘要
物联网设备越来越多地出现,有利也有弊。在方便了使用的同时,也存在着信息泄漏的风险。但由于设备的用户界面、协议和功能都是异构的,因此很难深入和大规模地理解这些风险。
在这项工作中,对美国和英国实验室中的81个设备进行了多维度的信息暴露分析。最后,将对照实验与由36名参与者组成的现场用户研究收集的数据进行了比较。
1 介绍
消费者物联网设备越来越受欢迎,可以提供很多服务。通过结合丰富的传感器(如摄像头、麦克风、动作传感器)和互联网连接,这些设备有潜力了解和暴露用户及其周围环境的广泛信息。由于大多数此类设备缺乏任何显示信息暴露的界面,因此迫切需要进行研究,为此类大规模暴露提供透明度,并确定不同司法管辖区的相关隐私影响。
有几个关键挑战限制了我们对物联网设备信息暴露及其隐私影响的理解。首先,物联网设备生态系统通常是封闭的,因此信息暴露的基本事实并不容易获得。在缺乏事实真相的情况下,我们必须制定分析信息暴露的策略。也就是说,我们专注于使用基于包含在(可能是加密的)网络流量中的信息的推论。其次,大规模描述物联网信息暴露的特征很麻烦,它需要手动设置大量设备,使用小心控制的交互,并捕捉它们产生的显著网络流量,也需要新的技术来自动化物联网设备实验,收集数据并进行分析。第三,之前的所有研究都集中于一个管辖区的研究团队基于与物联网设备交互的信息暴露。有必要了解相同的设备在具有不同隐私法的司法管辖区以及被大量用户使用时的行为。
主要研究贡献包括:
•分析我们认为是迄今为止最大的流行消费者物联网设备集合。
•半自动化控制实验,可进行大规模的设备分析,加上6个月的非受控实验,作为irb批准的研究的一部分。
•苹果与苹果首次在不同的隐私法律管辖范围内对设备行为进行比较。
•使用上述测试平台的功能来分析网络流量的目的地,衡量哪些信息在互联网上暴露给其他方,评估设备交互可以如何基于网络流量进行预测。
•分析空闲流量,检测意外的设备活动。
2 定义和目标
这项工作测量来自流行的消费者物联网设备的网络活动和相应的信息暴露。特别是我们将重点关注其IP流量目的地的特征、此类流量是否通过加密进行保护,以及这种公开的潜在隐私影响是什么。
2.1定义
物联网设备暴露的信息。为了本研究的目的,我们定义了物联网设备可以暴露的三类信息。
•存储数据。包括设备标识符和用户在设备激活期间给出的个人身份信息、活动日志、设备状态等
•传感器数据。这包括物联网设备的传感器获得的信息,如运动检测、视频监控视频、音频记录。
•活动数据。这包括关于用户如何与设备交互的信息(例如,通过移动设备上的应用程序或物联网设备上的按钮),以及设备的哪些功能被使用(例如,切换灯)。
我们专注于使用受控实验和网络流量分析检测基线信息暴露。
信息被暴露的当事人。当信息由物联网设备公开时,它会显式地与其IP流量的目的地共享,并隐式地与被动地观察其网络流量的任何一方共享。我们首先根据物联网设备所联系的IP地址的所有者定义第一、支持和第三方。
•第一方。负责实现设备功能的物联网设备制造商或相关公司。
•支持方。任何提供外包计算资源的公司,如CDN和云提供商。
•第三方。不是第一方或支持方的任一方。这包括广告和分析公司。
除了IP流量的目的之外,我们还考虑网络窃听者,他们可以被动地观察物联网设备(如设备的互联网服务提供商(ISP))暴露的信息。
隐私问题。“非第一方”指任何支持方或任何第三方。为了解信息暴露是否涉及隐私问题,我们考虑:
•网络流量中包含的、暴露给非第一方的任何个人身份信息(PII);
•向非第一方暴露的任何用户录音(音频/视频/图像)或用户活动(动作传感器、看电视习惯),或以普通用户既没有披露也没有预料到的方式暴露给第一方;
•允许非第一方观察家中设备的任何网络流量收集,它们何时被使用,以及如何被使用(例如,用于分析用户)。
2.2目标
在本节中,我们定义了关于不同信息暴露的关键研究问题。
RQ1:网络流量的目的地是什么?
与第三方的沟通可能是一个隐私问题,因为这些第三方可以跟踪用户的信息,可能是为了将数据货币化(例如,通过广告)。此外,为多个物联网设备(包括来自不同制造商的设备)提供服务的支持方可以获得家庭活动的详细可见性。最后,跨越国际边界的数据可能受到不同的隐私法律的约束,包括合法的拦截法规。
RQ2:流量被加密到什么程度?
使用加密可以防止敏感信息暴露给窃听者,而缺乏加密可能会暴露设备的身份、与设备的交互以及其他敏感信息。
RQ3:哪些数据以明文形式发送?
当明文网络流量包含敏感数据时,我们将其视为隐私问题。
RQ4:哪些内容使用加密发送?
虽然传统上认为加密可以提供机密性,但加密本身并不能防止敏感信息的泄露。例如,敏感数据可能通过加密暴露给第三方,或者窃听者可能根据加密的流量模式和明文协议信息(例如,TCP/IP报头、TLS握手)可靠地推断设备类型和活动。
RQ5:设备是否意外暴露信息?
有些报道表明,智能音箱偷偷地、连续地录制音频,并将其传输给他们的提供商。更一般地说,我们关注敏感信息(例如,用户录音),用户希望仅通过显式交互暴露这些信息。当它暴露给任何一方(即使是第一方)时,这就成为了一个隐私问题,因为用户并没有故意触发这种暴露。
RQ6:设备的位置(管辖权,网络出口的位置)是否影响信息暴露?
物联网设备可能被允许暴露或多或少的信息,这取决于地区法规(如欧盟的GDPR)。位于或其网络流量出口的相同设备的暴露差异可能表明对当地法律的适应情况不同。
2.3非目标
修改的设备。我们在实验中只使用未经改造的装置。修改设备或其固件可能会揭示有关信息暴露的基本事实,但这样做无法扩展到大量的设备。
不使用MITM。我们不使用中间人(MITM) TLS连接来显示加密流量的明文内容。由于MITM通过改变设备行为影响了我们结果的有效性,我们选择在本研究中不这么做。
没有配套的应用流量。我们在实验室中捕获所有网络流量,包括用于与物联网设备交互的配套应用程序的流量。然而,由于我们发现,除了使用之前的技术发现的信息外,几乎没有额外的信息暴露,因此我们只关注由物联网设备产生的流量。
不完备。在我们的测试中,我们无法从物联网设备中识别所有暴露的信息。此外,我们无法量化我们所测量的信息暴露的隐私风险。相反,我们关注的是暴露的信息、潜在的隐私影响,以及意外暴露敏感数据的案例研究。
3数据收集方法
3.1物联网设备
我们的分析包括81台具有IP连接的物联网设备:46台购买自美国商店(美国设备)并部署在美国试验台,35台购买自英国商店(英国设备)并部署在英国试验台。这两个实验室共有26种通用设备。设备分为以下几类:摄像头(安全摄像头和视频门铃)、智能hub(作为非ip物联网设备桥梁的家庭自动化设备,如Zigbee、Z-wave和Insteon设备)、家庭自动化设备(智能灯、插座和恒温器)、电视(实际电视和电视狗)、音频(带语音助手的智能扬声器)和家电(冰箱、清洁用具、烹饪用具、气象站)。
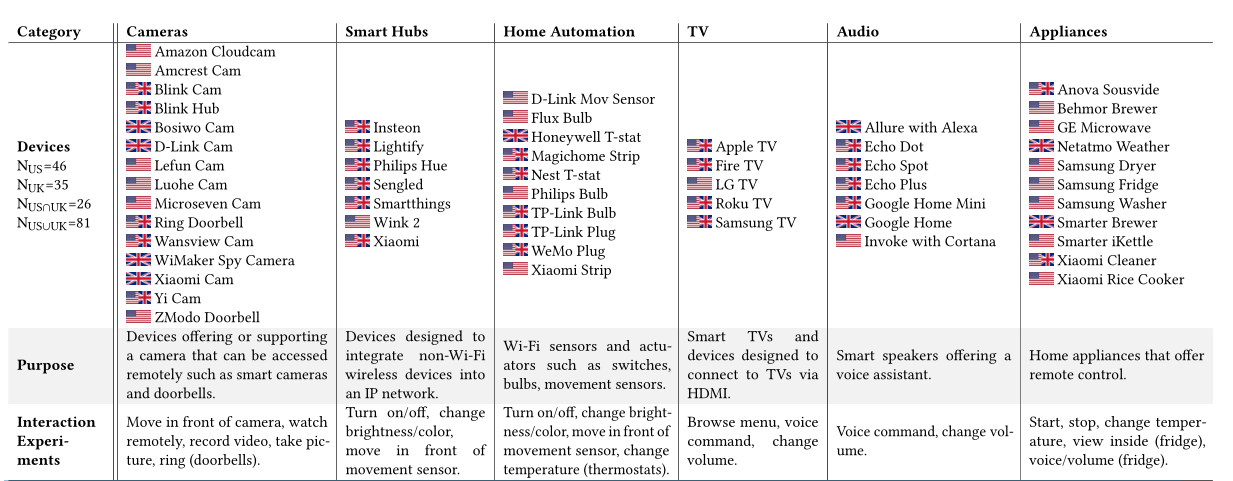
表:测试中的物联网设备。从上到下:按类别分类的物联网设备、它们在类别中的共同用途,以及我们在类别中的所有设备上执行的交互实验(如果可用)。
3.2试验台
这些设备被部署在美国和英国的试验台上,使用相同的数据收集和实验基础设施。
网络。这两个试验台都包括提供网络连接和数据收集的服务器。每个测试平台中的服务器配置相同,包括一台运行Ubuntu 18.06的Linux服务器,具有两个有线网络接口和两个Wi-Fi适配器桥接有线物联网网络,用于正在测试的无线物联网设备(一个用于2.4GHz设备,一个用于5GHz设备)。多个有线物联网设备通过网络交换机连接到有线物联网网络中。物联网设备通过服务器端实现的标准NAT与公网进行通信。
为了测试出口IP地址对信息公开的影响,我们配置了VPN隧道连接美国实验室和英国实验室。只有在标记为VPN的实验中,网络流量才会通过这些隧道。
数据收集。通过测试平台的网络网关服务器的所有流量都是使用tcpdump自动捕获的,每个MAC地址使用不同的文件来分离来自不同设备的流量。我们指定标签(存储在额外的pcap文件中)来隔离与设备进行特定交互时产生的流量(例如,“打开智能灯”)。
用于交互的辅助设备。我们的实验包括手动和自动交互。对于需要配套应用程序的物联网设备,我们使用运行Android 6.0.1的Nexus 5X智能手机。对于需要语音助手的物联网设备,我们使用Echo Spot。对于通过语音助手进行的交互,我们使用基于云的谷歌语音合成器根据自动化实验中指定的文本生成语音命令,并通过位于语音助手设备(如Echo Spot)附近的扬声器播放这些命令。
3.3实验
我们进行受控、空闲和不受控的实验来分析设备在不同条件下暴露的信息。所有受控和空闲的实验都通过VPN隧道进行了重复。总共进行了34,586次对照实验(20,777次使用美国试验台,13,809次使用英国试验台),外加112小时的空闲实验。
电力实验。在初步研究中,我们发现大多数物联网设备在通电时交换相当大的流量。因此,我们的电力实验包括给设备上电(之前从交流电源断开),并在没有任何交互的情况下收集两分钟的网络流量。
相互作用实验。为了解与设备交互时暴露的信息,我们进行了交互实验。这包括与物联网设备的积极交互,然后用交互名称标记捕获的流量。对于每一个这样的实验,我们首先等待设备上电至少两分钟(以避免包括电力实验流量)。两分钟后,就在交互开始之前,我们开始捕捉流量,并在整个交互过程中继续这样做,在交互完成后,至少需要5-15秒的时间。
空闲实验。在最初的上电阶段之后,人们可能会认为物联网设备在不活跃使用时的信息暴露最小。为了测试,我们进行了一些空闲实验,在物联网设备不被积极使用且位于与人类交互隔离的环境中时,捕获其流量。我们的空闲时间为每个实验室一周平均每晚8小时。
非受控实验(仅限美国)。这些实验包括在irb批准的用户研究期间捕获由物联网设备在美国试验台产生的所有(未标记的)流量。参与者可以在任何时间使用实验室(除了我们进行空闲实验期间),他们可以使用房间里任何他们认为合适的设备。
为了衡量物联网流量的区域差异,我们使用了两种方法。首先,我们比较了英国和美国实验室中常见设备暴露的信息,信息暴露方面的任何差异都可以由以下因素来解释:在不同市场销售的硬件/固件的差异、出口IP地址、基于IP地址或位置的服务器选择,以及每个司法管辖区的数据保护法规。其次,我们使用实验室之间的VPN连接来比较通过美国IP地址出口到公共互联网的美国设备和通过英国IP地址出口到公共互联网的相同设备(反之亦然,对于英国实验室设备)。在这种情况下,每对场景的硬件/固件和管辖权是相同的,但出口IP地址(以及根据IP选择的服务器)不同。我们将这些场景的观察结果结合起来,以帮助确定观察到的信息暴露差异的可能根源。
4目标分析
4.1测量目的地
在本节中,我们将根据物联网设备的目的地址是第一方、第三方还是支持方来分析物联网设备流量的目的地址。我们使用以下方法来标记目的地IP的当事方和地理位置。
二级域名(SLD)。对于来自设备的每个流,我们首先确定目的IP地址是否对应于设备发出的请求的DNS响应,从而确定SLD。如果是,我们使用SLD进行相应的DNS查找;否则,我们搜索HTTP报头(主机字段)和/或TLS握手(服务器名称指示字段)的域。如果以上任何一种方法都不能产生一个域,我们将不标记IP的SLD。
识别组织的名字。我们使用WHOIS数据或常识性匹配规则来识别SLD的组织名称。如果我们不能识别一个域的SLD,我们将组织设置为相应的区域注册表所报告的IP地址的所有者(例如,欧洲IP的RIPE)。
确定类型。如果在上一步中确定的IP组织与物联网设备的名称、制造商或相关公司相匹配,我们将其归类为第一方。如果没有,我们手动搜索有关该政党的公共信息。如果该公司在其网站上声明其专门提供连接(CDN)或云服务(如Amazon AWS),则我们将该方视为支持方。在任何其他情况下,我们认为该方为第三方。
决定政党的国家。我们使用了Passport工具,该工具能够通过将traceroute数据与其他IP地理位置源结合起来,推断出包含目标IP地址的国家。
4.2目标描述
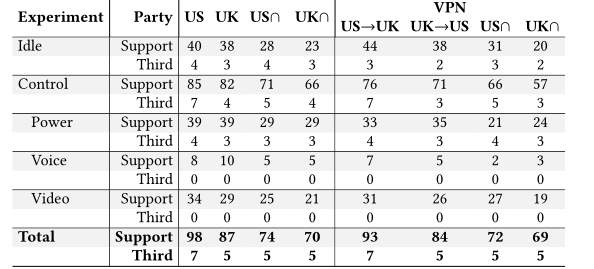
表:通过设备联系的非第一方的数量
该表显示了美国和英国设备联系的每种实验的唯一目的地的数量。表格的第一列显示了实验的类型,第二列显示了一方的类型(支持与第三),其余的列显示了使用以下符号表示的一组设备的值。
从表中可以看出,与其他类型的实验相比,控制性实验可以为支持方和第三方提供更多的交流。其中,功率实验代表了与第三方的大部分通信,这可能是由于设备与目的地方建立了初始连接。
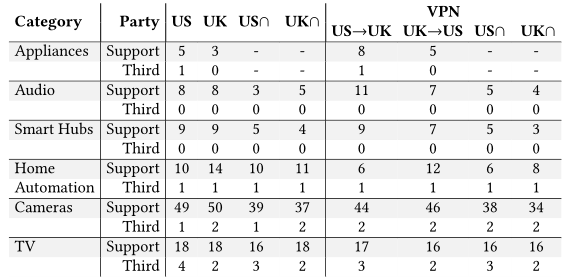
表:按设备联系的非第一方人数,按设备类别(第一列)、当事人类型(第二列)分组。右列指定实验室位置和网络连接性
上表显示了两个数据集中每个类别中唯一目的地的数量。电视(如三星电视、LG电视、Roku电视、Fire电视)在所有设备类别中接触第三方数量最多。
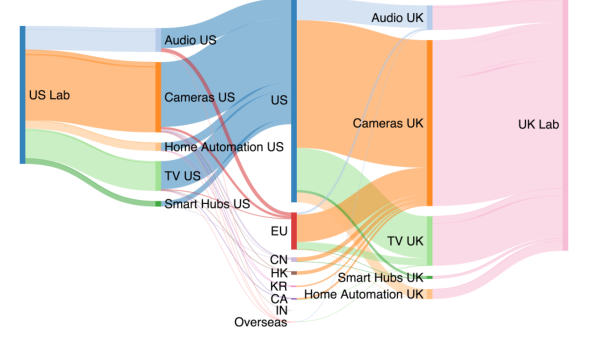
图:美国(左)和英国(右)实验室到前7个目的地地区(中)的网络流量。
上图显示了从普通设备到美国(左)和英国(右)实验室的流量,每个波段的高度对应于传输的字节数。结果按设备类别(左中、右中)分组,终点为目的地国家/地区(中)。对于美国和英国的实验室来说,大多数设备流量都在美国终止,可能是由于对基础设施的依赖和有限的地理多样性。
4.3常用联系目的地
接下来,我们分析哪些非第一方域名和公司接触到最多的设备。即使是对特定家庭中设备的一个重要子集的了解,也可以用于为数据驱动的算法(如定向广告)对用户进行配置。
在此分析中,我们将重点关注目标组织,例如,nest.com和google.com属于拥有这两个属性的谷歌组织。单个设备可以联系多个组织,例如,三星电视可以联系两个非第一方组织:Netflix(第三方)和Amazon AWS(支持方),后者托管Netflix。
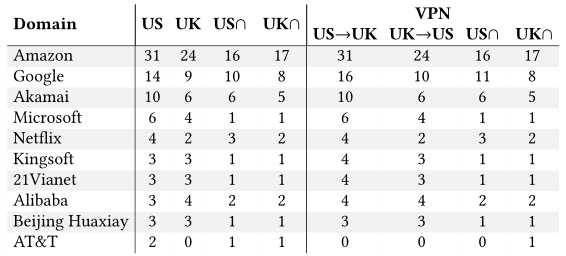
上表列出了设备数量最多的10家公司。我们发现,美国的31台设备和英国的24台设备至少联系了一台属于亚马逊的服务器,这在很大程度上是因为它们依赖于AWS来托管服务器。其次最常联系的组织也是托管提供商:谷歌、Akamai和Microsoft。因此,向非第一方暴露的信息量的一个重要因素是使用提供计算资源的支持方。
在我们的试验台上,几乎所有的电视设备都与Netflix联系,尽管我们从未为任何一台电视配置过Netflix账户。这至少向Netflix公开了一个特定位置的电视模式的信息。榜单的下半部分(除了美国电话电报公司)是亚马逊和谷歌的中国同行。这些服务器主要由中国公司设计的设备连接。
一般来说,通过VPN将设备连接到互联网不会导致显著的差异。唯一意想不到的案例是,美国的小米电饭煲只有通过VPN连接才会联系金山,通常情况下它会联系阿里巴巴云服务。
4.4
当只关注物联网设备连接的目的地时,我们发现了一些隐私问题。一些非第一方目的地(特别是Amazon、谷歌和Akamai)从我们的许多物联网设备接收信息,从而使它们能够潜在地对消费者进行分析。此外,我们发现电视在第三方通信中占比最大(可能是为用户定制内容)。关于地区差异,我们注意到,美国设备倾向于联系更多的非第一方,可能是由于对欧盟更宽松的隐私法规。VPN对所联系的一方的类型影响最小,最大的差异可能是由于使用更靠近VPN出口的副本提供内容。
5加密分析
5.1识别加密流量
我们首先使用Wireshark的协议分析器来识别TLS(不包括握手)和QUIC流量是加密的。
对于其余的流量,我们没有关于流量是否被加密的基本事实。因此,我们通过测量字节熵H来推断在这些流上使用了加密,其值在0和1之间,较高的值意味着字节序列更接近于随机。
我们对加密和未加密的内容(即IMC 2019网页)进行了额外的测试,以了解不同加密算法和密码套件的熵值如何变化。未加密内容的熵Hunenc = 0.55 (σ=0.07, min=0.35, max=0.62)。根据这些观察,我们无法确定一个始终能够正确地对加密和未加密的有效载荷进行分类的阈值。
有鉴于此,我们为连接是否加密选择了保守的阈值,目的是减少假阳性/假阴性,同时将剩余的情况归入“未确定”类别。具体来说,我们将熵H >0.8的流量分类为可能加密的流量,H <0.4的流量为可能未加密的流量,0.4≤H≤0.8的流量为未知流量,对应的是未确定的加密状态。
注意,上面的分析假设未加密内容和加密内容之间的熵有很大差异。我们发现这一假设不适用于媒体内容。因此,对于没有使用识别编码过滤掉的媒体(音频/视频)内容,我们使用第6节中描述的技术,使用它们的网络流量模式来识别并排除它们。
5.2加密采用
在本节中,我们将分析我们的美国和英国设备采用加密技术的情况。首先,我们显示我们识别为未加密、加密或未知的流量的比例。然后对于未加密的流量,我们识别设备类别和活动之间的模式。
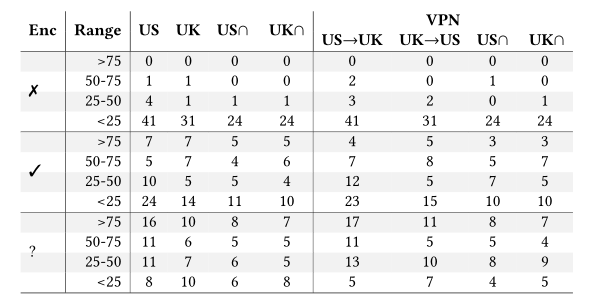
表5:跨实验室和网络的四分位数分组中按加密百分比计算的设备数量
整体采用。上表显示了部分数据未加密(第一行×)、加密(第二行✓)和未知(第三行“?”)的物联网设备的数量。每个子行表示我们使用四分位数进行分类时考虑的流量的分数。前两列考虑所有美国和英国设备的集合,第三和第四列考虑两个测试床中共有的所有美国和英国设备的集合。其余列显示前四列的相同数据,但使用VPN出口。
该表显示了一些积极的趋势:没有设备有超过75%的未加密流量,只有一台设备(在每个测试平台中)有超过50%的加密流量,而7台设备(在每个测试平台中)有超过75%的加密流量。我们还观察到一些负面趋势,揭示了可能的信息泄露:美国的5个设备和英国的2个设备发送了超过25%的未加密流量,而美国的8个设备和英国的10个设备发送的未知流量都超过25%。
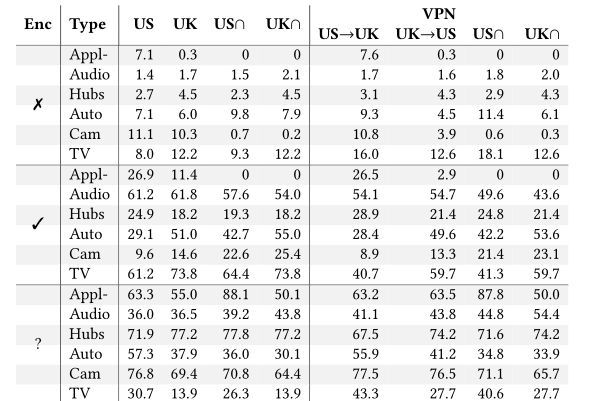
表6:对于每个设备类别,相应设备发送的未加密字节的平均百分比。
采用类别。我们现在根据设备的类别,分析设备暴露的未加密数据。上表显示了所有设备在每个类别(行)中暴露的数据的百分比,划分成不同的实验位置和出口配置(列)。一个关键的观察结果是,摄像头集体暴露了最大比例的未加密字节。另一个重要的观察结果是,家电、家庭自动化设备和智能集线器拥有最大比例的未知流量。经过人工调查后,我们发现这些设备有很大一部分是Wireshark不知道的专有协议,这些协议通常是部分加密的,这使得熵分析不确定,并激发了未来的调查。
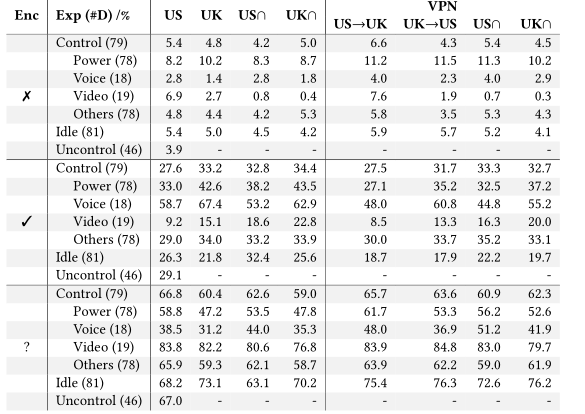
表8:未加密发送的字节百分比,按实验类型分组。每行中考虑的设备数量在第一列的括号中。
按实验类型进行加密分析。我们现在研究实验类型是否对发送的加密字节的比例有任何影响。我们在上表中报告的结果显示,视频加密字节的比例最低,而语音交互的比例最高。这类似于对电视和音频设备的类别分析。其他没有直接映射到特定类别的实验,没有显示出明显的趋势,这意味着加密技术的差异主要是由于设备本身,而不是实验类型。
这一观察结果也适用于不同地区的普通设备。然而,我们注意到一些不太重要的趋势,这可能需要进一步的研究来了解潜在的原因:功率实验最容易使用熵分析进行分类,并且显示了最高比例的未加密流量(>8.2%)和未加密流量(>33.0%)。我们还观察到设备通过VPN连接时的差异(例如,加密和未加密的视频设备流量)。这些差异显示不出明确的模式,可能是由于当设备检测到不同区域时设备行为的变化(例如,类似于电视上看到的不同内容/功能)。
5.3
虽然未加密的流量只占所有流量的一小部分,但我们确定了所有设备、类别、交互和区域通过明文流量暴露的大量信息。跨设备类别和设备交互的未加密流量的大多数差异是由特定设备造成的,而不是整个设备类别特有的。我们观察到加密使用的区域差异,特别是在电视类设备中,因为它们与不同的内容提供商交互,这取决于它们检测到的区域。
6内容分析
6.1识别PII和设备活动
我们使用以下技术来识别PII和网络流量中的设备活动。
文本PII在未加密的流量。为了识别以明文形式暴露的PII,我们只需在每个设备的网络流量中搜索任何已知的PII(在各种编码中)。出于分析的目的,PII包括设备标识符(例如,MAC地址、UUID等)和注册时提供的任何个人信息(例如,姓名、电子邮件地址、家庭地址、电话号码、用户名、密码等)。
设备活动推断(加密或未加密)。为了根据网络流量推断设备活动(不管它是否被加密),我们为每个设备交互使用实验标签和网络流量训练一个随机森林机器学习分类器。我们标签中包含的设备活动的例子包括设备上电、发出语音命令、查看视频流。
我们观察到,来自某些设备的实验包含了直接由实验交互产生的网络流量,以及与实验无关的网络流量(如通过NTP进行时间同步)。因此,我们为每个交互类型利用了多个交互(30个自动化测试,3个手动测试),来减轻交通噪音的影响。自动化用例中的大量测试也提供了足够的样本来应用交叉验证,从而允许我们评估我们方法的准确性。
6.2未加密的文本内容
在未加密的通信中,我们发现可识别内容有限,PII更少。这是一个好消息,特别是与之前在其他环境(如移动应用程序和网站)中识别大量在纯文本中暴露的PII的工作相比。
在我们的两个实验室中,我们都发现Magichome Strip以明文形式将其MAC地址发送到阿里巴巴托管的域名。有趣的是,Insteon hub将其MAC地址以明文形式发送到EC2域,但仅来自英国的实验室。我们在美国的实验室中没有发现类似的行为。有趣的是,每次小米摄像机检测到一个运动时,它的MAC地址、运动的时间和日期(明文)被发送到一个EC2域。我们还注意到一个视频包括了有效载荷。
6.3设备活动推理
在本节中,我们将描述如何训练机器学习分类器来估计有多少设备活动可以基于网络流量进行推断。请注意,我们并不要求(或尝试)根据准确性或F1分数等指标来生成性能最好的分类器。相反,我们使用这些指标来理解设备活动是否可以推断,如下所述。
为了可靠地推断设备活动,我们首先使用7/3分割交叉验证来验证我们的机器学习分类器(即,随机选择70%的数据进行训练,测试剩余的30%的数据,然后我们重复这个过程10次以获得平均指标)。然后我们使用F1得分,定义为调和平均数之间的精度和召回,作为质量指标评估的效果检测的假阳性和假阴性的活动装置,其中F 1 = 0是最差的分数和F 1 = 1是最好的分数。我们计算设备每个活动的F1得分(定义为该活动的F1得分),以及每个设备所有活动的F1得分(定义为该设备的F1得分)。当一个活动或设备的F1值大于0.75时,我们认为它是可推断的。
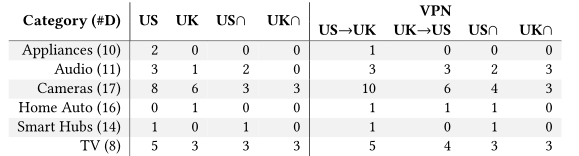
表:可推断设备的数量(F1评分> .75),按类别分组。第一列括号内的每个类别的设备总数。
每个类别的可预测设备。上表显示了使用我们的分类器几乎所有动作都可以推断的设备数量。摄像机拥有最多的可推断设备,其次是电视设备和音频设备。另外可以看到,在大多数情况下,我们在不同地区的可推断设备数量上存在一些差异(例如,在美国可以推断2个音频设备,在英国可以推断0个设备)。如果我们比较有和没有VPN连接的每个实验室,我们也会观察到这种微小的差异模式(例如,在美国实验室中,可以推断出2个设备没有VPN, 1个有VPN)。
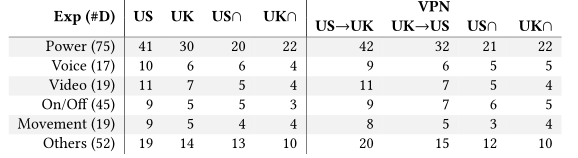
表:可推断活动的数量(括号中有这样一个活动的设备数量),按活动组聚合。当设备的F1分数为> .75时,我们认为该活动是可推断的。
具有可靠推断活动的设备。上表显示了我们可以可靠推断其活动的设备数量。我们发现,“Power”活动是最可推断的,因为它具有独特的交通模式,其次是视频和运动活动(由于与摄像机交互产生的大量数据)。每一种类型的活动都可以被认为是敏感的,因为它们表明家庭或其他部署空间信息中的存在和活动,这些信息可以很容易地被网络窃听者推断出来。在区域比较方面,上表还显示,不同地区可推断设备的数量存在差异(例如,美国可推断功率实验为41个,英国可推断功率实验为30个)。与前面的例子类似,我们也观察到可推断的设备有VPN和没有VPN的差异(例如,我们可以推断出9个提供移动活动的设备没有VPN, 8个提供VPN)。
6.4
在本节中,我们分析了未加密和加密的内容。首先,我们发现以明文形式暴露的敏感或个人信息非常有限—考虑到此类设备可能暴露的数据的敏感性,这是一个值得鼓励的观察结果。其次,我们发现,即使设备使用加密,其网络流量的时间模式也允许可靠地识别导致网络流量的交互。换句话说,一个偷听者能够可靠地了解用户与各种类型设备的交互,为分析和其他侵犯隐私的技术提供了可能。不同地区之间的推论存在差异,这是一个值得作为未来工作的一部分进行进一步研究的话题。
7意想不到的行为
在本节中,我们使用活动预测方法来检测空闲和不受控实验中的意外行为。
7.1测量意外行为
我们将意外行为定义为设备产生的网络流量对应于用户未发生或无意进行的交互。
7.2闲置实验
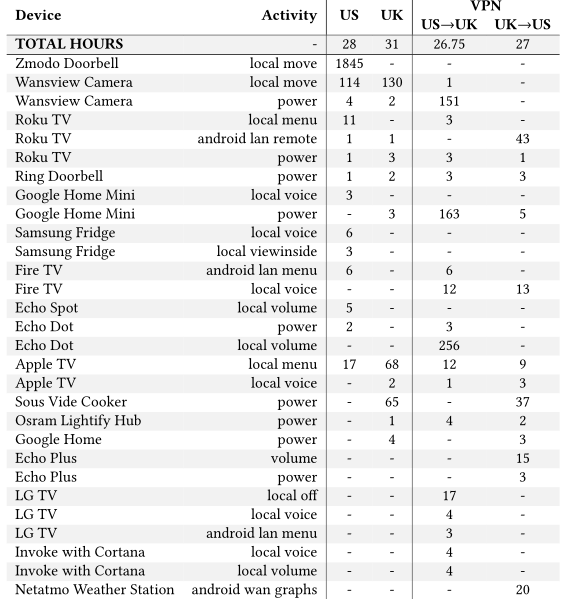
上表显示了我们在大约30小时的空闲实验中预测的可靠可预测活动的数量(详细信息在表的第一行)。最常检测到的活动有:所有设备的“power”活动、电视的“menu”活动(即导航电视主菜单屏幕的行为)和某些摄像机的“move”活动(即移动到摄像机前的行为)。我们还可以注意到一些不太常见和/或专门的活动(如“查看冰箱内部”)。
大量的“power”活动是由于设备经常断开和重新连接到Wi-Fi网络(我们通过DHCP服务器日志验证了这一点)。当设备重新连接时,它将与云服务执行一次新的握手,这与设备上电时类似。因此,我们不认为power活动是意外或可疑的。
我们认为,“菜单”活动是由电视来解释的,电视偶尔会刷新菜单页面的内容(例如,显示可供观看的新点播内容),当用户导航到“菜单”时所采取的操作大体相同。我们不认为这是意外或可疑的。
“移动”活动有时会在相机和/或运动传感器前没有移动时触发。在相机的情况下,设备记录视频时,它不是由移动触发,这是意想不到的和潜在的可疑。我们没有这种行为的根本原因。一种可能性是,尽管我们尽最大努力将每个摄像头与外部刺激隔离开来,但实验室中仍有一些东西触发了它们(例如,来自其他物联网设备的背景噪音)。另一种可能性是,这些设备有意捕捉这些视频。
地区比较。通过比较上表中美国和英国的列,我们可以看到空闲实验中检测到的行为的相似性和差异。两个实验室的Wi-Fi可靠性不同(通过DHCP日志确认)解释了功率实验(如真空烹饪器)的差异。然而,我们无法确定其他差异的根本原因,可能是由于实验室中常见设备之间的不确定性。
当使用VPN出口时,结果会有明显的不同,特别是智能音箱(来自Amazon和谷歌)和一个摄像头(Wansview)。虽然我们无法确定这些差异的根本原因,但这是一个未来工作的有趣领域。
7.3控制实验
我们使用同样的方法来分析六个月的数据,这些数据来自我们的非受控实验。大多数检测到的活动对应于我们确认在我们的实验室中流行/常见的互动(例如,使用微波炉,打开/关闭冰箱,在实验室中移动)。然而,由于在这些类别中检测到的活动数量众多,很难对所有这些类别进行手工核查。
相反,我们关注最敏感的和由分类器标记的意外活动,然后手动尝试触发相同的(意外)行为。我们将描述下面观察到的最有趣的案例。
环门铃。我们观察到,每当用户在门铃前移动时,门铃就会进行视频记录。然而,这是意想不到的行为。在发现这一几乎没有记录的功能后,我们登录账户去观看视频,并了解到我们必须每月支付额外的费用才能访问这些视频。我们还没有找到任何方法来关闭这个功能。
Zmodo门铃。当Zmodo门铃第一次打开时,以及当有人在它前面移动时,它都会上传摄像头快照。这个特性没有文档记载,我们无法阻止这样的快照被拍摄,也无法访问它们。
Alexa语音助理。在正常对话中,支持alexa的设备经常被触发。经过调查,我们发现默认的Alexa唤醒关键字“Alexa”经常被许多其他不相关的单词触发。一个显著的例子是以“我喜欢”开头的句子。我们知道这可能是语音识别技术的局限性,但这仍然是潜在的隐私暴露,因为亚马逊设备通常会在将整句话发送到服务器后识别错误激活。
7.4
虽然我们很少能肯定地识别出意外行为,但这样的情况确实存在,我们通过观察空闲流量识别出了许多情况。在我们不受控制的实验中,我们进一步发现了设备意外发送音频或视频的显著案例。我们的研究结果强调,对物联网设备暴露的信息的担忧是有理由的,因为进一步研究更准确的设备活动分类器和推断行为的根本原因。
8相关工作
我们现在回顾与物联网信息暴露相关的工作。
流量特性。之前的研究从不同的角度描述了物联网流量。关注是否使用加密,如果使用,如何滥用加密。而我们的研究扩展了之前的工作,考虑了更多的设备(81个),这些设备通常由于它们的大小和成本而被忽视(例如,大型电器,如冰箱、电视、洗衣机和烘干机),大量的实验(34,586个)由于我们的高自动化水平,我们的区域分析跨越了位于不同隐私司法管辖区的两个试验台。
异常行为检测。意外行为可以更一般地归类为异常检测,一个重要的前期工作的主题。之前的研究集中于入侵检测系统,这些系统通过使用设备搜索引擎、漏洞库和机器学习来识别已知和未知设备,从而检测攻击。另外,相关的工作集中在检测异常的策略实施方法上。我们在意外行为检测方面的贡献受到了上述方法的启发,但我们的机器学习方法独特地考虑了交互方法(例如,使用设备本地、通过其配套应用程序和通过语音助手),并包括大量的训练实验。
其他相关工作。其他相关工作涉及不同类别的物联网设备的信息暴露。
总而言之,我们的工作与之前的交通特征描述和异常检测工作中提出的许多目标和技术相同;然而,我们的主要和差异化的目标是增加此类分析的规模、实验的严谨性和地理多样性。我们通过分析不同地理位置和隐私管辖范围内的更广泛的设备,更广泛的交互实验,以及从6个月的自然发生的用户与我们的设备交互中不受控制的实验数据来补充受控的实验数据来实现这一目标。
9结论
我们观察到几个有希望的实践:大多数设备使用加密或其他编码来保护用户的PII,因此在明文中导致总体最小的PII暴露。然而,即使流量是加密的,且不依赖MITM或任何类型的物联网设备修改,我们的分析也识别出了信息暴露的显著案例:美国(英国)物联网设备联系的总目的地中57.45%(50.27%)是第三方或支持方,56%的美国设备和83.8%的英国设备联系其地区以外的目的地。我们进一步发现,很大一部分流量使用加密或其他未分类,而对于大多数设备,纯文本流量很少(有显著的例外),我们还发现,加密不会隐藏导致设备产生网络流量的各种交互,在许多情况下,允许窃听者推断消费者网络中的设备以及它们是如何使用的。我们从捕获音频和视频的设备中识别出意想不到的活动,我们发现了几个值得注意的情况,不同位置的曝光不同。这项研究是了解消费者物联网设备大规模信息暴露的第一步。为了便于更大规模的分析和重现性,我们的实验基础设施、代码和数据可以在https://github.com/NEU-SNS/intl-iot公开获得。
最后
以上就是醉熏砖头最近收集整理的关于Information Exposure From Consumer IoT Devices:A Multidimensional, Network-Informed Measurement论文笔记消费者物联网设备的信息暴露:一种多维的、网络知情的测量方法的全部内容,更多相关Information内容请搜索靠谱客的其他文章。








发表评论 取消回复