啥叫办公自动化
非IT专业人员打交道最多的三种文件: Word、Excel、PDF。
办公自动化就是把手工的操作通过编程自动化完成。 这个阶段讲: Word、Excel、PDF文件的读写,图表,简化日常工作。
1、老板让合并100个Excel表格,一顿操作猛如虎,一看工资2500。
2、其实Word、Excel等中的VBA编程、图表、公式玩6了就可以简化很多工作。 这个课程还是站在更专业的角度去编程,而且VBA慢慢也落伍了。
VBA写程序--Basic
使用yzk18-docs
1、Maven中引入yzk18-docs 。
2、看文档研究PDFHelpers的用法。就是对pdfbox的简单封装,没有封装的方法直接参考pdfbox的文档即可。
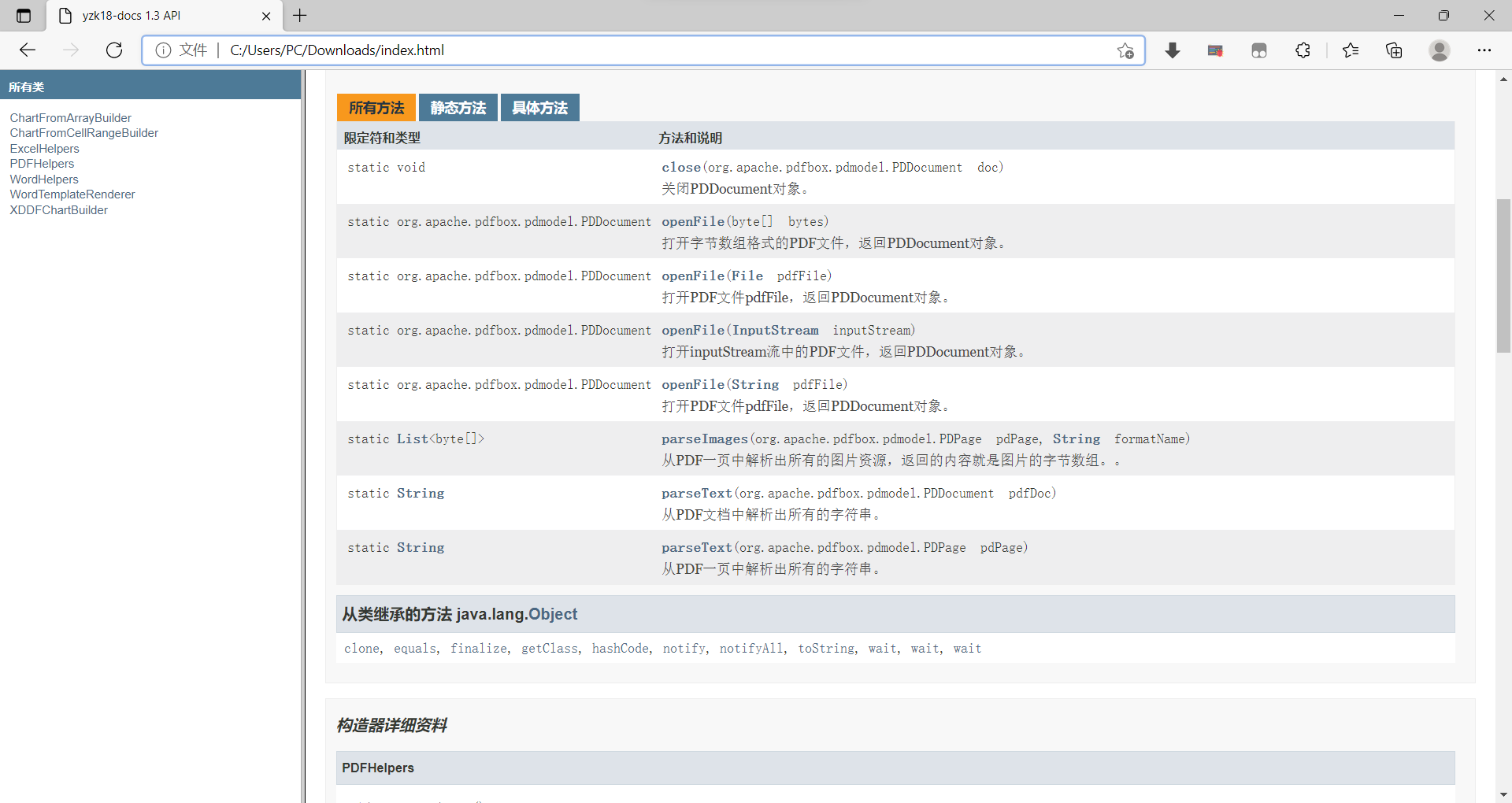
 PDF文档有扫描版和文字版
PDF文档有扫描版和文字版
有限PDF文档中图片中的文字我们使用PDFHelpers.openFile是识别不出来的,我们需要去一些厂商买他们的API接口,来识别。
PDDocument doc =PDFHelpers.openFile("D:\temp\PDF\柏可心宠物食品商业计划书.pdf");
System.out.println(doc.getNumberOfPages());//查找页数
PDPage page=doc.getPage(41);//因为程序是从零开始的,因此我们获取到的页数为42页
String s=PDFHelpers.parseText(page);//识别PDF中的文字
System.out.println(s);
PDFHelpers.close(doc);
可能我们读取到的PDF文档中的文字有重复,这是因为PDF与其他Doc等区别。每个文字是独立的,没有前后关系,只是坐标位置不同。
PDF-转Word都是不完美的。
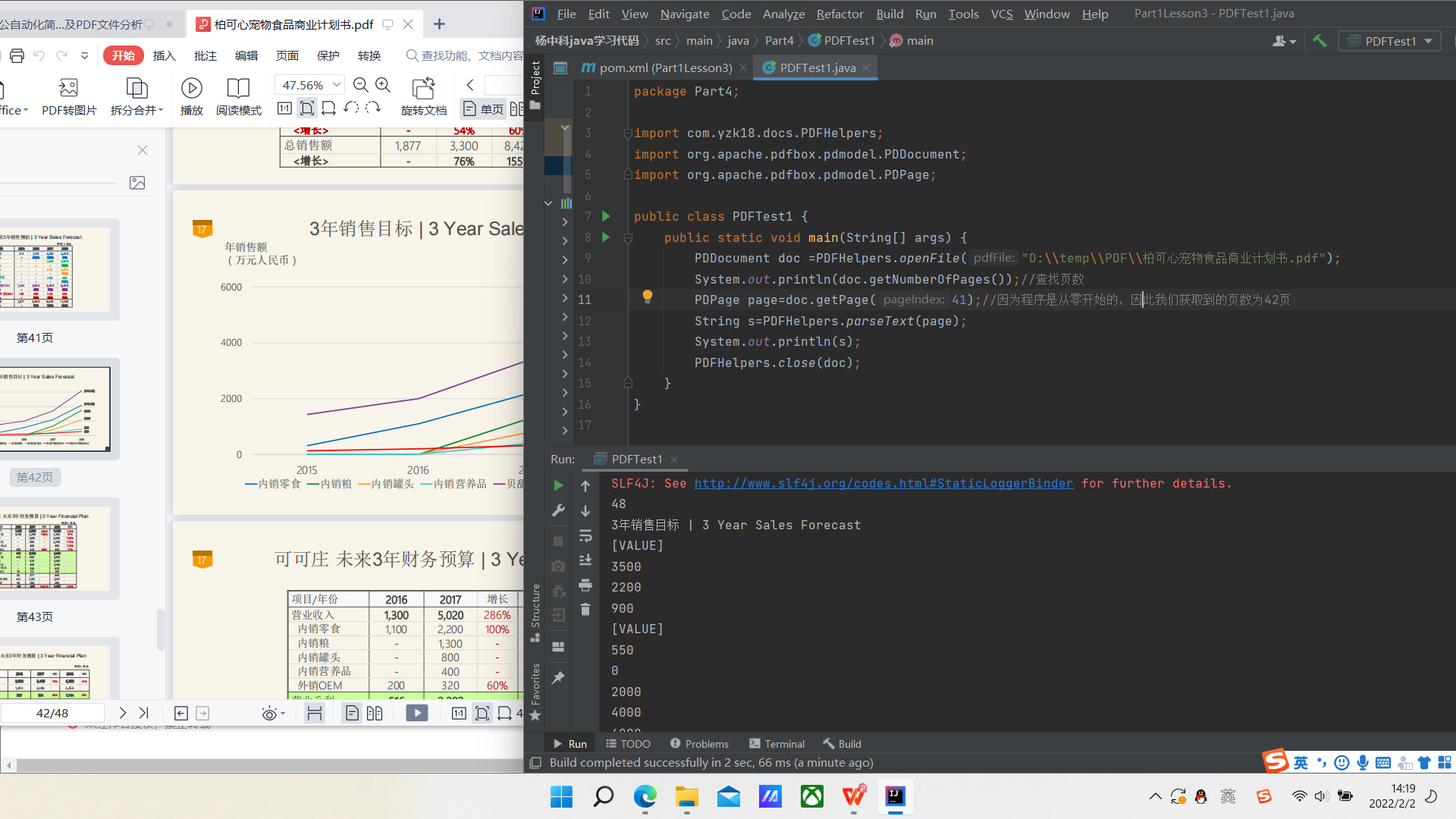
图片输出来
PDDocument doc =PDFHelpers.openFile("D:\temp\PDF\柏可心宠物食品商业计划书.pdf");
System.out.println(doc.getNumberOfPages());//查找页数
PDPage page=doc.getPage(34);//因为程序是从零开始的,因此我们获取到的页数为42页
String s=PDFHelpers.parseText(page);//识别PDF中的文字
System.out.println(s);
List<byte[]>images=PDFHelpers.parseImages(page,"png");//解析这一页的图片
//for (byte[] bytes:images)
for (int i=0;i<images.size();i++)
{
byte[] bytes=images.get(i);
IOHelpers.writeAllBytes("D:/temp/"+i+".png",bytes);//将图片bytes保存在路径上
}
PDFHelpers.close(doc);
3、案例:把一个PDF文件中的文字提取到一个文本文档中,图片保存到同级目录下,文件名用递增序号。
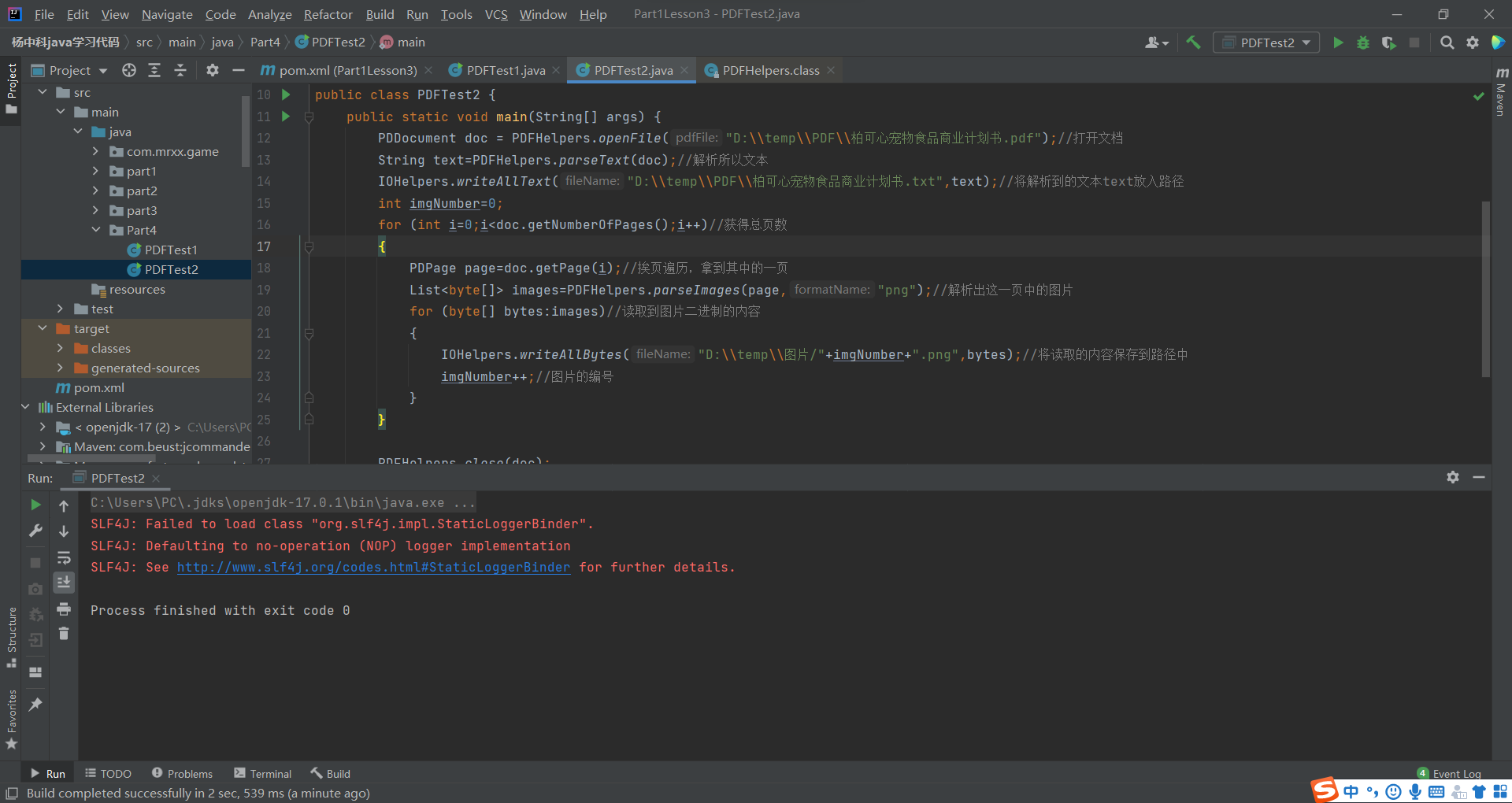
package Part4;
import com.yzk18.commons.IOHelpers;
import com.yzk18.docs.PDFHelpers;
import org.apache.pdfbox.pdmodel.PDDocument;
import org.apache.pdfbox.pdmodel.PDPage;
import java.util.List;
public class PDFTest2 {
public static void main(String[] args) {
PDDocument doc = PDFHelpers.openFile("D:\temp\PDF\柏可心宠物食品商业计划书.pdf");//打开文档
String text=PDFHelpers.parseText(doc);//解析所以文本
IOHelpers.writeAllText("D:\temp\PDF\柏可心宠物食品商业计划书.txt",text);//将解析到的文本text放入路径
int imgNumber=0;
for (int i=0;i<doc.getNumberOfPages();i++)//获得总页数
{
PDPage page=doc.getPage(i);//挨页遍历,拿到其中的一页
List<byte[]> images=PDFHelpers.parseImages(page,"png");//解析出这一页中的图片
for (byte[] bytes:images)//读取到图片二进制的内容
{
IOHelpers.writeAllBytes("D:\temp\图片/"+imgNumber+".png",bytes);//将读取的内容保存到路径中
imgNumber++;//图片的编号
}
}
PDFHelpers.close(doc);
}
}

限制 1、有的是纯扫描版文件,全都是图片,无法简单的提取文字,需要调用OCR等功能。有需要的可以先自己研究。 2、一些被加密等PDF文件需要特殊处理 OCR基本功能强大的都要调用付费接口,因为这个很消耗CPU资源。本地的方案识别准确率都不高,这是原理决定的。没有完美的解决方案。
最后
以上就是飘逸冬瓜最近收集整理的关于Java学习笔记:办公自动化简介及PDF文件分析的全部内容,更多相关Java学习笔记内容请搜索靠谱客的其他文章。
本图文内容来源于网友提供,作为学习参考使用,或来自网络收集整理,版权属于原作者所有。








发表评论 取消回复