Apache POI是Apache软件基金会的开源项目,POI提供API给Java程序对Microsoft Office格式档案读和写的功能。 .NET的开发人员则可以利用NPOI (POI for .NET) 来存取 Microsoft Office文档的功能。
需要的mavan依赖:
<!-- Excel poi -->
<dependency>
<groupId>org.apache.poi</groupId>
<artifactId>poi</artifactId>
<version>3.9</version>
</dependency>
<dependency>
<groupId>org.apache.poi</groupId>
<artifactId>poi-ooxml</artifactId>
<version>3.9</version>
</dependency>
<dependency>
<groupId>org.apache.poi</groupId>
<artifactId>poi-ooxml-schemas</artifactId>
<version>3.9</version>
</dependency>ExcelUtil.java
package com.citywy.controller;
import java.io.File;
import java.io.FileInputStream;
import java.io.IOException;
import java.io.InputStream;
import java.util.*;
import org.apache.poi.hssf.usermodel.HSSFCell;
import org.apache.poi.hssf.usermodel.HSSFWorkbook;
import org.apache.poi.ss.usermodel.Cell;
import org.apache.poi.ss.usermodel.Row;
import org.apache.poi.ss.usermodel.Sheet;
import org.apache.poi.ss.usermodel.Workbook;
import org.apache.poi.xssf.usermodel.XSSFWorkbook;
import org.apache.poi.openxml4j.exceptions.InvalidFormatException;
import org.apache.poi.ss.usermodel.WorkbookFactory;
import org.apache.poi.ss.util.CellRangeAddress;
public class ExcelUtil {
public static void main(String[] args){
ExcelUtil excelUtil = new ExcelUtil();
//读取excel数据
ArrayList<Map<String,String>> result = excelUtil.readExcelToObj("d:\first\a.xlsx");
for(Map<String,String> map:result){
System.out.println("输出:"+map);
}
}
/**
* 读取excel数据
* @param path
*/
private ArrayList<Map<String,String>> readExcelToObj(String path) {
Workbook wb = null;
ArrayList<Map<String,String>> result = null;
try {
wb = WorkbookFactory.create(new File(path));
result = readExcel(wb, 0, 1, 0);
} catch (InvalidFormatException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
}
return result;
}
/**
* 读取excel文件
* @param wb
* @param sheetIndex sheet页下标:从0开始
* @param startReadLine 开始读取的行:从0开始
* @param tailLine 去除最后读取的行
*/
private ArrayList<Map<String,String>> readExcel(Workbook wb,int sheetIndex, int startReadLine, int tailLine) {
Sheet sheet = wb.getSheetAt(sheetIndex);
Row row = null;
ArrayList<Map<String,String>> result = new ArrayList<Map<String,String>>();
for(int i=startReadLine; i<sheet.getLastRowNum()-tailLine+1; i++) {
row = sheet.getRow(i);
Map<String,String> map = new HashMap<String,String>();
for(Cell c : row) {
String returnStr = "";
boolean isMerge = isMergedRegion(sheet, i, c.getColumnIndex());
//判断是否具有合并单元格
if(isMerge) {
String rs = getMergedRegionValue(sheet, row.getRowNum(), c.getColumnIndex());
// System.out.print(rs + "------ ");
returnStr = rs;
}else {
// System.out.print(c.getRichStringCellValue()+"++++ ");
returnStr = c.getRichStringCellValue().getString();
}
if(c.getColumnIndex()==0){
map.put("id",returnStr);
}else if(c.getColumnIndex()==1){
map.put("base",returnStr);
}else if(c.getColumnIndex()==2){
map.put("siteName",returnStr);
}else if(c.getColumnIndex()==3){
map.put("articleName",returnStr);
}else if(c.getColumnIndex()==4){
map.put("mediaName",returnStr);
}else if(c.getColumnIndex()==5){
map.put("mediaUrl",returnStr);
}else if(c.getColumnIndex()==6){
map.put("newsSource",returnStr);
}else if(c.getColumnIndex()==7){
map.put("isRecord",returnStr);
}else if(c.getColumnIndex()==8){
map.put("recordTime",returnStr);
}else if(c.getColumnIndex()==9){
map.put("remark",returnStr);
}
}
result.add(map);
}
return result;
}
/**
* 获取合并单元格的值
* @param sheet
* @param row
* @param column
* @return
*/
public String getMergedRegionValue(Sheet sheet ,int row , int column){
int sheetMergeCount = sheet.getNumMergedRegions();
for(int i = 0 ; i < sheetMergeCount ; i++){
CellRangeAddress ca = sheet.getMergedRegion(i);
int firstColumn = ca.getFirstColumn();
int lastColumn = ca.getLastColumn();
int firstRow = ca.getFirstRow();
int lastRow = ca.getLastRow();
if(row >= firstRow && row <= lastRow){
if(column >= firstColumn && column <= lastColumn){
Row fRow = sheet.getRow(firstRow);
Cell fCell = fRow.getCell(firstColumn);
return getCellValue(fCell) ;
}
}
}
return null ;
}
/**
* 判断合并了行
* @param sheet
* @param row
* @param column
* @return
*/
private boolean isMergedRow(Sheet sheet,int row ,int column) {
int sheetMergeCount = sheet.getNumMergedRegions();
for (int i = 0; i < sheetMergeCount; i++) {
CellRangeAddress range = sheet.getMergedRegion(i);
int firstColumn = range.getFirstColumn();
int lastColumn = range.getLastColumn();
int firstRow = range.getFirstRow();
int lastRow = range.getLastRow();
if(row == firstRow && row == lastRow){
if(column >= firstColumn && column <= lastColumn){
return true;
}
}
}
return false;
}
/**
* 判断指定的单元格是否是合并单元格
* @param sheet
* @param row 行下标
* @param column 列下标
* @return
*/
private boolean isMergedRegion(Sheet sheet,int row ,int column) {
int sheetMergeCount = sheet.getNumMergedRegions();
for (int i = 0; i < sheetMergeCount; i++) {
CellRangeAddress range = sheet.getMergedRegion(i);
int firstColumn = range.getFirstColumn();
int lastColumn = range.getLastColumn();
int firstRow = range.getFirstRow();
int lastRow = range.getLastRow();
if(row >= firstRow && row <= lastRow){
if(column >= firstColumn && column <= lastColumn){
return true;
}
}
}
return false;
}
/**
* 判断sheet页中是否含有合并单元格
* @param sheet
* @return
*/
private boolean hasMerged(Sheet sheet) {
return sheet.getNumMergedRegions() > 0 ? true : false;
}
/**
* 合并单元格
* @param sheet
* @param firstRow 开始行
* @param lastRow 结束行
* @param firstCol 开始列
* @param lastCol 结束列
*/
private void mergeRegion(Sheet sheet, int firstRow, int lastRow, int firstCol, int lastCol) {
sheet.addMergedRegion(new CellRangeAddress(firstRow, lastRow, firstCol, lastCol));
}
/**
* 获取单元格的值
* @param cell
* @return
*/
public String getCellValue(Cell cell){
if(cell == null) return "";
if(cell.getCellType() == Cell.CELL_TYPE_STRING){
return cell.getStringCellValue();
}else if(cell.getCellType() == Cell.CELL_TYPE_BOOLEAN){
return String.valueOf(cell.getBooleanCellValue());
}else if(cell.getCellType() == Cell.CELL_TYPE_FORMULA){
return cell.getCellFormula() ;
}else if(cell.getCellType() == Cell.CELL_TYPE_NUMERIC){
return String.valueOf(cell.getNumericCellValue());
}
return "";
}
/**
* 从excel读取内容
*/
public static void readContent(String fileName) {
boolean isE2007 = false; //判断是否是excel2007格式
if(fileName.endsWith("xlsx"))
isE2007 = true;
try {
InputStream input = new FileInputStream(fileName); //建立输入流
Workbook wb = null;
//根据文件格式(2003或者2007)来初始化
if(isE2007)
wb = new XSSFWorkbook(input);
else
wb = new HSSFWorkbook(input);
Sheet sheet = wb.getSheetAt(0); //获得第一个表单
Iterator<Row> rows = sheet.rowIterator(); //获得第一个表单的迭代器
while (rows.hasNext()) {
Row row = rows.next(); //获得行数据
System.out.println("Row #" + row.getRowNum()); //获得行号从0开始
Iterator<Cell> cells = row.cellIterator(); //获得第一行的迭代器
while (cells.hasNext()) {
Cell cell = cells.next();
System.out.println("Cell #" + cell.getColumnIndex());
switch (cell.getCellType()) { //根据cell中的类型来输出数据
case HSSFCell.CELL_TYPE_NUMERIC:
System.out.println(cell.getNumericCellValue());
break;
case HSSFCell.CELL_TYPE_STRING:
System.out.println(cell.getStringCellValue());
break;
case HSSFCell.CELL_TYPE_BOOLEAN:
System.out.println(cell.getBooleanCellValue());
break;
case HSSFCell.CELL_TYPE_FORMULA:
System.out.println(cell.getCellFormula());
break;
default:
System.out.println("unsuported sell type======="+cell.getCellType());
break;
}
}
}
} catch (IOException ex) {
ex.printStackTrace();
}
}
}附加个人需求:
/**
* str最后一行读不到,手动最后加一行废数据
* 附加:将读取的内容合并为
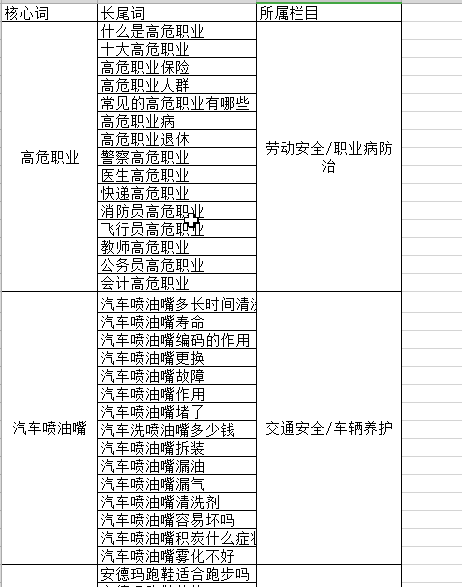
* 【高危职业】什么是高危职业_十大高危职业_xxx_xxx_xxx 最多8条
* 所属栏目读取最后一个/后的值 职业病防治
*/
public static void main(String[] args){
ExcelUtil excelUtil = new ExcelUtil();
//读取excel数据
ArrayList<Map<String,String>> result = excelUtil.readExcelToObj("d:\xreadexcel\a.xlsx");
Map<String, Object> result1 = new HashMap<String, Object>();
String str="";
for(Map<String,String> map:result){
String id = map.get("id");
String value = map.get("base");
String menu = map.get("siteName");
if(menu.contains("/")){
menu=menu.substring(menu.lastIndexOf("/")+1);
}
if(result1.containsKey(id)){
if(getCount(str, "_")<7){
str=str+"_"+value;
}
}else{
if(!str.equals("")){
System.out.println(str); //【高危职业】什么是高危职业_十大高危职业_..._..._...最多8条
}
//System.out.println(id); //高危职业
//System.out.println(menu.trim());//职业病防治
str="【"+id+"】"+value;
result1.put(id, value);
}
}
}
/**
* 获取字符串指定字符个数
* @param str
* @param tag
* @return
*/
public static int getCount(String str, String tag) {
int index = 0;
int count = 0;
while ((index = str.indexOf(tag)) != -1 ) {
str = str.substring(index + tag.length());
count++;
}
return count;
}转载:https://www.cnblogs.com/jiuchongxiao/p/5659884.html
最后
以上就是坦率信封最近收集整理的关于工具方法:java读取Excel合并单元格(简单实例)的全部内容,更多相关工具方法内容请搜索靠谱客的其他文章。
本图文内容来源于网友提供,作为学习参考使用,或来自网络收集整理,版权属于原作者所有。








发表评论 取消回复