EINSUM IS ALL YOU NEED
如果你和我一样,你会发现很难记住 PyTorch/TensorFlow 中用于计算点积、外积、转置和矩阵向量或矩阵矩阵乘法的所有不同函数的名称和签名。
Einsum 表示法是表达所有这些以及对张量的复杂操作的一种优雅方式,本质上是使用特定于领域的语言。
除了不必记住或定期查找特定库函数之外,这还有其他好处。
一旦你理解并使用了 einsum,你将能够更快地编写更简洁高效的代码。
当不使用 einsum 时,很容易引入不必要的张量整形和转置,以及可以省略的中间张量。
此外,像 einsum 这样的特定领域语言有时可以编译为高性能代码,而类似 einsum 的领域特定语言实际上是最近在 PyTorch 中引入的 Tensor Comprehensions3 的基础,它会自动生成 GPU 代码并自动调整特定输入大小的代码。
此外,opt einsum 和 tf einsum opt 等项目可用于优化 einsum 表达式的张量收缩顺序。

Einsum 通过 np.einsum 在 numpy 中实现,在 PyTorch 中通过 torch.einsum 实现,在 TensorFlow 中通过 tf.einsum. 实现。所有三个 einsum 函数共享相同的签名 einsum(equation,operands) 其中 equation 是表示爱因斯坦求和的字符串,并且
操作数是一个张量序列。



矩阵转置

求和
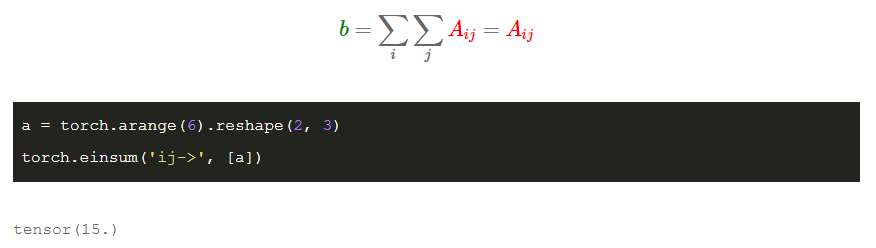
column sum
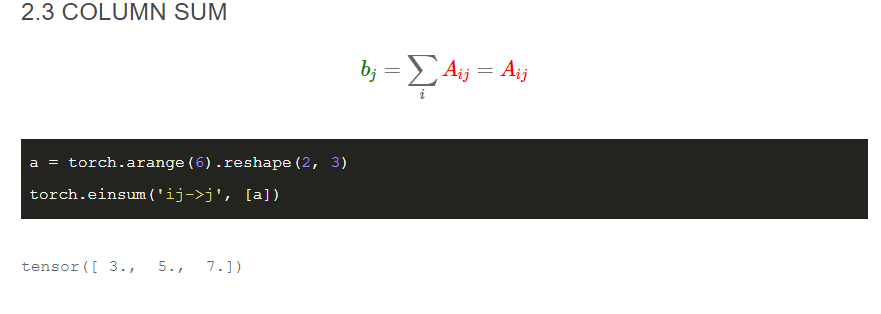
row sum
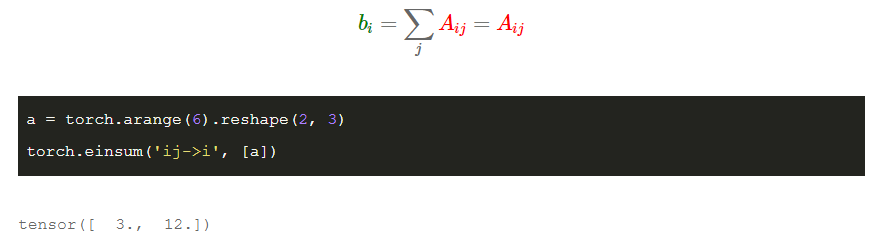
matrix-vector multiplication

matrix-matrix multiplication

dot product


handmard product

outer product

batch matrix multiplication
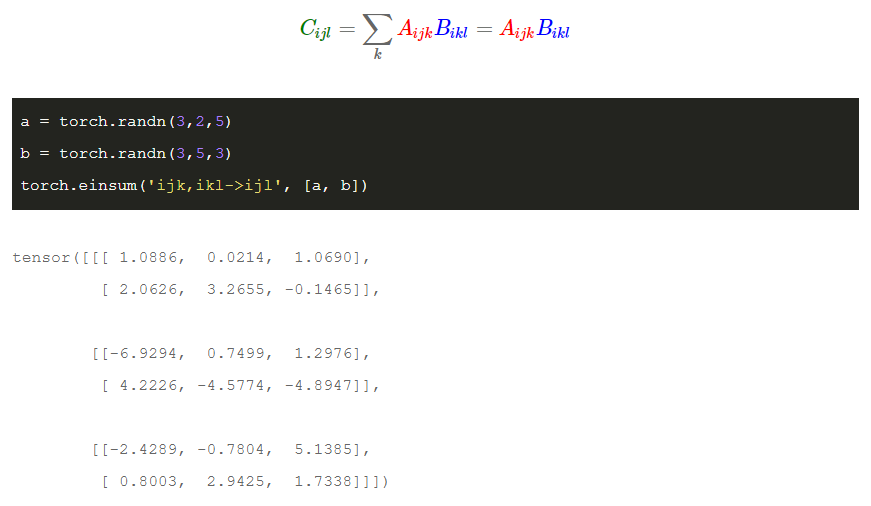
tensor contraction(张量收缩)

blinear transformation

case studies
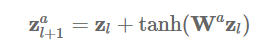
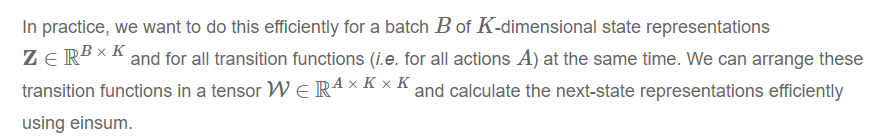
import torch.nn.functional as F
def random_tensors(shape, num=1, requires_grad=False):
tensors = [torch.randn(shape, requires_grad=requires_grad) for i in range(0, num)]
return tensors[0] if num == 1 else tensors
# Parameters
# -- [num_actions x hidden_dimension]
b = random_tensors([5, 3], requires_grad=True)
# -- [num_actions x hidden_dimension x hidden_dimension]
W = random_tensors([5, 3, 3], requires_grad=True)
def transition(zl):
# -- [batch_size x num_actions x hidden_dimension]
return zl.unsqueeze(1) + F.tanh(torch.einsum("bk,aki->bai", [zl, W]) + b)
# Sampled dummy inputs
# -- [batch_size x hidden_dimension]
zl = random_tensors([2, 3])
transition(zl)

attention
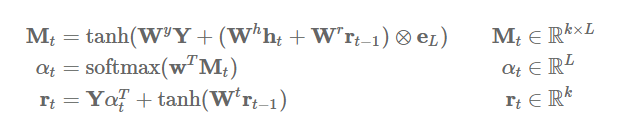
# Parameters
# -- [hidden_dimension]
bM, br, w = random_tensors([7], num=3, requires_grad=True)
# -- [hidden_dimension x hidden_dimension]
WY, Wh, Wr, Wt = random_tensors([7, 7], num=4, requires_grad=True)
# Single application of attention mechanism
def attention(Y, ht, rt1):
# -- [batch_size x hidden_dimension]
tmp = torch.einsum("ik,kl->il", [ht, Wh]) + torch.einsum("ik,kl->il", [rt1, Wr])
Mt = F.tanh(torch.einsum("ijk,kl->ijl", [Y, WY]) + tmp.unsqueeze(1).expand_as(Y) + bM)
# -- [batch_size x sequence_length]
at = F.softmax(torch.einsum("ijk,k->ij", [Mt, w]))
# -- [batch_size x hidden_dimension]
rt = torch.einsum("ijk,ij->ik", [Y, at]) + F.tanh(torch.einsum("ij,jk->ik", [rt1, Wt]) + br)
# -- [batch_size x hidden_dimension], [batch_size x sequence_dimension]
return rt, at
# Sampled dummy inputs
# -- [batch_size x sequence_length x hidden_dimension]
Y = random_tensors([3, 5, 7])
# -- [batch_size x hidden_dimension]
ht, rt1 = random_tensors([3, 7], num=2)
rt, at = attention(Y, ht, rt1)
at # -- print attention weights

最后
以上就是怕孤独美女最近收集整理的关于Einsum: numpy,pytorch and Tensorflowcase studies的全部内容,更多相关Einsum:内容请搜索靠谱客的其他文章。
本图文内容来源于网友提供,作为学习参考使用,或来自网络收集整理,版权属于原作者所有。








发表评论 取消回复