for i in range(2):
a.backward(retain_graph = True)
print("b.grad.data: {}".format(b.grad.data))不写.zero_grad()的代码结果
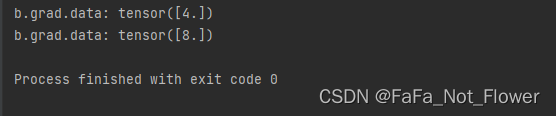
根据pytorch中的backward()函数的计算,当网络参量进行反馈时,梯度是被积累的而不是被替换掉;但是在每一个batch时毫无疑问并不需要将两个batch的梯度混合起来累积,因此这里就需要每个batch设置一遍zero_grad 。如果不是每一个batch就清除掉原有的梯度,而是比如说两个batch再清除掉梯度,这是一种变相提高batch_size的方法,对于计算机硬件不行,但是batch_size可能需要设高的领域比较适合,比如目标检测模型的训练。
参考:
【Pytorch 为什么每一轮batch需要设置optimizer.zero_grad】
https://blog.csdn.net/xiaoxifei/article/details/83474724
最后
以上就是霸气鸵鸟最近收集整理的关于.zero_grad()的重要性的全部内容,更多相关.zero_grad()内容请搜索靠谱客的其他文章。
本图文内容来源于网友提供,作为学习参考使用,或来自网络收集整理,版权属于原作者所有。








发表评论 取消回复