???? 『精品学习专栏导航帖』
- ????最适合入门的100个深度学习实战项目????
- ????【PyTorch深度学习项目实战100例目录】项目详解 + 数据集 + 完整源码????
- ????【机器学习入门项目10例目录】项目详解 + 数据集 + 完整源码????
- ????【机器学习项目实战10例目录】项目详解 + 数据集 + 完整源码????
- ????Java经典编程100例????
- ????Python经典编程100例????
- ????蓝桥杯历届真题题目+解析+代码+答案????
- ????【2023王道数据结构目录】课后算法设计题C、C++代码实现完整版大全????
文章目录
- 一、概述
- 二、高斯判别分析
- 1.算法思想
- 2.数据的分布假设
- 3.最大似然估计
- 4. 求解参数 ϕ phi ϕ
- 5.求解参数 μ 1 mu_1 μ1
- 6.求解参数 μ 2 mu_2 μ2
- 7.求解参数 Σ Sigma Σ
- 8.特别公式
2021人工智能领域新星创作者,带你从入门到精通,该博客每天更新,逐渐完善机器学习各个知识体系的文章,帮助大家更高效学习。

一、概述
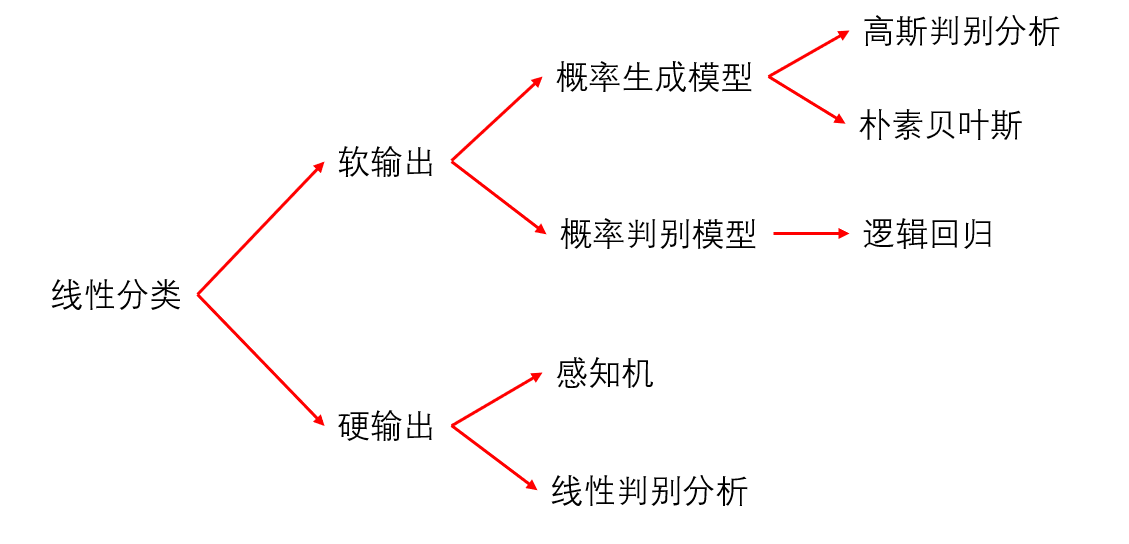
首先在讲高斯判别分析之前先看一下线性分类的几种常见模型。
-
软输出:就是通过概率的方式进行构建模型
-
硬输出:非概率方式
-
概率判别模型:判别模型就是会直接求 P ( Y ∣ X ) P(Y|X) P(Y∣X) 的值用于不同类别概率的比较
-
概率生成模型:它是通过贝叶斯方式将 P ( Y ∣ X ) P(Y|X) P(Y∣X)进行展开然后进而计算
本片文章将重点讲述概率生成模型——高斯判别分析
二、高斯判别分析
1.算法思想
首先我们得高斯判别分析属于一种概率生成模型,所以它是会使用概率的方式进行建模 P ( Y ∣ X ) P(Y|X) P(Y∣X) ,这个概率为后验概率,它的意思就是在样本X的前提下,Y属于不同类别的概率,我们会比较不同类别的概率,概率大的Y作为最终的分类类别。
那么显然这里我们可以使用MLE进行估计:
M
L
E
:
L
(
θ
)
=
l
o
g
P
(
Y
∣
X
)
=
l
o
g
P
(
Y
)
P
(
X
∣
Y
)
P
(
X
)
MLE:L(theta)=logP(Y|X)\=logfrac{P(Y)P(X|Y)}{P(X)}
MLE:L(θ)=logP(Y∣X)=logP(X)P(Y)P(X∣Y)
采用对数似然估计的方式来估计参数,这里的 X和Y都会服从一种分布,我们可以将他们的概率密度公式进行带入,又因为分母
P
(
X
)
P(X)
P(X)对于整个表达式来说是一个常数,所以我们的研究重点是分子,我们的目标就是:
a
r
g
m
a
x
θ
l
o
g
[
P
(
Y
)
P
(
X
∣
Y
)
]
argmax_theta log[P(Y)P(X|Y)]
argmaxθlog[P(Y)P(X∣Y)]
2.数据的分布假设
由于我们是基于二分类进行建模,所以y的取值只有0或者1,所以我们可以假设我们的标签y服从伯努利分布,即:
y
∼
B
e
r
n
o
u
l
l
i
(
ϕ
)
y sim Bernoulli(phi)
y∼Bernoulli(ϕ)
P ( y ) = ϕ y ( 1 − ϕ ) 1 − y P(y)=phi^y(1-phi)^{1-y} P(y)=ϕy(1−ϕ)1−y
如果当y=1时, P ( y ) P(y) P(y) 的值为 ϕ phi ϕ ,就是y发生的概率,如果y=0,此时 P ( y ) P(y) P(y) 的值为 1 − ϕ 1-phi 1−ϕ 就是y不发生的概率。
针对于数据X,我们也是假设其符合分布,我们用一幅图表示一下:
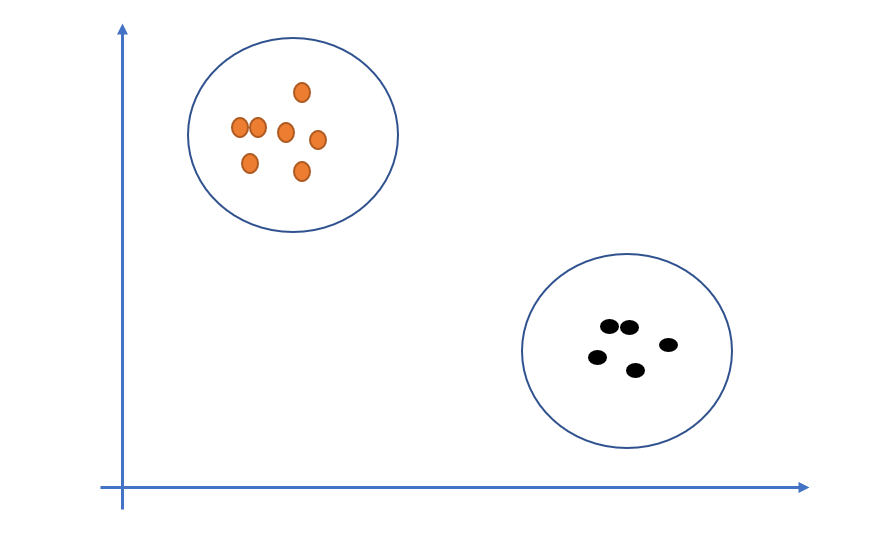
由于两类样本是分布在不同的区域内的,相同的样本都是在同一区域,所以我们可以假设两个类别的数据分别服从高斯分布,为什么使用高斯分布?是因为高斯分布的数学性质好,而且更容易模拟真实生活中的样本分布。
所以数据X的分布:
x
∣
(
y
=
1
)
∼
N
(
μ
1
,
Σ
)
x
∣
(
y
=
0
)
∼
N
(
μ
2
,
Σ
)
x|(y=1)quadsim N(mu_1,Sigma)\x|(y=0)quad sim N(mu_2,Sigma)
x∣(y=1)∼N(μ1,Σ)x∣(y=0)∼N(μ2,Σ)
所以数据X的概率密度函数为:
P
(
x
∣
y
)
=
N
(
μ
1
,
Σ
)
y
N
(
μ
2
,
Σ
)
1
−
y
P(x|y)=N(mu_1,Sigma)^yN(mu_2,Sigma)^{1-y}
P(x∣y)=N(μ1,Σ)yN(μ2,Σ)1−y
3.最大似然估计
我们希望
P
(
Y
∣
X
)
P(Y|X)
P(Y∣X) 的概率越大越好,也就是说在数据X的前提下,我们根据样本X的建模获得的Y对的几率越大越好,所以我们的目标函数就为:
a
r
g
m
a
x
θ
l
o
g
P
(
Y
∣
X
)
=
a
r
g
m
a
x
l
o
g
P
(
Y
)
P
(
X
∣
Y
)
P
(
X
)
argmax_theta logP(Y|X)\=argmaxlogfrac{P(Y)P(X|Y)}{P(X)}
argmaxθlogP(Y∣X)=argmaxlogP(X)P(Y)P(X∣Y)
此时的分母作为常数我们不需要管,我们只注重分子的大小,而分子恰恰就是我们上面定义的概率密度函数,有时也称
P
(
Y
)
P(Y)
P(Y) 叫先验概率,
P
(
X
∣
Y
)
P(X|Y)
P(X∣Y) 是似然。
所以我们的目标函数可以转化为:
a
r
g
m
a
x
l
o
g
P
(
Y
)
P
(
X
∣
Y
)
P
(
X
)
=
a
r
g
m
a
x
l
o
g
[
P
(
y
)
P
(
x
∣
y
)
]
=
a
r
g
m
a
x
∑
i
=
1
m
[
l
o
g
p
(
y
i
)
+
l
o
g
p
(
x
i
∣
y
i
)
]
=
a
r
g
m
a
x
∑
i
=
1
m
l
o
g
ϕ
i
y
(
1
−
ϕ
)
1
−
y
i
+
l
o
g
N
(
μ
1
,
Σ
)
y
i
+
l
o
g
N
(
μ
2
,
Σ
)
1
−
y
i
argmaxlogfrac{P(Y)P(X|Y)}{P(X)}\=argmax log[P(y)P(x|y)]\=argmax sum_{i=1}^m[log p(y_i)+log p(x_i|y_i)]\=argmax sum_{i=1}^mlog phi^y_i(1-phi)^{1-y_i}+log N(mu_1,Sigma)^{y_i}+log N(mu_2,Sigma)^{1-y_i}
argmaxlogP(X)P(Y)P(X∣Y)=argmax log[P(y)P(x∣y)]=argmax i=1∑m[log p(yi)+log p(xi∣yi)]=argmax i=1∑mlog ϕiy(1−ϕ)1−yi+log N(μ1,Σ)yi+log N(μ2,Σ)1−yi
该式子中的参数分别为
ϕ
、
μ
1
、
μ
2
、
Σ
phi、mu_1、mu_2、Sigma
ϕ、μ1、μ2、Σ ,所以我们要对上式求导,分别求取使目标函数达到极值的极值点。
4. 求解参数 ϕ phi ϕ
最终的目标函数中只有第一项是与 ϕ phi ϕ 有关的,所以只需要考虑这一项即可。
该式可以写为:
∑
i
=
1
m
y
i
(
l
o
g
ϕ
)
+
(
1
−
y
i
)
l
o
g
(
1
−
ϕ
)
sum_{i=1}^my_i(log phi)+(1-y_i)log (1-phi)
i=1∑myi(log ϕ)+(1−yi)log (1−ϕ)
对该式进行求导可以获得:
∂
L
∂
ϕ
=
∑
i
=
1
m
y
i
ϕ
−
1
−
y
i
1
−
ϕ
=
0
frac{partial L}{partial phi}=sum_{i=1}^mfrac{y_i}{phi}-frac{1-y_i}{1-phi}=0
∂ϕ∂L=i=1∑mϕyi−1−ϕ1−yi=0
进而可得:
∑
i
=
1
m
y
i
(
1
−
ϕ
)
−
(
1
−
y
i
)
ϕ
=
0
sum_{i=1}^my_i(1-phi)-(1-y_i)phi=0
i=1∑myi(1−ϕ)−(1−yi)ϕ=0
∑ i = 1 m ( y i − ϕ ) = 0 sum_{i=1}^m(y_i-phi)=0 i=1∑m(yi−ϕ)=0
所以可以解得:
ϕ
=
1
m
∑
i
=
1
m
y
1
phi=frac{1}{m}sum_{i=1}^my_1
ϕ=m1i=1∑my1
这里我们约定一下,总样本数为
N
N
N ,其中类别为1的有
N
1
N_1
N1 个,类别为0的有
N
2
N_2
N2 个,上面的推导写成m是我的书写习惯了,用m代表总样本数,接下来的总样本数为N。
所以我们最终的
ϕ
phi
ϕ 就为:
ϕ
=
N
1
N
phi=frac{N_1}{N}
ϕ=NN1
因为后面是对
y
i
y_i
yi 进行求和,而
y
i
y_i
yi 只有0和1分类,只有当y=1时才有效,而y=1类别有
N
1
N_1
N1 个样本,所以可以改写为上面的式子。
5.求解参数 μ 1 mu_1 μ1
目标函数:
a
r
g
m
a
x
∑
i
=
1
m
l
o
g
ϕ
i
y
(
1
−
ϕ
)
1
−
y
i
+
l
o
g
N
(
μ
1
,
Σ
)
y
i
+
l
o
g
N
(
μ
2
,
Σ
)
1
−
y
i
argmax sum_{i=1}^mlog phi^y_i(1-phi)^{1-y_i}+log N(mu_1,Sigma)^{y_i}+log N(mu_2,Sigma)^{1-y_i}
argmax i=1∑mlog ϕiy(1−ϕ)1−yi+log N(μ1,Σ)yi+log N(μ2,Σ)1−yi
参数
μ
1
mu_1
μ1 只和第二项有关,所以接下来处理求导只针对于它。
因为我们之间假设了X服从高斯分布,所以概率密度公式为:
N
(
μ
1
,
Σ
)
=
p
(
x
∣
y
)
=
1
(
2
π
)
p
2
∣
Σ
∣
1
2
e
x
p
(
−
1
2
(
x
−
μ
)
T
Σ
−
1
(
x
−
y
)
)
N(mu_1,Sigma)=p(x|y)\=frac{1}{(2pi)^{frac{p}{2}}|Sigma|^{frac{1}{2}}}exp(-frac{1}{2}(x-mu)^TSigma^{-1}(x-y))
N(μ1,Σ)=p(x∣y)=(2π)2p∣Σ∣211exp(−21(x−μ)TΣ−1(x−y))
我们现在对目标函数的第二项进行化简处理:
∑
i
=
1
m
l
o
g
N
(
μ
1
,
Σ
)
y
i
=
∑
i
=
1
m
y
i
l
o
g
N
(
μ
i
,
Σ
)
=
∑
i
=
1
m
y
i
l
o
g
1
(
2
π
)
p
2
∣
Σ
∣
1
2
e
x
p
(
−
1
2
(
x
−
μ
)
T
Σ
−
1
(
x
−
y
)
)
sum_{i=1}^mlog N(mu_1,Sigma)^{y_i}\=sum_{i=1}^my_ilog N(mu_i,Sigma)\=sum_{i=1}^my_ilog frac{1}{(2pi)^{frac{p}{2}}|Sigma|^{frac{1}{2}}}exp(-frac{1}{2}(x-mu)^TSigma^{-1}(x-y))
i=1∑mlog N(μ1,Σ)yi=i=1∑myilog N(μi,Σ)=i=1∑myilog (2π)2p∣Σ∣211exp(−21(x−μ)TΣ−1(x−y))
所以我们可以转化为:
∑
i
=
1
m
y
i
[
−
1
2
(
x
−
μ
1
)
T
Σ
−
1
(
x
−
μ
1
)
]
sum_{i=1}^my_i[-frac{1}{2}(x-mu_1)^TSigma^{-1}(x-mu_1)]
i=1∑myi[−21(x−μ1)TΣ−1(x−μ1)]
为什么化成了该式,因为上面的式子利用 log性质拆开后,都是常数,与参数
μ
1
mu_1
μ1 无关,所以就省略了。
之后我们对该式进行求导:
∂
L
∂
μ
1
=
∑
i
=
1
m
y
i
(
−
1
2
)
[
Σ
−
1
(
x
−
μ
1
)
d
(
x
−
μ
1
)
T
+
(
x
−
μ
1
)
T
Σ
−
1
d
(
x
−
μ
1
)
]
=
0
frac{partial L}{partial mu_1}=sum_{i=1}^my_i(-frac{1}{2})[Sigma^{-1}(x-mu_1)d(x-mu_1)^T+(x-mu_1)^TSigma^{-1}d(x-mu_1)]=0
∂μ1∂L=i=1∑myi(−21)[Σ−1(x−μ1)d(x−μ1)T+(x−μ1)TΣ−1d(x−μ1)]=0
∑ i = 1 m 2 Σ − 1 ( μ 1 − x ) y i ( − 1 2 ) = 0 sum_{i=1}^m2Sigma^{-1}(mu_1-x)y_i(-frac{1}{2})=0 i=1∑m2Σ−1(μ1−x)yi(−21)=0
∑ i = 1 m y i Σ − 1 x i = ∑ i = 1 m y i Σ − 1 μ 1 sum_{i=1}^my_iSigma^{-1}x_i=sum_{i=1}^my_iSigma^{-1}mu_1 i=1∑myiΣ−1xi=i=1∑myiΣ−1μ1
所以我们可以获得最终的解:
μ
1
=
∑
i
=
1
m
y
i
x
i
∑
i
=
1
m
y
1
=
∑
i
=
1
m
y
i
x
i
N
1
mu_1=frac{sum_{i=1}^my_ix_i}{sum_{i=1}^my_1}\=frac{sum_{i=1}^my_ix_i}{N_1}
μ1=∑i=1my1∑i=1myixi=N1∑i=1myixi
6.求解参数 μ 2 mu_2 μ2
由于参数 μ 2 mu_2 μ2 和 μ 1 mu_1 μ1 的求解方式类似,这里就省略了
7.求解参数 Σ Sigma Σ
目标函数:
a
r
g
m
a
x
∑
i
=
1
m
l
o
g
ϕ
i
y
(
1
−
ϕ
)
1
−
y
i
+
l
o
g
N
(
μ
1
,
Σ
)
y
i
+
l
o
g
N
(
μ
2
,
Σ
)
1
−
y
i
argmax sum_{i=1}^mlog phi^y_i(1-phi)^{1-y_i}+log N(mu_1,Sigma)^{y_i}+log N(mu_2,Sigma)^{1-y_i}
argmax i=1∑mlog ϕiy(1−ϕ)1−yi+log N(μ1,Σ)yi+log N(μ2,Σ)1−yi
我们可以看到
Σ
Sigma
Σ 与函数中的后两项都存在关系。
所以可以获得:
a
r
g
m
a
x
∑
i
=
1
m
l
o
g
N
(
μ
1
,
Σ
)
y
i
+
l
o
g
N
(
μ
2
,
Σ
)
1
−
y
i
=
∑
i
=
1
m
y
i
l
o
g
N
(
μ
1
,
Σ
)
+
(
1
−
y
i
)
l
o
g
N
(
μ
2
,
Σ
)
=
∑
x
i
∈
C
1
l
o
g
N
(
μ
1
,
Σ
)
+
∑
x
i
∈
C
2
l
o
g
N
(
μ
2
,
Σ
)
argmax sum_{i=1}^mlog N(mu_1,Sigma)^{y_i}+log N(mu_2,Sigma)^{1-y_i}\=sum_{i=1}^my_ilog N(mu_1,Sigma)+(1-y_i)log N(mu_2,Sigma)\=sum_{x_i in C_1}log N(mu_1,Sigma)+sum_{x_i in C_2}log N(mu_2,Sigma)
argmax i=1∑mlog N(μ1,Σ)yi+log N(μ2,Σ)1−yi=i=1∑myilog N(μ1,Σ)+(1−yi)log N(μ2,Σ)=xi∈C1∑log N(μ1,Σ)+xi∈C2∑log N(μ2,Σ)
其中第三部我们将其化简,为了表示方便,我们拆分成两个类别的求和,分别属于两个类的样本,这样就可以把
y
y
y 值去掉。
发现最终的结果,是两个通项公式的求和,所以我们接下来求一下这个通项公式
∑
l
o
g
N
(
μ
,
Σ
)
sum log N(mu,Sigma)
∑log N(μ,Σ) :
∑
i
=
1
m
l
o
g
N
(
μ
,
Σ
)
=
∑
i
=
1
m
l
o
g
1
(
2
π
)
p
2
∣
Σ
∣
1
2
e
x
p
(
−
1
2
(
x
−
μ
)
T
Σ
−
1
(
x
−
y
)
)
=
∑
i
=
1
m
l
o
g
1
(
2
π
)
p
2
+
l
o
g
∣
Σ
∣
−
1
2
−
1
2
(
x
−
μ
)
T
Σ
−
1
(
x
−
μ
)
=
C
−
N
2
l
o
g
∣
Σ
∣
−
1
2
∑
i
=
1
m
t
r
(
(
x
−
μ
)
T
Σ
−
1
(
x
−
μ
)
)
=
C
−
N
2
l
o
g
∣
Σ
∣
−
1
2
t
r
(
∑
i
=
1
m
(
x
−
μ
)
(
x
−
μ
)
T
Σ
−
1
)
=
C
−
N
2
l
o
g
∣
Σ
∣
−
1
2
N
t
r
(
S
Σ
−
1
)
sum_{i=1}^mlog N(mu,Sigma)=sum_{i=1}^mlog frac{1}{(2pi)^{frac{p}{2}}|Sigma|^{frac{1}{2}}}exp(-frac{1}{2}(x-mu)^TSigma^{-1}(x-y))\=sum_{i=1}^mlog frac{1}{(2pi)^{frac{p}{2}}}+log|Sigma|^{-frac{1}{2}}-frac{1}{2}(x-mu)^TSigma^{-1}(x-mu)\=C-frac{N}{2}log |Sigma|-frac{1}{2}sum_{i=1}^mtr((x-mu)^TSigma^{-1}(x-mu))\=C-frac{N}{2}log |Sigma|-frac{1}{2}tr(sum_{i=1}^m(x-mu)(x-mu)^TSigma^{-1})\=C-frac{N}{2}log |Sigma|-frac{1}{2}Ntr(SSigma^{-1})
i=1∑mlog N(μ,Σ)=i=1∑mlog (2π)2p∣Σ∣211exp(−21(x−μ)TΣ−1(x−y))=i=1∑mlog (2π)2p1+log∣Σ∣−21−21(x−μ)TΣ−1(x−μ)=C−2Nlog ∣Σ∣−21i=1∑mtr((x−μ)TΣ−1(x−μ))=C−2Nlog ∣Σ∣−21tr(i=1∑m(x−μ)(x−μ)TΣ−1)=C−2Nlog ∣Σ∣−21Ntr(SΣ−1)
所以将我们目标函数分别带入通项公式中的结果:
∑
x
i
∈
C
1
l
o
g
N
(
μ
1
,
Σ
)
+
∑
x
i
∈
C
2
l
o
g
N
(
μ
2
,
Σ
)
=
−
1
2
[
N
l
o
g
∣
Σ
∣
+
N
1
t
r
(
S
1
Σ
−
1
)
+
N
2
t
r
(
S
2
Σ
−
1
)
]
sum_{x_i in C_1}log N(mu_1,Sigma)+sum_{x_i in C_2}log N(mu_2,Sigma)\=-frac{1}{2}[Nlog |Sigma|+N_1tr(S_1Sigma^{-1})+N_2tr(S_2Sigma^{-1})]
xi∈C1∑log N(μ1,Σ)+xi∈C2∑log N(μ2,Σ)=−21[Nlog ∣Σ∣+N1tr(S1Σ−1)+N2tr(S2Σ−1)]
所以我们需要对上式进行求导:
∂
L
∂
Σ
=
−
1
2
(
N
Σ
−
1
−
N
1
S
1
Σ
−
1
−
N
2
S
2
Σ
−
1
)
=
0
frac{partial L}{partial Sigma}=-frac{1}{2}(NSigma^{-1}-N_1S_1Sigma^{-1}-N_2S_2Sigma^{-1})=0
∂Σ∂L=−21(NΣ−1−N1S1Σ−1−N2S2Σ−1)=0
解得参数
Σ
Sigma
Σ :
Σ
=
N
1
S
1
+
N
2
S
2
N
Sigma=frac{N_1S_1+N_2S_2}{N}
Σ=NN1S1+N2S2
8.特别公式
上面求导或者化简可能用到的公式:
t
r
(
A
)
=
A
(
A
为
标
量
)
tr(A)=Aquad (A为标量)
tr(A)=A(A为标量)
t r ( A B C ) = t r ( C A B ) = t r ( B C A ) tr(ABC)=tr(CAB)=tr(BCA) tr(ABC)=tr(CAB)=tr(BCA)
∂ ∣ A ∣ ∂ A = ∣ A ∣ A − 1 frac{partial |A|}{partial A}=|A|A^{-1} ∂A∂∣A∣=∣A∣A−1
∂ t r ( A B ) ∂ A = B T frac{partial tr(AB)}{partial A}=B^T ∂A∂tr(AB)=BT
写在最后
大家好,我是阿光,觉得文章还不错的话,记得“一键三连”哦!!!

最后
以上就是迅速花瓣最近收集整理的关于【机器学习】线性分类——高斯判别分析GDA(理论+图解+公式推导)一、概述二、高斯判别分析的全部内容,更多相关【机器学习】线性分类——高斯判别分析GDA(理论+图解+公式推导)一、概述二、高斯判别分析内容请搜索靠谱客的其他文章。








发表评论 取消回复