-
SparkSQL是什么 -
SparkSQL如何使用
- 1. SparkSQL 是什么
- 1.1. SparkSQL 的出现契机
- 1.2. SparkSQL 的适用场景
- 2. SparkSQL 初体验
- 2.3. RDD 版本的 WordCount
- 2.2. 命令式 API 的入门案例
- 2.2. SQL 版本 WordCount
- 3. [扩展] Catalyst 优化器
- 3.1. RDD 和 SparkSQL 运行时的区别
- 3.2. Catalyst
- 4. Dataset 的特点
- 5. DataFrame 的作用和常见操作
- 6. Dataset 和 DataFrame 的异同
- 7. 数据读写
- 7.1. 初识 DataFrameReader
- 7.2. 初识 DataFrameWriter
- 7.3. 读写 Parquet 格式文件
- 7.4. 读写 JSON 格式文件
- 7.5. 访问 Hive
- 7.6. JDBC
1. SparkSQL 是什么
对于一件事的理解, 应该分为两个大部分, 第一, 它是什么, 第二, 它解决了什么问题
-
理解为什么会有
SparkSQL -
理解
SparkSQL所解决的问题, 以及它的使命
1.1. SparkSQL 的出现契机
理解 SparkSQL 是什么
-
历史前提
-
发展过程
-
重要性
因为 SQL 是数据分析领域一个非常重要的范式, 所以 Spark 一直想要支持这种范式, 而伴随着一些决策失误, 这个过程其实还是非常曲折的

-
Hive
-
-
解决的问题
-
-
Hive实现了SQL on Hadoop, 使用MapReduce执行任务 -
简化了
MapReduce任务
新的问题
-
-
-
Hive的查询延迟比较高, 原因是使用MapReduce做调度
-
Shark
-
-
-
解决的问题
-
-
Shark改写Hive的物理执行计划, 使用Spark作业代替MapReduce执行物理计划 -
使用列式内存存储
-
以上两点使得
Shark的查询效率很高
新的问题
-
-
-
Shark重用了Hive的SQL解析, 逻辑计划生成以及优化, 所以其实可以认为Shark只是把Hive的物理执行替换为了Spark作业 -
执行计划的生成严重依赖
Hive, 想要增加新的优化非常困难 -
Hive使用MapReduce执行作业, 所以Hive是进程级别的并行, 而Spark是线程级别的并行, 所以Hive中很多线程不安全的代码不适用于Spark
-
由于以上问题,
Shark维护了Hive的一个分支, 并且无法合并进主线, 难以为继 -
-
-
解决的问题
-
-
Spark SQL使用Hive解析SQL生成AST语法树, 将其后的逻辑计划生成, 优化, 物理计划都自己完成, 而不依赖Hive -
执行计划和优化交给优化器
Catalyst -
内建了一套简单的
SQL解析器, 可以不使用HQL, 此外, 还引入和DataFrame这样的DSL API, 完全可以不依赖任何Hive的组件 -
Shark只能查询文件,Spark SQL可以直接降查询作用于RDD, 这一点是一个大进步
新的问题
-
-
对于初期版本的
SparkSQL, 依然有挺多问题, 例如只能支持SQL的使用, 不能很好的兼容命令式, 入口不够统一等
-
-
SparkSQL在 2.0 时代, 增加了一个新的API, 叫做Dataset,Dataset统一和结合了SQL的访问和命令式API的使用, 这是一个划时代的进步在
Dataset中可以轻易的做到使用SQL查询并且筛选数据, 然后使用命令式API进行探索式分析
SparkSQL
Dataset
|
重要性
|
SparkSQL 是什么
SparkSQL 是一个为了支持 SQL 而设计的工具, 但同时也支持命令式的 API
1.2. SparkSQL 的适用场景
理解 SparkSQL 的适用场景
| 定义 | 特点 | 举例 | |
|---|---|---|---|
| 结构化数据 | 有固定的 | 有预定义的 | 关系型数据库的表 |
| 半结构化数据 | 没有固定的 | 没有固定的 | 指一些有结构的文件格式, 例如 |
| 非结构化数据 | 没有固定 | 没有固定 | 指文档图片之类的格式 |
-
结构化数据
-
一般指数据有固定的
Schema, 例如在用户表中,name字段是String型, 那么每一条数据的name字段值都可以当作String来使用+----+--------------+---------------------------+-------+---------+ | id | name | url | alexa | country | +----+--------------+---------------------------+-------+---------+ | 1 | Google | https://www.google.cm/ | 1 | USA | | 2 | 淘宝 | https://www.taobao.com/ | 13 | CN | | 3 | 菜鸟教程 | http://www.runoob.com/ | 4689 | CN | | 4 | 微博 | http://weibo.com/ | 20 | CN | | 5 | Facebook | https://www.facebook.com/ | 3 | USA | +----+--------------+---------------------------+-------+---------+
半结构化数据
-
一般指的是数据没有固定的
Schema, 但是数据本身是有结构的{ "firstName": "John", "lastName": "Smith", "age": 25, "phoneNumber": [ { "type": "home", "number": "212 555-1234" }, { "type": "fax", "number": "646 555-4567" } ] }-
没有固定
-
指的是半结构化数据是没有固定的
Schema的, 可以理解为没有显式指定Schema
比如说一个用户信息的JSON文件, 第一条数据的phone_num有可能是String, 第二条数据虽说应该也是String, 但是如果硬要指定为BigInt, 也是有可能的
因为没有指定Schema, 没有显式的强制的约束
有结构
-
虽说半结构化数据是没有显式指定
Schema的, 也没有约束, 但是半结构化数据本身是有有隐式的结构的, 也就是数据自身可以描述自身
例如JSON文件, 其中的某一条数据是有字段这个概念的, 每个字段也有类型的概念, 所以说JSON是可以描述自身的, 也就是数据本身携带有元信息
Schema -
-
-
Spark的RDD主要用于处理 非结构化数据 和 半结构化数据 -
SparkSQL主要用于处理 结构化数据
-
-
-
SparkSQL提供了更好的外部数据源读写支持-
因为大部分外部数据源是有结构化的, 需要在
RDD之外有一个新的解决方案, 来整合这些结构化数据源
-
-
SparkSQL提供了直接访问列的能力-
因为
SparkSQL主要用做于处理结构化数据, 所以其提供的API具有一些普通数据库的能力
-
-
SparkSQL 处理什么数据的问题?
SparkSQL 相较于
RDD 的优势在哪?
SparkSQL 适用于什么场景?
SparkSQL 适用于处理结构化数据的场景
-
SparkSQL是一个即支持SQL又支持命令式数据处理的工具 -
SparkSQL的主要适用场景是处理结构化数据
2. SparkSQL 初体验
-
了解
SparkSQL的API由哪些部分组成
2.3. RDD 版本的 WordCount
val config = new SparkConf().setAppName("ip_ana").setMaster("local[6]")
val sc = new SparkContext(config)
sc.textFile("hdfs://node01:8020/dataset/wordcount.txt") .flatMap(_.split(" ")) .map((_, 1)) .reduceByKey(_ + _) .collect-
RDD版本的代码有一个非常明显的特点, 就是它所处理的数据是基本类型的, 在算子中对整个数据进行处理
2.2. 命令式 API 的入门案例
case class People(name: String, age: Int)
val spark: SparkSession = new sql.SparkSession.Builder()
.appName("hello")
.master("local[6]")
.getOrCreate()
import spark.implicits._
val peopleRDD: RDD[People] = spark.sparkContext.parallelize(Seq(People("zhangsan", 9), People("lisi", 15)))
val peopleDS: Dataset[People] = peopleRDD.toDS() val teenagers: Dataset[String] = peopleDS.where('age > 10) .where('age < 20) .select('name) .as[String] /* +----+ |name| +----+ |lisi| +----+ */ teenagers.show()| SparkSQL 中有一个新的入口点, 叫做 SparkSession | |
| SparkSQL 中有一个新的类型叫做 Dataset | |
| SparkSQL 有能力直接通过字段名访问数据集, 说明 SparkSQL 的 API 中是携带 Schema 信息的 |
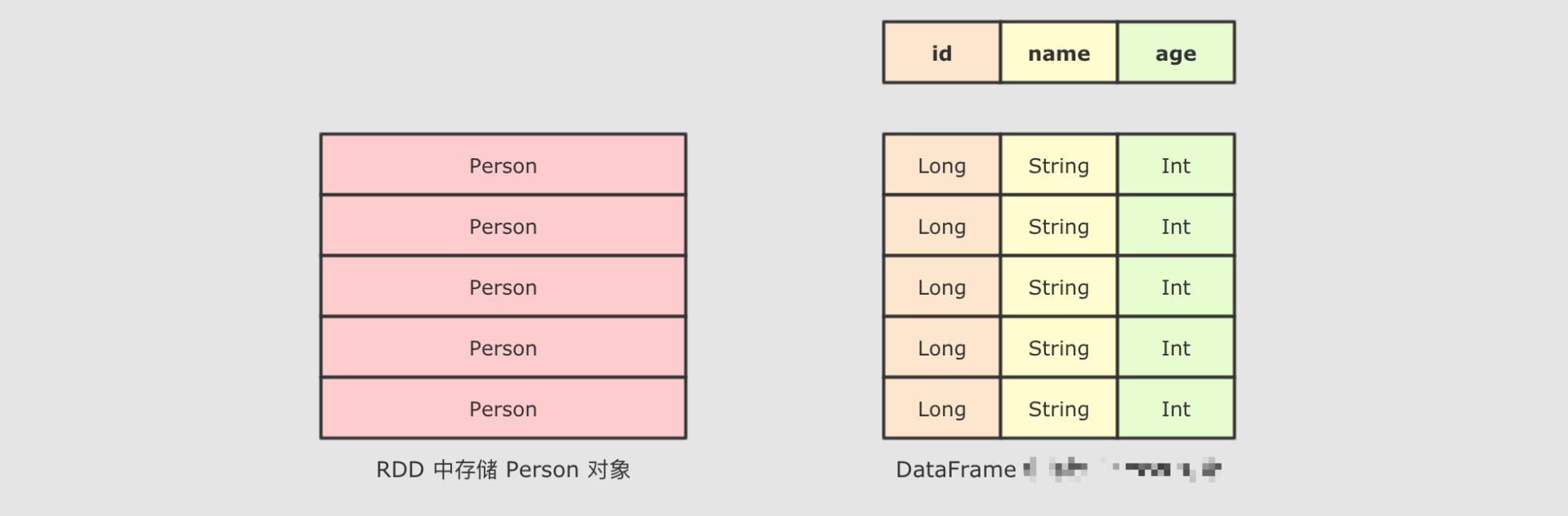
SparkSQL 最大的特点就是它针对于结构化数据设计, 所以 SparkSQL 应该是能支持针对某一个字段的访问的, 而这种访问方式有一个前提, 就是 SparkSQL 的数据集中, 要 包含结构化信息, 也就是俗称的 Schema
而 SparkSQL 对外提供的 API 有两类, 一类是直接执行 SQL, 另外一类就是命令式. SparkSQL 提供的命令式 API 就是 DataFrame 和 Dataset, 暂时也可以认为 DataFrame 就是 Dataset, 只是在不同的 API 中返回的是 Dataset 的不同表现形式
// RDD
rdd.map { case Person(id, name, age) => (age, 1) }
.reduceByKey {case ((age, count), (totalAge, totalCount)) => (age, count + totalCount)} // DataFrame df.groupBy("age").count("age")通过上面的代码, 可以清晰的看到, SparkSQL 的命令式操作相比于 RDD 来说, 可以直接通过 Schema 信息来访问其中某个字段, 非常的方便
2.2. SQL 版本 WordCount
val spark: SparkSession = new sql.SparkSession.Builder() .appName("hello") .master("local[6]") .getOrCreate() import spark.implicits._ val peopleRDD: RDD[People] = spark.sparkContext.parallelize(Seq(People("zhangsan", 9), People("lisi", 15))) val peopleDS: Dataset[People] = peopleRDD.toDS() peopleDS.createOrReplaceTempView("people") val teenagers: DataFrame = spark.sql("select name from people where age > 10 and age < 20") /* +----+ |name| +----+ |lisi| +----+ */ teenagers.show()以往使用 SQL 肯定是要有一个表的, 在 Spark 中, 并不存在表的概念, 但是有一个近似的概念, 叫做 DataFrame, 所以一般情况下要先通过 DataFrame 或者 Dataset 注册一张临时表, 然后使用 SQL 操作这张临时表
SparkSQL 提供了 SQL 和 命令式 API 两种不同的访问结构化数据的形式, 并且它们之间可以无缝的衔接
命令式 API 由一个叫做 Dataset 的组件提供, 其还有一个变形, 叫做 DataFrame
3. [扩展] Catalyst 优化器
-
理解
SparkSQL和以RDD为代表的SparkCore最大的区别 -
理解优化器的运行原理和作用
3.1. RDD 和 SparkSQL 运行时的区别
-
-
大致运行步骤
-
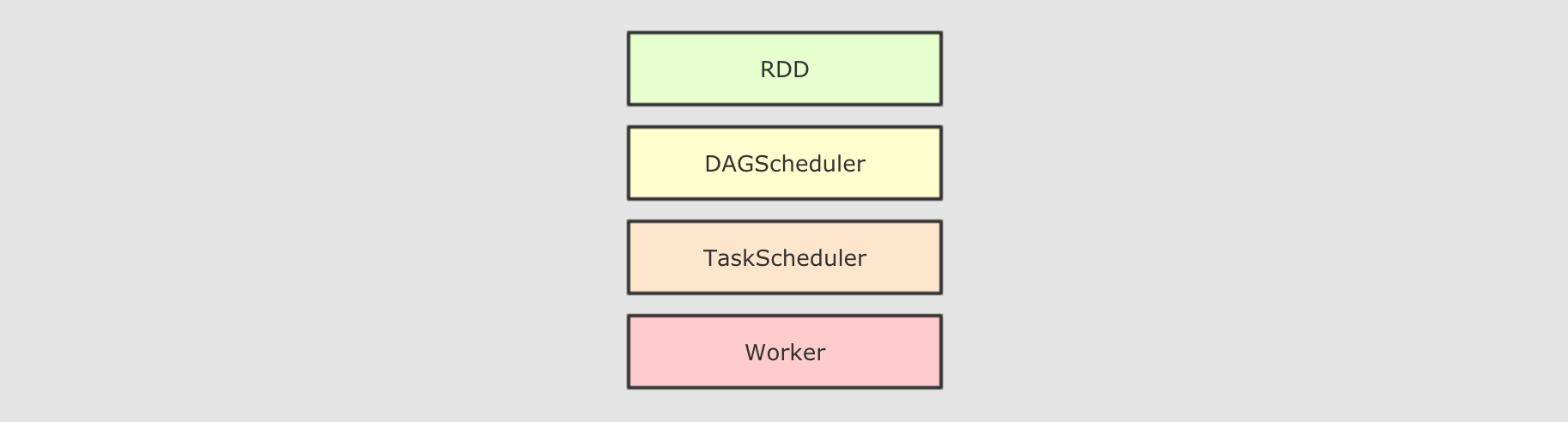
先将
RDD解析为由Stage组成的DAG, 后将Stage转为Task直接运行
问题
-
任务会按照代码所示运行, 依赖开发者的优化, 开发者的会在很大程度上影响运行效率
解决办法
-
创建一个组件, 帮助开发者修改和优化代码, 但是这在
RDD上是无法实现的
为什么
-
-
-
RDD没有Schema信息 -
RDD可以同时处理结构化和非结构化的数据
-
-
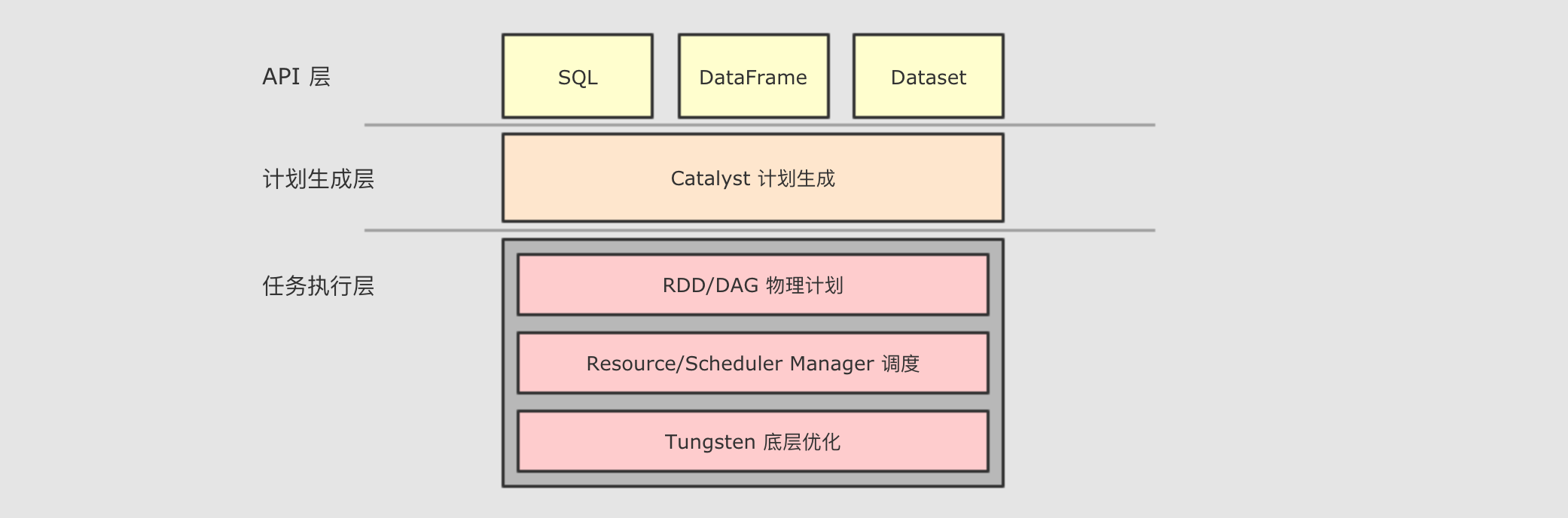
和
RDD不同,SparkSQL的Dataset和SQL并不是直接生成计划交给集群执行, 而是经过了一个叫做Catalyst的优化器, 这个优化器能够自动帮助开发者优化代码也就是说, 在
SparkSQL中, 开发者的代码即使不够优化, 也会被优化为相对较好的形式去执行-
为什么
-
首先,
SparkSQL大部分情况用于处理结构化数据和半结构化数据, 所以SparkSQL可以获知数据的Schema, 从而根据其Schema来进行优化
SparkSQL提供了这种能力? -
RDD 的运行流程
RDD 无法自我优化?
SparkSQL 提供了什么?
3.2. Catalyst
|
为了解决过多依赖 
|

-
Step 1 : 解析
-
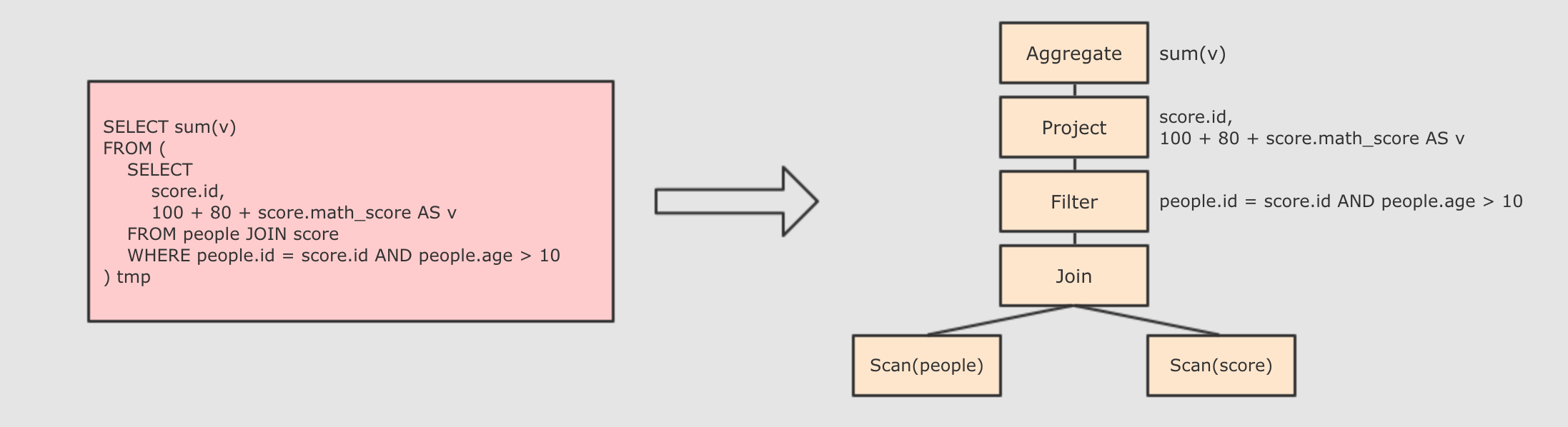 Step 2 : 在
Step 2 : 在
-
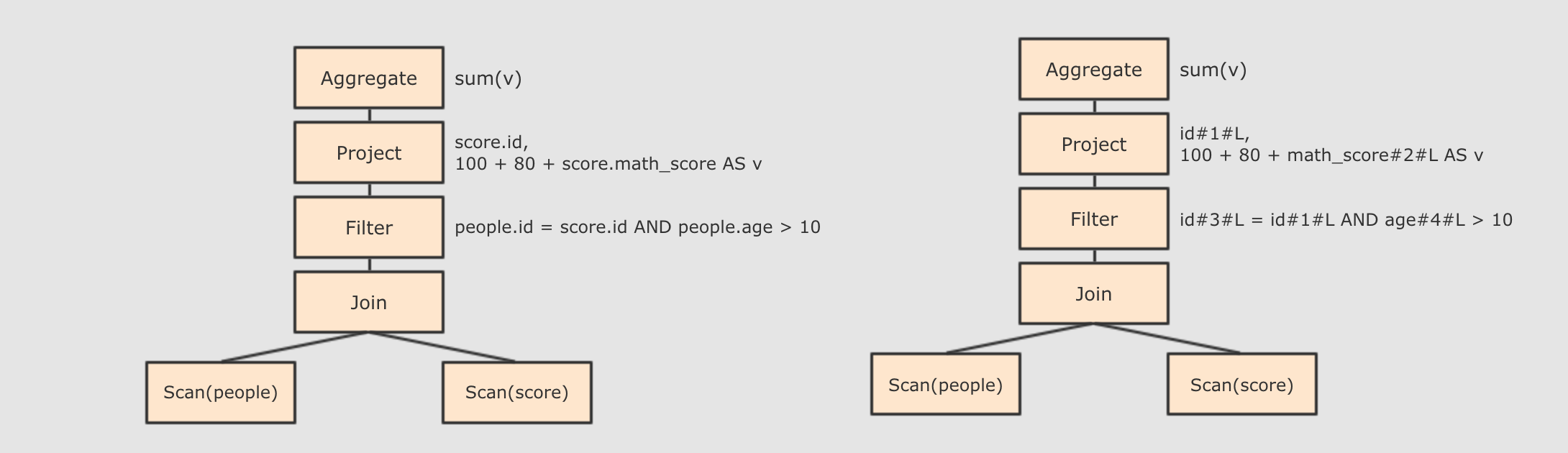
-
score.id → id#1#L为score.id生成id为 1, 类型是Long -
score.math_score → math_score#2#L为score.math_score生成id为 2, 类型为Long -
people.id → id#3#L为people.id生成id为 3, 类型为Long -
people.age → age#4#L为people.age生成id为 4, 类型为Long
Step 3 : 对已经加入元数据的
-
-
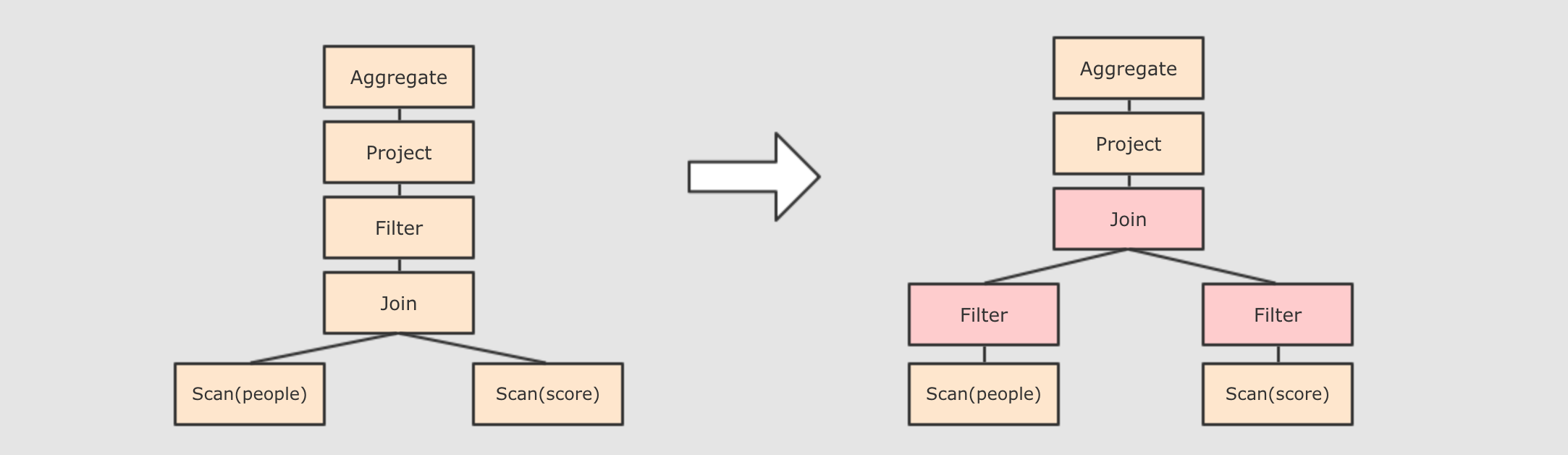
-
谓词下推
Predicate Pushdown, 将Filter这种可以减小数据集的操作下推, 放在Scan的位置, 这样可以减少操作时候的数据量
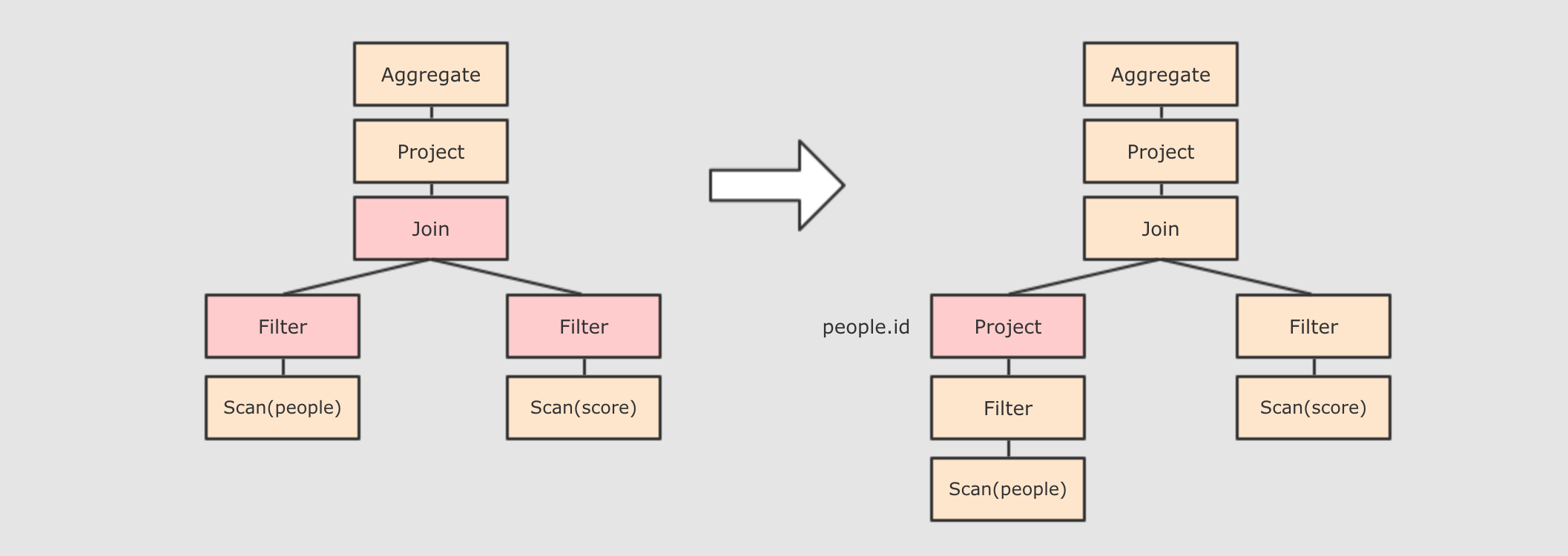
-
列值裁剪
Column Pruning, 在谓词下推后,people表之上的操作只用到了id列, 所以可以把其它列裁剪掉, 这样可以减少处理的数据量, 从而优化处理速度
-
还有其余很多优化点, 大概一共有一二百种, 随着
SparkSQL的发展, 还会越来越多, 感兴趣的同学可以继续通过源码了解, 源码在org.apache.spark.sql.catalyst.optimizer.Optimizer
Step 4 : 上面的过程生成的
-
-
-
在生成`物理计划`的时候, 会经过`成本模型`对整棵树再次执行优化, 选择一个更好的计划
-
在生成`物理计划`以后, 因为考虑到性能, 所以会使用代码生成, 在机器中运行
-
SQL, 并且生成
AST (抽象语法树)
AST 中加入元数据信息, 做这一步主要是为了一些优化, 例如
col = col 这样的条件, 下图是一个简略图, 便于理解
AST, 输入优化器, 进行优化, 从两种常见的优化开始, 简单介绍
AST 其实最终还没办法直接运行, 这个
AST 叫做
逻辑计划, 结束后, 需要生成
物理计划, 从而生成
RDD 来运行
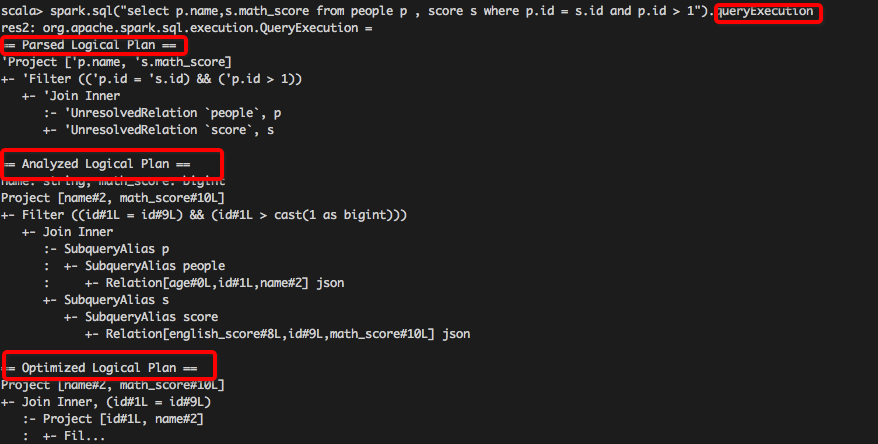
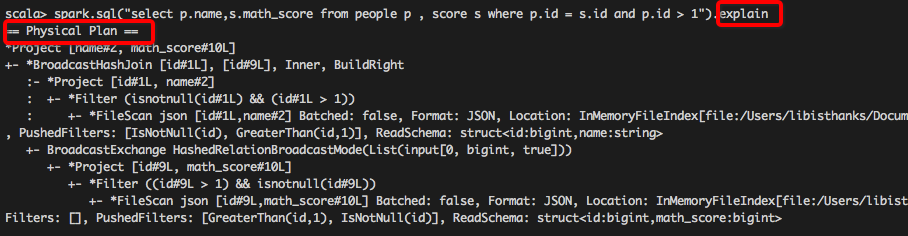
queryExecution 方法查看逻辑执行计划, 使用
explain 方法查看物理执行计划
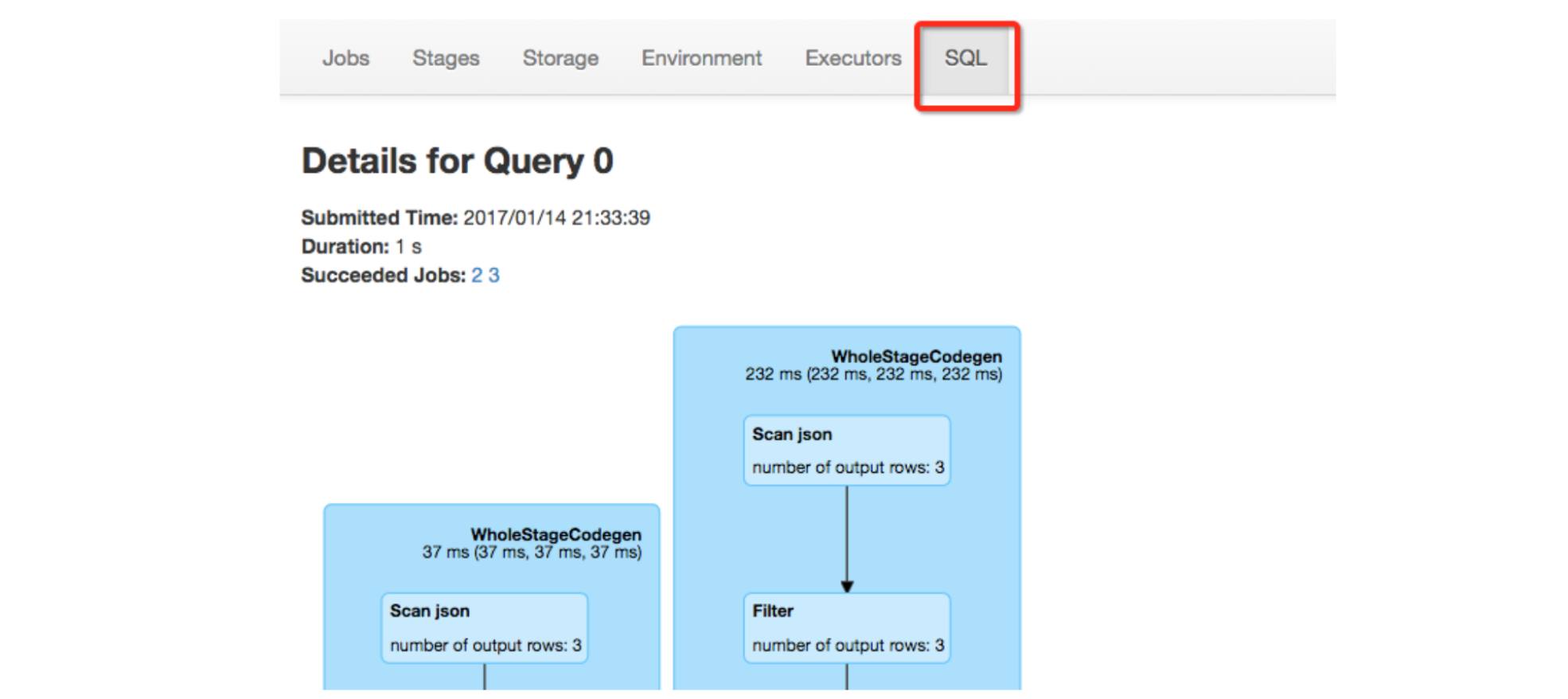
Spark WebUI 进行查看
|
SparkSQL 和 RDD 不同的主要点是在于其所操作的数据是结构化的, 提供了对数据更强的感知和分析能力, 能够对代码进行更深层的优化, 而这种能力是由一个叫做 Catalyst 的优化器所提供的
Catalyst 的主要运作原理是分为三步, 先对 SQL 或者 Dataset 的代码解析, 生成逻辑计划, 后对逻辑计划进行优化, 再生成物理计划, 最后生成代码到集群中以 RDD 的形式运行
4. Dataset 的特点
-
理解
Dataset是什么 -
理解
Dataset的特性
- 即使使用
-
Dataset最底层处理的是对象的序列化形式, 通过查看Dataset生成的物理执行计划, 也就是最终所处理的RDD, 就可以判定Dataset底层处理的是什么形式的数据val dataset: Dataset[People] = spark.createDataset(Seq(People("zhangsan", 9), People("lisi", 15))) val internalRDD: RDD[InternalRow] = dataset.queryExecution.toRdddataset.queryExecution.toRdd这个API可以看到Dataset底层执行的RDD, 这个RDD中的范型是InternalRow,InternalRow又称之为Catalyst Row, 是Dataset底层的数据结构, 也就是说, 无论Dataset的范型是什么, 无论是Dataset[Person]还是其它的, 其最底层进行处理的数据结构都是InternalRow所以,
Dataset的范型对象在执行之前, 需要通过Encoder转换为InternalRow, 在输入之前, 需要把InternalRow通过Decoder转换为范型对象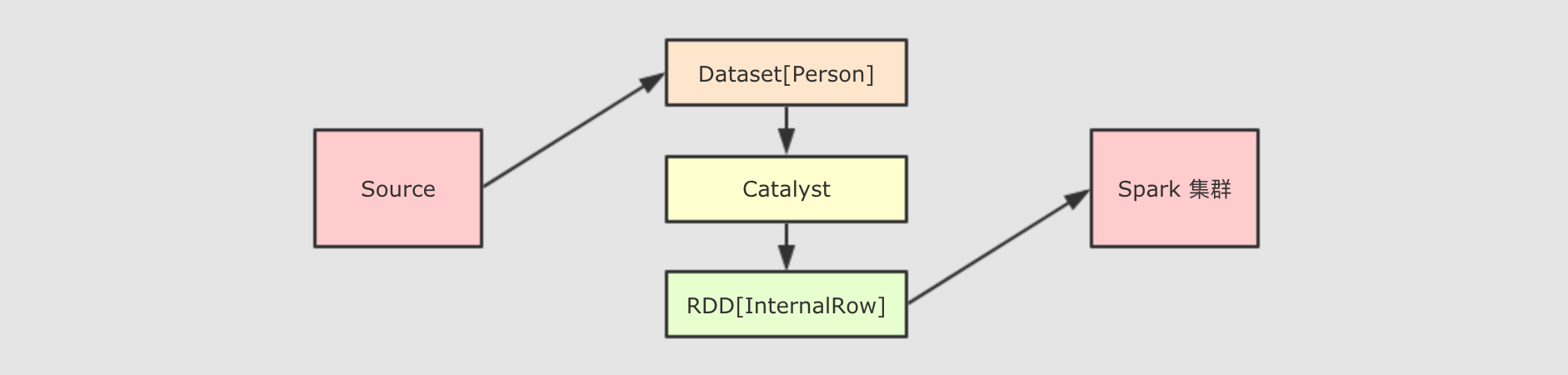 可以获取
可以获取
Dataset 是什么?
Dataset 的命令式
API, 执行计划也依然会被优化
Dataset 的底层是什么?
Dataset 对应的
RDD 表示
-
Dataset是一个新的Spark组件, 其底层还是RDD -
Dataset提供了访问对象中某个特定字段的能力, 不用像RDD一样每次都要针对整个对象做操作 -
Dataset和RDD不同, 如果想把Dataset[T]转为RDD[T], 则需要对Dataset底层的InternalRow做转换, 是一个比价重量级的操作
5. DataFrame 的作用和常见操作
-
理解
DataFrame是什么 -
理解
DataFrame的常见操作
-
DataFrame是SparkSQL中一个表示关系型数据库中表的函数式抽象, 其作用是让Spark处理大规模结构化数据的时候更加容易. 一般DataFrame可以处理结构化的数据, 或者是半结构化的数据, 因为这两类数据中都可以获取到Schema信息. 也就是说DataFrame中有Schema信息, 可以像操作表一样操作DataFrame.
DataFrame由两部分构成, 一是row的集合, 每个row对象表示一个行, 二是描述DataFrame结构的Schema.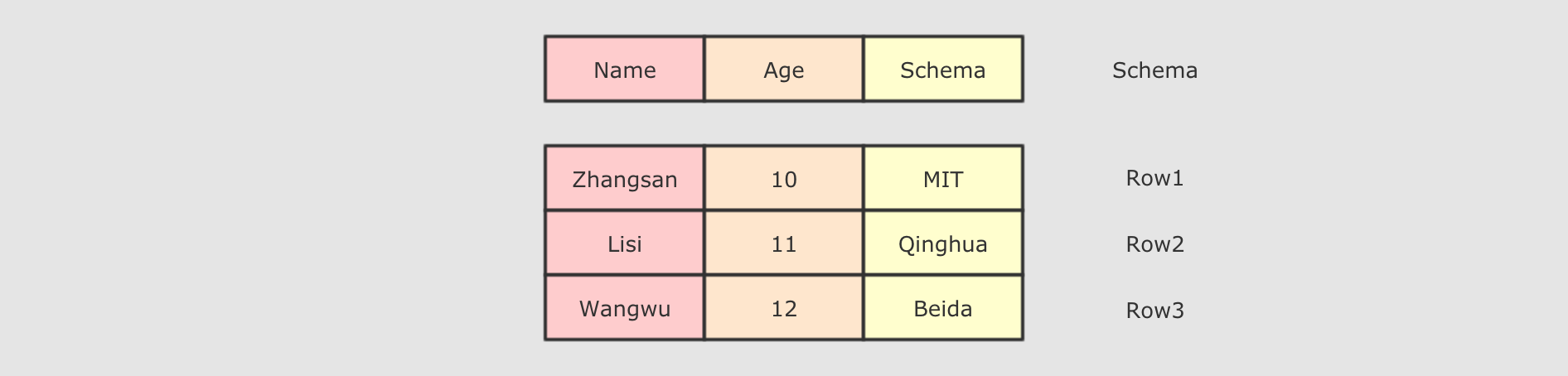
DataFrame支持SQL中常见的操作, 例如:select,filter,join,group,sort,join等val spark: SparkSession = new sql.SparkSession.Builder() .appName("hello") .master("local[6]") .getOrCreate() import spark.implicits._ val peopleDF: DataFrame = Seq(People("zhangsan", 15), People("lisi", 15)).toDF() /* +---+-----+ |age|count| +---+-----+ | 15| 2| +---+-----+ */ peopleDF.groupBy('age) .count() .show()
通过隐式转换创建
-
这种方式本质上是使用
SparkSession中的隐式转换来进行的val spark: SparkSession = new sql.SparkSession.Builder() .appName("hello") .master("local[6]") .getOrCreate() // 必须要导入隐式转换 // 注意: spark 在此处不是包, 而是 SparkSession 对象 import spark.implicits._ val peopleDF: DataFrame = Seq(People("zhangsan", 15), People("lisi", 15)).toDF()
根据源码可以知道,
toDF方法可以在RDD和Seq中使用通过集合创建
DataFrame的时候, 集合中不仅可以包含样例类, 也可以只有普通数据类型, 后通过指定列名来创建val spark: SparkSession = new sql.SparkSession.Builder() .appName("hello") .master("local[6]") .getOrCreate() import spark.implicits._ val df1: DataFrame = Seq("nihao", "hello").toDF("text") /* +-----+ | text| +-----+ |nihao| |hello| +-----+ */ df1.show() val df2: DataFrame = Seq(("a", 1), ("b", 1)).toDF("word", "count") /* +----+-----+ |word|count| +----+-----+ | a| 1| | b| 1| +----+-----+ */ df2.show()
通过外部集合创建
- 在
- 使用
DataFrame 是什么?
DataFrame
DataFrame
DataFrame 上可以使用的常规操作
SQL 操作
DataFrame
-
DataFrame是一个类似于关系型数据库表的函数式组件 -
DataFrame一般处理结构化数据和半结构化数据 -
DataFrame具有数据对象的 Schema 信息 -
可以使用命令式的
API操作DataFrame, 同时也可以使用SQL操作DataFrame -
DataFrame可以由一个已经存在的集合直接创建, 也可以读取外部的数据源来创建
6. Dataset 和 DataFrame 的异同
-
理解
Dataset和DataFrame之间的关系
-
根据前面的内容, 可以得到如下信息
-
Dataset中可以使用列来访问数据,DataFrame也可以 -
Dataset的执行是优化的,DataFrame也是 -
Dataset具有命令式API, 同时也可以使用SQL来访问,DataFrame也可以使用这两种不同的方式访问
所以这件事就比较蹊跷了, 两个这么相近的东西为什么会同时出现在
SparkSQL中呢?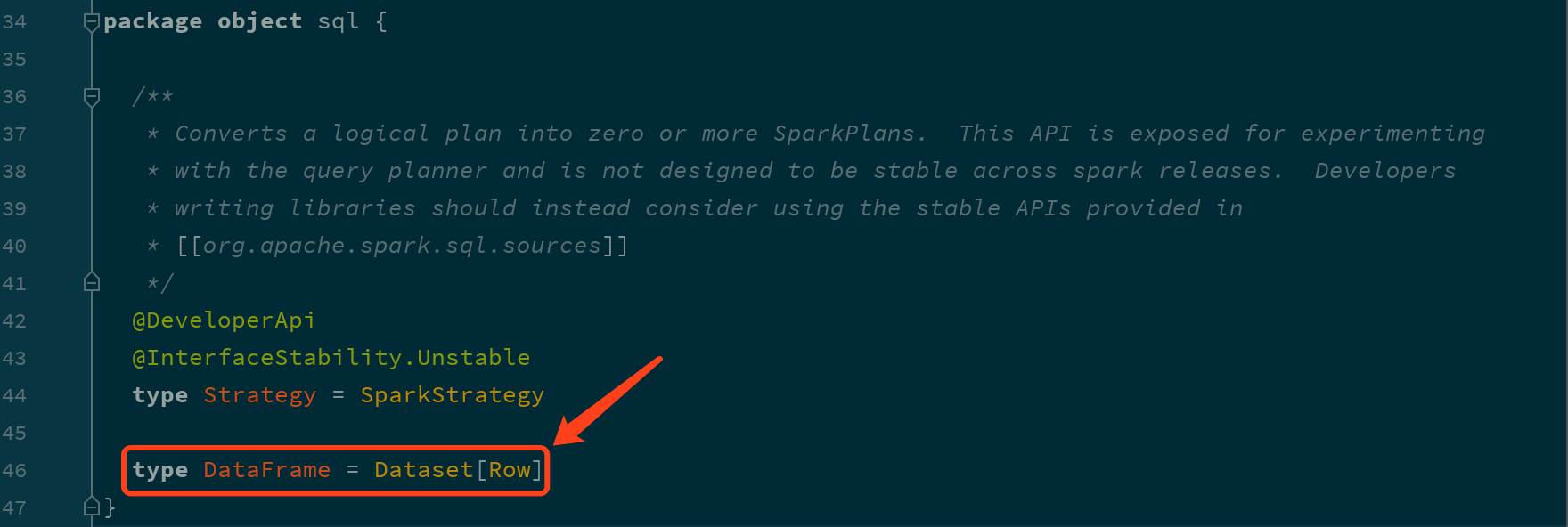
确实, 这两个组件是同一个东西,
DataFrame是Dataset的一种特殊情况, 也就是说DataFrame是Dataset[Row]的别名 -
-
val spark: SparkSession = new sql.SparkSession.Builder() .appName("hello") .master("local[6]") .getOrCreate() import spark.implicits._ val df: DataFrame = Seq(People("zhangsan", 15), People("lisi", 15)).toDF() val ds_fdf: Dataset[People] = df.as[People] val ds: Dataset[People] = Seq(People("zhangsan", 15), People("lisi", 15)).toDS() val df_fds: DataFrame = ds.toDF()
DataFrame 就是
Dataset
DataFrame 和
Dataset 所表达的语义不同
Row 是什么?
DataFrame 和
Dataset 之间可以非常简单的相互转换
-
DataFrame就是Dataset, 他们的方式是一样的, 也都支持API和SQL两种操作方式 -
DataFrame只能通过表达式的形式, 或者列的形式来访问数据, 只有Dataset支持针对于整个对象的操作 -
DataFrame中的数据表示为Row, 是一个行的概念
7. 数据读写
-
理解外部数据源的访问框架
-
掌握常见的数据源读写方式
7.1. 初识 DataFrameReader
-
理解
DataFrameReader的整体结构和组成
SparkSQL 的一个非常重要的目标就是完善数据读取, 所以 SparkSQL 中增加了一个新的框架, 专门用于读取外部数据源, 叫做 DataFrameReader
import org.apache.spark.sql.SparkSession
import org.apache.spark.sql.DataFrameReader
val spark: SparkSession = ... val reader: DataFrameReader = spark.readDataFrameReader 由如下几个组件组成
| 组件 | 解释 |
|---|---|
|
| 结构信息, 因为 |
|
| 连接外部数据源的参数, 例如 |
|
| 外部数据源的格式, 例如 |
DataFrameReader 有两种访问方式, 一种是使用 load 方法加载, 使用 format 指定加载格式, 还有一种是使用封装方法, 类似 csv, json, jdbc 等
import org.apache.spark.sql.SparkSession
import org.apache.spark.sql.DataFrame
val spark: SparkSession = ... // 使用 load 方法 val fromLoad: DataFrame = spark .read .format("csv") .option("header", true) .option("inferSchema", true) .load("dataset/BeijingPM20100101_20151231.csv") // Using format-specific load operator val fromCSV: DataFrame = spark .read .option("header", true) .option("inferSchema", true) .csv("dataset/BeijingPM20100101_20151231.csv")但是其实这两种方式本质上一样, 因为类似 csv 这样的方式只是 load 的封装

|
如果使用 也就是说, |
-
使用
spark.read可以获取 SparkSQL 中的外部数据源访问框架DataFrameReader -
DataFrameReader有三个组件format,schema,option -
DataFrameReader有两种使用方式, 一种是使用load加format指定格式, 还有一种是使用封装方法csv,json等
7.2. 初识 DataFrameWriter
-
理解
DataFrameWriter的结构
对于 ETL 来说, 数据保存和数据读取一样重要, 所以 SparkSQL 中增加了一个新的数据写入框架, 叫做 DataFrameWriter
val spark: SparkSession = ...
val df = spark.read
.option("header", true) .csv("dataset/BeijingPM20100101_20151231.csv") val writer: DataFrameWriter[Row] = df.writeDataFrameWriter 中由如下几个部分组成
| 组件 | 解释 |
|---|---|
|
| 写入目标, 文件格式等, 通过 |
|
| 写入模式, 例如一张表已经存在, 如果通过 |
|
| 外部参数, 例如 |
|
| 类似 |
|
| 类似 |
|
| 用于排序的列, 通过 |
mode 指定了写入模式, 例如覆盖原数据集, 或者向原数据集合中尾部添加等
Scala 对象表示 | 字符串表示 | 解释 |
|---|---|---|
|
|
| 将 |
|
|
| 将 |
|
|
| 将 |
|
|
| 将 |
DataFrameWriter 也有两种使用方式, 一种是使用 format 配合 save, 还有一种是使用封装方法, 例如 csv, json, saveAsTable 等
val spark: SparkSession = ...
val df = spark.read
.option("header", true) .csv("dataset/BeijingPM20100101_20151231.csv") // 使用 save 保存, 使用 format 设置文件格式 df.write.format("json").save("dataset/beijingPM") // 使用 json 保存, 因为方法是 json, 所以隐含的 format 是 json df.write.json("dataset/beijingPM1")|
默认没有指定 |
-
类似
DataFrameReader,Writer中也有format,options, 另外schema是包含在DataFrame中的 -
DataFrameWriter中还有一个很重要的概念叫做mode, 指定写入模式, 如果目标集合已经存在时的行为 -
DataFrameWriter可以将数据保存到Hive表中, 所以也可以指定分区和分桶信息
7.3. 读写 Parquet 格式文件
-
理解
Spark读写Parquet文件的语法 -
理解
Spark读写Parquet文件的时候对于分区的处理
-
什么时候会用到
-

在
ETL中,Spark经常扮演T的职务, 也就是进行数据清洗和数据转换.为了能够保存比较复杂的数据, 并且保证性能和压缩率, 通常使用
Parquet是一个比较不错的选择.所以外部系统收集过来的数据, 有可能会使用
Parquet, 而Spark进行读取和转换的时候, 就需要支持对Parquet格式的文件的支持.
使用代码读写
- 写入
-
Spark在写入文件的时候是支持分区的, 可以像Hive一样设置某个列为分区列val spark: SparkSession = new sql.SparkSession.Builder() .appName("hello") .master("local[6]") .getOrCreate() // 从 CSV 中读取内容 val dfFromParquet = spark.read.option("header", value = true).csv("dataset/BeijingPM20100101_20151231.csv") // 保存为 Parquet 格式文件, 不指定 format 默认就是 Parquet dfFromParquet.write.partitionBy("year", "month").save("dataset/beijing_pm")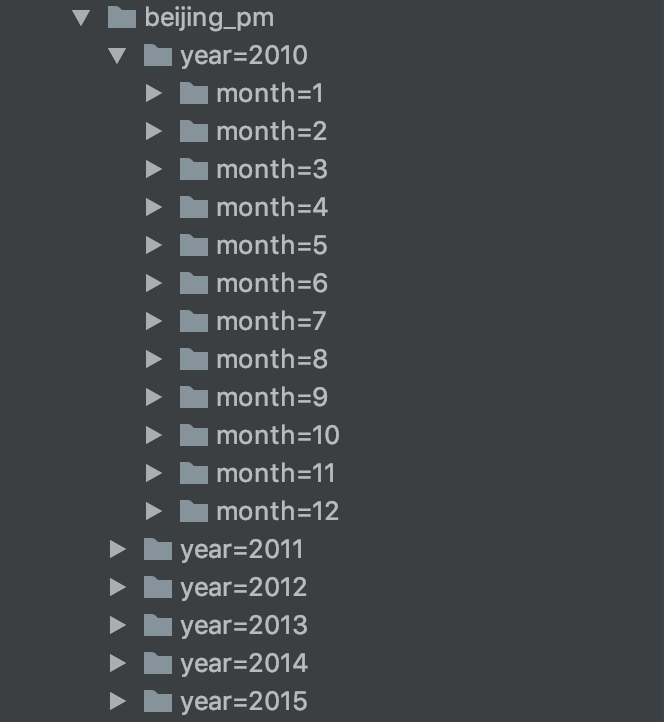
Parquet ?
Parquet 文件
Parquet 的时候可以指定分区
|
这个地方指的分区是类似 |
-
分区发现
-
在读取常见文件格式的时候,
Spark会自动的进行分区发现, 分区自动发现的时候, 会将文件名中的分区信息当作一列. 例如 如果按照性别分区, 那么一般会生成两个文件夹gender=male和gender=female, 那么在使用Spark读取的时候, 会自动发现这个分区信息, 并且当作列放入创建的DataFrame中使用代码证明这件事可以有两个步骤, 第一步先读取某个分区的单独一个文件并打印其
Schema信息, 第二步读取整个数据集所有分区并打印Schema信息, 和第一步做比较就可以确定val spark = ... val partDF = spark.read.load("dataset/beijing_pm/year=2010/month=1") partDF.printSchema()把分区的数据集中的某一个区单做一整个数据集读取, 没有分区信息, 自然也不会进行分区发现 
val df = spark.read.load("dataset/beijing_pm") df.printSchema()此处读取的是整个数据集, 会进行分区发现, DataFrame 中会包含分去列 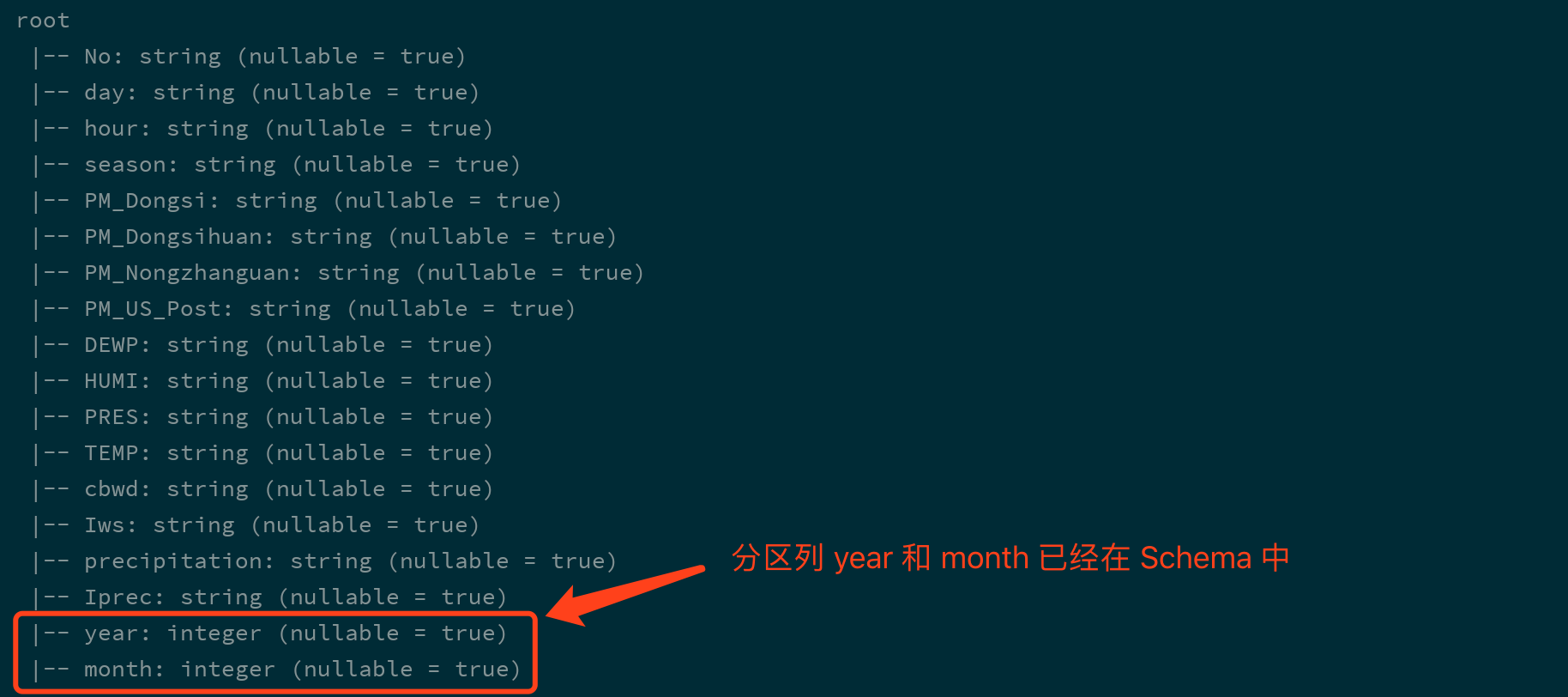
| 配置 | 默认值 | 含义 |
|---|---|---|
|
|
| 一些其他 |
|
|
| 一些其他 |
|
|
| 打开 Parquet 元数据的缓存, 可以加快查询静态数据 |
|
|
| 压缩方式, 可选 |
|
|
| 当为 true 时, Parquet 数据源会合并从所有数据文件收集的 Schemas 和数据, 因为这个操作开销比较大, 所以默认关闭 |
|
|
| 如果为 |
-
Spark不指定format的时候默认就是按照Parquet的格式解析文件 -
Spark在读取Parquet文件的时候会自动的发现Parquet的分区和分区字段 -
Spark在写入Parquet文件的时候如果设置了分区字段, 会自动的按照分区存储
7.4. 读写 JSON 格式文件
-
理解
JSON的使用场景 -
能够使用
Spark读取处理JSON格式文件
-
什么时候会用到
-
在
ETL中,Spark经常扮演T的职务, 也就是进行数据清洗和数据转换.在业务系统中,
JSON是一个非常常见的数据格式, 在前后端交互的时候也往往会使用JSON, 所以从业务系统获取的数据很大可能性是使用JSON格式, 所以就需要Spark能够支持 JSON 格式文件的读取
读写
-
将要
Dataset保存为JSON格式的文件比较简单, 是DataFrameWriter的一个常规使用val spark: SparkSession = new sql.SparkSession.Builder() .appName("hello") .master("local[6]") .getOrCreate() val dfFromParquet = spark.read.load("dataset/beijing_pm") // 将 DataFrame 保存为 JSON 格式的文件 dfFromParquet.repartition(1) .write.format("json") .save("dataset/beijing_pm_json")如果不重新分区, 则会为 DataFrame底层的RDD的每个分区生成一个文件, 为了保持只有一个输出文件, 所以重新分区保存为
JSON格式的文件有一个细节需要注意, 这个JSON格式的文件中, 每一行是一个独立的JSON, 但是整个文件并不只是一个JSON字符串, 所以这种文件格式很多时候被成为JSON Line文件, 有时候后缀名也会变为jsonlbeijing_pm.jsonl{"day":"1","hour":"0","season":"1","year":2013,"month":3} {"day":"1","hour":"1","season":"1","year":2013,"month":3} {"day":"1","hour":"2","season":"1","year":2013,"month":3}也可以通过
DataFrameReader读取一个JSON Line文件val spark: SparkSession = ... val dfFromJSON = spark.read.json("dataset/beijing_pm_json") dfFromJSON.show()JSON格式的文件是有结构信息的, 也就是JSON中的字段是有类型的, 例如"name": "zhangsan"这样由双引号包裹的Value, 就是字符串类型, 而"age": 10这种没有双引号包裹的就是数字类型, 当然, 也可以是布尔型"has_wife": trueSpark读取JSON Line文件的时候, 会自动的推断类型信息val spark: SparkSession = ... val dfFromJSON = spark.read.json("dataset/beijing_pm_json") dfFromJSON.printSchema()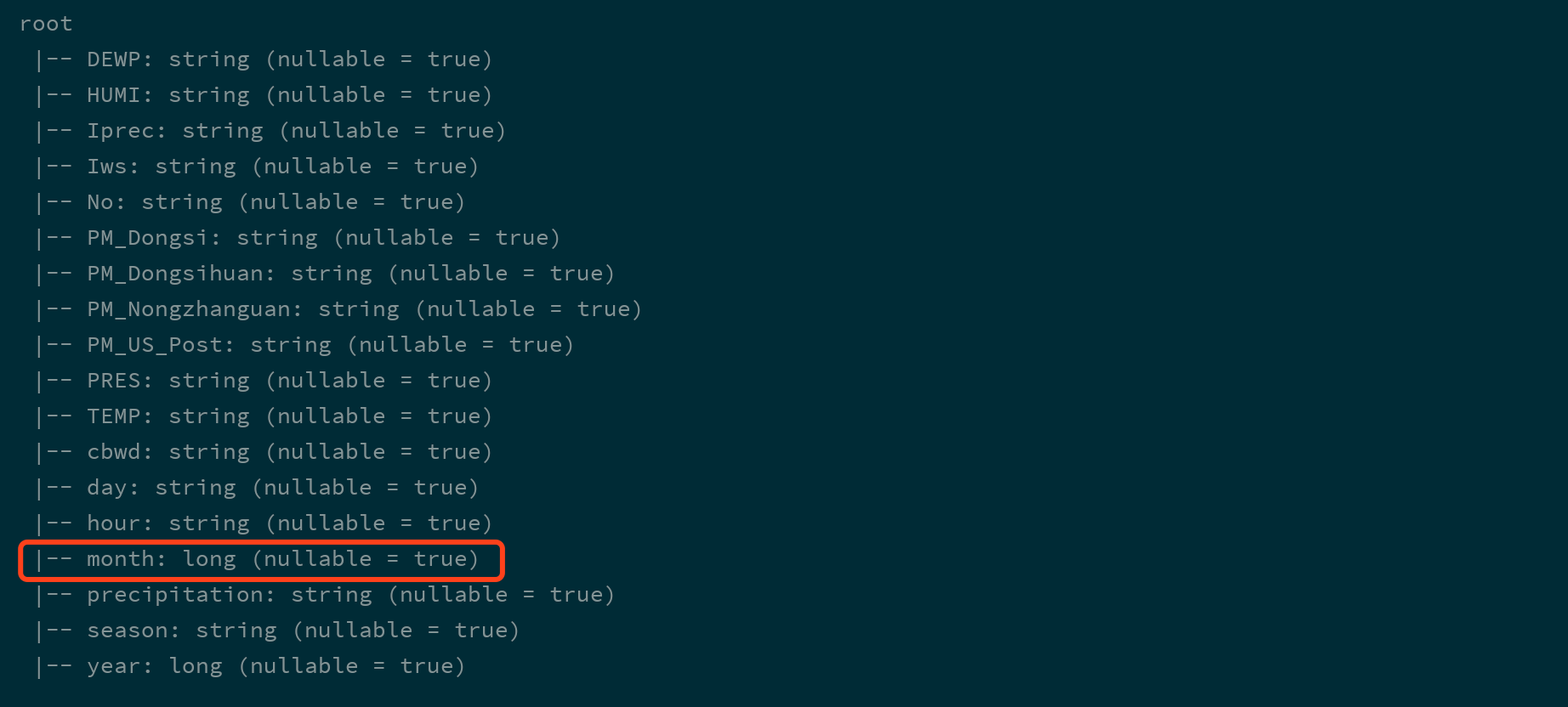
-
这种情况其实还是比较常见的, 例如如下的流程

假设业务系统通过
Kafka将数据流转进入大数据平台, 这个时候可能需要使用RDD或者Dataset来读取其中的内容, 这个时候一条数据就是一个JSON格式的字符串, 如何将其转为DataFrame或者Dataset[Object]这样具有Schema的数据集呢? 使用如下代码就可以val spark: SparkSession = ... import spark.implicits._ val peopleDataset = spark.createDataset( """{"name":"Yin","address":{"city":"Columbus","state":"Ohio"}}""" :: Nil) spark.read.json(peopleDataset).show()
JSON ?
JSON 文件
Spark 可以从一个保存了
JSON 格式字符串的
Dataset[String] 中读取
JSON 信息, 转为
DataFrame
-
JSON通常用于系统间的交互,Spark经常要读取JSON格式文件, 处理, 放在另外一处 -
使用
DataFrameReader和DataFrameWriter可以轻易的读取和写入JSON, 并且会自动处理数据类型信息
7.5. 访问 Hive
-
整合
SparkSQL和Hive, 使用Hive的MetaStore元信息库 -
使用
SparkSQL查询Hive表 -
案例, 使用常见
HiveSQL -
写入内容到
Hive表
7.5.1. SparkSQL 整合 Hive
-
开启
Hive的MetaStore独立进程 -
整合
SparkSQL和Hive的MetaStore
和一个文件格式不同, Hive 是一个外部的数据存储和查询引擎, 所以如果 Spark 要访问 Hive 的话, 就需要先整合 Hive
-
整合什么 ?
- 为什么要开启
-
Hive的MetaStore是一个Hive的组件, 一个Hive提供的程序, 用以保存和访问表的元数据, 整个Hive的结构大致如下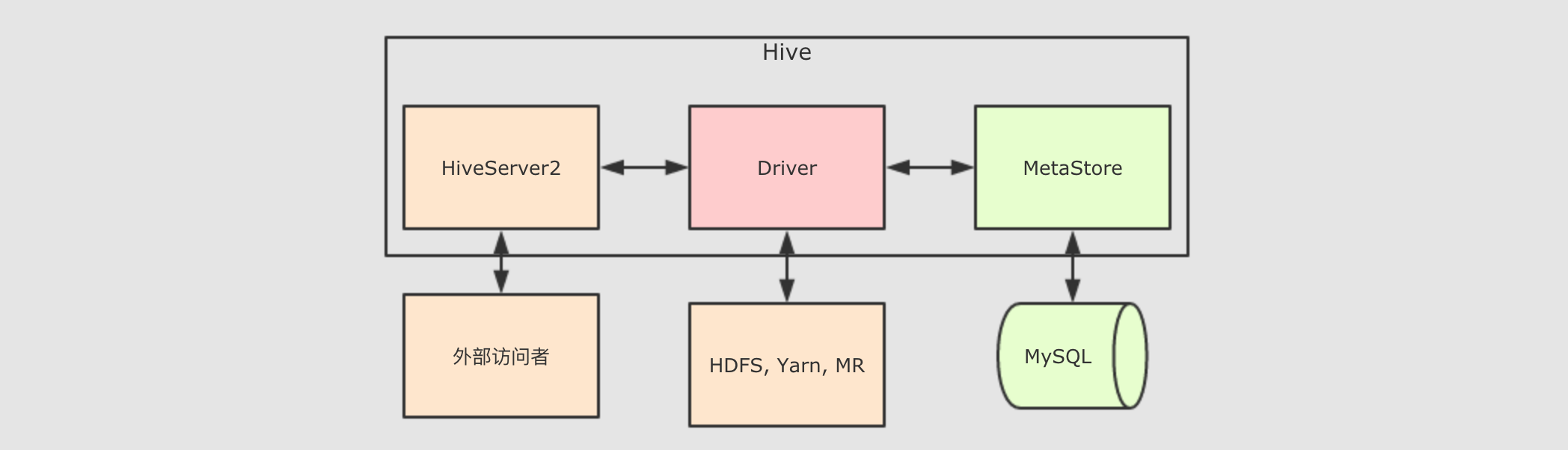
由上图可知道, 其实
Hive中主要的组件就三个,HiveServer2负责接受外部系统的查询请求, 例如JDBC,HiveServer2接收到查询请求后, 交给Driver处理,Driver会首先去询问MetaStore表在哪存, 后Driver程序通过MR程序来访问HDFS从而获取结果返回给查询请求者而
Hive的MetaStore对SparkSQL的意义非常重大, 如果SparkSQL可以直接访问Hive的MetaStore, 则理论上可以做到和Hive一样的事情, 例如通过Hive表查询数据而 Hive 的 MetaStore 的运行模式有三种
-
内嵌
Derby数据库模式这种模式不必说了, 自然是在测试的时候使用, 生产环境不太可能使用嵌入式数据库, 一是不稳定, 二是这个
Derby是单连接的, 不支持并发 -
Local模式Local和Remote都是访问MySQL数据库作为存储元数据的地方, 但是Local模式的MetaStore没有独立进程, 依附于HiveServer2的进程 -
Remote模式和
Loca模式一样, 访问MySQL数据库存放元数据, 但是Remote的MetaStore运行在独立的进程中
我们显然要选择
Remote模式, 因为要让其独立运行, 这样才能让SparkSQL一直可以访问 -
Hive 的
MetaStore
Hive 开启
MetaStore
SparkSQL 整合
Hive 的
MetaStore
|
如果不希望通过拷贝文件的方式整合 Hive, 也可以在 SparkSession 启动的时候, 通过指定 Hive 的 MetaStore 的位置来访问, 但是更推荐整合的方式 |
7.5.2. 访问 Hive 表
-
在
Hive中创建表 -
使用
SparkSQL访问Hive中已经存在的表 -
使用
SparkSQL创建Hive表 -
使用
SparkSQL修改Hive表中的数据
-
在
- 通过
- 通过
- 使用
Hive 中创建表
SparkSQL 查询
Hive 的表
SparkSQL 创建
Hive 表
SparkSQL 处理数据并保存进 Hive 表
7.6. JDBC
-
通过
SQL操作MySQL的表 -
将数据写入
MySQL的表中
-
准备
- 使用
- 运行程序
- 从
MySQL 环境
SparkSQL 向
MySQL 中写入数据
MySQL 中读取数据
转载于:https://www.cnblogs.com/mediocreWorld/p/11614461.html
最后
以上就是忐忑小鸽子最近收集整理的关于Update:sparksql:第1节 SparkSQL_使用场景_优化器_Dataset的全部内容,更多相关Update:sparksql:第1节内容请搜索靠谱客的其他文章。








发表评论 取消回复