常用查询
python实现各进制转换的总结大全 :
https://www.jb51.net/article/116482.htm
https://www.jb51.net/article/139206.htm
字符串的切片操作:
https://www.jb51.net/article/161326.htm
方法
strip()
strip() 方法用于移除字符串头尾指定的字符(默认为空格或换行符)或字符序列
str.split()方法
split(str="", num=string.count(str))
以 str 为分隔符截取字符串,如果 num 有指定值,则仅截取 num+1 个子字符串
str.rjust(4, ‘0’)
string.rjust(width) 返回一个原字符串右对齐,并使用空格填充至长度 width 的新字符串
str.rfind(str)
rfind(str, beg=0,end=len(string))
类似于 find()函数,不过是从右边开始查找.
str.replace(old, new [, max])
replace(old, new [, max]) 把 将字符串中的 old 替换成 new,如果 max 指定,则替换不超过 max 次。
标题"新增分割".join[]
join(seq) 以指定字符串作为分隔符,将 seq 中所有的元素(的字符串表示)合并为一个新的字符串
大小写转换及查找
lower() 大写转为小写
upper() 小写转为大写
swapcase() 将字符串中大写转换为小写,小写转换为大写
isupper()如果字符串中包含至少一个区分大小写的字符,并且所有这些(区分大小写的)字符都是大写,则返回 True,否则返回 False
isnumeric() 如果字符串中只包含数字字符,则返回 True,否则返回 False
isspace()如果字符串中只包含空白,则返回 True,否则返回 False.
islower()如果字符串中包含至少一个区分大小写的字符,并且所有这些(区分大小写的)字符都是小写,则返回 True,否则返回 False
isdigit()如果字符串只包含数字则返回 True 否则返回 False…
isalpha()如果字符串至少有一个字符并且所有字符都是字母或中文字则返回 True, 否则返回 False
isalnum()如果字符串至少有一个字符并且所有字符都是字母或数字则返 回 True,否则返回 False
n,m = map(int, input().split())
题目
HJ32 没有看懂题
描述
Catcher是MCA国的情报员,他工作时发现敌国会用一些对称的密码进行通信,比如像这些ABBA,ABA,A,123321,但是他们有时会在开始或结束时加入一些无关的字符以防止别国破解。比如进行下列变化 ABBA->12ABBA,ABA->ABAKK,123321->51233214 。因为截获的串太长了,而且存在多种可能的情况(abaaab可看作是aba,或baaab的加密形式),Cathcer的工作量实在是太大了,他只能向电脑高手求助,你能帮Catcher找出最长的有效密码串吗?
数据范围:字符串长度满足 1 le n le 2500 1≤n≤2500
输入描述:
输入一个字符串(字符串的长度不超过2500)
输出描述:
返回有效密码串的最大长度
HJ 33 整数与IP地址的转换
描述
原理:ip地址的每段可以看成是一个0-255的整数,把每段拆分成一个二进制形式组合起来,然后把这个二进制数转变成
一个长整数。
举例:一个ip地址为10.0.3.193
每段数字 相对应的二进制数
10 00001010
0 00000000
3 00000011
193 11000001
组合起来即为:00001010 00000000 00000011 11000001,转换为10进制数就是:167773121,即该IP地址转换后的数字就是它了。
数据范围:保证输入的是合法的 IP 序列
输入描述:
输入
1 输入IP地址
2 输入10进制型的IP地址
输出描述:
输出
1 输出转换成10进制的IP地址
2 输出转换后的IP地址
知识点:
1/ 十进制转为2进制 bin(int(i)) 二进制转为十进制 int(i,2)
2/列表拼接为字符串
3/列表的切片操作 https://www.jb51.net/article/161548.htm
list[2:4] 获取第2到第5位
list[2:] 从索引2开始到结束位置
list[::4] 从开始到结束中间隔一个字符
list[1:4] 从第二个到结束中间隔一个字符
list[2:-1] 从第二个到末尾的字符
list[-2:] 截取末尾两个字符
list[::-1] 反转
list[1:8:2] 从第二个开始中间各一个曲切片
脚本
def int_ip(ip_int):
ip_bin = str(bin(int(ip_int))[2::].rjust(32,'0'))
list_ip = [ str(int(ip_bin[i:i+8],2)) for i in range(0,32,8)]
return ".".join(list_ip)
def ip_int(ip_address):
list_ip = [bin(int(i))[2::].rjust(8, '0') for i in ip_address.split('.') if 0 <= int(i) < 256]
l = ''
for ss in list_ip:
l += ss
return int(l, 2)
print(ip_int(input()))
print(int_ip(input()))
HJ34
描述
Lily上课时使用字母数字图片教小朋友们学习英语单词,每次都需要把这些图片按照大小(ASCII码值从小到大)排列收好。请大家给Lily帮忙,通过代码解决。
Lily使用的图片使用字符"A"到"Z"、“a"到"z”、"0"到"9"表示。
数据范围:每组输入的字符串长度满足 1 le n le 1000 1≤n≤1000
输入描述:
一行,一个字符串,字符串中的每个字符表示一张Lily使用的图片。
输出描述:
Lily的所有图片按照从小到大的顺序输出
while True:
try:
ss = input()
ll = []
for s in ss:
ll.append(s)
ll.sort()
print(''.join(ll))
except:
break
HJ35 蛇形矩阵
描述
蛇形矩阵是由1开始的自然数依次排列成的一个矩阵上三角形。
例如,当输入5时,应该输出的三角形为:
1 3 6 10 15
2 5 9 14
4 8 13
7 12
11
输入描述:
输入正整数N(N不大于100)
输出描述:
输出一个N行的蛇形矩阵。
知识点:
关于换行的输出
def ll(n):
ll = [1]
for i in range(2, n+1):
ll.append(ll[-1] + i)
return ll
def mm(s):
ll = []
ll.append(s)
while len(ll[-1][1::]) > 0:
mm = []
for i in ll[-1][1::]:
mm.append(i-1)
ll.append(mm)
return ll
while True:
try:
ll = ll(int(input()))
for s in mm(ll):
for o in s:
print(o,end=" ")
if len(s)>1:
print("")
except:
break
HJ36 字符串加密
描述
有一种技巧可以对数据进行加密,它使用一个单词作为它的密匙。下面是它的工作原理:首先,选择一个单词作为密匙,如TRAILBLAZERS。如果单词中包含有重复的字母,只保留第1个,将所得结果作为新字母表开头,并将新建立的字母表中未出现的字母按照正常字母表顺序加入新字母表。如下所示:
A B C D E F G H I J K L M N O P Q R S T U V W X Y Z
T R A I L B Z E S C D F G H J K M N O P Q U V W X Y (实际需建立小写字母的字母表,此字母表仅为方便演示)
上面其他用字母表中剩余的字母填充完整。在对信息进行加密时,信息中的每个字母被固定于顶上那行,并用下面那行的对应字母一一取代原文的字母(字母字符的大小写状态应该保留)。因此,使用这个密匙, Attack AT DAWN (黎明时攻击)就会被加密为Tpptad TP ITVH。
请实现下述接口,通过指定的密匙和明文得到密文。
数据范围:1 le n le 100 1≤n≤100 ,保证输入的字符串中仅包含小写字母
输入描述:
先输入key和要加密的字符串
输出描述:
返回加密后的字符串
示例1
输入:
nihao
ni
输出:
le
知识点:
灵活运用:
str.islower() 判断字符串全是小写输出 True
str.isupper() 判断字符串全是大写输出True
s.lower() 字符串转为小写
s.upper() 字符串转为大写
解体思路:
1/输入密钥去重
2/利用去重后的密钥构造出新的字符串
3/利用输入字符串转为需要的字符串
def quchong(key):
ll = ''
for i in key:
if i not in ll:
ll += i
return ll
def cankao(key):
ss = 'ABCDEFGHIJKLMNOPQRSTUVWXYZ'
mm = quchong(key)
for s in ss:
if s.upper() not in mm.upper():
mm += s
# print("ss",ss)
# print("mm",mm)
return [ss,mm]
def zhuanhaun(next,key):
oo = ''
for n in next:
if n.islower(): ## 判断是小写
oo += cankao(key)[1][cankao(key)[0].find(n.upper())].lower()
elif n.isupper(): # 判断是大写
oo += cankao(key)[1][cankao(key)[0].find(n)]
else:
oo += n
print(oo)
while True:
try:
key = input()
next = input()
zhuanhaun(next,key)
except:
break
HJ37 统计每个月兔子的总数
描述
有一种兔子,从出生后第3个月起每个月都生一只兔子,小兔子长到第三个月后每个月又生一只兔子。
例子:假设一只兔子第3个月出生,那么它第5个月开始会每个月生一只兔子。
假如兔子都不死,问第n个月的兔子总数为多少?
数据范围:输入满足 1 le n le 31 1≤n≤31
输入描述:
输入一个int型整数表示第n个月
输出描述:
输出对应的兔子总数
示例1
输入:
3
复制
输出:
2
```python
# 1 1 2 3 5 8 13 21 34
关键是要发现规
while True:
try:
n =int(input())
l = [1,1]
for i in range(2,n):
l.append(l[i-2]+l[i-1])
print(l[-1])
except:
break
HJ38 求小球落地5次后所经历的路程和第5次反弹的高度
描述
假设一个球从任意高度自由落下,每次落地后反跳回原高度的一半; 再落下, 求它在第5次落地时,共经历多少米?第5次反弹多高?
数据范围:输入的小球初始高度满足 1 le n le 1000 1≤n≤1000 ,且保证是一个整数
输入描述:
输入起始高度,int型
输出描述:
分别输出第5次落地时,共经过多少米以及第5次反弹多高。
注意:你可以认为你输出保留六位或以上小数的结果可以通过此题。
示例1
输入:
1
复制
输出:
2.875
0.03125
while True:
try:
H = int(input())
S = 0 - H
for i in range(5):
S = S + H * 2
H = H/2
print(float(S))
print(float(H))
except:
break
HJ39
描述
IP地址是由4个0-255之间的整数构成的,用"."符号相连。
二进制的IP地址格式有32位,例如:10000011,01101011,00000011,00011000;每八位用十进制表示就是131.107.3.24
子网掩码是用来判断任意两台计算机的IP地址是否属于同一子网络的根据。
子网掩码与IP地址结构相同,是32位二进制数,由1和0组成,且1和0分别连续,其中网络号部分全为“1”和主机号部分全为“0”。
你可以简单的认为子网掩码是一串连续的1和一串连续的0拼接而成的32位二进制数,左边部分都是1,右边部分都是0。
利用子网掩码可以判断两台主机是否中同一子网中。
若两台主机的IP地址分别与它们的子网掩码进行逻辑“与”运算(按位与/AND)后的结果相同,则说明这两台主机在同一子网中。
示例:
I P 地址 192.168.0.1
子网掩码 255.255.255.0
转化为二进制进行运算:
I P 地址 11000000.10101000.00000000.00000001
子网掩码 11111111.11111111.11111111.00000000
AND运算 11000000.10101000.00000000.00000000
转化为十进制后为:
192.168.0.0
I P 地址 192.168.0.254
子网掩码 255.255.255.0
转化为二进制进行运算:
I P 地址 11000000.10101000.00000000.11111110
子网掩码 11111111.11111111.11111111.00000000
AND运算 11000000.10101000.00000000.00000000
转化为十进制后为:
192.168.0.0
通过以上对两台计算机IP地址与子网掩码的AND运算后,我们可以看到它运算结果是一样的。均为192.168.0.0,所以这二台计算机可视为是同一子网络。
输入一个子网掩码以及两个ip地址,判断这两个ip地址是否是一个子网络。
若IP地址或子网掩码格式非法则输出1,若IP1与IP2属于同一子网络输出0,若IP1与IP2不属于同一子网络输出2。
注:
有效掩码与IP的性质为:
- 掩码与IP每一段在 0 - 255 之间
- 掩码的二进制字符串前缀为网络号,都由‘1’组成;后缀为主机号,都由’0’组成
输入描述:
3行输入,第1行是输入子网掩码、第2,3行是输入两个ip地址
题目的示例中给出了三组数据,但是在实际提交时,你的程序可以只处理一组数据(3行)。
输出描述:
若IP地址或子网掩码格式非法则输出1,若IP1与IP2属于同一子网络输出0,若IP1与IP2不属于同一子网络输出2
示例1
输入:
255.255.255.0
192.168.224.256
192.168.10.4
255.0.0.0
193.194.202.15
232.43.7.59
255.255.255.0
192.168.0.254
192.168.0.1
复制
输出:
1
2
0
复制
说明:
对于第一个例子:
255.255.255.0
192.168.224.256
192.168.10.4
其中IP:192.168.224.256不合法,输出1
对于第二个例子:
255.0.0.0
193.194.202.15
232.43.7.59
2个与运算之后,不在同一个子网,输出2
对于第三个例子,2个与运算之后,如题目描述所示,在同一个子网,输出0
在这里插入代码片# 判断子网掩码是否合法:
def mask(mask):
ip_mask_bin = "".join([str(bin(int(i))[2::]).rjust(8, '0') for i in mask])
if ip_mask_bin.rfind('1')+1 == ip_mask_bin.find('0'):
return True
#判断Ip地址是否合法
def ip_address(ip_address):
i = 0
for ip in ip_address:
if int(ip)>-1 and int(ip) < 256:
i += 1
if i == 4:
return True
#生成2进制IP地址列表
def ip_bin(ip):
IP_bin = [str(bin(int(i))[2::]).rjust(8,'0') for i in ip]
return IP_bin
def check_ip_ip(mask,ip1,ip2): #判断IP1 和IP2 是在同一个网段
coun = 0
for i in range(0,4):
if int(ip1[i]) & int(mask[i]) == int(ip2[i]) & int(mask[i]):
coun += 1
if coun == 4:
return True
else:
return False
while True:
try:
ip_mask = input().split('.')
ip1_address = input().split('.')
ip2_address = input().split('.')
if mask(ip_mask) and ip_address(ip_mask):
if ip_address(ip1_address) and ip_address(ip2_address):
if check_ip_ip(ip_mask,ip1_address,ip2_address):
print("0")
else:
print("2")
else:
print('1')
else:
print('1')
except:
break```
HJ40
描述
输入一行字符,分别统计出包含英文字母、空格、数字和其它字符的个数。
数据范围:输入的字符串长度满足 1 le n le 1000 1≤n≤1000
输入描述:
输入一行字符串,可以有空格
输出描述:
统计其中英文字符,空格字符,数字字符,其他字符的个数
示例1
输入:
1qazxsw23 edcvfr45tgbn hy67uj m,ki89ol./;p0-=][
复制
输出:
26
3
10
12
在这里插入代码片
while True:
try:
ss = input()
w = 0 #英文字符 string.isalpha()
q = 0 #空格字符 string.isspace()
n = 0 #数字字符 string.isdecimal() string.isdigit() string.isnumeric()
s = 0 #其它字符
for i in ss:
if i.isalpha():
w += 1
elif i.isspace():
q += 1
elif i.isnumeric():
n += 1
else:
s += 1
print(w)
print(q)
print(n)
print(s)
except:
break
HJ41
描述
现有n种砝码,重量互不相等,分别为 m1,m2,m3…mn ;
每种砝码对应的数量为 x1,x2,x3…xn 。现在要用这些砝码去称物体的重量(放在同一侧),问能称出多少种不同的重量。
注:
称重重量包括 0
数据范围:每组输入数据满足 1 le n le 10 1≤n≤10 , 1 le m_i le 2000 1≤m
i
≤2000 , 1 le x_i le 10 1≤x
i
≤10
输入描述:
对于每组测试数据:
第一行:n — 砝码的种数(范围[1,10])
第二行:m1 m2 m3 … mn — 每种砝码的重量(范围[1,2000])
第三行:x1 x2 x3 … xn — 每种砝码对应的数量(范围[1,10])
输出描述:
利用给定的砝码可以称出的不同的重量数
示例1
输入:
2
1 2
2 1
复制
输出:
5
复制
说明:
可以表示出0,1,2,3,4五种重量。
说明:
目标是根据给定砝码,得出多少种求和结果?
分析:
1/ 求出可以得到 每种砝码的求和结果
for a in range(kind):
for i in range(number[a]):
list_kind.append(weight[a])
2/ 不同砝码的之间的求和结果,并且要去重
for q in list_kind:
for ww in list(set_weight):
set_weight.add(int(q) + ww)
while True:
try:
#砝码种类
kind = int(input())
#砝码重量
weight = (input()).strip().split(' ')
#砝码数量
number = [int(a) for a in (input()).strip().split(' ')]
# print(kind,weight,number)
list_kind = []
set_weight = {0, }
for a in range(kind):
for i in range(number[a]):
list_kind.append(weight[a])
# print(list_kind)
for q in list_kind:
for ww in list(set_weight):
set_weight.add(int(q) + ww)
print(len(set_weight))
except:
break
HJ42 学英语
描述
Jessi初学英语,为了快速读出一串数字,编写程序将数字转换成英文:
具体规则如下:
1.在英语读法中三位数字看成一整体,后面再加一个计数单位。从最右边往左数,三位一单位,例如12,345 等
2.每三位数后记得带上计数单位 分别是thousand, million, billion.
3.公式:百万以下千以上的数 X thousand X, 10亿以下百万以上的数:X million X thousand X, 10 亿以上的数:X billion X million X thousand X. 每个X分别代表三位数或两位数或一位数。
4.在英式英语中百位数和十位数之间要加and,美式英语中则会省略,我们这个题目采用加上and,百分位为零的话,这道题目我们省略and
下面再看几个数字例句:
22: twenty two
100: one hundred
145: one hundred and forty five
1,234: one thousand two hundred and thirty four
8,088: eight thousand (and) eighty eight (注:这个and可加可不加,这个题目我们选择不加)
486,669: four hundred and eighty six thousand six hundred and sixty nine
1,652,510: one million six hundred and fifty two thousand five hundred and ten
说明:
数字为正整数,不考虑小数,转化结果为英文小写;
保证输入的数据合法
关键字提示:and,billion,million,thousand,hundred。
数据范围:1 le n le 2000000 1≤n≤2000000
输入描述:
输入一个long型整数
输出描述:
输出相应的英文写法
示例1
输入:
22
复制
输出:
twenty two
解体思路:
1/ 发现规律:
111 127 190 567 =111billion 127 million 190 thousand 567
one hundred and eleven billion one hundred and twenty seven million one hundred and ninety thousand five hundred and sixty seven
2/转换位列表:
[‘567’,‘190’,‘127’,‘111’]
3/ 用字典表示 1-10 20 30 40 50 60 70 80 90 一一对应这部分没有规律;
4/ 人一个小于 1000的数字转为英文三位数函数构造:
分下面三种
1-19
20-99
100-999
5/按照 大于小于1000 小于1 000 000 小于1 000 000 000 小于1 000 000 000 000分类加
billion,million,thousand
import math
def split_text3(text, length):
text_list = []
group_num = len(text) / int(length)
group_num = math.ceil(group_num) # 向上取整
for i in range(group_num):
tmp = text[::-1][i * int(length):i * int(length) + int(length)][::-1]
text_list.append(tmp.rjust(3,'0'))
return text_list
NUMBER_CONSTANT = {0:"zero ", 1:"one", 2:"two", 3:"three", 4:"four", 5:"five", 6:"six", 7:"seven",8:"eight", 9:"nine", 10:"ten", 11:"eleven", 12:"twelve", 13:"thirteen",14:"fourteen", 15:"fifteen", 16:"sixteen", 17:"seventeen", 18:"eighteen", 19:"nineteen" }
IN_HUNDRED_CONSTANT = {2:"twenty", 3:"thirty", 4:"forty", 5:"fifty", 6:"sixty", 7:"seventy", 8:"eighty", 9:"ninety"}
def thou(num):
nums = num
s = ""
a = 0
b = 0
if int(num)>99 :
a = int(num)//100
s += NUMBER_CONSTANT[a]+" hundred"
num = int(num)-a*100
if int(num)>19 and int(num) <100:
if a > 0:
s += " and "
b= int(num)//10
s += IN_HUNDRED_CONSTANT[b]
num = int(num)-b*10
if int(num)>0 and int(num)<20:
if int(nums[0]) >0 or int(nums[1]) >0:
s += " "
if a >0:
if "and" not in s:
s += "and "
s += NUMBER_CONSTANT[int(num)]
if int(num)<1:
return s
return s
while True:
try:
ss = input()
m = ""
temp = split_text3(ss, 3)
if len(temp) == 1:
m += thou(temp[0])
if len(temp) == 2:
m += thou(temp[1]) + " thousand " + thou(temp[0])
if len(temp) == 3:
m += thou(temp[2]) + " million " + thou(temp[1]) + " thousand " + thou(temp[0])
if len(temp) == 4:
m += thou(temp[3]) + " billion " + thou(temp[2]) + " million " + thou(temp[1]) + " thousand " + thou(
temp[0])
m.strip()
print(m)
except:
break
HJ45 名字的漂亮度
描述
给出一个字符串,该字符串仅由小写字母组成,定义这个字符串的“漂亮度”是其所有字母“漂亮度”的总和。
每个字母都有一个“漂亮度”,范围在1到26之间。没有任何两个不同字母拥有相同的“漂亮度”。字母忽略大小写。
给出多个字符串,计算每个字符串最大可能的“漂亮度”。
本题含有多组数据。
数据范围:输入的名字长度满足 1 le n le 10000 1≤n≤10000
输入描述:
第一行一个整数N,接下来N行每行一个字符串
输出描述:
每个字符串可能的最大漂亮程度
示例1
输入:
2
zhangsan
lisi
输出:
192
101
说明:
对于样例lisi,让i的漂亮度为26,l的漂亮度为25,s的漂亮度为24,lisi的漂亮度为25+26+24+26=101.
题目解析:
字符串的票亮度最高,就是出现次数最多的字符的漂亮度为最大 26 出现次数次多的是25 依次减小。然后相加每个字母的漂亮度之和就是字符串的漂亮度。
def piao(str):
dic = {}
for i in str:
if i not in list(dic.keys()):
dic[i] = 1
else:
dic[i] += 1
dics = sorted(dic.items(),key=lambda x :x[1],reverse=True)
return dics
def zhi(str):
dics = piao(str)
n = 0
num = [ i for i in range(26,0,-1)]
for i in range(len(dics)):
n += num[i]*dics[i][1]
return n
while True:
try:
number = int(input())
for i in range(number):
print(zhi(input()))
except:
break
HJ66 配置文件恢复
描述
有6条配置命令,它们执行的结果分别是:
命 令 执 行
reset reset what
reset board board fault
board add where to add
board delete no board at all
reboot backplane impossible
backplane abort install first
he he unknown command
注意:he he不是命令。
为了简化输入,方便用户,以“最短唯一匹配原则”匹配(注:需从首字母开始进行匹配):
1、若只输入一字串,则只匹配一个关键字的命令行。例如输入:r,根据该规则,匹配命令reset,执行结果为:reset what;输入:res,根据该规则,匹配命令reset,执行结果为:reset what;
2、若只输入一字串,但匹配命令有两个关键字,则匹配失败。例如输入:reb,可以找到命令reboot backpalne,但是该命令有两个关键词,所有匹配失败,执行结果为:unknown command
3、若输入两字串,则先匹配第一关键字,如果有匹配,继续匹配第二关键字,如果仍不唯一,匹配失败。
例如输入:r b,找到匹配命令reset board 和 reboot backplane,执行结果为:unknown command。
例如输入:b a,无法确定是命令board add还是backplane abort,匹配失败。
4、若输入两字串,则先匹配第一关键字,如果有匹配,继续匹配第二关键字,如果唯一,匹配成功。例如输入:bo a,确定是命令board add,匹配成功。
5、若输入两字串,第一关键字匹配成功,则匹配第二关键字,若无匹配,失败。例如输入:b addr,无法匹配到相应的命令,所以执行结果为:unknow command。
6、若匹配失败,打印“unknown command”
注意:有多组输入。
数据范围:数据组数:1le tle 8001≤t≤800 ,字符串长度1le sle 201≤s≤20
进阶:时间复杂度:O(n)O(n) ,空间复杂度:O(n)O(n)
输入描述:
多行字符串,每行字符串一条命令
输出描述:
执行结果,每条命令输出一行
示例1
输入:
reset
reset board
board add
board delet
reboot backplane
backplane abort
复制
输出:
reset what
board fault
where to add
no board at all
impossible
install first
while True:
try:
ss = input()
dick_oreder = {
"reset": "reset what",
"reset board": "board fault",
"board add": "where to add",
"board delete": "no board at all",
"reboot backplane": "impossible",
"backplane abort": "install first",
"he he": "unknown command",
}
LIST_ORDER = [
"reset",
"reset board",
"board add",
"board delete",
"reboot backplane",
"backplane abort",
"he he",
]
ff = "he he"
i = 0
if len(ss.split(" ")) == 1:
for order in LIST_ORDER:
l = order.split(" ")
if len(l) == 1 and (ss in l[0][0:len(ss)]):
i += 1
ff = order
if i > 1:
print(dick_oreder["he he"])
else:
print(dick_oreder[ff])
elif len(ss.split(" ")) > 1:
ss1 = ss.split(" ")[0]
ss2 = ss.split(" ")[1]
for order in LIST_ORDER:
l = order.split(" ")
if (
len(l) > 1
and (ss1 in l[0][0 : len(ss1)])
and (ss2 in l[1][0 : len(ss2)])
):
i += 1
ff = order
if i > 1:
print(dick_oreder["he he"])
else:
print(dick_oreder[ff])
else:
print(dick_oreder[ff])
except:
break
HJ83 二维数组操作


示例1
输入:
4 9
5 1 2 6
0
8
2 3
4 7
4 2 3 2
3
3
4 7
复制
输出:
0
-1
0
-1
0
0
-1
0
0
-1
复制
说明:
本组样例共有2组样例输入。
第一组样例:
1.初始化数据表为4行9列,成功
2.交换第5行1列和第2行6列的数据,失败。因为行的范围应该是(0,3),不存在第5行。
3.在第0行上方添加一行,成功。
4.在第8列左边添加一列,失败。因为列的总数已经达到了9的上限。
5.查询第2行第3列的值,成功。
第二组样例:
1.初始化数据表为4行7列,成功
2.交换第4行2列和第3行2列的数据,失败。因为行的范围应该是(0,3),不存在第4行。
3.在第3行上方添加一行,成功。
4.在第3列左边添加一列,成功。
5.查询第4行7列的值,失败。因为虽然添加了一行一列,但数据表会在添加后恢复成4行7列的形态,所以行的区间仍然在[0,3],列的区间仍然在[0,6],无法查询到(4,7)坐标。
在这里插入代码片
while True:
try:
n,m = map(int, input().split())
if n < 10 and m <10:
print(0)
else:
print(-1)
list_nm = []
for i in range(n):
for j in range(m):
list_nm.append([i,j])
x1,y1,x2,y2 = map(int, input().split())
if ([x1,y1] in list_nm) and ([x2,y2] in list_nm):
print(0)
else:
print(-1)
x = int(input())
if x < n and n < 9:
print(0)
else:
print(-1)
y = int(input())
if y < m and m < 9:
print(0)
else:
print(-1)
q,a = map(int, input().split())
if [q,a] in list_nm:
print(0)
else:
print(-1)
except:
break
HJ84 统计大写字母个数
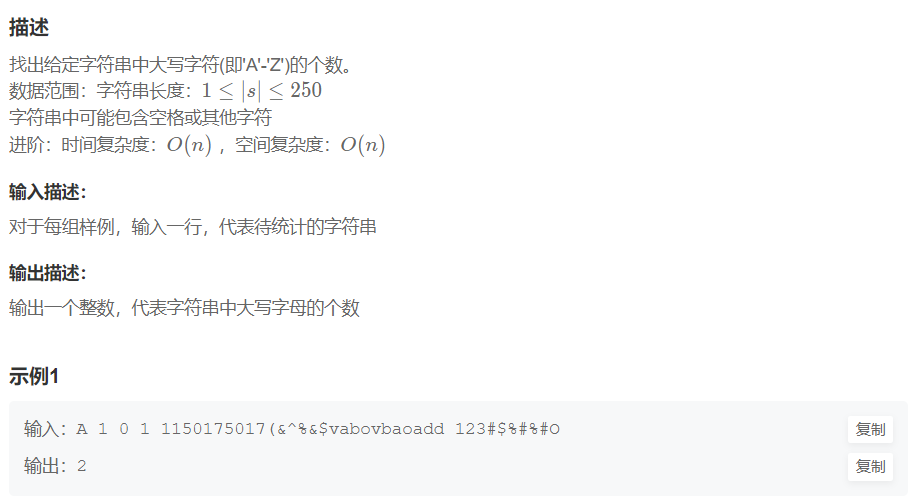
在这里插入代码片
while True:
try:
ss = input()
n = 0
for i in ss:
if i.isupper():
n += 1
print(n)
except:
break
标题HJ85 最长回文子串
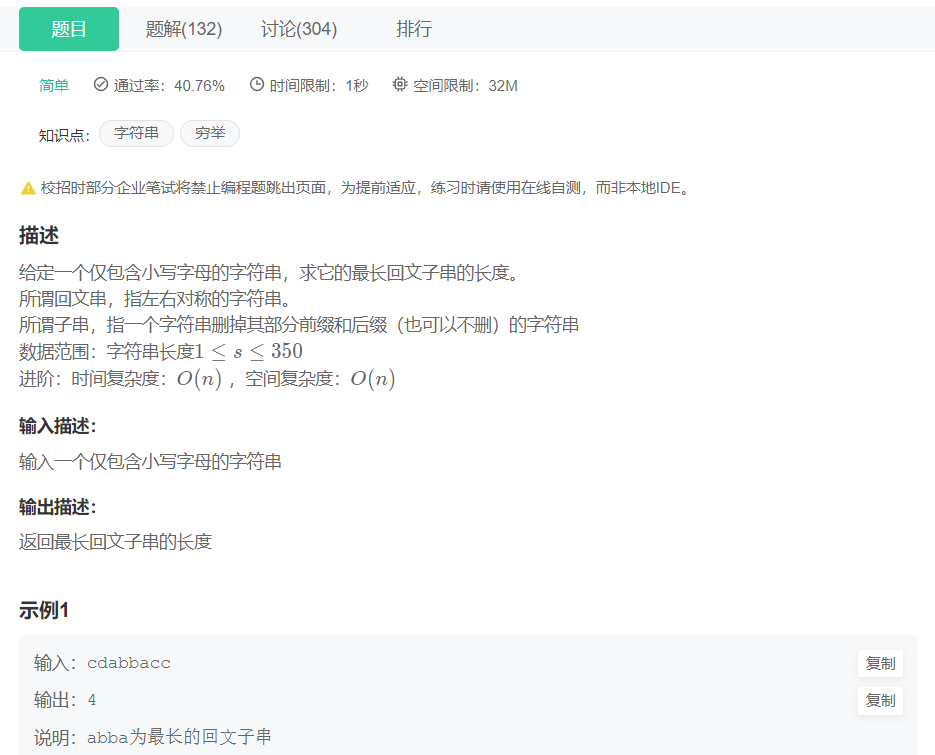
while True:
try:
ss = input()
s = []
for i in range(len(ss)):
for j in range(i+1,len(ss)+1):
if ss[i:j] == ss[i:j][::-1]:
s.append(j-i)
print(max(s))
except:
break
HJ86 求最大连续bit数
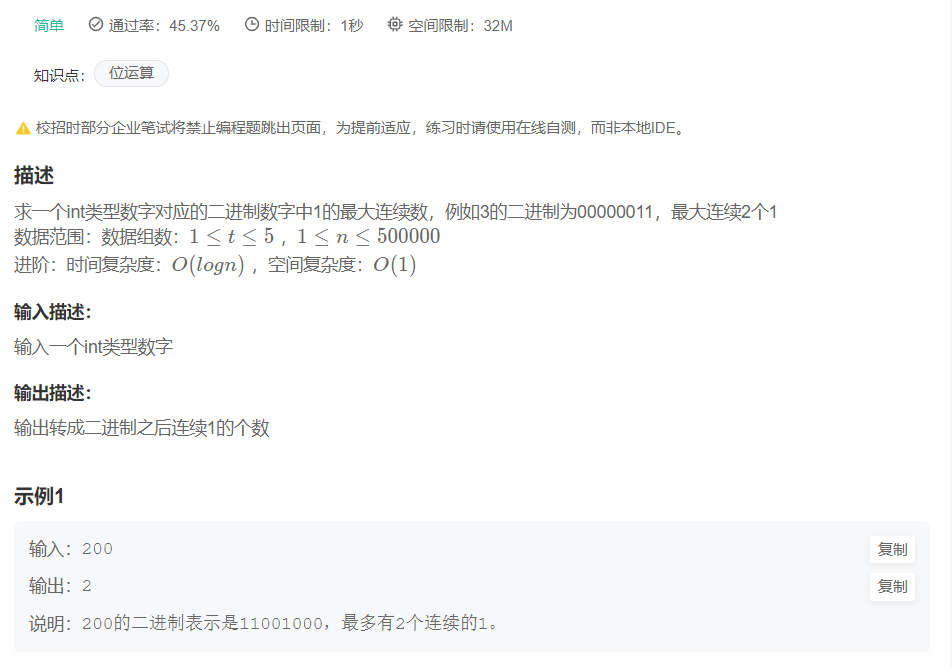
在这里插入代码片
def ss(str):
sn1 = 0
for i in str:
if i == '1':
sn1 += 1
if sn1 == len(str):
return True
while True:
try:
num = int(input())
num_b = bin(num)[2::]
s = 0
for i in range(0,len(num_b)):
for j in range(i+1,len(num_b)+1):
if ss(num_b[i:j]) and len(num_b[i:j]) > s:
s = len(num_b[i:j])
print(s)
except:
break
HJ87 密码强度等级
描述
密码按如下规则进行计分,并根据不同的得分为密码进行安全等级划分。
一、密码长度:
5 分: 小于等于4 个字符
10 分: 5 到7 字符
25 分: 大于等于8 个字符
二、字母:
0 分: 没有字母
10 分: 密码里的字母全都是小(大)写字母
20 分: 密码里的字母符合”大小写混合“
三、数字:
0 分: 没有数字
10 分: 1 个数字
20 分: 大于1 个数字
四、符号:
0 分: 没有符号
10 分: 1 个符号
25 分: 大于1 个符号
五、奖励(只能选符合最多的那一种奖励):
2 分: 字母和数字
3 分: 字母、数字和符号
5 分: 大小写字母、数字和符号
最后的评分标准:
= 90: 非常安全
= 80: 安全(Secure)
= 70: 非常强
= 60: 强(Strong)
= 50: 一般(Average)
= 25: 弱(Weak)
= 0: 非常弱(Very_Weak)
对应输出为:
VERY_SECURE
SECURE
VERY_STRONG
STRONG
AVERAGE
WEAK
VERY_WEAK
请根据输入的密码字符串,进行安全评定。
注:
字母:a-z, A-Z
数字:0-9
符号包含如下: (ASCII码表可以在UltraEdit的菜单view->ASCII Table查看)
!"#$%&’()*+,-./ (ASCII码:0x21~0x2F)
:;<=>?@ (ASCII码:0x3A~0x40)
[]^_` (ASCII码:0x5B~0x60)
{|}~ (ASCII码:0x7B~0x7E)
提示:
1 <= 字符串的长度<= 300
输入描述:
输入一个string的密码
输出描述:
输出密码等级
示例1
输入:
38$@NoNoN
复制
输出:
VERY_SECURE
复制
说明:
样例的密码长度大于等于8个字符,得25分;大小写字母都有所以得20分;有两个数字,所以得20分;包含大于1符号,所以得25分;由于该密码包含大小写字母、数字和符号,所以奖励部分得5分,经统计得该密码的密码强度为25+20+20+25+5=95分。
在这里插入代码片
# 判断字母长度
def lange(ss):
if len(ss) > 7:
return 25
if 4< len(ss) < 8:
return 10
if 5 > len(ss):
return 5
# 是否有字母
def abc(ss):
s1 = False
s2 = False
for i in ss:
if i.isupper():
s1 = True
if i.islower():
s2 = True
if s1 == True and s2 == True:
return 20
elif s1 == True and s2 == False:
return 10
elif s1 == False and s2 == True:
return 10
elif s1 == False and s2 == True:
return 0
# 判断数字
def number(ss):
s = 0
for i in ss:
if i.isnumeric():
s += 1
if s == 1:
return 10
elif s > 1:
return 20
else:
return 0
# 判断字符
def symbol(ss):
s = 0
for i in ss:
if not i.isalnum():
s += 1
if s == 1:
return 10
elif s > 1:
return 25
else:
return 0
def aaaa(ss):
l = [0]
if abc(ss) != 0 and number(ss) != 0:
l.append(2)
if abc(ss) != 0 and number(ss) != 0 and symbol(ss) != 0 :
l.append(3)
if abc(ss) == 20 and number(ss) != 0 and symbol(ss) != 0 :
l.append(5)
return max(l)
while True:
try:
ss = input()
sum = lange(ss) + abc(ss) + number(ss) + symbol(ss) + aaaa(ss)
if sum > 89 :
print("VERY_SECURE")
if 79 < sum < 90:
print("SECURE")
if 69 < sum < 80:
print("VERY_STRONG")
if 59 < sum < 70:
print("STRONG")
if 49 < sum < 60:
print("AVERAGE")
if 24 < sum < 50:
print("WEAK")
if -1 < sum < 25:
print("VERY_WEAK")
except:
break
HJ92 在字符串中找出连续最长的数字串
描述
输入一个字符串,返回其最长的数字子串,以及其长度。若有多个最长的数字子串,则将它们全部输出(按原字符串的相对位置)
本题含有多组样例输入。
数据范围:字符串长度 1 le n le 200 1≤n≤200 , 保证每组输入都至少含有一个数字
输入描述:
输入一个字符串。1<=len(字符串)<=200
输出描述:
输出字符串中最长的数字字符串和它的长度,中间用逗号间隔。如果有相同长度的串,则要一块儿输出(中间不要输出空格)。
示例1
输入:
abcd12345ed125ss123058789
a8a72a6a5yy98y65ee1r2
复制
输出:
123058789,9
729865,2
复制
说明:
样例一最长的数字子串为123058789,长度为9
样例二最长的数字子串有72,98,65,长度都为2
while True:
try:
ss = input()
l = 0
ll = []
for i in range(len(ss)):
for j in range(i+1,len(ss)+1):
if ss[i:j].isnumeric() and len(ss[i:j]) >= l:
l = len(ss[i:j])
ll.append(ss[i:j])
kk = []
for i in ll:
if len(i) == l:
kk.append(i)
print("{},{}".format(''.join(kk),l))
except:
break
HJ94 记票统计
描述
请实现一个计票统计系统。你会收到很多投票,其中有合法的也有不合法的,请统计每个候选人得票的数量以及不合法的票数。
(注:不合法的投票指的是投票的名字不存在n个候选人的名字中!!)
数据范围:每组输入中候选人数量满足 1 le n le 100 1≤n≤100 ,总票数量满足 1 le n le 100 1≤n≤100
输入描述:
第一行输入候选人的人数n,第二行输入n个候选人的名字(均为大写字母的字符串),第三行输入投票人的人数,第四行输入投票。
输出描述:
按照输入的顺序,每行输出候选人的名字和得票数量(以" : "隔开,注:英文冒号左右两边都有一个空格!),最后一行输出不合法的票数,格式为"Invalid : "+不合法的票数。
示例1
输入:
4
A B C D
8
A D E CF A GG A B
复制
输出:
A : 3
B : 1
C : 0
D : 1
Invalid : 3
复制
说明:
E CF GG三张票是无效的,所以Invalid的数量是3.
while True:
try:
num = int(input())
name = input().split()
name += ['Invalid']
number = []
for i in range(num+1):
number.append(0)
piao_num = int(input())
dick_number = dict(zip(name,number))
piao = input().split()
for p in piao:
if p in name:
dick_number[p] += 1
else:
dick_number['Invalid'] += 1
for k,v in dick_number.items():
print("{} : {}".format(k,v))
except:
break
桶排序
在计数排序中,如果元素的范围比较大(比如在1到1亿之间),如何改造算法
桶排序:Bucket Sort 首先将元素分在不同的桶中,在对每个桶中的元素进行paix。
桶排序的思想也非常简单,将元素分到几个不同的桶中,再对每个桶中的元素进行排序。结果一次输出就是有序的了。简单示意图可以参考下面图片:

原理介绍结合具体数:
有100万个数,需要100个桶,每个桶中存放1万个数,桶中存放固定区间的数值,并按照顺序排列,最后将100个桶按照顺序拼接为一个新的列表就完成了排序;
在这里插入代码片
#!/usr/bin/env python
# encoding: utf-8
def bucket_sort(li,n=100,max_num = 10000): # 分成100个桶 ,max_num数据的最大值
# 不知道最大数,定义一个最大数
bucketa = [[] for _ in range(n)] #创建桶
for var in li:
#决定这个数var 放到那个桶里,
i = min(var // (max_num // n),n-1)
#max_num// n 始终是100,var是小于100肯定在0号桶,8000肯定在80号桶,是800肯定在8号桶这个一个数据计算方法
bucketa[i].append(var) #把var天机到桶里
for j in range(len(bucketa[i])-1,0,-1): #这一步可以改造
if bucketa[i][j] < bucketa[i][j-1]:
bucketa[i][j] ,bucketa[i][j-1] = bucketa[i][j-1],bucketa[i][j]
else:
break
sorted_li = []
for buc in bucketa:
sorted_li.extend(buc)
return sorted_li
# 保持桶内顺序
import random
li = [random.randint(0,10000) for i in range(100000)]
print(li)
li = bucket_sort(li)
print(li)
基数排序:
多关键字排序 公司员工按照 工资 年龄:
多关键字排序:加入现有一个员工表:要求按照薪资进行排序,年龄相同的员工在按照薪资进行稳定的排序。

最后
以上就是动人洋葱最近收集整理的关于【python算法练习】常用查询方法题目桶排序基数排序:的全部内容,更多相关【python算法练习】常用查询方法题目桶排序基数排序内容请搜索靠谱客的其他文章。

![【C语言】从键盘上输入5个字符串,char str[5][20] 按照字符串的长度将字符串按从小到大的顺序排序](https://www.shuijiaxian.com/files_image/reation/bcimg15.png)






发表评论 取消回复