今天在使用Hive查询某分析数据最大值的时候,出现了一定的问题,hive中现象如下:
Caused by: java.io.FileNotFoundException://http://slave1:50060/tasklog?attemptid=attempt_201501050454_0006_m_00001_1
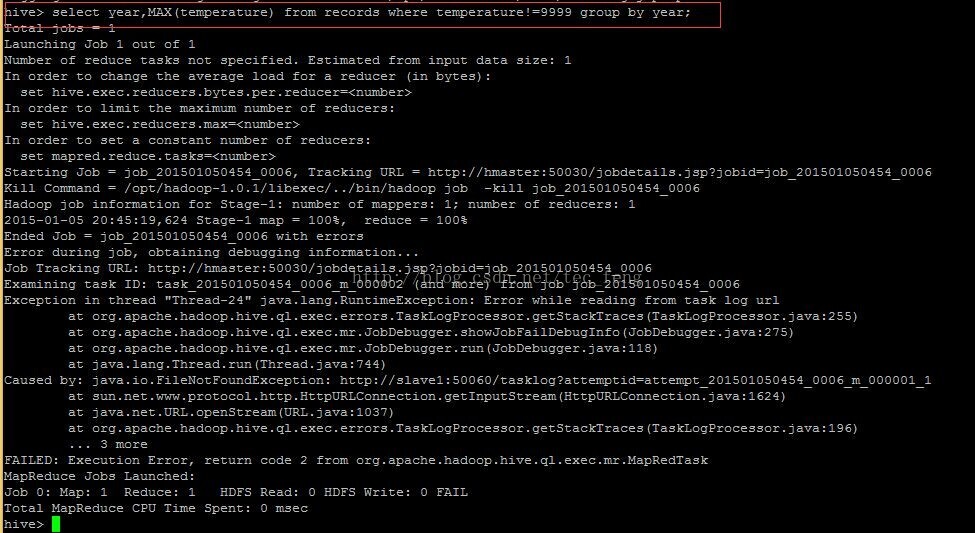
然后查看一下jobtracker的日志:
2015-01-05 21:43:23,724 INFO org.apache.hadoop.mapred.JobInProgress: job_201501052137_0004: nMaps=1 nReduces=1 max=-1
2015-01-05 21:43:23,724 INFO org.apache.hadoop.mapred.JobTracker: Job job_201501052137_0004 added successfully for user 'hadoop' to queue 'default'
2015-01-05 21:43:23,724 INFO org.apache.hadoop.mapred.AuditLogger: USER=hadoop IP=192.168.1.193 OPERATION=SUBMIT_JOB TARGET=job_201501052137_0004 RESULT=SUCCESS
2015-01-05 21:43:23,732 INFO org.apache.hadoop.mapred.JobTracker: Initializing job_201501052137_0004
2015-01-05 21:43:23,732 INFO org.apache.hadoop.mapred.JobInProgress: Initializing job_201501052137_0004
2015-01-05 21:43:23,817 INFO org.apache.hadoop.mapred.JobInProgress: jobToken generated and stored with users keys in /opt/hadoop-1.0.1/tmp/mapred/system/job_201501052137_0004/jobToken
2015-01-05 21:43:23,822 INFO org.apache.hadoop.mapred.JobInProgress: Input size for job job_201501052137_0004 = 41. Number of splits = 1
2015-01-05 21:43:23,822 INFO org.apache.hadoop.mapred.JobInProgress: tip:task_201501052137_0004_m_000000 has split on node:/default-rack/slave1
2015-01-05 21:43:23,822 INFO org.apache.hadoop.mapred.JobInProgress: job_201501052137_0004 LOCALITY_WAIT_FACTOR=0.5
2015-01-05 21:43:23,822 INFO org.apache.hadoop.mapred.JobInProgress: Job job_201501052137_0004 initialized successfully with 1 map tasks and 1 reduce tasks.
2015-01-05 21:43:26,140 INFO org.apache.hadoop.mapred.JobTracker: Adding task (JOB_SETUP) 'attempt_201501052137_0004_m_000002_0' to tip task_201501052137_0004_m_000002, for tracker 'tracker_slave2:127.0.0.1/127.0.0.1:380
2015-01-05 21:43:29,144 INFO org.apache.hadoop.mapred.TaskInProgress: Error from attempt_201501052137_0004_m_000002_0: Error initializing attempt_201501052137_0004_m_000002_0:
java.io.IOException: Exception reading file:/opt/hadoop-1.0.1/tmp/mapred/local/ttprivate/taskTracker/hadoop/jobcache/job_201501052137_0004/jobToken
at org.apache.hadoop.security.Credentials.readTokenStorageFile(Credentials.java:135)
at org.apache.hadoop.mapreduce.security.TokenCache.loadTokens(TokenCache.java:165)
at org.apache.hadoop.mapred.TaskTracker.initializeJob(TaskTracker.java:1179)
at org.apache.hadoop.mapred.TaskTracker.localizeJob(TaskTracker.java:1116)
at org.apache.hadoop.mapred.TaskTracker$5.run(TaskTracker.java:2404)
at java.lang.Thread.run(Thread.java:744)
Caused by: java.io.FileNotFoundException: File file:/opt/hadoop-1.0.1/tmp/mapred/local/ttprivate/taskTracker/hadoop/jobcache/job_201501052137_0004/jobToken does not exist.
at org.apache.hadoop.fs.RawLocalFileSystem.getFileStatus(RawLocalFileSystem.java:397)
at org.apache.hadoop.fs.FilterFileSystem.getFileStatus(FilterFileSystem.java:251)
at org.apache.hadoop.fs.ChecksumFileSystem$ChecksumFSInputChecker.<init>(ChecksumFileSystem.java:125)
at org.apache.hadoop.fs.ChecksumFileSystem.open(ChecksumFileSystem.java:283)
at org.apache.hadoop.fs.FileSystem.open(FileSystem.java:427)
at org.apache.hadoop.security.Credentials.readTokenStorageFile(Credentials.java:129)
... 5 more
2015-01-05 21:43:29,144 ERROR org.apache.hadoop.mapred.TaskStatus: Trying to set finish time for task attempt_201501052137_0004_m_000002_0 when no start time is set, stackTrace is : java.lang.Exception
at org.apache.hadoop.mapred.TaskStatus.setFinishTime(TaskStatus.java:145)
at org.apache.hadoop.mapred.TaskInProgress.incompleteSubTask(TaskInProgress.java:670)
at org.apache.hadoop.mapred.JobInProgress.failedTask(JobInProgress.java:2942)
at org.apache.hadoop.mapred.JobInProgress.updateTaskStatus(JobInProgress.java:1159)
at org.apache.hadoop.mapred.JobTracker.updateTaskStatuses(JobTracker.java:4739)
at org.apache.hadoop.mapred.JobTracker.processHeartbeat(JobTracker.java:3683)
at org.apache.hadoop.mapred.JobTracker.heartbeat(JobTracker.java:3378)
at sun.reflect.GeneratedMethodAccessor3.invoke(Unknown Source)
at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43)
at java.lang.reflect.Method.invoke(Method.java:606)
at org.apache.hadoop.ipc.RPC$Server.call(RPC.java:563)
at org.apache.hadoop.ipc.Server$Handler$1.run(Server.java:1388)
at org.apache.hadoop.ipc.Server$Handler$1.run(Server.java:1384)
at java.security.AccessController.doPrivileged(Native Method)
at javax.security.auth.Subject.doAs(Subject.java:415)
at org.apache.hadoop.security.UserGroupInformation.doAs(UserGroupInformation.java:1093)
at org.apache.hadoop.ipc.Server$Handler.run(Server.java:1382)
2015-01-05 21:43:29,146 INFO org.apache.hadoop.mapred.JobTracker: Adding task (JOB_SETUP) 'attempt_201501052137_0004_r_000002_0' to tip task_201501052137_0004_r_000002, for tracker 'tracker_slave2:127.0.0.1/127.0.0.1:380
2015-01-05 21:43:29,146 INFO org.apache.hadoop.mapred.JobTracker: Removing task 'attempt_201501052137_0004_m_000002_0'
2015-01-05 21:43:32,154 INFO org.apache.hadoop.mapred.TaskInProgress: Error from attempt_201501052137_0004_r_000002_0: Error initializing attempt_201501052137_0004_r_000002_0:
java.io.IOException: Exception reading file:/opt/hadoop-1.0.1/tmp/mapred/local/ttprivate/taskTracker/hadoop/jobcache/job_201501052137_0004/jobToken
at org.apache.hadoop.security.Credentials.readTokenStorageFile(Credentials.java:135)
at org.apache.hadoop.mapreduce.security.TokenCache.loadTokens(TokenCache.java:165)
at org.apache.hadoop.mapred.TaskTracker.initializeJob(TaskTracker.java:1179)
at org.apache.hadoop.mapred.TaskTracker.localizeJob(TaskTracker.java:1116)
at org.apache.hadoop.mapred.TaskTracker$5.run(TaskTracker.java:2404)
at java.lang.Thread.run(Thread.java:744)
Caused by: java.io.FileNotFoundException: File file:/opt/hadoop-1.0.1/tmp/mapred/local/ttprivate/taskTracker/hadoop/jobcache/job_201501052137_0004/jobToken does not exist.
at org.apache.hadoop.fs.RawLocalFileSystem.getFileStatus(RawLocalFileSystem.java:397)
at org.apache.hadoop.fs.FilterFileSystem.getFileStatus(FilterFileSystem.java:251)
at org.apache.hadoop.fs.ChecksumFileSystem$ChecksumFSInputChecker.<init>(ChecksumFileSystem.java:125)
查看以前临时文件目录 , 查看core-site.xml里面:
hadoop.tmp.dir 在/opt/hadoop-1.0.1/tmp/下面,该文件被赋予hadoop的拥有者和750的权限,但是可能存在一些问题。
将该文件做一下修改:
hadoop.tmp.dir 为/home/hadoop/temp
重新格式化hdfs,并重启,使用hive查询,该问题消失
将该文件做一下修改:
hadoop.tmp.dir 为/home/hadoop/temp
重新格式化hdfs,并重启,使用hive查询,该问题消失
最后
以上就是迅速水池最近收集整理的关于Hadoop集群中使用Hive查询报错的全部内容,更多相关Hadoop集群中使用Hive查询报错内容请搜索靠谱客的其他文章。
本图文内容来源于网友提供,作为学习参考使用,或来自网络收集整理,版权属于原作者所有。








发表评论 取消回复