我是靠谱客的博主 鳗鱼向日葵,这篇文章主要介绍window使用spark连接HDP-3.1.5.0时报Unrecognized Hadoop major version number: 3.1.1问题,现在分享给大家,希望可以做个参考。
当使用idea使用saprk连接hive时,报以下错误:Unrecognized Hadoop major version number: 3.1.1
pom依赖如下:
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>com.yuwang</groupId>
<artifactId>spark</artifactId>
<version>1.0-SNAPSHOT</version>
<properties>
<spark.version>2.3.2</spark.version>
<mysql.java.connector.version>8.0.22</mysql.java.connector.version>
<hadoop.version>3.1.1</hadoop.version>
<sql.server.version>4.0</sql.server.version>
<gson.version>2.8.6</gson.version>
<phoenix.version>4.16</phoenix.version>
</properties>
<dependencies>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-core_2.11</artifactId>
<version>${spark.version}</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-sql_2.11</artifactId>
<version>${spark.version}</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-hive_2.11</artifactId>
<version>${spark.version}</version>
</dependency>
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>${mysql.java.connector.version}</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
<version>${hadoop.version}</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-hdfs</artifactId>
<version>${hadoop.version}</version>
<exclusions>
<exclusion>
<groupId>com.google.protobuf</groupId>
<artifactId>protobuf-java</artifactId>
</exclusion>
</exclusions>
</dependency>
<dependency>
<groupId>com.google.code.gson</groupId>
<artifactId>gson</artifactId>
<version>${gson.version}</version>
</dependency>
<!-- <dependency>-->
<!-- <groupId>com.microsoft.sqlserver</groupId>-->
<!-- <artifactId>sqljdbc4</artifactId>-->
<!-- <version>${sql.server.version}</version>-->
<!-- </dependency>-->
</dependencies>
<build>
<plugins>
<plugin>
<!-- java -->
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-compiler-plugin</artifactId>
<version>3.8.1</version>
<configuration>
<source>${java.version}</source>
<target>${java.version}</target>
<fork>true</fork>
<compilerVersion>${java.version}</compilerVersion>
</configuration>
</plugin>
<plugin>
<!-- scala -->
<groupId>net.alchim31.maven</groupId>
<artifactId>scala-maven-plugin</artifactId>
<version>4.3.1</version>
<configuration>
<scalaCompatVersion>2.12.11</scalaCompatVersion>
<scalaVersion>2.12.11</scalaVersion>
</configuration>
<executions>
<execution>
<id>scala-compile-first</id>
<phase>process-resources</phase>
<goals>
<goal>add-source</goal>
<goal>compile</goal>
</goals>
</execution>
</executions>
</plugin>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-resources-plugin</artifactId>
<version>3.1.0</version>
</plugin>
<plugin>
<artifactId>maven-compiler-plugin</artifactId>
<version>3.6.1</version>
<configuration>
<source>1.8</source>
<target>1.8</target>
</configuration>
</plugin>
<plugin>
<artifactId>maven-assembly-plugin</artifactId>
<configuration>
<descriptorRefs>
<descriptorRef>jar-with-dependencies</descriptorRef>
</descriptorRefs>
</configuration>
<executions>
<execution>
<id>make-assembly</id>
<phase>package</phase>
<goals>
<goal>single</goal>
</goals>
</execution>
</executions>
</plugin>
</plugins>
</build>
</project>
原因:hdp-3.1.5集成了hadoop3.1和spark2.3,当我idea使用2.3的spark时,不认识3.1的hadoop,查看源码发现:
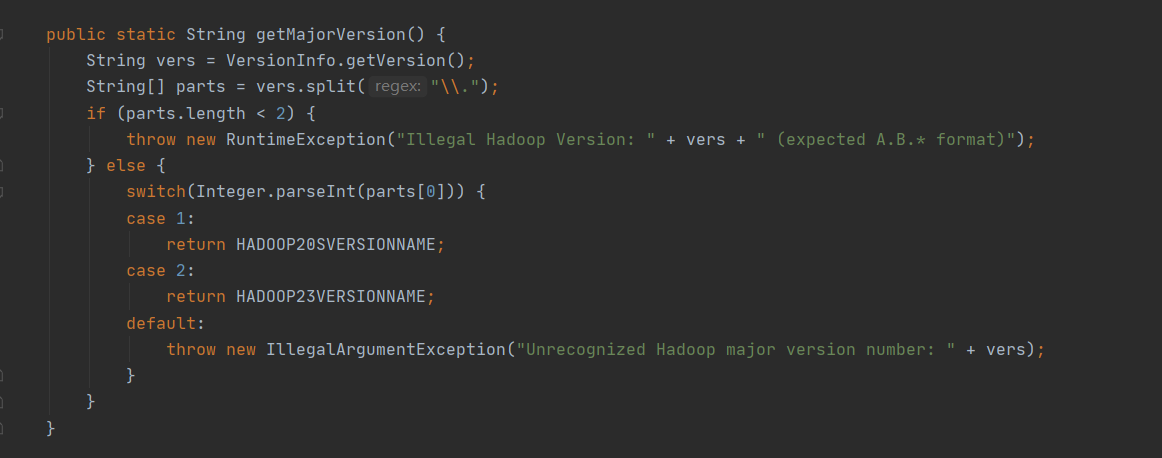
spark2.3的源码里,没有对应hadoop3.x的版本,继续深究源码发现是以common-version-info.properties文件里包含了版本信息
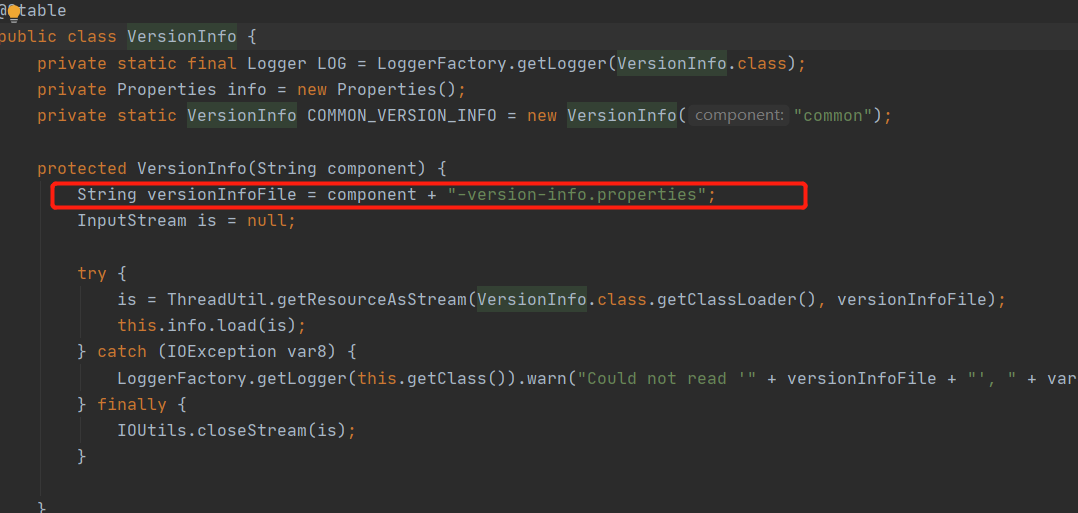
解决办法:
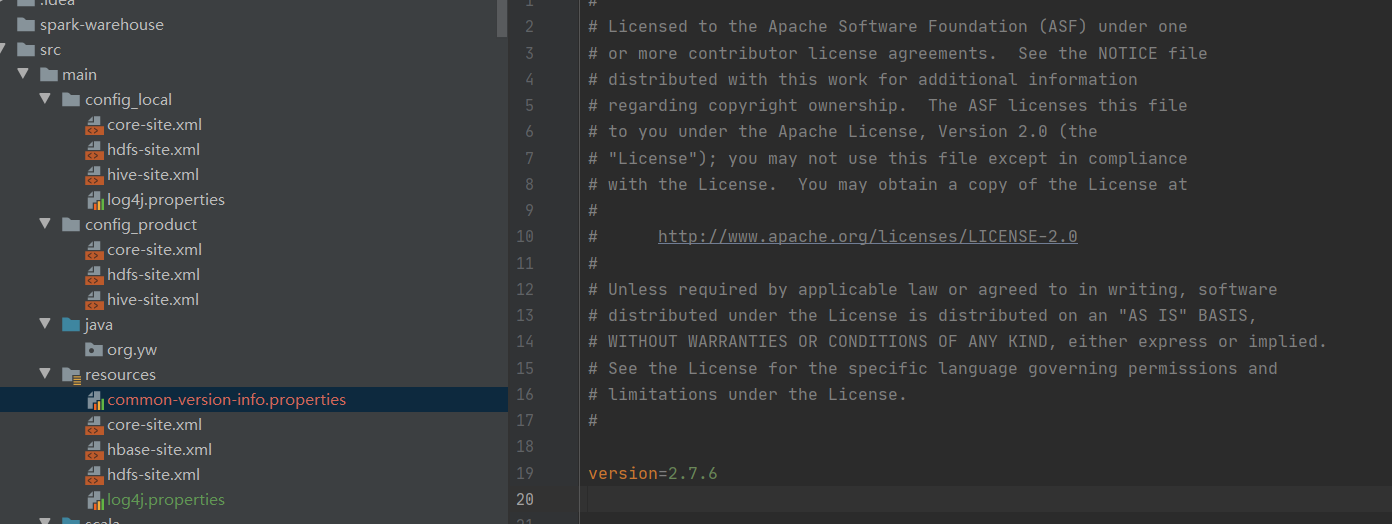
在classpath目录下添加common-version-info.properties文件,内容指定版本
(虽然我Pom依赖里Hadoop是3.x,但是不影响),内容如下:
最后代码spark代码如下:
package org.yw
import java.sql.DriverManager
import java.util.Properties
import org.apache.spark.sql.SparkSession
import org.yw.db.PhoenixDB
object SparkTest {
def main(args: Array[String]): Unit = {
var master = "local"
var sql = "select * from person"
val spark = SparkSession
.builder()
.appName("test hive")
.master(master)
// 指定hive的metastore的端口 默认为9083 在hive-site.xml中查看
.config("hive.metastore.uris", "thrift://bigdata03:9083")
//指定hive的warehouse目录
.config("spark.sql.warehouse.dir", "hdfs://ns//warehouse/tablespace/external/hive")
.enableHiveSupport()
.getOrCreate()
spark.sql(sql).show()
}
}
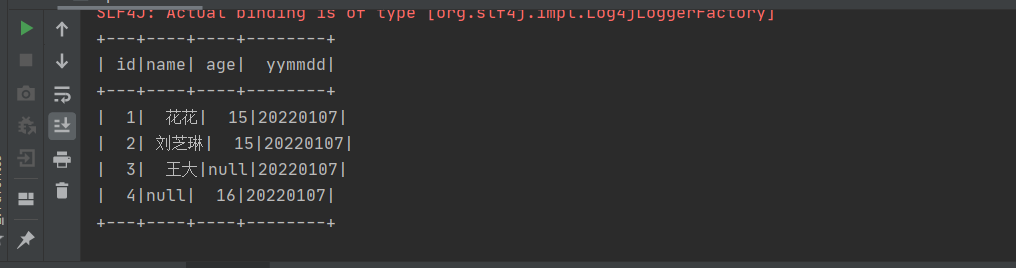
输出如下
最后
以上就是鳗鱼向日葵最近收集整理的关于window使用spark连接HDP-3.1.5.0时报Unrecognized Hadoop major version number: 3.1.1问题的全部内容,更多相关window使用spark连接HDP-3.1.5.0时报Unrecognized内容请搜索靠谱客的其他文章。
本图文内容来源于网友提供,作为学习参考使用,或来自网络收集整理,版权属于原作者所有。








发表评论 取消回复