引用自:http://tech.sina.com.cn/mobile/n/2011-06-20/18371792199.shtml 作者:小熊在线-宁道奇
并行计算:让处理的速度变得更快
相对于串行计算,并行计算可以划分成时间并行和空间并行。时间并行即流水线技术,空间并行使用多个处理器执行并发计算,当前研究的主要是空间的并行问题。以程序和算法设计人员的角度看,并行计算又可分为数据并行和任务并行。数据并行把大的任务化解成若干个相同的子任务,处理起来比任务并行简单。

并行计算,解放不堪重负的处理器
空间上的并行导致两类并行机的产生,按照麦克·弗莱因(Michael Flynn)的说法分为单指令流多数据流(SIMD)和多指令流多数据流(MIMD),而常用的串行机也称为单指令流单数据流(SISD)。MIMD类的机器又可分为常见的五类:并行向量处理机(PVP)、对称多处理机(SMP)、大规模并行处理机(MPP)、工作站机群(COW)、分布式共享存储处理机(DSM)。
从自然哲学层面上来讲:任何最为复杂的事情,都可以被拆分成若干个小问题去解决。这就是当今并行计算的哲学理论依据。然而在当今的双路、四路、八路甚至多路处理器系统中,并行计算的概念早已得到广泛应用。目前业界最为普及的并行计算规范就是OpenMP。

OpenMP:同构计算最为普及的标准

OpenMP(Open Multi-Processing)是由OpenMP Architecture Review Board牵头提出的,并已被广泛接受的,用于共享内存并行系统的多线程程序设计的一套指导性注释(Compiler Directive)。OpenMP支持的编程语言包括C语言、C++和Fortran;而支持OpenMP的编译器包括Sun Studio和Intel Compiler,以及开放源码的GCC和Open64编译器。OpenMP提供了对并行算法的高层的抽象描述,程序员通过在源代码中加入专用的pragma来指明自己的意图,由此编译器可以自动将程序进行并行化,并在必要之处加入同步互斥以及通信。当选择忽略这些pragma,或者编译器不支持OpenMP时,程序又可退化为通常的程序(一般为串行),代码仍然可以正常运作,只是不能利用多线程来加速程序执行。

OpenMP的特色
OpenMP提供的这种对于并行描述的高层抽象降低了并行编程的难度和复杂度,这样程序员可以把更多的精力投入到并行算法本身,而非其具体实现细节。对基于数据分集的多线程程序设计,OpenMP是一个很好的选择。同时,使用OpenMP也提供了更强的灵活性,可以较容易的适应不同的并行系统配置。线程粒度和负载平衡等是传统多线程程序设计中的难题,但在OpenMP中,OpenMP库从程序员手中接管了部分这两方面的工作。
OpenMP的缺点
作为高层抽象,OpenMP并不适合需要复杂的线程间同步和互斥的场合。OpenMP的另一个缺点是不能在非共享内存系统(如计算机集群)上使用。由此如果我们想将不同类型的计算器、计算机联和起来,协同工作。我们就需要使用异构计算技术。
双剑岂可合璧:什么是异构计算?
异构计算(Heterogeneous computing)主要是指使用不同类型指令集和体系架构的计算单元组成系统的计算方式。常见的计算单元类别包括CPU、GPU等协处理器、DSP、ASIC、FPGA等。
异构计算近年来得到更多关注,主要是因为通过提升CPU时钟频率和内核数量而提高计算能力的传统方式遇到了散热和能耗瓶颈。而与此同时,GPU等专用计算单元虽然工作频率较低,具有更多的内核数和并行计算能力,总体性能-芯片面积比和性能-功耗比都很高,却远远没有得到充分利用。
广义上,不同计算平台的各个层次上都存在异构现象,除硬件层的指令集、互联方式、内存层次之外,软件层中应用二进制接口、API、语言特性底层实现等的不同,对于上层应用和服务而言,都是异构的。
从实现的角度来说,异构计算就是制定出一系列的软件与硬件的标准,让不同类型的计算设备能够共享计算的过程和结果。同时不断优化和加速计算的过程,使其具备更高的计算效能。
计算的发展历程:从32bit到异构计算(上)
2003年以前,是32bit的时代。处理器制造厂商,不断提升制造工艺技术,使用更精细的制程来制造处理器。同时也不断提高处理器的时脉,如133MHz、166MHz、200MHz、300MHz……最终频率提升到了3GHz后,就难作寸进了。到目前为止我们也未曾见到Intel和AMD发布高于4GHz主频的处理器产品。
2003年出现了x86-64,有时会简称为“x64”,是64位微处理器架构及其相应指令集的一种,也是Intel x86架构的延伸产品。“x86-64”1999由AMD设计,AMD首次公开64位集以扩充给IA-32,称为x86-64(后来改名为AMD64)。其后也为英特尔所采用,现时英特尔称之为“Intel 64”,在之前曾使用过Clackamas Technology (CT)、IA-32e及EM64T。外界多使用"x86-64"或"x64"去称呼此64位架构,从而保持中立,不偏袒任何厂商。
AMD64代表AMD放弃了跟随Intel标准的一贯作风,选择了像把16位的Intel 8086扩充成32位的80386般,去把x86架构扩充成64位版本,且兼容原有标准。
AMD64架构在IA-32上新增了64位暂存器,并兼容早期的16位和32位软件,可使现有以x86为对象的编译器容易转为AMD64版本。除此之外,NX bit也是引人注目的特色之一。
不少人认为,像DEC Alpha般的64位RISC芯片,最终会取代现有过时及多变的x86架构。但事实上,为x86系统而设的应用软件实在太庞大,成为Alpha不能取代x86的主要原因,AMD64能有效地把x86架构移至64位的环境,并且能兼容原有的x86应用程序。

计算的发展历程:从32bit到异构计算(下)
2006年出现了双核心多核心。多核心,也叫多微处理器核心是将两个或更多的独立处理器封装在一起的方案,通常在一个集成电路(IC)中。双核心设备只有两个独立的微处理器。一般说来,多核心微处理器允许一个计算设备在不需要将多核心包括在独立物理封装时执行某些形式的线程级并发处理(Thread-Level Parallelism,TLP)这种形式的TLP通常被认为是芯片级多处理。在游戏中你必须要使用驱动程序来利用第二颗核心。
此后处理器制造厂商发现,利用多核心架构可以在不提升处理器频率的情况下,继续不断提升处理器的效能。
2008年通用计算GPGPU
通用图形处理器(General-purpose computing on graphics processing units,简称GPGPU),是一种利用处理图形任务的图形处理器来计算原本由中央处理器处理的通用计算任务。这些通用计算常常与图形处理没有任何关系。由于现代图形处理器强大的并行处理能力和可编程流水线,令流处理器可以处理非图形数据。特别在面对单指令流多数据流(SIMD),且数据处理的运算量远大于数据调度和传输的需要时,通用图形处理器在性能上大大超越了传统的中央处理器应用程序。
3D显示卡的性能从NVIDIA的GeForce256时代就颇受瞩目,时间到了2008年,显示卡的计算能力开始被用在实际的计算当中。并且其处理的速度也远远超越了传统的x86处理器。
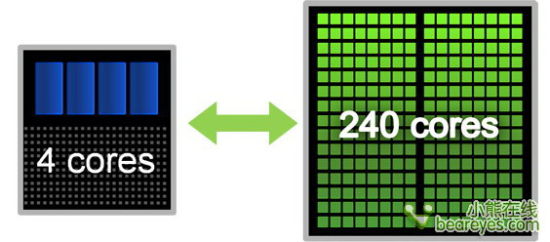
2010年CPU+GPU异构计算
对于GPGPU表现出的惊人计算能力叫人为之折服,但是在显卡进行计算的同时,处理器处于闲置状态。由此处理器厂商也想参与到计算中来,他们希望CPU和GPU能够协同运算,完成那些对计算量有着苛刻要求的应用。同时也希望将计算机的处理能力再推上一个新的高峰。
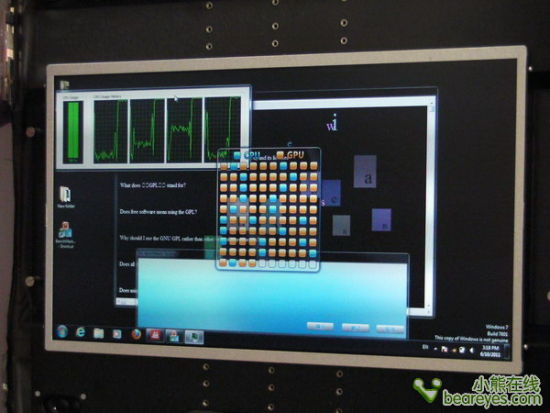
异构计算要求CPU和GPU协同运算
天河星云:异构计算大显神威
国际TOP500组织TOP500.org在网站上公布了最新全球超级计算机TOP500强排行榜,由国防科学技术大学研制,部署在国家超级计算天津中心,中国千万亿次超级计算机“天河一号”位居第一位,实测运算速度可以达到每秒2570万亿次。
“天河一号”耗资6亿元,连接了上万个美国英特尔和Nvidia公司制造的CPU和GPU,属异构混合架构。在过去一年里,天河一号进行了大升级,目前的配置是14336颗英特尔六核至强X5670 2.93GHz CPU和7168颗Nvidia Tesla M2050 GPU和2048颗自主研发的八核飞腾FT-1000 CPU。处理内核数突破20万颗,是去年24576颗的8.25倍。

排名第三的是曙光公司研制的“星云”高性能计算机,其实测运算速度达到每秒1270万亿次。petaflop/s,千万亿次计算单位。星云系统峰值为每秒3000万亿次(3PFlops),实测Linpack值每秒1271万亿次(1.271PFlops),是中国第一台、世界第三台实测双精度浮点计算超千万亿次的超级计算机。
星云超级计算机采用自主设计的HPP体系结构,处理器是32nm工艺的六核至强X5650,并且采用了Nvidia Tesla C2050 GPU做协处理,由4640个计算单元组成。它采用了高效异构协同计算技术,系统包括了9280颗通用CPU和4640颗专用GPGPU组成。计算网络采用了单向40Gbps QDR Infiniband技术,核心存储采用了自主设计的Parastor高速I/O系统。
美国橡树岭国家实验室的“美洲虎”超级计算机此前排名第一,在新榜单中,其排名下滑一位。“美洲虎”的实测运算速度可达每秒1750万亿次。有趣的是中国的两套系统和东京工业大学的系统,所使用的都是NVIDIA的GPU通用计算加速方案。事实上,在Top 500强超级计算机榜单中,有28套系统采用的是图形处理器作为通用计算加速。有16套系统采用的是Cell处理器,其中有10套采用的是NVIDIA的芯片,有2套采用的是AMD的Radeon芯片。目前的Top 500强中有10大系统超越了千万亿次大关。这些超级计算机中有五套来自美国,而其他则来自中国,日本,法国,德国。
迥异:不同计算架构的特点
上文提到的采用的异构计算架构都属于大型计算机的范畴。对于个人计算机而言,尤其是x86架构的计算机,异构计算的步伐则要慢许多。这是因为,无论是处理器还是显示卡,又或者其他运算部件,都有其自身的架构和特性。他们是针对不同领域,面向不同应用所设计的芯片。所以他们在功能性方面千差万别。要想将他们都统一起来,除了需要制定共同的规范和标准之外,还要针对其计算的特点设计软件。

举例来说,CPU和GPU在进行计算时,就有许多不同。对于处理器来说,它是一颗通用处理器。它要应对各种类型的计算应用。无论是数学方面的,还是逻辑方面的运算。我们可以看到,一颗比较常规的处理器其中的ALU计算单元仅仅占据整个核心面积的25%以内。在处理器中,超过50%的核心面积用来制作Cache高速缓存,无论是L1、L2还是片上的L3。而另外还有25%的核心面积用来作为控制器。它控制着处理管线的运作,控制着各种分支预测,让多核心处理器可以更有效率。
而我们再反观GPU,其结构要简单的多。GPU的任务是加速3D像素的计算。因此我们在显卡中可以看到数以百计的流处理器单元或者是CUDA核心。而在整个计算过程中,GPU承担的逻辑计算任务非常小。同时它有着更宽的显存带宽,有着更高速的显存。所以在GPU芯片中,也就无需更大容量的片上缓存机制。
通过上文的分析,我们可以看到CPU的在处理时,适合作所有工作,各个方面都比较平均。逻辑处理能力要比GPU快,但是对于数学计算方面,其速度不如具有海量处理核心的GPU快。而GPU方面,数学计算性能强大,大规模并行处理机制强大,但是逻辑处理能力不足,仅仅能在某些计算领域应用。
Llano核心解析:一个真正的异构计算芯片
AMD前不久发布的新一代Llano处理器,是一颗真正意义上的异构计算处理器。从这张这新架构图中,我们可以看到Llano具备四个处理核心,每一颗核心具有不同类型的L1高速缓存。同时每一个处理核心具备512KB X 2的容量为1MB的L2高速缓存。由此在处理器的部分,构成了4MB的二级缓存。
在整个芯片接近50%的面积上,是GPU的部分。一颗处理芯片同时包含了CPU和GPU的部分,这可以说是非常典型的异构计算架构。同时,在芯片的两边我们也可以看到高度集成的4个PCIe总线控制器,还有一个128bit位宽的DDR3内存控制器。
这样的异构计算芯片可以充分发挥不同计算部件的优势。当需要进行较多逻辑计算时,可以使用CPU部分完成。当需要大量的浮点运算时,可以借用GPU的浮点运算处理管线来完成。同时如果处理器的某些核心正处于空闲,也可以让其加入到计算中来。由此可见异构计算不仅仅是需要统一起不同类型的计算部件,同时也需要有针对性的让更适合的硬件作适用的计算工作。

新的计算架构需要全新的软件标准
对于异构计算来说,更重要的软件。虽然现在我们看到许多计算机中都应用了GPGPU的通用计算,使用显卡来进行大规模的并行计算任务,但是在这个过程中,处理器就被闲置了。例如许多转码程序在运行的时候,仅仅是显卡在跑,而处理器并未参与到转码加速中来。将异构的运算部件,全部有效的调用起来,这是一件困难的编程工作。
如下图所示,传统意义上的多路处理器计算时,仅仅使用的是处理器的并行计算。并未让GPU加入到其中。而现在我们常说的GPGPU通用计算,包括NVIDIA的CUDA和AMD的Stream在计算的时候,也仅仅是GPU在跑,处理器是闲置的。
除了应用软件之外,曾经我们耳熟能详的评测软件,也并未对异构计算作出优化。无论是PCmark还是3Dmark,在这些软体进行测试的时候,会将CPU和GPU利用不同的测试项目分别进行测试。并没有将它们合并在一起,进行有效的异构计算。

Sysmark仅仅是建立许多计算任务,然后让系统来跑,这仅仅是针对的是处理器的部分。而Chinebench系列的软体,仅仅是考察的CPU的渲染性能。对于多核心和超线程虽然有很好的支持,但是并未让GPU加入测试。如你所见,目前针对x86或者台式机平台的异构计算软件少之甚少,甚至连一款像样的异构计算评测软件都无有。
CUDA:在夹缝中挣扎求存
CUDA(Compute Unified Device Architecture,统一计算架构)是由NVIDIA所推出的一种集成技术,是该公司对于GPGPU的正式名称。通过这个技术,用户可利用NVIDIA的GeForce 8以后的GPU和较新的Quadro GPU进行计算。亦是首次可以利用GPU作为C-编译器的开发环境。NVIDIA营销的时候,往往将编译器与架构混合推广,造成混乱。实际上,CUDA架构可以兼容OpenCL或者自家的C-编译器。无论是CUDA C-语言或是OpenCL,指令最终都会被驱动程序转换成PTX代码,交由显示核心计算。

以GeForce 8800 GTX为例,其核心拥有128个内处理器。利用CUDA技术,就可以将那些内处理器串通起来,成为线程处理器去解决数据密集的计算。而各个内处理器能够交换、同步和共享数据。利用NVIDIA的C-编译器,通过驱动程序,就能利用这些功能。亦能成为流处理器,让应用程序利用进行运算。GeForce 8800 GTX显示卡的运算能力可达到520GFlops,如果建设SLI系统,就可以达到1TFlops。
利用CUDA技术,配合适当的软件(例如MediaCoder),就可以利用显示核心进行高清视频编码加速。视频解码方面,同样可以利用CUDA技术实现。此前,NVIDIA的显示核心本身已集成PureVideo单元。可是,实现相关加速功能的一个微软API-DXVA,偶尔会有加速失效问题。所以利用CoreAVC配合CUDA,变相在显示核心上实现软件解码,解决兼容性问题。另外,配合适当的引擎,显示核心就可以计算光线跟踪。NVIDIA就放出了自家的Optix实时光线跟踪引擎,通过CUDA技术利用GPU计算光线跟踪。
FireStream:慢慢淡出我们的视野
Firestream,是AMD旗下的品牌系列之一。与Radeon(用于消费级显卡)和FirePro(用于专业显卡)不同,FireStream主要用于AMD的高性能计算卡系列。FireStream产品中的GPU不是用来作3D加速用途,而是利用GPU内置的流处理器变成一群并行处理器,作为浮点运算协处理器,协助中央处理器计算复杂的浮点运算程序,例如复杂的科学运算。Firestream的竞争对手是nVIDIA的Tesla系列高性能计算卡。
早在数年前,人们就意识到GPU不但可以处理图形数据,还可以处理其他数据。BionicFX就试过利用GeForce 6800处理音频数据,ATI亦做过同样的试验。而且史丹佛大学的Folding@Home研究项目亦可利用Radeon X1900作运算加速;通过GPU来模拟蛋白质合成,进而找寻有关蛋白质的疾病。
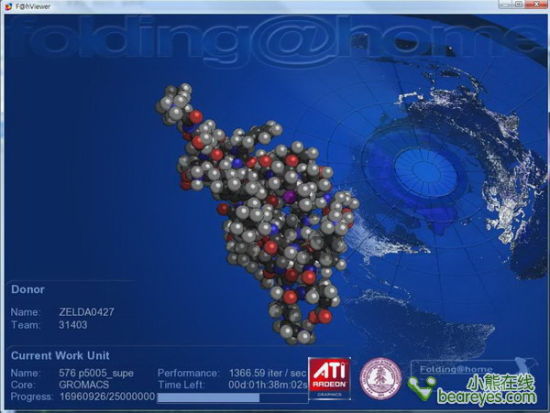
第一个产品,FireStream 580,是建基于R580图形芯片。它将是一块采用R580显核的特殊显示卡,R580显示核心中的48个独立的像素处理器能带来强大的浮点运算性能。该产品采用PCI Express x16作为接口,流处理器的频率是600 MHz,可以同时运行512线程,并配备了1GB GDDR3存储器,频率是1300 MHz。并有可能使用多个核心并发处理数据。这个流处理器的功耗为165瓦特。

FireStream 580
NVIDIA PhysX:最出色的GPGPU应用实例
PPU (Physics Processing Unit)
物理处理单元,即 PPU,是一种特别为减轻 CPU 计算,尤其是物理运算部分的处理器。这概念类似于对上10年间GPU。在现代 计算机中,GPU用于处理 矢量图形,并且延伸到3D图形。但GPU对物理处理无能为力,故目前大部分物理处理都交给CPU处理,这无疑是加重了CPU本来就不轻的负担。

NVIDIA PhysX
PhysX 是一套由 AGEIA 设计的执行复杂的物理运算的PPU,又可以代表一款物理引擎。AGEIA 声称,PhysX 将会使设计师在开发游戏的过程中,使用复杂的物理效果,而不需要像以往那样,耗费漫长的时间开发一套物理引擎。以往使用了物理引擎,还会使一些配置较低的电脑,无法流畅运行游戏。AGEIA 更宣称 PhysX 执行物理运算的效率,比当前的 CPU 与物理处理软件的组合高出 100 倍。游戏设计语言 Dark Basic Pro 将会支持 PhysX,并允许其用户利用 PhysX 执行物理运算。在 2005年7月20日,索尼同意在即将发售的 PlayStation 3 中使用 AGEIA 的 PhysX 和它的 SDK —— NovodeX 。现时,AGEIA公司己被NVIDIA收购,相关的显卡亦可以加速该物理引擎。
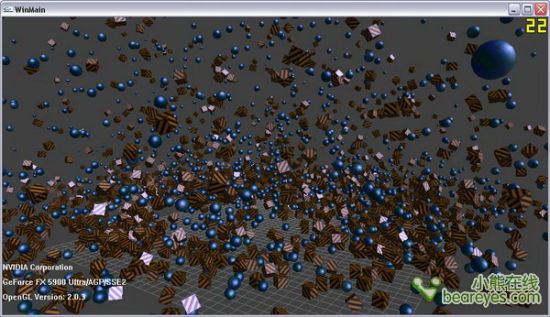
NVIDIA PhysX是一种功能强大的物理加速引擎,可在顶级PC和游戏中实现实时的物理学计算。PhysX软件被广泛应用于数百个游戏中,软件注册用户数量已超过20,000名。索尼的Playstation 3、微软的Xbox 360、任天堂的Wii以及个人计算机均支持PhysX。
PhysX设计用途是利用具备数百个内核的强大处理器来进行硬件加速。加上GPU超强的并行处理能力,PhysX将使物理加速处理能力呈指数倍增长并将您的游戏体验提升至一个全新的水平,在游戏中呈现丰富多彩、身临其境的物理学游戏环境。
OpenCL:无人能模仿 很难被超越
2008年6月的WWDC大会上,苹果提出了OpenCL规范,旨在提供一个通用的开放API,在此基础上开发GPU通用计算软件。随后,Khronos Group宣布成立GPU通用计算开放行业标准工作组,以苹果的提案为基础创立OpenCL行业规范。
OpenCL (Open Computing Language,开放计算语言) 是一个为异构平台编写程序的框架,此异构平台可由CPU,GPU或其他类型的处理器组成。OpenCL由一门用于编写kernels(在OpenCL设备上运行的函数)的语言(基于C99)和一组用于定义并控制平台的API组成。OpenCL提供了基于任务分区和数据分区的并行计算机制。
OpenCL类似于另外两个开放的工业标准OpenGL和OpenAL,这两个标准分别用于三维图形和计算机音频方面。OpenCL扩展了GPU用于图形生成之外的能力。OpenCL由非盈利性技术组织Khronos Group掌管。

OpenCL最初苹果公司开发,拥有其商标权,并在与AMD,IBM,英特尔和nVIDIA技术团队的合作之下初步完善。随后,苹果将这一草案提交至Khronos Group。2010年6月14日,OpenCL 1.1 发布。
OpenCL:奠定了异构计算的基础
虽然苹果制定OpenCL的私心路人皆知,希望通过OpenGL来让自家的Mac电脑可以顺利的使用两个显卡巨头的产品做GPGPU运算。但是苹果的这一举措却为未来的x86平台异构计算奠定了坚实的基础。因为无论是CUDA还是FireStream,无论是CUDA核心还是流处理器,软件开发人员都可以通过OpenCL来支持。

中国用户可以登录英伟达中文官方网站上下载到最新的驱动程序,只要您下载的驱动是195.62版本或更高,就可以在Geforce 8系列或更高级的显卡中开启OpenCL,在安装好新版本的显卡驱动程序并重新启动后,OpenCL就自动开启了。当有需要使用CPU来完成的工作如转换视频时,GPU代替CPU进行运算,以提高转换速度。但是在3D游戏中应该是不会调用OpenCL的,因为显卡有自己的硬件加速功能以及物理引擎。

当然同样,在NVIDIA的Quadro系列专业显卡中,同样能够使用OpenCL技术。只要您的显卡能够达到CUDA的要求,就能够正常使用OpenCL,以获得优异的CPU运算效率。
在AMD-ATI的Stream技术中,已经为日常使用、办公、游戏等提供物理加速。原理与OpenCL基本相同,但是,目前AMD-ATI还没有进行推广,但是官方承诺,在日后会逐渐增多Stream支持的游戏。但是Stream使用的显卡平台还是比较高,而性能非常优异的显卡无疑带来更高昂的价格,我们也同样希望AMD能够做到像NVIDIA那样,只需要支持DirectX10的显卡就能开启OpenCL,以方便更多的AMD-ATI用户。Geforce 8系列以上的显卡能完美支持DirectX10,所以官方将开启OpenCL的显卡最低定为8系列。
DirectCompute:立足DX11,应用广泛
Microsoft DirectCompute是一个应用程序接口(API),允许Windows Vista或Windows 7平台上运行的程序利用图形处理器(GPU)进行通用计算,DirectCompute是Microsoft DirectX的一部分。虽然DirectCompute最初在DirectX 11 API中得以实现,但支持DX10的GPU可以利用此API的一个子集进行通用计算,支持DX11的GPU则可以使用完整的DirectCompute功能。

显卡对DirectX的支持程度影响可用的DirectCompute版本:
DirectX 10:DirectCompute 4.0
DirectX 10.1:DirectCompute 4.1
DirectX 11:DirectCompute 5.0
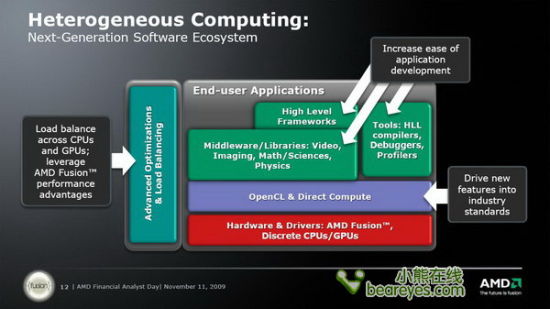
AMD开始全面支持异构计算
相比OpenGL丰富的功能和体系化的SDK来说,DirectCompute仅仅是以一个简单的API存于世上,显然不能赢得更多厂商的关注。由此微软又酝酿了C++ AMP……且看下文分解。
Llano:融聚今宵 真正的异构计算平台
这是AMD近期发布的最强Llano处理器,具有划时代的意义,具备真正的异构计算架构。AMD A8-3850配备了四个主频2.9GHz的CPU核心,不过遗憾的是A8-3850并不支持Turbo Core自动超频。在GPU方面,A8-3850配备的是一颗完整功能的Radeon HD 6550D,该GPU核心配备了400个流处理器,核心频率为600MHz。

A8-3850 APU处理器,采用Llano核心
实际上A8-3850 APU处理器的集成GPU核心性能平均要比Core i5 2500K快58%左右。如果我们只考虑在游戏里的峰值性能的话,在类似于《现代战争2》这样的游戏里,最新Llano桌面APU的GPU在帧频表现上是可以达到Sandy Bridge两倍的,这也再次证明了英特尔集成GPU在游戏领域的尴尬。至于Llano的GPU性能,相信这才是玩家们最喜闻乐见的。
虽然我们也认为Sandy Bridge在集成GPU性能方面是不错的入门选择,但是至少在2011年,Llano桌面APU仍然是懂行玩家最该做出的选择。值得注意的在这些测试里,测试方随后还为Core i5 2500K GPU安装了最新的2372驱动程序,结果证明大部分的结果仍然没有改变,不过在少数领域英特尔发掘出了更多的潜力。无论如何,在GPU测试里,AMD的Llano桌面APU A8-3850发挥出了令人印象深刻的性能。

Socket-FM1接口
C++ AMP:微软发布异构计算编程语言
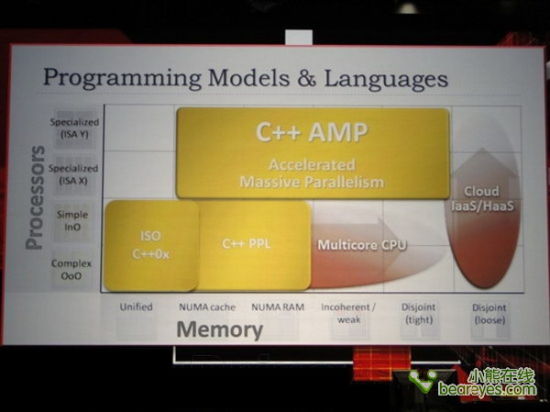
自从AMD发布了Llano处理器,异构计算就真正进入了寻常百姓的家中。虽然OpenCL作为通用大规模并行计算的行业领军标准,得到了AMD、Intel、NVIDIA等芯片业巨头和大量行业厂商的支持,但唯独缺少了微软。
近日在AMD Fusion开发者峰会上,微软终于拿出了自己的异构计算编程语言:“C++ AMP”,其中AMP三个字母是“accelerated massive parallelism”的缩写,也就是加速大规模并行的意思。

微软的“异构并行计算”
C++ AMP是微软Visual Studio和C++编程语言的新扩展包,用于辅助开发人员充分适应现在和未来的高度并行和异构计算环境。它使用C++语言的句法,将捆绑在下个版本的Visual Studio中发布,预计会在今年晚些时候放出测试版本。
为了与OpenCL相抗衡,微软宣布C++ AMP标准将是一种开放的规范,允许其它编译器集成和支持。这无疑是对OpenCL的最直接挑战。

C++ AMP的威力:刚体模拟性能绽放(上)
为了展示了C++ AMP的威力,微软现场运行了一个“刚体模拟”程序。一个可执行文件能够在多台计算机和设备上同时运行。这里我们可以看到,Llano APU x86处理器可以贡献出3GFlops的计算量。Llano APU的显示核心与处理核心协同工作,可以提供500GFlops的计算量。另外,Llano APU和Radeon HD 5800可以提供1000多GFlops的计算量,模拟4万多个粒子。即使是AMD的E-350这样的仅有18W的低功耗笔记本处理器也可以提供16GFlops的计算量,能够模拟16000多个粒子。
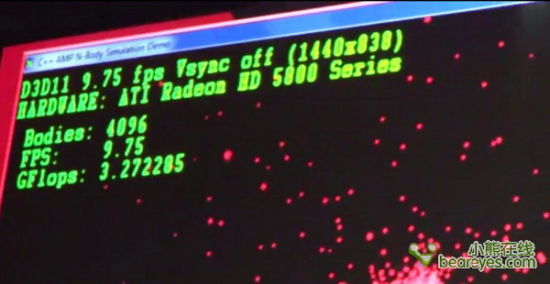
E-350的CPU部分,可以得到3.2GFlops的计算量
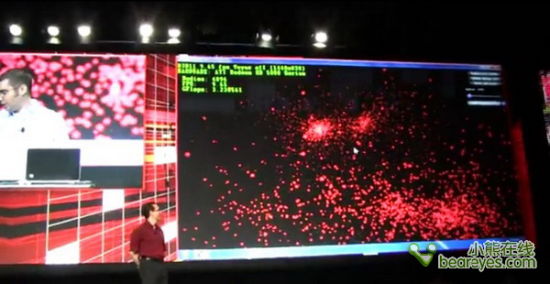
仅仅可以模拟4096多个刚体粒子
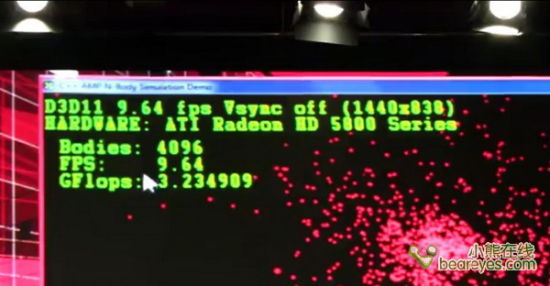
请注意这里鼠标所指示的运算量
C++ AMP的威力:刚体模拟性能绽放(中)
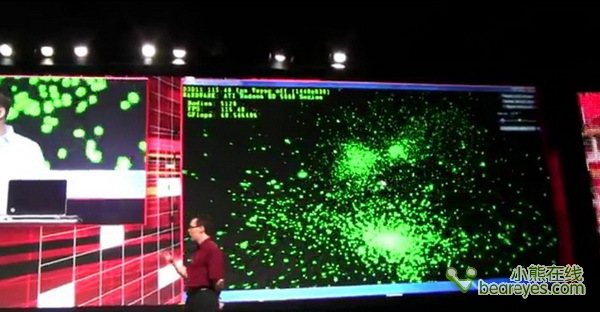
模拟的刚体粒子数量增加到5120个
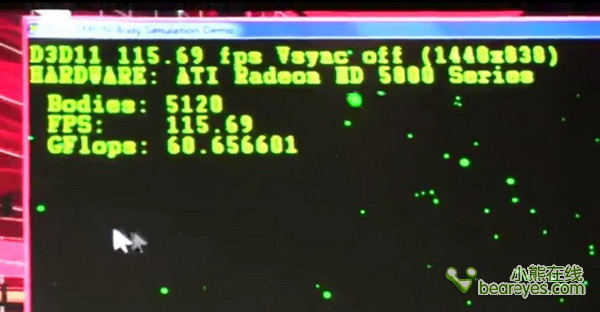
CPU与GPU核心,联合运算,可以提供60GFlops的运算量
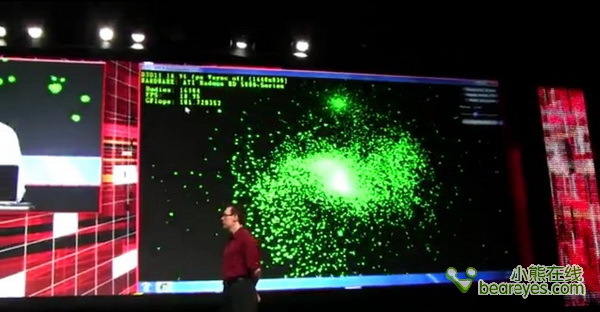
下面加入更多刚体粒子
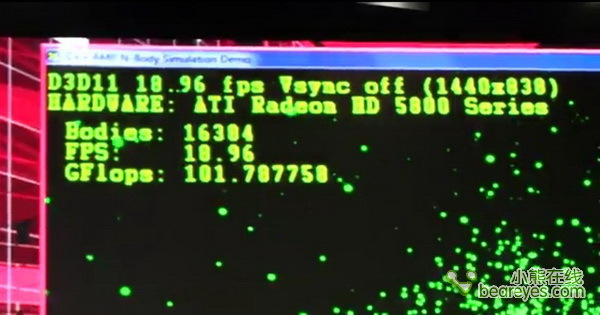
小贴士:什么是刚体?
在任何力的作用下,体积和形状都不发生改变的物体叫做刚体(Rigid body)。在物理学内,理想的刚体是一个固体的,尺寸值有限的,形变情况可以被忽略的物体。不论有否受力,在刚体内任意两点的距离都不会改变。在运动中,刚体上任意一条直线在各个时刻的位置都保持平行。
C++ AMP的威力:刚体模拟性能绽放(下)

加入更多刚体粒子,模拟20160个
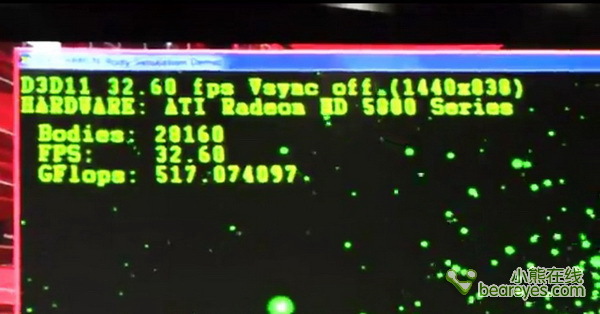
Llano APU可以贡献出500GFlops的计算量,这与AMD之前宣称的个人超级计算机的口号属实

刚体的模拟数量达到了40960个的时候,就需要极大的计算量才能保证稳定输出30fps的帧率。下面这张图,你可以看到在联合了两台台式机之后,计算量接近1TFlops。
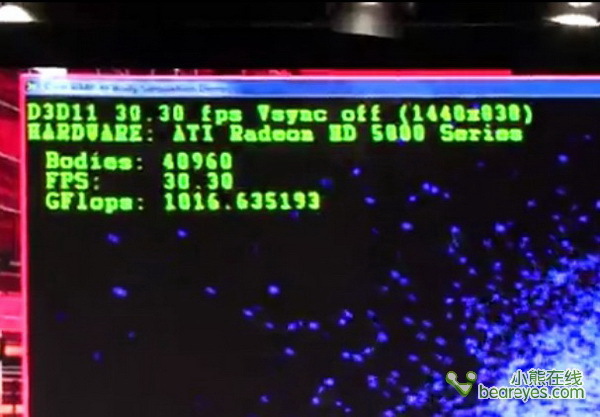
一触即发:异构计算行业标准大战
NVIDIA并未获得Intel关于x86架构的授权,就连开发x86的模拟器的自由都被封杀。无奈之下CUDA也仅仅是GPGPU的单独运算。OpenCL是免费开放的,也是目前异构计算的唯一选择。
而微软的C++ AMP会与Windows紧密贴合起来。虽然也属于开放性的标准,但是微软对其未来方向的掌控,其执行应该更有效力。OpenCL有多家主力厂商支持,技术纷争不断,为了自家产品的利益难免在新版本制定方面出现歧路。现在的局面就有点类似曾经OpenGL对决DirectX的时代,不知道这次微软是否还能够全面胜出。

上面这张图表明,如果你的计算量仅有630GFlops的话,你的帧数仅仅能维持在19fps左右。
最后
以上就是动听手机最近收集整理的关于双剑合璧:CPU+GPU异构计算完全解析的全部内容,更多相关双剑合璧内容请搜索靠谱客的其他文章。








发表评论 取消回复