
问题:在内存的分配上,那个占用的内存更少呢?
第一种24B 第二种16B
相信看完这篇文章,你就能清楚的明白了
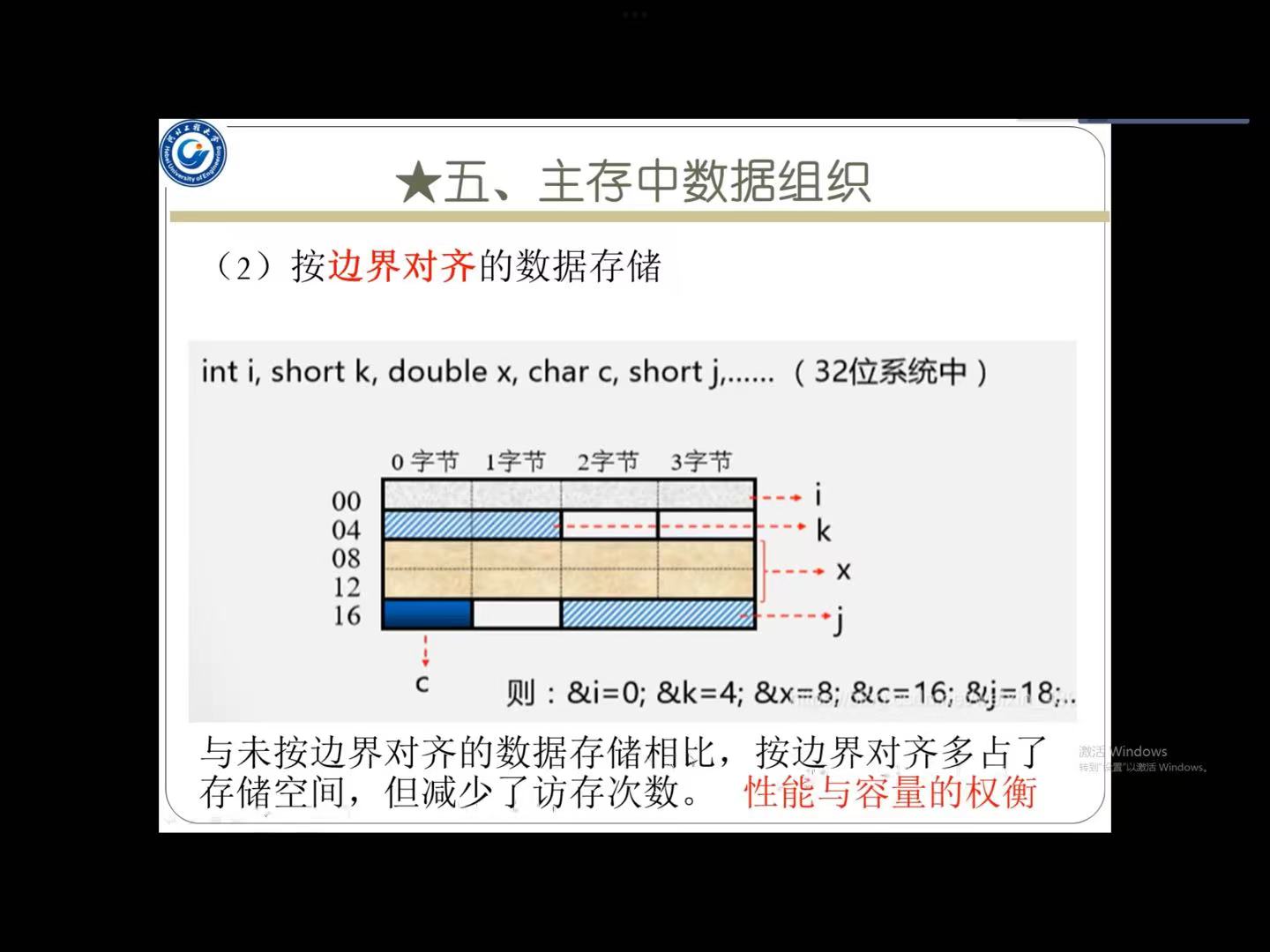
简单来说,数据的存储尽量在同一个存储空间,不能分家,并且要使末端对齐
法则:莫类型数据边界对齐存储的起始地址是该数据类型字长的整数倍
即如果是双子长(16bit)那么边界对齐的起始地址的末3位必须是000
这就保证了添加该数据进去以后依然是存储是整数倍
所以我解释一下s1的内存大小为什么是24呢
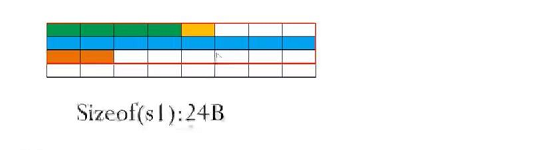
即在添加该元素的时候,要考虑到元素的起始位置是不是元素大小的整数倍,由此发现结构体占三行,每行是8个字节(64位操作系统的默认),一共24字节
复制粘贴 查看结果
#include <iostream>
#include <stdio.h>
using namespace std;
struct test1
{
int a;
char b;
double c;
short d;
} s1;
int main()
{
cout << sizeof(s1) << endl;
return 0;
}接下来 将一下大端模式和小端模式

大端模式 数据高位地址在低位地址 (数据是个十百千万 地址从高位到低位置)
数据高位对应的地址 就是字开始的地址
小端模式 如图,正好相反 小端模式对于计算机来说更好
通过以下代码,判断本机是大端还是小端模式
#include <stdio.h>
union utest
{
int a;
char b;
} u;
int main()
{
u.a = 0x12345678;
if (u.b == 0x12)
{
printf("大端模式");
}
else
{
printf("小端模式");
}
return 0;
}
最后
以上就是文静月亮最近收集整理的关于边界对齐、大端模式和小端模式的全部内容,更多相关边界对齐、大端模式和小端模式内容请搜索靠谱客的其他文章。
本图文内容来源于网友提供,作为学习参考使用,或来自网络收集整理,版权属于原作者所有。








发表评论 取消回复