目录
Overview
The ZNS Zoned Storage Model
Zone types
Zone Capacity and Zone Size
Active Zones
Zone Append
Linux 分区存储支持概述
Overview
Kernel Versions
推荐的内核版本
ZBD Support Restrictions
写排序控制
Zone Write Locking
初步实现
改进的实现:块I/O调度程序
分区命名空间(ZNS) ssd代表了主机软件和基于闪存的ssd之间的一种新的功能划分。ZNS SSD将其容量划分为zone,每个zone可以按任意顺序读取,但必须按顺序写入。这些特性允许ZNS SSD改善其内部数据放置,从而通过更高的写吞吐量、更低的QoS和更大的容量获得更高的性能。
ZNS ssd实现了由NVM Express (NVMe)组织定义的NVMe ZNS命令集规范,并作为NVMe 2.0规范的一部分发布。最新的版本是1.1。
Overview
ZNS SSD 遵循分区存储模型。 这种基于标准的架构采用统一的存储方法,使 HDD 和 ZNS SSD 中的叠瓦式磁记录 (SMR) 能够共享统一的软件堆栈。 特别是对于 ZNS SSD,区域抽象允许主机将其写入与基于闪存的 SSD 的顺序写入所需属性对齐,从而优化数据在 SSD 介质上的放置。 请注意,媒体可靠性的管理仍然是 ZNS SSD 的唯一责任,并且应该以与传统 SSD 相同的方式进行管理。
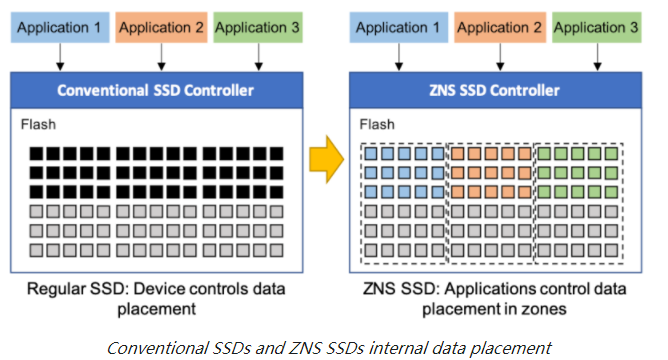
The ZNS Zoned Storage Model
ZNS 命令集规范建立在为 SMR 硬盘引入的现有主机管理分区存储模型的基础上,采用 SCSI ZBC(分区块命令)标准和 ATA ZAC(分区 ATA 命令)标准。 定义了兼容的区域状态机,并定义了一组类似的区域块命令。
这些相似之处简化了主机存储堆栈和应用程序的实施,以同时支持主机管理的 SMR 硬盘和 ZNS SSD。
鉴于 ZNS SSD 通常是使用非易失性存储器实现的,ZNS 规范引入了额外的功能来启用这种类型的介质,如下所述。
Zone types
ZBC 和 ZAC SMR 硬盘可以选择性地公开许多接受随机写入操作的常规区域。 ZNS 规范没有定义这组可选的随机写入区域,因为 NVMe 支持多个命名空间,因此可以公开一个支持常规 I/O 访问的单独命名空间。
Zone Capacity and Zone Size
ZNS 规范引入了区域容量的概念。 这个概念在 ZBC 和 ZAC 标准中没有定义。
与 ZBC 和 ZAC 标准类似,ZNS 将区域大小定义为区域内逻辑块的总数。 区域容量是每个区域的附加属性,指示每个区域内可用逻辑块的数量,从每个区域的第一个逻辑块开始。 区域容量始终小于或等于区域大小。
引入这一新属性是为了允许区域大小保持逻辑块数量的 2 次方(便于逻辑块到区域编号的转换),同时允许优化区域存储容量到底层媒体特性的映射。 例如,在基于闪存的设备的情况下,区域容量可以与闪存擦除块的大小对齐,而无需设备实现大小为 2 的擦除块。
下图说明了区域容量概念。
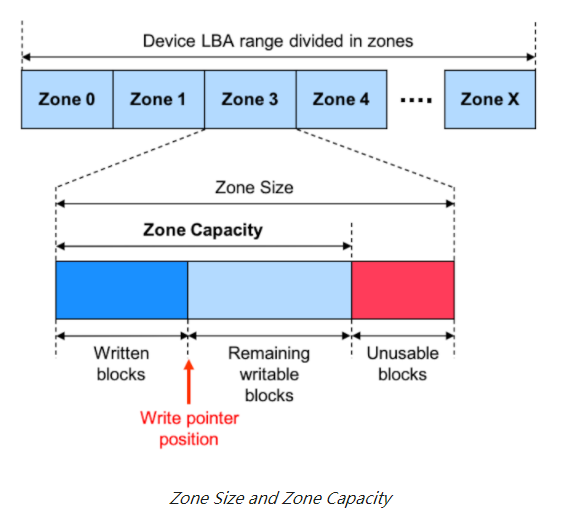
由于区域容量和区域末端之间的逻辑块地址没有映射到任何物理存储块,因此对这些块的写访问将导致错误。 因此,在该区域中的读取与读取未写入块时的处理方式相同。
当写入块的数量等于区域容量时,区域容量小于区域大小的区域将转换为满状态。
NOTE
控制器报告的总命名空间容量始终等于区域定义的逻辑块的总数。 换言之,该报告的容量包括区域容量低于区域大小的不可用逻辑块。 命名空间的可用容量等于所有区域容量的总和。 如果命名空间包含区域容量低于区域大小的区域,则此可用容量始终小于报告的命名空间容量。
Active Zones
控制器实现通常需要分配内部资源(例如写入缓冲区)来执行区域的写入操作。因此,对控制器可用资源总量的限制可能意味着对可以同时处于implicit open 或者 explicit open条件的区域总数的限制。 ZNS、ZBC 和 ZAC 标准中类似地定义了对 open zones的最大数量的潜在限制。
然而,ZNS 规范定义了对可以处于implicit open、explicit open或close条件的区域数量的附加限制。具有这种条件的任何区域都被定义为active zone,并且对应于正在写入或仅部分写入的任何区域。 ZNS SSD 可能会对可以active 的区域的最大数量施加限制。此限制始终等于或大于open zones的最大数量限制。
这一新限制对用户应用程序施加了新的限制。虽然命名空间的maximum number of open zones仅限制了应用程序可以同时写入的区域数,但maximum number of active zones限制了应用程序可以选择用于存储数据的区域数。如果达到maximum number of active zones,则应用程序必须reset 或finish 一些活动区域,然后才能选择其他区域来存储数据。
与maximum number of open zones限制类似,命名空间的maximum number of active zones限制不会影响读取操作。无论当前打开和活动区域的数量如何,始终可以访问任何未offline 的区域以进行读取。
Zone Append
NVMe 规范允许设备控制器以任意顺序执行多个可用提交队列submission queues中的命令。这对主机 IO 堆栈有影响,即即使主机顺序提交针对区域的写入命令,这些命令也可能在处理之前重新排序,并违反顺序写入要求,从而导致错误。主机软件可以通过将每个区域未完成的写入命令数限制为1来避免此类错误。这可能会导致性能下降,尤其是对于主要发出小型写入操作的工作负载。
为了避免这个问题,ZNS 规范引入了新的 Zone Append 命令。
Zone Append命令是指定区域的第一个逻辑块作为写入位置的写入操作。执行命令时,设备控制器在指示的区域内写入数据,但在当前区域写入指针位置进行。写入位置的这种变化是自动的,并且数据的有效写入位置通过命令完成信息指示给主机。这种机制允许主机同时提交多个区域附加操作,并让设备以任何顺序处理这些操作。
下图说明了常规写操作和区域追加写操作之间的区别。
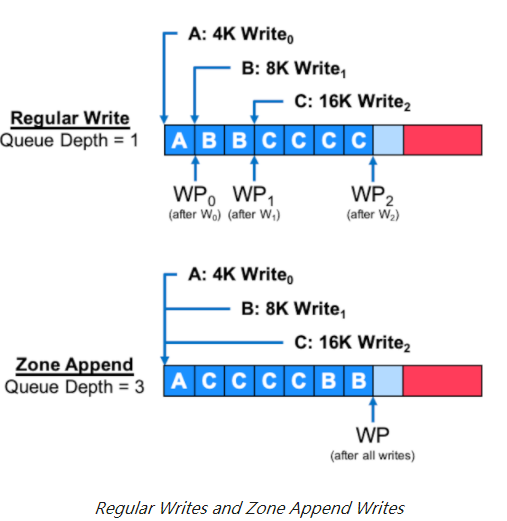
在上面的示例中,主机必须向同一个区域发出三个不同的数据 A (4KB)、B (8KB) 和 C (16KB) 写入操作。使用常规写入命令,这只能在每个区域写入队列深度为1下安全地完成,即主机必须等待未完成的写入操作完成,然后才能发出下一个写入请求。对于每个写请求,写位置必须等于区域写指针位置。这导致数据以与发布时相同的顺序存储在区域中。
使用Zone Append写操作,写队列深度限制被删除,主机可以同时发出所有三个写请求。在完成所有写入请求后,区域写入指针位置与前一种情况相同,因为写入的数据总量相等。然而,区域内写入数据的位置可能不对应于主机命令发出顺序,因为设备控制器可以自由地重新排序命令执行,以它认为合适的方式。主机可以通过zone append completion information发现每个请求的有效写入位置。
Linux 分区存储支持概述
分区块设备支持已添加到版本 4.10的 Linux ®内核中。后续版本改进了这种支持,并在原始块设备访问接口之外添加了新功能。现在可以使用更高级的功能,例如设备映射器支持device mapper support和 ZBD 感知文件系统。
Overview
应用程序开发人员可以通过各种 I/O 路径使用分区块设备,可以通过不同的编程接口对其进行控制,并且可以以不同的方式公开分区块设备。下图显示了各种访问路径的简化表示。
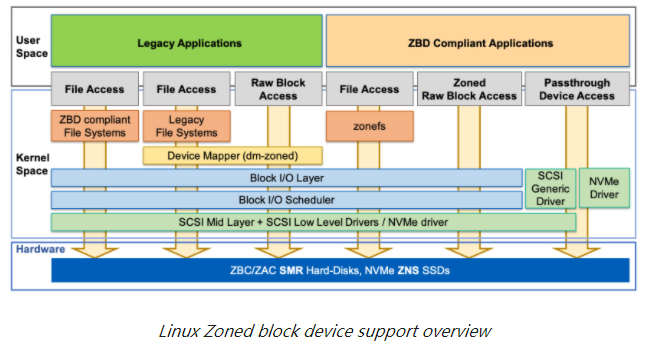
三个不同的 I/O 路径实现了两个 POSIX 兼容接口,这些接口隐藏了分区块设备的顺序区域的写入约束。这三个 I/O 路径可以运行传统应用程序(未修改以实现全顺序写入流的应用程序)。
文件访问接口这是文件系统实现的接口,允许应用程序将其数据组织到文件和目录中。文件访问接口有两种不同的实现:
ZBD 兼容文件系统:通过此实现,文件系统被修改为直接处理分区块设备的顺序写入约束。应用程序对文件的随机写入被文件系统转换为顺序写入流,从而对应用程序隐藏了设备约束。F2FS文件系统就是一个例子 。
Legacy File System:在此实现中,使用未修改的文件系统,并且设备顺序写入约束由设备映射器目标驱动程序device mapper target driver处理,该驱动程序将分区块设备公开为常规块设备。此设备映射器称为dm-zoned。它的特性和使用在“设备映射器”指南的 dm-zoned 部分中进行了详细讨论。
原始块访问接口这是原始块设备文件访问接口,应用程序可以使用它直接访问存储在设备上的数据。与传统文件系统案例类似,此接口是使用dm-zoned设备映射器目标驱动程序实现的,以对应用程序隐藏顺序写入约束。
另外,三个附加接口可用于已写入或修改以符合分区块设备的顺序写入约束的应用程序。这些接口直接将设备约束暴露给应用程序,这些应用程序必须确保使用从区域的写入指针位置开始的顺序流写入数据。
文件访问接口:这个特殊的接口由 zonefs文件系统实现。zonefs是一个非常简单的文件系统,它将分区块设备的每个区域公开为一个文件。但与常规 POSIX 文件系统不同的是,zonefs 不会自动处理设备的顺序写入约束。应用程序负责按顺序写入代表区域的文件。
分区原始块访问接口:这是原始块访问接口的对应物(没有任何中间驱动程序来处理设备约束)。应用程序可以通过直接打开代表分区块设备的设备文件来使用此接口,以访问块层提供的区域信息和管理操作。 例如,Linux System Utilities使用此接口。物理分区块设备以及逻辑创建的分区块设备(例如,使用 dm-linear设备映射器目标device mapper target创建的分区块设备)支持此接口。libzbd用户库和工具可以简化使用此接口的应用程序的实现。
Passthrough Device Access Interface直通设备访问接口:这是允许应用程序直接向设备发送 SCSI 或 NVMe 命令的接口(由 SCSI 通用驱动程序 (SG) 和 NVMe 驱动程序提供)。内核对应用程序发送的命令的干扰最小,因此需要一个应用程序本身可以处理所有设备限制(例如逻辑和物理扇区大小、区域边界、命令超时、命令重试计数等)。libzbc 和libnvme等用户级库可以极大地简化使用该接口的应用程序的实现。
Kernel Versions
带有内核 4.10 的分区块设备支持的初始版本仅限于块层 ZBD 用户界面、SCSI 层顺序写入顺序控制和对F2FS文件系统的本机支持。以下内核版本添加了更多功能,例如设备映射器驱动程序和对块多队列基础架构的支持。
下图总结了分区块设备支持与内核版本的演变。
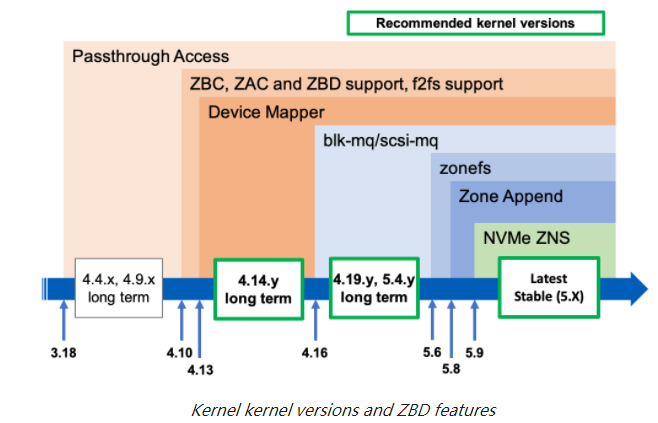
Passthrough Access Support直通访问支持 ( SG Access )支持将主机管理的 ZBC/ZAC 硬盘公开为 SCSI 通用 (SG) 节点已正式添加到内核 3.18,其中定义了TYPE_SCSISCSI 设备的设备类型和设备类的ATA_DEV_ZAC定义ATA 设备。对于 3.18 版本之前的内核,SATA 主机管理的 ZAC 磁盘不会作为 SG 节点或块设备文件向用户公开。这些较旧的内核将简单地忽略报告主机管理的 ZAC 设备签名的 SATA 设备,并且这些设备将无法以任何方式使用。对于连接到兼容 SAS HBA 的 SCSI 磁盘或 SATA 磁盘,用户可以通过 SG 驱动程序创建的节点文件访问主机管理的磁盘来表示这些磁盘。
分区块设备访问和F2FS支持添加到内核版本 4.10 的块 I/O 层分区块设备支持允许将主机管理的 ZBC 和 ZAC 磁盘公开为块设备文件,类似于常规磁盘。此支持还包括对内核libata命令转换的更改,以将 SCSI ZBC 区域块命令转换为 ZAC 区域 ATA 命令。对于依赖 SCSI 通用直接访问的应用程序,这可以使用相同的代码处理 ZBC (SCSI) 和 ZAC (ATA) 磁盘(例如,不需要发出 ATA 命令)。也可以使用磁盘块设备文件(例如/dev/sdX设备文件)与常规 POSIX 系统调用。但是,与普通磁盘相比,仍然存在一些限制(请参阅Kernel ZBD Support Restrictions)
设备映射器和dm-zoned支持在内核版本 4.13.0 中,设备映射器基础结构添加了对分区块设备的支持。这种支持允许在分区块设备之上使用dm-linear和dm-flakey设备映射器目标。此外,还添加了dm 分区设备映射器目标驱动程序。
块多队列和 SCSI 多队列支持内核版本 4.16.0 添加了对块多队列基础结构的支持。此改进支持使用启用了 SCSI 多队列 ( scsi-mq ) 支持的主机管理的 ZBC 和 ZAC 磁盘,同时保留对传统单队列块 I/O 路径的支持。块多队列和scsi-mq I/O 路径是自内核版本 5.0 以来的默认设置,删除了旧的单队列块 I/O 路径支持。
zonefs内核 5.6.0 首次引入了zonefs文件系统,它将分区块设备的区域公开为常规文件。zonefs使用内核内部分区块设备接口实现,支持所有类型的分区块设备(SCSI ZBC、ATA ZAC 和 NVMe ZNS)。
Zone Append操作支持内核版本 5.8.0 引入了一个通用块层接口,用于支持 Zone Append操作。此版本还修改了 SCSI 层以使用常规写入命令模拟这些操作。通过引入 NVMe ZNS 支持(见下文),该仿真统一了所有分区块设备的接口和功能,简化了文件系统等其他功能的实现。
NVM Express Zoned Namespaces在内核版本 5.9 中,添加了对 NVMe ZNS 命令集的支持。这使 nvme 驱动程序具有发现分区命名空间所需的命令集增强功能,并将它们注册到块层作为主机托管区域块设备。此内核版本仅支持不实现任何zone optional characteristics (ZOC) 的设备,并且还要求设备实现可选的Zone Append command。
对内核分区块设备支持的改进仍在进行中。对新文件系统(如btrfs)的支持将在未来几个月发布。
推荐的内核版本
自 4.10 以来的所有内核版本都包括分区块设备支持。但是,如图Kernel versions and features所示,推荐使用某些版本而不是其他版本。
长期稳定 (LTS) 版本内核版本 4.14、4.19、5.4、5.10 和 5.15 是长期稳定的内核版本,其中包括从主线(开发)内核中的修复反向移植的错误修复。这些版本受益于为更高版本开发的稳定性改进。对 zoned-block-device 支持基础设施的修复也向后移植到这些版本。
最新稳定版本虽然不一定标记为长期稳定版本,但最新稳定内核版本会接收在内核开发主线中开发的所有错误修复。除非该版本被标记为长期支持版本,否则随着以下版本从主线版本切换到稳定版本,将修复向后移植到稳定内核版本会停止。因此不建议长时间使用特定的内核稳定版本。
对于任何稳定或长期稳定的内核版本,我们建议系统管理员使用该版本中的最新可用版本,以确保应用所有已知的修复程序。
当前主线、稳定和长期稳定内核版本的列表可以在 Linux Kernel Archives站点上找到。
ZBD Support Restrictions
为了尽量减少对块层代码的更改,重用了块层的各种现有功能(例如,为软件 RAID 实现的 LBA 边界上的 IO 自动拆分就是这种重用的一个例子)。与分区块设备的行为不兼容或太复杂而无法更改的内核组件保持不变。这导致了一组约束,这些约束约束了所有与 Linux 一起工作的分区块设备。
区域大小ZBC、ZAC 和 ZNS 标准不对设备的区域布局施加任何限制(这意味着区域可以是任意大小),但内核 ZBD 支持仅限于所有区域大小相同的区域设备. 区域大小还必须等于逻辑块的数量,即 2 的幂。只有设备的最后一个区域可能具有较小的大小(所谓的runt zone)。此区域大小限制允许内核代码使用通常用于软件 RAID 设备的块层“分块”空间管理。分块空间管理使用二次幂算术(位移操作)来确定正在访问哪个块(即哪个区域),并且它还确保块 I/O 操作不会跨越区域边界。
无限制读取ZBC 和 ZAC 标准定义了URSWRZ位,该位确定当读取操作针对顺序写入所需区域的未写入扇区时,设备是否会返回错误。(这种读取操作的一个示例是当读取命令访问区域的写入指针位置之后的扇区时。)Linux 仅支持允许不受限制的读取命令的 ZBC 和 ZAC 主机管理的硬盘。换句话说,Linux 仅支持报告未设置URSWRZ位的 SMR 硬盘。添加此限制是为了确保在检查磁盘分区表时块层磁盘分区扫描过程不会导致读取命令失败。
直接 IO 写入内核页缓存不保证缓存的脏页将按扇区顺序刷新到块设备。如果应用程序使用缓冲写入来写入设备的顺序写入所需区域,这可能会导致未对齐的写入错误。为了避免这个陷阱,直接使用没有文件系统的分区块设备的应用程序应该始终使用直接 I/O 操作来写入主机管理磁盘的顺序写入所需区域(也就是说,它们应该发出write()带有使用该 O_DIRECT标志的块设备“文件打开”)。
Zone Append ZNS 规范定义了可选的“Zone Append”命令。当主机必须写入数据但要求设备报告数据放置的位置时,可以使用此命令代替常规写入命令。这允许高效的主机实现,因为 (1) 不必跟踪写指针,并且 (2) 不必对写命令进行排序。Linux IO 堆栈已启用以将其与内核版本 5.8 一起使用,并且 NVMe 驱动程序要求设备支持此可选命令,以便命名空间可通过内核使用。
写排序控制
从历史上看,Linux ®内核块 I/O 堆栈(即块层和 SCSI 层)从未保证块 I/O 请求的确切执行顺序。由于块 I/O 请求在内核中执行的异步性以及设备请求队列需要细粒度锁模型的必要性,无法保证块 I/O 请求的确切执行顺序(当多个上下文同时向块设备发出 I/O 请求时,最大限度地减少锁争用开销)。参考
这种设计的直接结果是无法向表现良好的 ZBD 兼容应用程序提供保证,即区域的写入命令将以递增的 LBA 顺序交付(匹配区域顺序写入约束)。
为了解决这个问题,内核 ZBD 支持添加了区域写入锁定,以确保每个区域按顺序处理写入请求。
Zone Write Locking
区域写入锁定实现了每个区域的写入锁定per-zone write lock,以序列化针对同一区域的写入请求的执行。这个特性不能保证写命令总是在区域写指针的位置发出:这是写 I/O 发出者的责任。区域写入锁定仅保证应用程序、文件系统或设备映射器目标发出写入命令的顺序将受到块 I/O 堆栈的尊重。因此,分区块设备的表现良好的用户将避免未对齐的写入命令失败。
区域写入锁定不会以任何方式影响读取命令。 读取请求不需要序列化且处理方式与常规块设备相同同。
初步实现
区域写锁定首先在内核 4.10 的 SCSI 磁盘驱动程序(块层之下)中实现,对已由块 I/O 调度程序传递到设备调度队列的请求进行操作。
这种早期实施依赖于 SCSI 层可以延迟向设备发出任何请求的事实。通过维护每个区域一个位的位图,SCSI 磁盘驱动程序在看到写入命令时将区域标记为锁定。此处更详细地介绍了此算法:
1.如果要发送到设备的下一个命令不是写入命令,则立即发送该命令。
2.如果分派的下一个命令是写入命令,则检查命令的目标区域的区域写入锁定位zone write lock bit。
(1)如果写命令的目标区域没有写锁定(即,该位未设置),则该区域被锁定,并且向设备发出写命令。这两个操作都是在设备请求队列自旋锁spinlock下原子执行的。
(2)如果目标区域已被锁定(即,该位已设置),则 SCSI 磁盘驱动程序会暂时延迟向设备发出命令,直到区域写入锁定被释放。
(3)当一个写命令完成时,该命令的目标区域的区域写锁被释放,并且调度过程被恢复。这意味着如果调度队列头部的命令针对同一区域,则可以发出命令(当写入命令完成时)(步骤 2.a)。
NOTE:如上所示实施的区域写入锁定还可以防止 SAS HBA 或 SATA 适配器意外重新排序命令。AHCI 规范没有定义向设备发出命令的明确顺序。结果,许多芯片组无法保证命令的正确顺序。
尽管此实现为传统的单队列块 I/O 路径提供了写入顺序保证并且不依赖于任何特定的 HBA,但它有几个限制:
潜在的性能下降对任何区域的任何写入命令都会导致命令调度处理停止。这可以防止分派所有其他命令,包括读取命令。这会限制在以高队列深度操作设备时通过设备级命令重新排序获得的性能优势。极端情况是应用程序通过异步 I/O 系统调用(例如 io_submit())向区域发出写入流。在这种情况下,顺序写入命令将在设备调度队列中按顺序排列,从而导致驱动器以一个队列深度运行,一次一个写入命令。
不支持块多队列 I/O 路径block multi-queue I/O path与传统的单队列块 I/O 接口不同,多队列块 I/O 实现并不严重依赖设备队列自旋锁来处理磁盘用户(应用程序或内核组件)发出的块 I/O 请求。这会导致在请求被传递到设备调度队列之前发生潜在的块 I/O 请求重新排序以及区域写入锁定的无效性。
这些限制导致使用块层 I/O 调度程序在 I/O 堆栈的更高级别开发新的区域写入锁定实现。
改进的实现:块I/O调度程序
通过将区域写入锁定实现在 I/O 堆栈中向上移动,还可以支持块多队列(和 SCSI 多队列)基础架构。 内核版本 4.16 添加了此改进,并且删除了区域写入锁定的 SCSI 层实现。
这种区域写入锁定的新实现依赖于块层deadline 和 mq-deadline I/O 调度程序,并且还解决了先前实现的性能限制。 具体来说,新算法如下。
NOTE
deadline 和 mq-deadline 调度程序通过按类型(读与写)对命令进行分组来操作,并始终分别处理这两组命令,例如 首先发出许多读取,然后发出许多写入。 这通过利用硬件功能(例如设备级预读)来提高性能。
1.如果调度程序正在处理读取命令...
(1)...读命令列表中排队的第一个命令被允许继续并提交到设备调度队列。
(2)如果没有可用的读命令,激活写处理(步骤2)。
(3)如果达到读命令处理时间限制,则激活写命令处理(步骤2)以避免写命令饥饿。
(4)如果读取命令仍然可获得,则从步骤 1 重新开始。
2.处理写命令时,调度程序中排队的写命令列表按顺序从 LBA 有序列表头部的命令或到达时间有序列表中的第一个命令开始扫描(当存在命令不足的风险时)。
(1)如果第一个写命令的目标区域没有写锁定(区域位图位未设置),则该区域被锁定并向设备发出写命令。 这两个操作都是在调度程序维护的自旋锁下原子执行的。
(2)如果目标区域已经被锁定(位设置),则跳过该命令,并在写命令的LBA有序列表中搜索针对不同区域的第一个写命令。 如果找到这样的命令,则再次执行步骤 2。
(3)如果所有排队的写命令都针对锁定区域,则调度器操作模式(批处理模式)切换到*read*并调用步骤1。
3.当一个写命令完成时,该命令的目标区域的区域写锁被释放,调度器被激活。 根据当前的批处理模式,在第 1 步或第 2 步恢复操作。
从该算法可以清楚地看出,设备现在可以在更高的队列深度下运行,并且只有针对同一区域的顺序写入才会受到限制。 所有读取命令都可以继续执行,并且针对不同区域的写入命令不会相互影响。
NOTE
这个新的实现不保证整体的命令顺序。 仅针对针对同一区域的写入命令提供保证。 调度程序可以更改针对不同区域的写入命令的调度顺序。 对于任何单个顺序区域,在任何时候,总是最多有一个正在执行的写入命令。 当存在读取访问并且同时写入多个区域时,可以在高队列深度下进行整体磁盘操作。
最后
以上就是复杂金毛最近收集整理的关于NVMe Zoned Namespaces (ZNS) SSDsOverviewThe ZNS Zoned Storage ModelLinux 分区存储支持概述写排序控制的全部内容,更多相关NVMe内容请搜索靠谱客的其他文章。








发表评论 取消回复