前言
对于没有GPU训练机的人来讲,使用云服务器训练自己的模型应该最最优选择,只是在训练的时候开个按时计费的服务器,训练完成后保存环境镜像之后,可以完全停掉服务器,期间不产生任何费用,下次再训练时,启动环境就可以,很容易保护好自己的训练环境不受污染。
一、选择服务器
1.这里选择的是阿里有服务器,直接用支付宝账号登录。
2.选择配置,按量计费,我训练yolov5的模型,2万多的数据集,V100完全够用了。
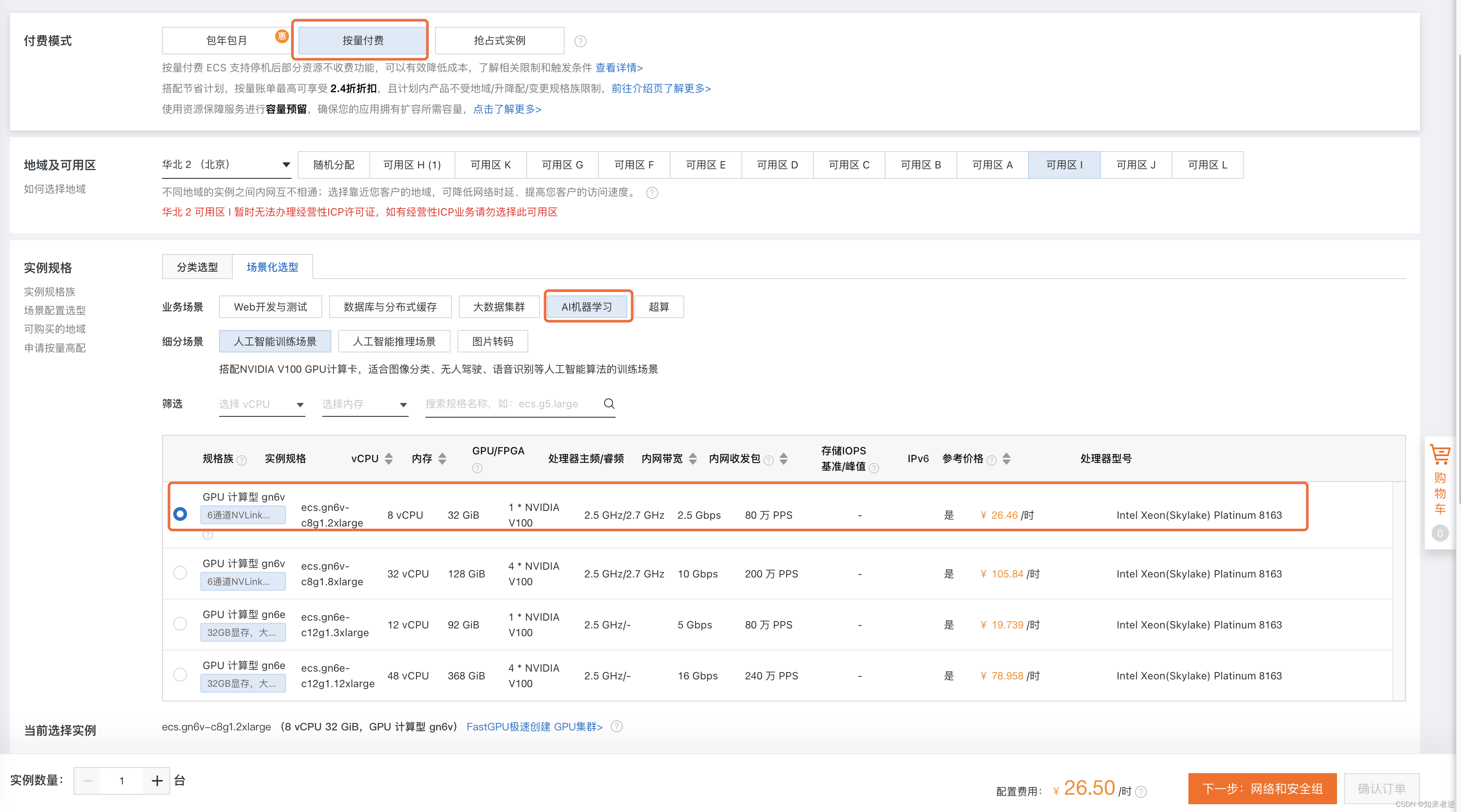
3.选择系统和安装GPU启动
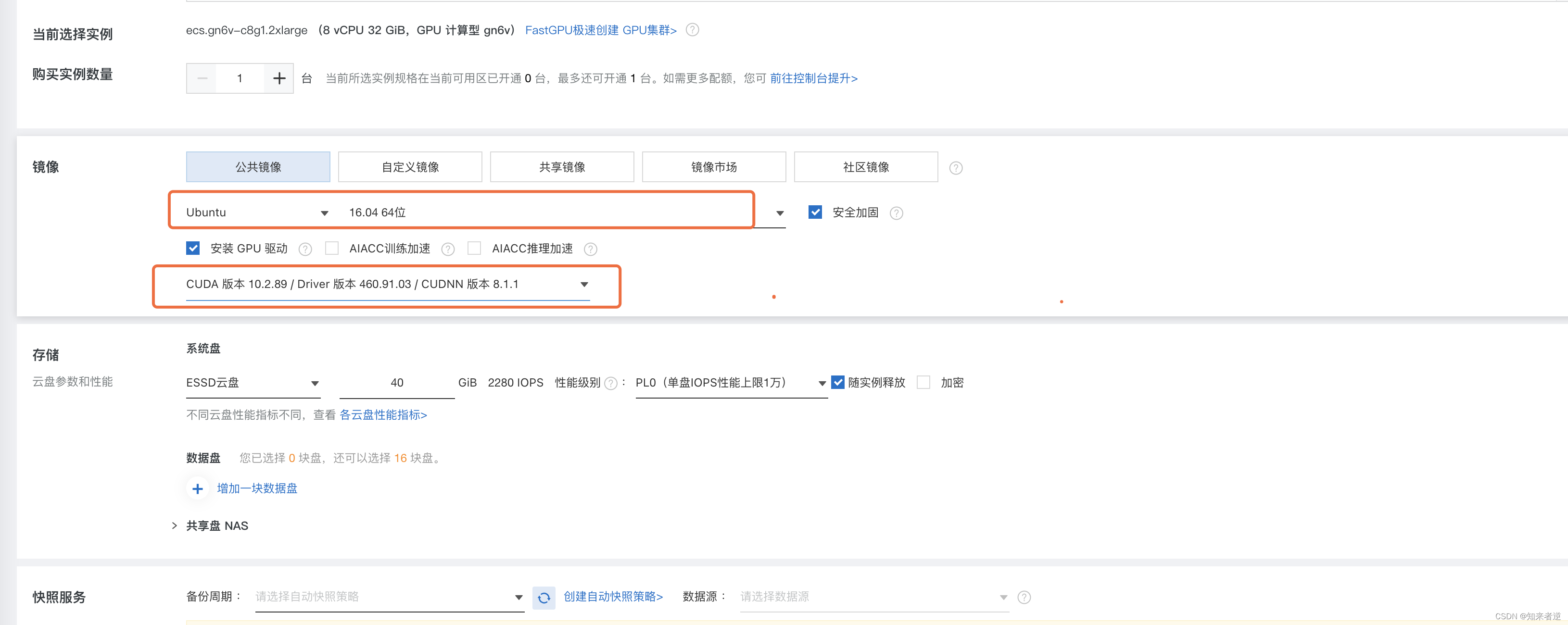
3.选择网络速度(上行下行的速度),之后确认订单就可以了。

二、配置服务器
1.连接服务器,直接点远程连接。
2.切换到root并安装需要的文件。
su
cd
sudo apt-get install vim #vim
sudo apt-get install unzip #解压
sudo apt-get install zip #压缩
sudo apt-get install screen #保护进程会话
三、配置环境(使用Anaconda3)
1.先把Anaconda3下载到自己本地目录,之后用scp上传到服务器
scp data/Anaconda3-5.3.0-Linux-x86_64.sh root@39.xxx.xx.xxx:/home/data/
等待上传完成之后,在服务器上安装Anaconda3,一路确认到安装完成。

把Anaconda3加到环境变量
sudo vim ~/.bashrc
把bin路径加到文件末尾,之后保存文件退出。
export PATH=$PATH:/root/anaconda3/bin

使用环境生效
source ~/.bashrc
2.创建环境
conda create --name yolov5 python=3.7
conda activate yolov5
3.下载算法代码,可以直接从git上下载源码,也可以把自己改好的源码上传。
从git 上下载源码,yolov5s为例:
git下载
git clone https://github.com/ultralytics/yolov5.git
cd yolov5
pip install -r requirements.txt
本地上传与手动安装依赖
scp data/yolov5.zip root@39.xxx.xx.xxx:/home/data/
等上传完成之后,切到服务器
unzip yolov5.zip
cd yolov5
conda install pytorch torchvision cudatoolkit=10.2 -c pytorch
pip install cython matplotlib tqdm opencv-python tensorboard scipy pillow onnx pyyaml pandas seaborn
四、数据处理
1.上传数据集到服务器
scp data/dataset.zip root@39.xxx.xx.xxx:/home/data/yolov5
2.上传完成之后,把数据分成训练集和测试集,这里面使用的coco数据格式,要转成yolov5的格式。
unzip dataset.zip
python generate_txt.py --img_path data/XXXXX/JPEGImages --xml_path data/XXXXX/Annotations --out_path data/XXXXX
数据转换与生成 generate_txt.py源码
import os
import glob
import argparse
import random
import xml.etree.ElementTree as ET
from PIL import Image
from tqdm import tqdm
def get_all_classes(xml_path):
xml_fns = glob.glob(os.path.join(xml_path, '*.xml'))
class_names = []
for xml_fn in xml_fns:
tree = ET.parse(xml_fn)
root = tree.getroot()
for obj in root.iter('object'):
cls = obj.find('name').text
class_names.append(cls)
return sorted(list(set(class_names)))
def convert_annotation(img_path, xml_path, class_names, out_path):
output = []
im_fns = glob.glob(os.path.join(img_path, '*.jpg'))
for im_fn in tqdm(im_fns):
if os.path.getsize(im_fn) == 0:
continue
xml_fn = os.path.join(xml_path, os.path.splitext(os.path.basename(im_fn))[0] + '.xml')
if not os.path.exists(xml_fn):
continue
img = Image.open(im_fn)
height, width = img.height, img.width
tree = ET.parse(xml_fn)
root = tree.getroot()
anno = []
xml_height = int(root.find('size').find('height').text)
xml_width = int(root.find('size').find('width').text)
if height != xml_height or width != xml_width:
print((height, width), (xml_height, xml_width), im_fn)
continue
for obj in root.iter('object'):
cls = obj.find('name').text
cls_id = class_names.index(cls)
xmlbox = obj.find('bndbox')
xmin = int(xmlbox.find('xmin').text)
ymin = int(xmlbox.find('ymin').text)
xmax = int(xmlbox.find('xmax').text)
ymax = int(xmlbox.find('ymax').text)
cx = (xmax + xmin) / 2.0 / width
cy = (ymax + ymin) / 2.0 / height
bw = (xmax - xmin) * 1.0 / width
bh = (ymax - ymin) * 1.0 / height
anno.append('{} {} {} {} {}'.format(cls_id, cx, cy, bw, bh))
if len(anno) > 0:
output.append(im_fn)
with open(im_fn.replace('.jpg', '.txt'), 'w') as f:
f.write('n'.join(anno))
random.shuffle(output)
train_num = int(len(output) * 0.9)
with open(os.path.join(out_path, 'train.txt'), 'w') as f:
f.write('n'.join(output[:train_num]))
with open(os.path.join(out_path, 'val.txt'), 'w') as f:
f.write('n'.join(output[train_num:]))
def parse_args():
parser = argparse.ArgumentParser('generate annotation')
parser.add_argument('--img_path', type=str, help='input image directory')
parser.add_argument('--xml_path', type=str, help='input xml directory')
parser.add_argument('--out_path', type=str, help='output directory')
args = parser.parse_args()
return args
if __name__ == '__main__':
args = parse_args()
class_names = get_all_classes(args.xml_path)
print(class_names)
convert_annotation(args.img_path, args.xml_path, class_names, args.out_path)
五、训练模型
1.训练模型前,要先运行screen,以保证服务终端断线之后还能继续训练。
screen -S yolo
yolo 是一个标记,可以自己随便填,用来分辨该窗口的用途,避免窗口多了自己混淆
screen 常用命令
screen -ls #查看进程
screen -r -d 1020 #后台运行的screen进程
kill -9 1020 #杀死不需要的进程
screen -wipe #检查目前所有的screen作业,并删除已经无法使用的screen作业
2.重新激活环境
conda activate yolov5
3.训练模型
python train.py --cfg models/yolov5s.yaml --data data/ODID.yaml --hyp data/hyp.scratch.yaml --epochs 100 --multi-scale --device 0
六、Linux下常用的一些指令
- scp
从服务器下载文件
scp username@IP:/remote_path/filename ~/local_destination
上传本地文件到服务器
scp ~/local_path/local_filename username@IP:/remote_path
从服务器下载整个目录
scp -r username@servername:/remote_path/remote_dir/ ~/local_destination
上传目录到服务器
scp -r ~/local_dir username@servername:/remote_path/remote_dir
- vim配置
系统级配置文件目录:/etc/vim/vimrc
用户级配置文件目录:~/.vim/vimrc
修改配置文件vimrc或者.vimrc
//显示行号
set nu
- 压缩与解压
zip命令
zip -r file.zip ./*
将当前目录下的所有文件和文件夹全部压缩成file.zip文件,-r表示递归压缩子目录下所有文件.
unzip命令
unzip -o -d /home/sunny file.zip
把file.zip文件解压到 /home/sunny/
-o:不提示的情况下覆盖文件;
-d:-d /home/sunny 指明将文件解压缩到/home/sunny目录下;
其他
zip -d file.zip smart.txt
删除压缩文件中smart.txt文件
zip -m file.zip ./rpm_info.txt
向压缩文件中file.zip中添加rpm_info.txt文件
- 终端代理
export ALL_PROXY=socks5://127.0.0.1:4081 #端口号
curl -L cip.cc #验证是否成功
- 显卡驱动
nvidia-smi
最后
以上就是粗暴战斗机最近收集整理的关于配置使用云服务器训练神经网络模型——在阿里GPU服务器训练yolov5模型的全部内容,更多相关配置使用云服务器训练神经网络模型——在阿里GPU服务器训练yolov5模型内容请搜索靠谱客的其他文章。








发表评论 取消回复