1. time模块
import time
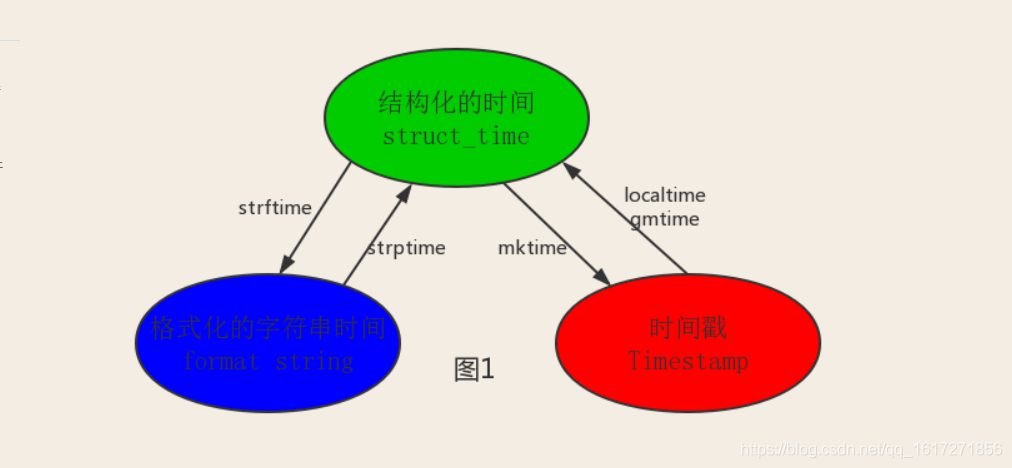
*一*#时间戳--》结构化时间--》格式化的字符串时间
-----------------------------------------------------------------------------
res1=time.localtime(654126574)
print(res1 )
#res1====time.struct_time(tm_year=1990, tm_mon=9, tm_mday=24, tm_hour=5, tm_min=49, tm_sec=34, tm_wday=0, tm_yday=267, tm_isdst=0)
-----------------------------------------------------------------------------
res2=time.strftime('%Y-%m-%d %H:%M:%S',res1)
print(res2)
#res2=====1990-09-24 05:49:34
----------------------------------------------------------------------------
*二*#格式化的字符串时间--》结构化时间--》时间戳
res1=time.strptime('1990-09-24 05:49:34','%Y-%m-%d %H:%M:%S')
print(res1)
#res1====time.struct_time(tm_year=1990, tm_mon=9, tm_mday=24, tm_hour=5, tm_min=49, tm_sec=34, tm_wday=0, tm_yday=267, tm_isdst=-1)
----------------------------------------------------------------------
res2=time.mktime(res1)
print(res2)
#res2=====654126574.0
三#时间加减
import datetime
print(datetime.datetime.now()) #返回系统当前时间格式为2021-08-16 15:11:49.477146
print(datetime.date.fromtimestamp(time.time()) ) # 时间戳直接转成日期格式 2021-08-16
print(datetime.datetime.now() + datetime.timedelta(3)) #当前时间+3天
print(datetime.datetime.now() + datetime.timedelta(-3)) #当前时间-3天
print(datetime.datetime.now() + datetime.timedelta(hours=3)) #当前时间+3小时
print(datetime.datetime.now() + datetime.timedelta(minutes=30)) #当前时间+30分
c_time = datetime.datetime.now()
print(c_time.replace(minute=3,hour=2)) #时间替换
2.radom模块
import random
print(random.random())#(0,1)----float 大于0且小于1之间的小数
print(random.randint(1,3)) #[1,3] 大于等于1且小于等于3之间的整数
print(random.randrange(1,3)) #[1,3) 大于等于1且小于3之间的整数 顾头不顾尾range
print(random.choice([1,'23',[4,5]]))#1或者23或者[4,5] 列表随机选一个
print(random.sample([1,'23',[4,5]],2))#列表元素任意2个组合 列表随机选俩
print(random.uniform(1,3))#大于1小于3的小数,如1.927109612082716
item=[1,3,5,7,9]
random.shuffle(item) #打乱item的顺序,相当于"洗牌" 随机排序
print(item)
####补充知识 print(ord(90))=Z 数字转换阿斯克码
# chr('A')字符转换数字
#生成随机数0-9或者A-Z
def make_radom(k):
dic=''
for i in range(k):
s1=str(random.randint(0,9))
s2=chr(random.randint(65,90))
dic += random.choice([s1,s2])
return dic
print(make_radom(4))
3.OS模块
os.getcwd() #获取当前工作目录,即当前python脚本工作的目录路径
os.chdir("dirname") #改变当前脚本工作目录;相当于shell下cd
os.curdir 返回当前目录: ('.')
os.pardir 获取当前目录的父目录字符串名:('..')
os.makedirs('dirname1/dirname2') 可生成多层递归目录
os.removedirs('dirname1') 若目录为空,则删除,并递归到上一级目录,如若也为空,则删除,依此类推
os.mkdir('dirname') 生成单级目录;相当于shell中mkdir dirname
os.rmdir('dirname') 删除单级空目录,若目录不为空则无法删除,报错;相当于shell中rmdir dirname
os.listdir('dirname') 列出指定目录下的所有文件和子目录,包括隐藏文件,并以列表方式打印
os.remove() 删除一个文件
os.rename("oldname","newname") 重命名文件/目录
os.stat('path/filename') 获取文件/目录信息
os.sep 输出操作系统特定的路径分隔符,win下为"\",Linux下为"/"
os.linesep 输出当前平台使用的行终止符,win下为"tn",Linux下为"n"
os.pathsep 输出用于分割文件路径的字符串 win下为;,Linux下为:
os.name 输出字符串指示当前使用平台。win->'nt'; Linux->'posix'
os.system("bash command") 运行shell命令,直接显示
os.environ 获取系统环境变量
os.path.abspath(path) 返回path规范化的绝对路径
os.path.split(path) 将path分割成目录和文件名二元组返回
os.path.dirname(path) 返回path的目录。其实就是os.path.split(path)的第一个元素
os.path.basename(path) 返回path最后的文件名。如何path以/或结尾,那么就会返回空值。
即os.path.split(path)的第二个元素
os.path.exists(path) 如果path存在,返回True;如果path不存在,返回False path可以是文件也可以是文件夹
os.path.isabs(path) 如果path是绝对路径,返回True
os.path.isfile(path) #如果path是一个存在的文件,返回True。否则返回False path只可以是文件
os.path.isdir(path) #如果path是一个存在的目录,则返回True。否则返回False path只可以是文件夹
os.path.join(path1[, path2[, ...]]) # 将多个路径组合后返回,第一个绝对路径之前的参数将被忽略
os.path.getatime(path) 返回path所指向的文件或者目录的最后存取时间
os.path.getmtime(path) 返回path所指向的文件或者目录的最后修改时间
os.path.getsize(path) 返回path的大小
4.sys模块
sys.argv #命令行参数List,第一个元素是程序本身路径
sys.exit(n) 退出程序,正常退出时exit(0)
sys.version 获取Python解释程序的版本信息
sys.maxint 最大的Int值
sys.path # 返回模块的搜索路径,初始化时使用PYTHONPATH环境变量的值
sys.platform 返回操作系统平台名称
5.shutil模块
shutil.copyfileobj(fsrc, fdst[, length])
将文件内容拷贝到另一个文件中
import shutil
shutil.copyfileobj(open('old.xml','r'), open('new.xml', 'w'))
shutil.copyfile(src, dst)
拷贝文件
shutil.copyfile('f1.log', 'f2.log') #目标文件无需存在
shutil.copymode(src, dst)
仅拷贝权限。内容、组、用户均不变
shutil.copymode('f1.log', 'f2.log') #目标文件必须存在
shutil.copystat(src, dst)
仅拷贝状态的信息,包括:mode bits, atime, mtime, flags
shutil.copystat('f1.log', 'f2.log') #目标文件必须存在
shutil.copy(src, dst)
拷贝文件和权限
import shutil
shutil.copy('f1.log', 'f2.log')
shutil.copy2(src, dst)
拷贝文件和状态信息
import shutil
shutil.copy2('f1.log', 'f2.log')
shutil.ignore_patterns(*patterns)
shutil.copytree(src, dst, symlinks=False, ignore=None)
递归的去拷贝文件夹
import shutil
shutil.copytree('folder1', 'folder2', ignore=shutil.ignore_patterns('*.pyc', 'tmp*')) #目标目录不能存在,
注意对folder2目录父级目录要有可写权限,ignore的意思是排除
拷贝软连接
shutil.rmtree(path[, ignore_errors[, onerror]])
递归的去删除文件
import shutil
shutil.rmtree('folder1')
shutil.move(src, dst)
递归的去移动文件,它类似mv命令,其实就是重命名。
import shutil
shutil.move('folder1', 'folder3')
压缩打包文件
import shutil # 打包这个文件夹
ret = shutil.make_archive('./xxx', 'gztar', root_dir=r'G:pycharmprojectATM')
解压
import tarfile
t=tarfile.open("xxx.tar.gz",'r') #解压的文件
t.extractall(r'G:pycharmprojectday14aaa') #解压完放在这
t.close()
6.json&pickle模块
序列化
- 内存中的数据类型------序列化-------》格式
- 内存中的数据类型《------反序列化-------格式
作用:
- 存档—》pickle
- 跨平台交互数据—》json
# =====================================>json兼容所有语言,但是不支持所有的python数据类型
#
# ====================> dumps--->loads
import json
str_json = json.dumps({"x":1,'y':2,'z':True,'a':None})
print(str_json) #{"x": 1, "y": 2, "z": true, "a": null}
dic = json.loads(str_json)
print(dic) #{'x': 1, 'y': 2, 'z': True, 'a': None}
# ====================> dump--->load
import json
dumps loads 操作的是字符串类型
直接写到a.json里面
json.dump({"x":1,'y':2,'z':True,'a':None},open('a.json',mode='wt',encoding='utf-8'))
读出来一句话搞定
dic = json.load(open('a.json',mode='rt',encoding='utf-8'))
print(dic)
dump load 操作的是字典类型
=====================================> pickle只适用于python,但是可以支持所有python的数据类型
# ====================> dumps--->loads
import pickle
res_pkl = pickle.dumps({"x":1,'y':2,'z':True,'a':None})
print(res_pkl)
dic = pickle.loads(res_pkl)
print(dic)
# ====================> dump--->load
import pickle
pickle.dump({"x":1,'y':2,'z':True,'a':None},open('a.pkl',mode='wb'))
dic = pickle.load(open('a.pkl',mode='rb'))
print(dic)
import pickle
import json
# Python学习交流群:711312441
# res = pickle.dumps({1,2,3,4,5,6})
res = json.dumps({1,2,3,4,5,6})
print(res)
7. shelve模块
shelve模块比pickle模块简单,只有一个open函数,返回类似字典的对象,可读可写;key必须为字符串,而值可以是python所支持的数据类型
import shelve
f=shelve.open(r'sheve.txt')
# f['stu1_info']={'name':'egon','age':18,'hobby':['piao','smoking','drinking']}
# f['stu2_info']={'name':'gangdan','age':53}
# f['school_info']={'website':'http://www.pypy.org','city':'beijing'}
print(f['stu1_info']['hobby'])
f.close()
8.xml模块
xml是实现不同语言或程序之间进行数据交换的协议,跟json差不多,但json使用起来更简单,不过,古时候,在json还没诞生的黑暗年代,大家只能选择用xml呀,至今很多传统公司如金融行业的很多系统的接口还主要是xml。
9. configparser模块
[section1]
k1 = v1
k2:v2
user=egon
age=18
is_admin=true
salary=31
[section2]
k1 = v1
import configparser
config=configparser.ConfigParser()
config.read('a.cfg')
#查看所有的标题
res=config.sections() #['section1', 'section2']
print(res)
#查看标题section1下所有key=value的key
options=config.options('section1')
print(options) #['k1', 'k2', 'user', 'age', 'is_admin', 'salary']
#查看标题section1下所有key=value的(key,value)格式
item_list=config.items('section1')
print(item_list) #[('k1', 'v1'), ('k2', 'v2'), ('user', 'egon'), ('age', '18'), ('is_admin', 'true'), ('salary', '31')]
#查看标题section1下user的值=>字符串格式
val=config.get('section1','user')
print(val) #egon
#查看标题section1下age的值=>整数格式
val1=config.getint('section1','age')
print(val1) #18
#查看标题section1下is_admin的值=>布尔值格式
val2=config.getboolean('section1','is_admin')
print(val2) #True
#查看标题section1下salary的值=>浮点型格式
val3=config.getfloat('section1','salary')
print(val3) #31.0
#改写
import configparser
config=configparser.ConfigParser()
config.read('a.cfg',encoding='utf-8')
#删除整个标题section2
config.remove_section('section2')
#删除标题section1下的某个k1和k2
config.remove_option('section1','k1')
config.remove_option('section1','k2')
#判断是否存在某个标题
print(config.has_section('section1'))
#判断标题section1下是否有user
print(config.has_option('section1',''))
#Python学习交流群:711312441
#添加一个标题
config.add_section('egon')
#在标题egon下添加name=egon,age=18的配置
config.set('egon','name','egon')
config.set('egon','age',18) #报错,必须是字符串
#最后将修改的内容写入文件,完成最终的修改
config.write(open('a.cfg','w'))
10. hashlib模块
什么叫hash:hash是一种算法(3.x里代替了md5模块和sha模块,主要提供 SHA1, SHA224, SHA256, SHA384, SHA512 ,MD5 算法),该算法接受传入的内容,经过运算得到一串hash值
hash值的特点是:
- 只要传入的内容一样,得到的hash值必然一样=====>要用明文传输密码文件完整性校验
- 不能由hash值返解成内容=======》把密码做成hash值,不应该在网络传输明文密码
- 只要使用的hash算法不变,无论校验的内容有多大,得到的hash值长度是固定的
11.suprocess模块
import subprocess
#输入cmd指令 stdout等于正确管道执行,stderr=错误管道执行
obj=subprocess.Popen("tasklist",shell=True,
stdout=subprocess.PIPE,
stderr=subprocess.PIPE,
)
print(obj)
print(obj.stdout.read().decode('gbk')) #正确执行,都需要解码指定gbk
print(obj.stderr.read().decode('gbk')) #错误执行,都需要解码指定gbk
12.logging模块
#level等级设置
CRITICAL = 50 #FATAL = CRITICAL
ERROR = 40
WARNING = 30 #WARN = WARNING
INFO = 20
DEBUG = 10
NOTSET = 0 #不设置
#字典里面主要设置这几个
logger:产生日志的对象
Filter:过滤日志的对象
Handler:接收日志然后控制打印到不同的地方,FileHandler用来打印到文件中,StreamHandler用来打印到终端
Formatter对象:可以定制不同的日志格式对象,然后绑定给不同的Handler对象使用,以此来控制不同的Handler的日志格式
#formatters里面的打印到屏幕或者文件设置的参数
%(name)s:Logger的名字,并非用户名,详细查看
%(levelno)s:数字形式的日志级别
%(levelname)s:文本形式的日志级别
%(pathname)s:调用日志输出函数的模块的完整路径名,可能没有
%(filename)s:调用日志输出函数的模块的文件名
%(module)s:调用日志输出函数的模块名
%(funcName)s:调用日志输出函数的函数名
%(lineno)d:调用日志输出函数的语句所在的代码行
%(created)f:当前时间,用UNIX标准的表示时间的浮 点数表示
%(relativeCreated)d:输出日志信息时的,自Logger创建以 来的毫秒数
%(asctime)s:字符串形式的当前时间。默认格式是 “2003-07-08 16:49:45,896”。逗号后面的是毫秒
%(thread)d:线程ID。可能没有
%(threadName)s:线程名。可能没有
%(process)d:进程ID。可能没有
%(message)s:用户输出的消息
#在settings配置文件里面配置
LOGGING_DIC = {
'version': 1,
'disable_existing_loggers': False,
'formatters': {
'格式1': { #格式对象名字
'format': '%(asctime)s %(name)s %(filename)s:%(lineno)d %(levelname)s:%(message)s' #参数
},
'格式2': { #格式对象名字
'format': '%(asctime)s :%(message)s' #参数
},
},
'filters': {},
'handlers': {
'屏幕': {
'level': 'DEBUG',
'class': 'logging.StreamHandler', # 打印到屏幕
'formatter': '格式2'
},
'文件': {
'level': 'DEBUG',
'class': 'logging.FileHandler', # 保存到文件
'formatter': '格式1',
'filename': DESC_dir,
'encoding': 'utf-8',
},
},
'loggers': {
# '交易日志': {
# 'handlers': ['屏幕','文件'],
# 'level': 'DEBUG',
# 'propagate': False,
# },
'': { #不写名字找不到的话就指定这个
'handlers': ['屏幕','文件'],
'level': 'DEBUG',
'propagate': False,
},
},
}
#在lib的common下重写log方法
import logging.config
from conf import settings
logging.config.dictConfig(settings.LOGGING_DIC)#指定配置文件的字典
def log(msg,name,level='info'): #msg传进来的文字,name=logger对象名字 level等级
logger = logging.getLogger(name) #获取logger对象名字 拿着这个名字去配置文件寻找找不到用没名字那个
if level == 'info':
logger.info(msg) #调方法
elif level == 'debug':
logging.debug(msg)
elif level == 'warn':
logger.warning(msg)
elif level == 'error':
logger.error(msg)
elif level == 'critical':
logger.critical(msg)
最后
以上就是虚心黑夜最近收集整理的关于Python中12个常用模块的使用教程的全部内容,更多相关Python中12个常用模块内容请搜索靠谱客的其他文章。








发表评论 取消回复