Google guide :http://www.googleguide.com/advanced_operators_reference.html
相关资料:
- :http://www.bubuko.com/infodetail-2292041.html
- :http://www.pinginglab.net/open/course/9
- :https://download.csdn.net/download/freeking101/10756254
- :https://zhuanlan.zhihu.com/p/400365865
如何用好谷歌等搜索引擎?
如何使用 Google 高级搜索技巧
1、有哪些好用的搜索引擎?
From:https://www.runningcheese.com/search-engines
当进行搜索时,搜索结果很大一部分因素是取决于搜索引擎,这就好比 "在有鱼的地方钓鱼"。特别是在一些 "高精尖" 搜索时,谷歌、百度往往不能奏效,使用专业的、垂直的搜索引擎,往往就能找到我们要的答案。那除了百度,还有哪些好用的搜索引擎?
搜索引擎大全
:http://www.eryi.org/
虫部落 快搜:https://search.chongbuluo.com/
站长之家 工具导航:https://ntool.chinaz.com/tools/nav
综合搜索
- 谷歌 ( Google ):https://www.google.com/
- 必应 ( bing ) 搜索:https://cn.bing.com/
- 百度 ( baidu ):https://www.baidu.com/
- 搜狗搜索,国内唯一能和百度形成竞争的引擎:https://www.sogou.com/
- 俄罗斯第一大搜索引擎,世界第5大搜索引擎:https://yandex.com/
- 俄罗斯版的雅虎,基于 Yandex 的无过滤搜索引擎,可以设置为英文:https://www.rambler.ru/
- ddg 匿名搜索引擎,宣称不会收集用户数据:https://duckduckgo.com/
- 法国搜索引擎。( 搜索时,可以指定国家进行搜索 ):https://www.qwant.com/
- 环保搜索引擎,通过算法优化整合Bing和Yahoo的搜索结果,广告的盈利捐给公益事业:https://www.ecosia.org/
- 德国搜索引擎,有自己独立的搜索引擎库:https://fireball.com/
- 韩国搜索引擎,韩国的 "百度":https://www.naver.com/
- 日本喜欢用谷歌和雅虎
特色搜索引擎
- 知识搜索引擎,理解你的搜索,经过知识库的分析计算后,返回直接的和可视化的结果。:https://www.wolframalpha.com/
- 简洁、快速、不追踪不纪录隐私的搜索引擎,很大程度上可以替代谷歌:https://duckduckgo.com/
- 自带网页预览功能的搜索引擎,把搜索结果通过页面预览的方式来展示给用户:https://peekier.com/
- 多引擎搜索,中国版 DDG,将多个搜索引擎的结果放在一起显示:https://mijisou.com/
- 谷歌图片搜索,搜索谷歌图片:https://www.google.com/imghp
元搜索引擎
- 元搜索引擎,元搜索引擎里的老大哥,Dogpile 和 WebCrawler 都是它旗下的产品:https://infospace.com/
- 元搜索引擎,将查询请求主要递交给多个搜索引擎,经过智能处理后返回给用户:https://www.webcrawler.com/
- 元搜索引擎,对检索结果进行二次加工,如对检索结果去重、重新排序等:https://www.dogpile.com/
站内搜索
- 关键字 site:www.baidu.com
- 关键字 site:www.google.com
2、google 搜索 高级指令
google 所有 搜素指令
下表列出了与每个 Google 搜索服务一起使用的搜索运算符。
| 搜索服务 | 搜索运算符 |
|---|---|
| 网络搜索 | allinanchor:,allintext:,allintitle:,allinurl:,cache:,define:,filetype:,id:,inanchor:,info:,intext:,intitle:,inurl:,link:,related:,site: |
| 图片搜寻 | allintitle:,allinurl:,filetype:,inurl:,intitle:,site: |
| 团体 | allintext:,allintitle:,author:,group:,insubject:,intext:,intitle: |
| 目录 | allintext:,allintitle:,allinurl:,ext:,filetype:,intext:,intitle:,inurl: |
| 新闻 | allintext:,allintitle:,allinurl:,intext:,intitle:,inurl:,location:,source: |
| 产品搜寻 | allintext:, allintitle: |
注意:每个条目通常包括语法,功能、示例。如果在冒号(
:)和后续查询词之间加空格,则某些搜索运算符将无法正常工作。所以请始终将关键字放在冒号旁边,即在冒号后不需要空格。许多搜索运算符可以出现在查询中的任何位置。在示例中,我们将搜索运算符放置在尽可能右侧的位置。我们这样做是因为“高级搜索”表单以这种方式编写查询。同样,这样的约定使更清楚地知道哪些运算符与哪些术语相关联。

以下是搜索运算符的字母列表
allinanchor:
使用
allinanchor:查询时,Google会将结果限制在页面链接上的 定位文本中包含查询词 的页面。例如,[ allinanchor: best museums sydney ]将仅返回页面链接链接文本中包含“ best”,“ museums”和“ sydney”的页面。
锚文本是链接到另一个网页或当前页面上其他位置的页面上的文本。单击锚文本时,您将被带到该页面或链接到该页面的位置。在使用
allinanchor:查询时,请勿包括任何其他搜索运算符。allinanchor:也可以通过 “出现次数” 下的“高级Web搜索”页面使用的功能。
allintext:
使用 allintext:查询时,Google只会显示 页面文本中包含查询词 的 页面。例如,[ allintext: travel packing list ] 将仅返回在页面文本中出现单词“ travel”,“ packing”和“ list”的页面。
allintitle:
使用
allintitle:查询时,Google只会显示 标题中包含查询词 的结果。例如,[ allintitle: detect plagiarism ] 将仅返回标题中包含 “ detect” 和 “ plagiarism” 字样的文档。也可以通过“高级网页搜索”页上“事件”下获得此功能。
网页的标题 通常显示在浏览器窗口的顶部和Google搜索页面的第一行中。网站的作者使用 HTML TITLE 元素指定页面的标题。网页中只有一个标题。
在使用
allintitle:查询时,请勿包括任何其他搜索运算符。allintitle:的功能也可以通过“出现次数”下的“高级Web搜索”页面获得。在“图像搜索”中,
allintitle:将返回名称中包含您指定的术语的文件中的图像。在Google新闻中,
allintitle:将返回标题包括您指定的术语的文章。
allinurl:
使用
allinurl:查询时,Google只显示 URL中 包含查询词的结果。例如,[ allinurl:google faq ] 将仅返回URL中包含单词“ google”和“ faq”的文档。在 URL中,单词经常一起运行。当您使用allinurl:时,它们不必一起运行。
在Google新闻中,
allinurl:将返回标题包括您指定的术语的文章。统一资源定位器(通常称为URL)是指定文件在Internet上的位置的地址。
在使用
allinurl:查询时,请勿包括任何其他搜索运算符。allinurl:也可以通过“出现次数”下的“高级Web搜索”页面使用的功能。
author:
使用
author:查询中,Google只会显示包含指定作者的新闻组文章。作者可以是 全名、部分姓名、电子邮件地址。例如,[ children author:john author:doe ] 或者 [ children author:doe@someaddress.com ] 返回包含John Doe或doe@someaddress.com的单词“ children”的文章。
Google会精确搜索您指定的内容。如果您的查询包含[ author:” John Doe” ](带引号),则Google不会找到作者指定为“ Doe,John”的文章。
cache:
cache:url将查询 Google 的网页缓存,而不是页面的当前版本。例如,[ cache:www.eff.org ] 将显示Google的电子前沿基金会主页的缓存版本。注意:不要在
cache:和 URL (网址) 之间放置空格。。。在网页的缓存版本中,Google会突出显示查询中出现在
cache:搜索运算符之后的字词。例如,[ cache:www.pandemonia.com/flying/ fly diary ] 将显示Google的Flight Diary的缓存版本,其中Hamish Reid的文档记录了学习如何飞行的内容,并突出显示了“ fly”和“ diary”。
define:
使用
define:查询时,Google会显示 关键字 在网络页面上的定义。该高级搜索运算符对于查找单词,短语和首字母缩写词的定义很有用。例如,[ define:blog ]将显示“ Blog”(网络日志)的定义。
filetype:
ext:是filetype:的别名在使用
filetype:suffixsuffix查询时,Google会将结果限制为名称以结尾的页面(即文件)。例如,[ web page evaluation checklist filetype:pdf ] 将返回与 “web”、 “page”、 “evaluation”、“checklist” 相匹配的 pdf 文件。
也可以使用 or 运算符将结果限制为名称以pdf和doc结尾的页面,例如[ email security filetype:pdf OR filetype:doc ]。
如果您未在“高级搜索表单”或filetype:运算符中指定文件格式,则Google会搜索各种文件格式;例如,请参阅“文件类型转换”中的表。
group:
在使用
group:查询中,Google会将搜索结果限制为某些 论坛或子区域的新闻组文章。例如,[ sleep group:misc.kids.moderated ]将返回组misc.kids.moderated中包含单词“ sleep”的 文章,而[ sleep group:misc.kids ]将返回分区misc.kids中的文章,包含“睡眠”一词。
inanchor:
在使用
inanchor:查询时,Google会将结果限制为包含您在锚文本或页面链接中指定的查询词的页面。例如,[ restaurant inanchor:gourmet ]将返回以下页面,其中链接到页面的锚文本中包含单词“ gourmet”,而页面中包含单词“ restaurants”。
info:
id:是info:的别名。在使用 info:URL 查询时,将显示有关相应网页的一些信息。例如,[ info:gothotel.com ] 将显示有关国家酒店目录GotHotel.com主页的信息。
注意:
info:和 网页URL 之间必须没有空格。也可以通过直接在Google搜索框中键入网页URL来获得此功能。
intext:
只显示页面中包含关键字的页面中。例如,[ Hamish Reid intext:pandemonia ]将返回在文本中提及“ pandemonia”一词的文档,并在文档中的任何位置(无论是否文本)都提及名称“ Hamish”和“ Reid”。注意:
intext:和后面的单词之间不得有空格。将
intext:查询中的每个单词放在前面等同于将查询放在allintext:前面,例如[ intext:handsome intext:poets ]与 [ allintext: handsome poets ]相同。
intitle:
该查询将结果限制为标题中包含的文档。例如,[ flu shot intitle:help ]将返回在其标题中提及“ help”一词的文档,并在文档中的任何位置(无论是否有标题)提及“ flu”和“ shot”一词。
注意:
intitle:和以下单词之间不得有空格。将
intitle:查询中的每个单词放在前面就等于将其放在allintitle:查询中,例如[ intitle:google intitle:search ]与[ allintitle:google search ]相同。insubject: 等同于 intitle:
例如,[ insubject:”falling asleep” ] 将返回主题中包含 “falling asleep” 短语的Google网上论坛文章。
inurl:
在使用
inurl:查询时,Google只会显示 URL中包含该单词的页面。例如,[ inurl:print site:www.googleguide.com ]在Google指南中搜索其中URL包含单词“ print”的页面。它会找到位于Google指南网站上名为“ print”的目录或文件夹中的pdf文件。
查询[ inurl:healthy eating ]将返回在其URL中提及“healthy”的文档,并在文档中的任何位置提及“eating”的文档。
注意:
inurl:和以下单词之间不得有空格。将
inurl:查询中的每个单词放在前面就等于将其放在allinurl:查询中,例如,[ inurl:healthy inurl:eating ]与[ allinurl:Healthy eating ]相同。在URL中,单词经常一起运行。当您使用inurl:时,它们不必一起运行。
link:
查询显示指向该页面的页面。例如,要查找指向Google指南首页的页面,请输入:
link:URL,示例:[ link:www.googleguide.com ]注意:根据Google的文档,“您不能将链接结合在一起:搜索和常规关键字搜索。”
查找不在Google自己网站上的Google主页链接:[ link:www.google.com -site:google.com ]
查找不在其自身网站上的UK Owners Direct主页的链接:[ link:www.www.ownersdirect.co.uk -site:ownersdirect.co.uk ]
location:
如果您
location:在Google新闻查询中包含,则仅返回您指定位置的文章。例如,[ queen location:canada ]将显示与来自加拿大站点的“queen”一词匹配的文章。美国的两个字母的州缩写与美国的各个州相匹配,加拿大的两个字母的省缩写(例如,新斯科舍省的NS)也可以使用-尽管某些省份的在线报纸很少,所以您可能不会获得很多结果。也可以使用其他两个字母的缩写,例如UK表示UK。
movie:
如果您
movie:将查询内容包括在内,则Google会找到与电影相关的信息。有关示例,请参见Google的博客。
related:
该查询将列出与您指定的网页相似的网页。例如,[ related:www.consumerreports.org ]将列出与“消费者报告”主页相似的网页。
related:URL注意:在
related:和网页网址之间不要包含空格。您还可以从Google主要结果页面上的“相似页面”链接以及“高级搜索”页面的“特定于页面的搜索”区域的相似选择器中找到相似的页面。如果您希望经常搜索相似的页面,请考虑安装GoogleScout浏览器按钮,以搜索相似的页面。
site:
在使用
site:查询时,Google只会对指定的网站进行搜索。例如,[ admissions site:www.lse.ac.uk ] 将显示伦敦政治经济学院网站的招生信息,而 [ peace site:gov ] 将在该
.gov域中找到有关和平的页面。您可以指定带或不带句点的域,例如:.gov 或者 gov。
注意:请勿在“ site:”和域之间包含空格。
您可以使用许多的搜索运算符的结合基本的搜索运算符:+、-、OR、"空格"。
例如,要从
microsoft.com以外的所有站点查找有关Windows安全性的信息,请输入:[ windows security –site:microsoft.com ]您还可以通过“高级搜索”页面上的域选择器将结果限制为站点或域。
source:
使用
source:查询时,搜索指定ID的新闻来源的文章。例如, [ election source:new_york_times ]将返回出现在《纽约时报》上的带有“选举”一词的文章。要查找新闻来源ID,请输入一个查询,其中包括术语和您要查找的出版物的名称。您也可以在“高级新闻搜索”表单的“新闻来源”字段中指定出版物名称。您可以在查询框中的
source:搜索运算符后面找到新闻来源ID 。例如,假设您在“新闻来源”框中输入出版物名称Ha'aretz,然后单击“ Google搜索”按钮。出现结果页面,其搜索框包含[ 和平来源:ha_aretz__subscription_ ]。这意味着新闻源ID为ha_aretz__subscription_。此查询将仅返回以色列报纸Ha'aretz中包含“和平”一词的文章。
weather
如果您输入带有单词
weather和城市或位置名称的查询,如果Google识别出该位置,则预测将显示在结果页面的顶部。否则,您的结果通常将包含指向具有该天气情况和该位置的天气预报的站点的链接。由于天气不是高级运算符,因此无需在该词后加冒号。例如,[ weather Sunnyvale CA ]将返回加利福尼亚州森尼韦尔的天气,[ weather 94041 ]将返回包含邮政编码(美国邮政编码)94041(加利福尼亚州山景城)的城市的天气。
搜索指令 --- 基础篇
intitle: 搜索网页标题中包含有特定字符的网页。
用法:[intitle]+[:]+[关键字1]+[空格]+[关键字2]
示例:intitle:后台 // 只搜索网页标题中包含 "后台" 的网页
示例:intitle:login admin // 搜索标题包含 "login" 和 "admin" 的网页
示例:出国留学 intitle:美国 // 搜索页面中包含 "出国留学",且标题中包含 "美国" 的网页示例:intitle:"Index Of"
allintitle: 搜索返回的是页面标题中包含多组关键词的文件。(百度不支持)
搜索标题中既包含 "SEO" 也包含 "搜索引擎优化" 的页面。
示例:allintitle:SEO 搜索引擎优化
示例:intitle:SEO intitle:搜索引擎优化
inurl: 搜索 URL中包含指定字符的页面。就是 url 中包含 "搜索词" 的页面。
用法:[inurl]+[:]+[关键字1]+[空格]+[关键字2]
示例:inurl:admin // 搜索 URl 中包含 admin 的页面
示例:inurl:mp3 // 搜索url中包含mp3的所有页面
示例:恋人心 inurl:mp3 // 搜索url中包含mp3关键字的页面,并且页面中包含 恋人心的网页 (使用了 "与" 运算)
示例:inurl:china news // 搜索url中即包含"china"又包含"news"的网页。
allinurl: 搜索 url 中包含多个关键词的页面。allinurl 是排他性指令
示例:allinurl:byr jobs // 等价于:inurl:byr inurl:jobs
intext: 搜索网页正文内容中包含指定关键字的页面。(百度不支持)
示例:intext:操作系统 // 搜索页面中包含 "操作系统" 的页面
示例:intext:SEO方法 // 搜索页面中包含 "SEO方法" 的页面
allintext: 搜索页面正文中包含多组关键词的页面。排他性指令。(百度不支持)
// 搜索正文中既包含 "SEO",也包含 "搜索引擎优化" 的页面。
示例:allintext:SEO 搜索引擎优化 // 等价于 intext:SEO intext:搜索引擎优化
filetype: 搜索指定类型文件。
基本查询语法:[关键字1]+[空格]+[filetype]+[:]+[文件类型标识]
百度支持的文件格式有:pdf,doc,xls,ppt,rtf,all。其中all表示所有百度支持的文件类型。
Google则支持所有能索引的文件格式,包括 HTML,PHP等。
示例:filetype:pdf // 搜索 pdf 文档。
示例:filetype:pdf SEO // 搜索包含SEO这个关键词的PDF文件。
示例:photoshop实用技巧 filetype:doc // 搜索包含 "photoshop实用技巧" 的doc文件。示例:filetype:pdf
示例:kali filetype:pdf
site: 在一个网址前加 "site:",可以限制只搜索某个具体网站、网站频道、或某域名内的所有网页,即在指定网站内搜索 。
用法:[关键字]+[site]+[:]+[网站名称或国别]
"site:"后不能有 "http://" 前缀或 "/" 后缀,网站频道只局限于 "频道名.域名" 方式,不能是 "域名/频道名" 方式。示例:site:baidu.com // 搜索所有在 baidu.com 下的页面
示例:site:sina.com.cn // 搜索 sina.com.cn 下的所有网页
示例:site:blog.sina.com.cn // 搜索 子域名blog.sina.com.cn 的所有网页
示例:mp3 site:music.163.com // 在 music.163.com 站点下搜索包含mp3的网页
示例:免费短信 site:www.baidu.com // 在 www.baidu.com 网站内搜索包含 "免费短信" 的页面
示例:intel site:com.cn // 在域名"com.cn"的网站内搜索包含 "intel" 的页面
movie: 返回跟查询关键词相关的电影信息。
示例:movie:变形金刚
info: 查询网站的一些信息。
示例:info:bbs.byr.cn 返回一个结果列表,列表的选项是这个网站的某一方面的信息。
info=cache+related+link+site+intext+intitle
"" 英文的双引号
代表完全匹配,使关键词不分开,顺序都不能变。
在百度中也可以使用书名号《》或者 [],也可以让百度不拆分关键字。
示例:[计算机]
+ 或者 空格 。逻辑 "与",减小搜索范围。加号(或者减号)前面必须是空格,加号(或者减号)后面没有空格,紧跟着要排除的词。
示例:小说 金庸 等价于 小说+金庸 或者 小说 +金庸
示例:注册会计师考试 -推广 -推广链接 // 搜索结果中去除 "推广" 和 "推广链接"的页面。示例:写真 自拍 图片 intext:mm
示例:自拍 写真 intext:图片
| "或" 运算。增大搜索范围
示例:写真 | 图片 // 搜索包含 "写真" 或者 包含 "图片" 的网页。只要包含任意一个即可。
- 减号。"非" 运算,搜索不含特定查询词的页面。减号与前一个关键词之间一定要有一个空格,与后一个关键词之间一定不能有空格。搜索结果为:匹配前一个关键词,但不匹配后一个关键词。
示例:武侠小说 -古龙 // 搜索包含 "武侠小说" 但是不包含 "古龙" 的网页
weather: 查询某一地区或城市的天气。例如:weather:beijing
* 星号,表示通配符。可以匹配任意字符串。百度不支持通配符 ? 和 * 但是谷歌支持。
示例:搜索*擎 // 搜索结果页面中不仅有 "搜索引擎",还有 "搜索巨擎" 之类的页面。
define: 查询关键词的词义,起的是字典的作用。
例如:define:computer,支持汉字!
inanchor: 搜索锚点文字中包含搜索词的页面。(百度不支持)。
比如在谷歌搜索 "inanchor:点击这里",返回结果页面本身并不一定包含 "点击这里" 这4个字,而是指向这些页面的链接锚文字中出现了 "点击这里" 这4个字。
allinanchor、inanchor 是排他性指令。
link: 搜索某个链接的反向链接(反向链接是指所有来自其他页面能够跳转到目标URL的链接,包括站内和站外)
Google的link指令返回的链接只是google索引库中的一部分,而且是近乎随机的一部分,几乎没啥用。
百度则不支持link:指令。
示例:link:sina.com.cn // 返回的就是 sina.com.cn 的反向链接。
related:仅 Google 支持,搜索与所给网站类似的网站。即查询与某个网站相关联或者相类似的页面。这种关联到到底指的是什么,Google并没有明确说明,一般认为指的是有共同外部链接的网站。
它会返回Google认为的可能和你提供的网站类似的其他网站。
例如:related:bbs.gfan.com,会返回安卓巴士,eoe社区,91等站点,但不会返回机锋网。
其实这个命令Google经常在用,比如搜一个东西,Google除了返回给我结果,还会在结果下面给我们返回一些相关的词条。示例:related:dunsh.org
domain: 查找跟某一网站相关的信息
// 查询在网站内容里面包含了www.bing.com信息的网站
示例:domain:www.bing.com
.. // 表示数值范围。例如:手机 2000..3000 元,注意 "3000" 与 "元" 之间必须有空格。另外,也可以是三个点。
常用
keyword intitle:标题关键字 // 标题搜索
keyword site:www.baidu.com // 站内搜索
keyword inurl:video // 链接搜索
"keyword"(双引号) 或《keyword》 // 精确搜索, 常用与搜索书籍小说,影视内容等。
keyword filetype:pdf // Filetype过滤文件类型
keyword +keyword // "与" 搜索,其实就是+搜索
keyword|keyword|keyword // "或" 搜索
keyword -keyword // "非" 搜索,其实就是-搜索
搜索指令 --- 进阶篇
GHDB ( 实时更新搜索用法 ):https://www.exploit-db.com/google-hacking-database
示例:intitle:"Index Of"
- 查找后台地址:site:域名
- inurl:login|admin|manage|member|admin_login|login_admin|system|login|user|main|cms
- 查找文本内容:site:域名 intext:管理|后台|登陆|用户名|密码|验证码|系统|帐号|admin|login|sys|managetem|password|username
- 查找可注入点:site:域名 inurl:aspx|jsp|php|asp
- 查找上传漏洞:site:域名 inurl:file|load|editor|Files
- 查看脚本类型:site:域名 filetype:asp/aspx/php/jsp
- 迂回策略:inurl:cms/data/templates/images/index/
- 网络设备关键词:intext:WEB Management Interface for H3C SecPath Series
- 存在的数据库:site:域名 filetype:mdb|asp|#
intitle:index.of filetype:log
intitle:error intitle:warning
intitle:index.of
error|warning
login|logon
username|userid|ID
password|passcode
admin|administrator
-ext:html|-ext:htm|-ext:asp|-exp:php
inurl:temp|inurl:tmp|inurl:backup|inurl:bak
intitle:"index of" "catalina.out"
intitle:"index of" linkedin-api
intext:"SQL" && "DB" inurl:"/runtime/log/"
intitle:"index of" zoom-api
intitle:"index of" "private_key.pem"
site:*.com "index of" error_logs
site:com.* intitle:"index of" *shell.php
allintitle:index of "/icewarp"
intitle:"index of" ".env" OR "pass"
inurl:*org intitle:"index of" "docker-compose"
intitle:"index of /" "sqlite.db"
# Description: site:gov.in filetype:xlsx "password"
"index of" filetype:db
site:gov.* intitle:"index of" *.pptx
intitle:"SAP Web Application Server" logon
intitle:"index of" instagram-api
site:com.* intitle:"index of" *.admin.password
ext:java intext:"import org.apache.logging.log4j.Logger;"
intitle:"index of" " admin.php "
intitle:"index of" "wp-upload"
intitle:"index of "cloud-config.yml"
Various Online Devices Dork
inurl:webcam site:skylinewebcams.com inurl:roma
inurl:"/sap/admin/public"
site:com.* intitle:"index of" *.sql
intitle:"index of" "printenv.pl
inurl:/_vti_bin/ ext:asmx
"This system" inurl:login
site:.com intitle:"Admin portal"
site:cloudfront.net inurl:d
allintext:wp-includes/rest-api
intitle:"index of" " index.php?id= "
intitle:"index of" aws/
sap/bc/ui5_ui5/ui2/ushell/shells/abap/FioriLaunchpad.html -site:sap.com
intitle:"index of" google-api-php-client
intitle:"index of" " *admin-login.php "
intitle:"Login. MicroStrategy"
intitle:"index of" " *config.php "
intitle:index of "aws/credentials"
site:org.* intitle:"index of" * resources
site:.com intitle:"index of" /ipa
intitle:"index of "docker-compose.yml"
inurl:7001/console intitle:weblogic
intitle:"index of" sns-login
intitle:"index of" facebook-api
site:gov.* intitle:"index of" *.db
site:.com intitle:"index of" /paypal
intext:"/webdynpro/resources/sap.com/"
intitle:"index of" ("passenger.*.log" | "passenger.log" | | "production.log" )
intitle:"index of" /gscloud
intitle:"Index of" people.1st
intitle:"Index of" htpasswd
inurl:.com index of apks
site:.com intitle:"index of" /payments.txt
intitle:index.of.etc
inurl:"ucp.php?mode=login"
intitle:"HFS" AND intext:"httpfileserver 2.3" AND -intext:"remote"
intitle:"ST Web Client"
inurl:/doc/page/login.asp?
index of "fileadmin/php"
site:gov intitle:"index of" *.data
site:com.* intitle:"index of" *.admin
intitle:"Login to SDT-CS3B1"
inurl:"*admin|login" site: gov
intitle:"Index of" etc/shadow
intext:"token" filetype:log "authenticate"
"index of" filetype:sql
inurl:.com index of movies
intitle:"index of" "keystore.jks"
site:gov.* intitle:"index of" *.xls
allintitle:index of "/microweber"
inurl:/RDWeb/Pages/en-US/ filetype:aspx ~login
Fwd: site:*/opac/login
inurl:/_layouts "[To Parent Directory]"
site:gov.* intitle:"index of" *.doc
intitle:"index of" " wp-includes "
inurl:"opac/login " site:.edu
intitle:" SyncThru Web Service" intext:"Supplies Information"
intitle: index of "awstats"
"index of" :.py
inurl:/admin/login.php intitle:("Iniciar sesion" OR "hacked")
intitle:"Index of" pwd.db
inurl:/intranet/signup
inurl:/sap/bc/webdynpro/ logon
=?UTF-8?Q?=E2=80=9CIndex_of_/backup=E2=80=9D?=
intitle:[TM4Web] inurl:login.msw
site:com.* intitle:"index of" *.db
=?UTF-8?Q?intitle:"Index_of=E2=80=9D_user=5Fcarts_OR_user_=5Fcart.?=
inurl: document/d intext: ssn
"index of" filetype:env
intitle:"index of" "man.sh"
site:amazonaws.com inurl:elb.amazonaws.com
inurl:wp-content/plugins/reflex-gallery/
intitle:index of "error_log"
site:gov.* intitle:"index of" *.shell
site:com intitle:index of ..................etcpasswd
intitle:"index of" include/
index of /wp-admin.zip
intitle:"Index of /" inurl:(resume|cv)
site:.edu intext:"index of" "shell"
service._vti_pvt.index
inurl:gitlab "AWS_SECRET_KEY"
intitle:index of /backup private
intitle:iDRAC* inurl:login.html
intitle:"index of" "db.py"
intitle:"index of" filetype:sql
"index of" :.env
site:gov.* intitle:"index of" *.php
intitle:Index of "pyvenv.cfg"
intitle:"index of" "files.pl"
inurl:"microstrategy/servlet/mstrweb"
intitle:"Apache Flink Web Dashboard"
intitle:"login" intext:"authorized users only"
intitle:"index of" "java.log" | "java.logs"
intitle:"index of" "admin-shell"
intitle:" index of "/order/status"
intitle:"index of" twitter-api-php
intitle:index of ./jira-software
intitle:"index of" .ovpn
intitle:"ManageEngine Desktop Central 10" AND (inurl:configurations OR inurl:authorization)
google 的指令集
From:http://blog.fens.me/google-command/
常用的搜索命令,使用热度依次递减
搜索不同国家网站
inurl:tw 只搜索台湾的网站
inurl:jp 只搜索日本的网站Index of/ 使用它可以直接进入网站首页下的所有文件和文件夹中。
site 指定搜索的某个网站。示例: mp3 site:www.163.com
filetype 搜索指定的文件类型,如:.bak,.mdb,.inc等。示例:kali filetype:pdf空格 或 + 逻辑与。一般用空格代替,还可以用 + 代替
| 或者 OR 逻辑或
- 把某个字忽略,例子:新加 -坡。
~ 同意词。
. 单一的通配符。
* 通配符,可代表多个字母。
"" 精确查询。intitle 返回所有网页标题中包含关键词的网页。一次只能搜索一个关键词。
inurl 返回的结果的 url 中包含关键词。一次只能搜索一个关键词。allinurl 结果的url中包含多个关键词。allinurl是排他性指令,不能与其他指令结合使用。
示例: allinurl:byr jobs 等于inurl:byr inurl:jobs
allintitle 在标题中同时包含多个关键词。allintitle 属于排他性指令,不能与其他指令结合使用。
示例: allintitle:seo 搜索引擎 等价于 intitle:seo intitle:搜索引擎。
allintext 在结果的正文内容中同时包含多个关键词。排他性指令。
allinanchor、inanchor 是排他性指令。
inanchor 它返回的结果是导入链接锚文字中包含搜索词的页面。
比如在 Google 搜索 inanchor:点击这里,
返回的结果页面本身并不一定包含"点击这里"这四个字,而是指向这些页面的链接锚文字中出
现了 "点击这里" 这四个字。需要注意区别与inurl,inurl是网页本身的url地址,而inanchor是在
外部用于指向该 url 地址的文本(<a>..</a>之间文本)中找。
例如:inanchor:download,你可能会发现有 "FlashGet最佳的下载管理模式",
而该页面中根本就没有 "download" 字样。define 查询关键词的词义,支持汉字。示例:define:computer
weather 查询某一地区或城市的天气。示例:weather:beijing
intext 将返回所有在网页正文部分包含关键词的网页。示例: intext:剑圣
星号* 通配符,可以匹配任意字符串。
例如:搜索*擎,则返回的结果中不仅有 "搜索引擎",还有 "搜索巨擎" 之类的。
.. 或者 ... 表示数值范围。也可以是三个点。
示例:手机 2000..3000 元,注意 "3000" 与 "元" 之间必须有空格。
cache 搜索google里关于某些内容的缓存。这个命令现在也被Google集成到了搜索结果里,
当你把鼠标悬浮在搜索结果上时,右侧会自动出现此结果的快照信息。
info 查询网站的一些信息。info=cache+related+link+site+intext+intitle。
示例:info:bbs.byr.cn 返回一个结果列表,列表的选项是这个网站的某一方面的信息。
related 查询与所给的网站类似的网站,它会返回Google认为的可能和你提供的网站类似的其他网站。
示例:related:bbs.gfan.com,会返回安卓巴士,eoe社区,91等站点,但不会返回机锋网。
其实这个命令Google经常在用,比如我们搜一个东西,Google除了返回给我结果,
还会在结果下面给我们返回一些相关的词条。
Link 查询链接到这个 url 的页面。示例: link:thief.one 可以返回所有和 thief.one 做了链接的URL。
linkdomain 查询这个url链接的页面。
示例: linkdomain:bbs.gfan.com -site:bbs.gfan.com,这样的结果比较准确,
因为扫除了本身的干扰,它将返回机锋网链接到的页面。从机锋指向其他页面。
利用google暴库。利用goole可以搜索到互联网上可以直接下载到的数据库文件,语法如下:
inurl:editor/db/
inurl:eWebEditor/db/
inurl:bbs/data/
inurl:databackup/
inurl:blog/data/
inurl:bokedata
inurl:bbs/database/
inurl:conn.asp
inc/conn.asp
Server.mapPath(".mdb")
allinurl:bbs data
filetype:mdb inurl:database
filetype:inc conn
inurl:data filetype:mdb
intitle:"index of" data
利用goole搜索敏感信息。利用google可以搜索一些网站的敏感信息,语法如下:
intitle:"index of" etc
intitle:"Index of" .sh_history
intitle:"Index of" .bash_history
intitle:"index of" passwd
intitle:"index of" people.lst
intitle:"index of" pwd.db
intitle:"index of" etc/shadow
intitle:"index of" spwd
intitle:"index of" master.passwd
intitle:"index of" htpasswd
inurl:service.pwd
利用 google 搜索 C 段服务器信息。此技巧来自 lostwolf (http://wolvez.club/)
site:218.87.21.* // 通过google可获取218.87.21.0/24网络的服务信息。
第一篇
Google 常用搜索技巧及 "index of" 详细使用方法:https://blog.csdn.net/sunxinty/article/details/52624380
********** 注意 引号 是 英文引号,英文引号,英文引号。。。重要的事说三遍 **********
在搜索框上输入: "index of /" inurl:lib
再按搜索你将进入许多图书馆,并且一定能下载自己喜欢的书籍。
在搜索框上输入: "index of /" cnki
再按搜索你就可以找到许多图书馆的CNKI、VIP、超星等入口!
在搜索框上输入: "index of /" ppt
再按搜索你就可以突破网站入口下载powerpint作品!
在搜索框上输入: "index of /" mp3
再按搜索你就可以突破网站入口下载 mp3、rm等影视作品!
在搜索框上输入: "index of /" swf
再按搜索你就可以突破网站入口下载 flash作品!
在搜索框上输入: "index of /" 要下载的软件名
再按搜索你就可以突破网站入口下载软件!
再透露一下,如果你输入:"index of /" AVI
第二篇
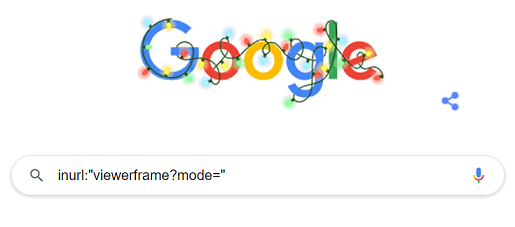
用 google 看世界!!! 只要你在 google 里输入特殊的关键字,就可以搜到数千个摄象头的 IP 地址,通过他你就可以看到其所摄的实时影象!!
在 google 里输入 inurl:"viewerframe?mode=" 随便打开一个,然后按提示装一个插件,就可以看到了!!!
第三篇
Google 搜索技巧简介。Google 毫无疑问是当今世界上最强大的搜索引擎。然而,它也是一个秘密武器,它能搜索到一些你意想不到的信息。
搜索 URL
比如我们提交这种形式:passwd.txt site:http://www.360docs.net/doc/info-5ce0fa3c10661ed9ad51f3dc.html
看到了什么?是不是觉得太不可思议了!有很多基于 CGI/PHP/ASP 类型的留言板存在这种问题。有时我们得到密码甚至还是明码的!管理员或许太不负责了,或许安全防范的意识太差了,如果你是网络管理员,赶快检查一下不要让恶意攻击者捡了便宜。不要太相信 DES 加密,即使我们的密码经过 DES 加密的密码,还是可以通过软件来爆破密码。
这次我们能得到包含密码的文件。
site:http://www.360docs.net/doc/info-5ce0fa3c10661ed9ad51f3dc.html 意思是只搜索 http://www.360docs.net/doc/info-5ce0fa3c10661ed9ad51f3dc.html 的 URL。http://www.360docs.net/doc/info-5ce0fa3c10661ed9ad51f3dc.html 是一个网络服务器提供商。
同样,我们可以搜索一些顶级域名,比如:.net .org .jp .in .gr
config.txt site:.jp
admin.txt site:.tw
搜索首页的目录
首页是非常有用的,它会提供给你许多有用的信息。
我们提交如下的形式:
"Index of /admin"
"Index of /secret"
"Index of /cgi-bin" site:.edu
你可以自己定义搜索的首页字符。这样就可以获得许多信息。
搜索特定的文件类型
比如你想指定一种文件的类型,可以提交如下形式:
filetype:.doc site:.mil classified
这个就是搜索军方的资料,你可以自定义搜索。
第四篇
Google 的查询语法可以精确的搜索结果,得到真正想要数据。 当然也可以利用它从互联网上来挖掘更多本来不应该知道的保密和隐私的信息。
现在我将要详细讨论这些技术,展示如何利用 Google 从网上挖掘信息的,以及如何利用这些信息来入侵远程服务器。
"index of"
利用 "index of" 与发来查找开放目录浏览的站点。一个开放了目录浏览的WEB服务器意味着任何人都可以像浏览通常的本地目录一样浏览它上面的目录。
这里将讨论如何利用 "index of" 语法来得到开放目录浏览的WEB服务器列表。试想如果得到了本不应该在internet上可见的密码文件或其它敏感文件,结果会怎样!!!
下面给出了一些能轻松得到敏感信息的例子。
Index of /admin
Index of /passwd
Index of /password
Index of /mail
"Index of /" +passwd
"Index of /" +password.txt
"Index of /" +.htaccess
"Index of /secret"
"Index of /confidential"
"Index of /root"
"Index of /cgi-bin"
"Index of /credit-card"
"Index of /logs"
"Index of /config"
inurl 和 allinurl
利用 inurl 或 allinurl 寻找缺陷站点或服务器
"allinurl:winnt/system32/"(不包括引号)
会列出所有通过 web 可以访问限制目录如 "system32" 的服务器的链接。如果你很幸运你就可以访问到 "system32" 目录中的cmd.exe。
一旦你能够访问 cmd.exe,就可以执行它,瞧!服务器归你所有了。
allinurl:wwwboard/passwd.txt
会列出所有存在 "WWWBoard 密码缺陷" 的服务器的链接。
想了解更多关于这个缺陷的知识,你可以参看下面的链接:http://www.360docs.net/doc/info-5ce0fa3c10661ed9ad51f3dc.html /exploits/2BUQ4S0SAW.html
inurl:bash_history
会列出所有通过web可以访问 ".bash_history" 文件的服务器的链接。这是一个历史命令文件。这个文件包含了管理员执行的命令列表,有时还包含敏感信息例如管理员输入的密码。如果这个文件被泄漏并且包含加密的 unix 密码,就可以用 "John The Ripper" 来爆破密码。
inurl:config.txt
会列出所有通过 web 可以访问 "config.txt" 文件的服务器的链接。这个文件包含敏感信息,包括管理员密码的哈希值和数据库认证凭证。
例如:Ingenium Learning Management System是一个由 Click2learn.Inc 开发的基于Web的Windows应用程序。Ingenium Learning Management System5.1和6.1版本以非安全的方式在config.txt文件中存储了敏感信息。
更多相关内容请参看:
其它类似的组合其它语法的“inurl:”或“allinurl:”用法:
inurl:admin filetype:txt
inurl:admin filetype:db
inurl:admin filetype:cfg
inurl:mysql filetype:cfg
inurl:passwd filetype:txt
inurl:iisadmin
inurl:auth_user_file.txt
inurl:orders.txt
inurl:"wwwroot/*."
inurl:adpassword.txt
inurl:webeditor.php
inurl:file_upload.php
inurl:gov filetype:xls "restricted"
index of ftp +.mdb allinurl:/cgi-bin/ +mailto
intitle 或 allintitle
寻找缺陷站点或服务器
allintitle:"index of /root"
会列出所有通过web可以访问限制目录如“root”的服务器的链接。这个目录有时包含可通过简单Web查询得到的敏感信息。
allintitle:"index of /admin"
会列出所有开放如“admin”目录浏览权限的WEB站点列表链接。大多数Web应用程序通常使用“admin”来存储管理凭证。这个目录有时包含可通过简单Web查询得到的敏感信息。
其它类似的组合其它语法的 "intitle:" 或 "allintitle:" 用法:
intitle:"Index of" .sh_history
intitle:"Index of" .bash_history
intitle:"index of" passwd
intitle:"index of" people.lst
intitle:"index of" pwd.db
intitle:"index of" etc/shadow
intitle:"index of" spwd
intitle:"index of" master.passwd
intitle:"index of" htpasswd
intitle:"index of" members OR accounts
intitle:"index of" user_carts OR user_cart
allintitle: sensitive filetype:doc
allintitle: restricted filetype :mail
allintitle: restricted filetype:doc site:gov
其它有趣的搜索串
查找有跨站脚本漏洞(XSS)的站点:
allinurl:/scripts/cart32.exe
allinurl:/CuteNews/show_archives.php
allinurl:/phpinfo.php
查找有SQL注入漏洞的站点:
allinurl:/privmsg.php
3、baidu 高级搜索
百度高级搜索页面:https://www.baidu.com/gaoji/advanced.html
4、bing 高级搜索
高级搜索选项
:https://help.bing.microsoft.com/#apex/bing/zh-CHS/10002/-1
- 默认情况下,所有搜索都是 AND 搜索。
- 必须完全大写 NOT 和 OR 运算符。否则,必应会将他们作为非索引字而忽略,通常会发生单词和数字被忽略以加速全文搜索的情况。
- 除了本主题中提到的符号之外,非索引字和所有标点符号都会被忽略,除非他们带有引号或前面有“+”号。
- 只有前 10 个术语用于获取搜索结果。
- 术语分组和布尔运算符按以下首选顺序给予支持:
- ()
- ""
- NOT – +
- AND &
- OR |
- 由于 OR 是优先级最低的运算符,因此在搜索中与其他运算符连用时,请为 OR 术语加上引号。
-
此处介绍的某些特性和功能可能在您的国家或地区不可用。
| 符号 | 函数 |
|---|---|
| + | 查找包含前面带 + 号的所有术语的网页。还允许您包含通常被忽略的术语。 |
| " " | 在短语中查找完全匹配的字词。 |
| () | 查找或排除包含一组单词的网页。 |
| AND 或 & | 查找包含所有术语或短语的网页。 |
| NOT 或 – | 排除包含某个术语或短语的网页。 |
| OR 或 | | 查找包含某个术语或短语的网页。 |
优先级
( ) 具有最高优先级。
AND、&& 和 & 的优先级高于 OR、| 和 ||。
示例:foo bar OR bing yahoo
等价于:(foo AND bar) | (bing AND yahoo)
不等价:foo (bar | bing) yahoo
示例:foo AND bar NOT hello
等价于:(foo AND bar) NOT hello
示例:foo OR bar NOT hello
等价于:(foo OR bar) NOT hello
高级搜索关键字
:https://help.bing.microsoft.com/#apex/bing/zh-CHS/10001/-1
不要下面关键字的冒号后面加入空格。
| 关键字 | 定义 | 示例 |
|---|---|---|
| contains: | 确保搜索结果锁定到带有指定文件类型链接的站点。 | 若要搜索包含 Windows Media 音频 (.wma) 文件链接的网站,请键入 music contains:wma。 |
| ext: | 仅返回带有指定文件扩展名的网页。 | 若要查找以 DOCX 格式创建的报告,请键入主题,然后键入 ext:docx。 |
| filetype: | 仅返回以指定文件类型创建的网页。 | 若要查找以 PDF 格式创建的报告,请键入主题,然后键入 filetype:pdf。 |
| inanchor: 或 inbody:或 intitle: | 这些关键字分别返回元数据包含指定术语(如站点的锚点、正文或标题)的网页。每个关键字只能指定一个术语。您可以根据需要串联多个关键字条目。 | 若要查找在锚点中包含“msn”同时正文中包含“spaces”和“magog”术语的网页,请键入 inanchor:msn inbody:spaces inbody:magog。 |
| ip: | 查找指定 IP 地址托管的站点。IP 地址必须由点分隔为四部分。键入 ip: 关键字,后接网站的 IP 地址。 | 键入 IP:207.46.249.252。 |
| language: | 返回指定语言的网页。直接在 language: 关键字之后指定语言代码。 | 若要只查看关于古董的英文网页,请键入 "antiques" language:en。 |
| loc: 或 location: | 返回来自指定国家或地区的网页。直接在 loc: 关键字之后指定国家或地区代码。若要关注两种或更多语言,请使用逻辑 OR 来组织语言。 | 若要查看来自美国或大不列颠有关雕塑的网页,请键入 sculpture (loc:US OR loc:GB)。有关可以在必应中使用的语言代码列表,请参见国家、地区和语言代码。 |
| prefer: | 为搜索术语或另一家运营商添加重点,以帮助锁定搜索结果。 | 若要查找足球的相关网页,但搜索内容主要限定在某球队,请键入 football prefer:organization。 |
| site: | 返回属于指定站点的网页。若要关注两个或更多个域,请使用逻辑 OR 来组织域。您可以使用 site: 来搜索 Web 域、顶级域和深度不超过两级的目录。您也可以在站点上搜索包含指定搜索词的网页。 | 若要查看 BBC 或 CNN 网站上关于心脏病的网页,请键入 "heart disease" (site:bbc.co.uk OR site:cnn.com)。若要在 微软 网站上查找关于 Halo 的 PC 版本的网页,请键入 site:www.microsoft.com/games/pc halo。 |
| feed: | 为您搜索的术语在网站上查找 RSS 或 Atom 源。 | 若要查找关于足球的 RSS 或 Atom 源,请键入 feed:football。 |
| hasfeed: | 在网站上查找包含有关搜索术语的 RSS 或 Atom 源的网页。 | 若要查找关于纽约时报网站的包含 RSS 或 Atom 源的网页,请键入 site:www.nytimes.com hasfeed:football。 |
| url: | 检查列出的域或网址是否在必应的索引内。 | 若要验证 微软 域是否在索引内,请键入 url:microsoft.com。 |
5、shodan 搜索引擎
shodan 网络搜索引擎偏向网络设备以及服务器的搜索,具体内容可上网查阅,这里给出它的高级搜索语法。
地址:https://www.shodan.io/
搜索语法
- hostname: 搜索指定的主机或域名,例如 hostname:”google”
- port: 搜索指定的端口或服务,例如 port:”21”
- country: 搜索指定的国家,例如 country:”CN”
- city: 搜索指定的城市,例如 city:”Hefei”
- org: 搜索指定的组织或公司,例如 org:”google”
- isp: 搜索指定的ISP供应商,例如 isp:”China Telecom”
- product: 搜索指定的操作系统/软件/平台,例如 product:”Apache httpd”
- version: 搜索指定的软件版本,例如 version:”1.6.2”
- geo: 搜索指定的地理位置,例如 geo:”31.8639, 117.2808”
- before/after: 搜索指定收录时间前后的数据,格式为dd-mm-yy,例如 before:”11-11-15”
- net: 搜索指定的IP地址或子网,例如 net:”210.45.240.0/24”
以上内容参考:http://xiaix.me/shodan-xin-shou-ru-keng-zhi-nan/
6、censys 搜索引擎
censys 搜索引擎功能与shodan类似,以下几个文档信息。
地址:https://www.censys.io/
https://www.censys.io/certificates/help 帮助文档
https://www.censys.io/ipv4?q= ip查询
https://www.censys.io/domain?q= 域名查询
https://www.censys.io/certificates?q= 证书查询
搜索语法。默认情况下 censys 支持全文检索。
- 23.0.0.0/8 or 8.8.8.0/24 可以使用 and or not
- 80.http.get.status_code: 200 指定状态
- 80.http.get.status_code:[200 TO 300] 200-300之间的状态码
- location.country_code: DE 国家
- protocols: ("23/telnet" or "21/ftp") 协议
- tags: scada 标签
- 80.http.get.headers.server:nginx 服务器类型版本
- autonomous_system.description: University 系统描述
- 正则
7、钟馗之眼
钟馗之眼搜索引擎偏向web应用层面的搜索。
地址:https://www.zoomeye.org/
搜索语法
- app:nginx 组件名
- ver:1.0 版本
- os:windows 操作系统
- country:”China” 国家
- city:”hangzhou” 城市
- port:80 端口
- hostname:google 主机名
- site:thief.one 网站域名
- desc:nmask 描述
- keywords:nmask’blog 关键词
- service:ftp 服务类型
- ip:8.8.8.8 ip地址
- cidr:8.8.8.8/24 ip地址段
8、FoFa搜索引擎
FoFa 搜索引擎偏向资产搜索。
地址:https://fofa.so
安全圈炸锅了,FOFA暂停对外开放,被工信部列为“黑名单”!:https://zhuanlan.zhihu.com/p/460403187
搜索语法
- title=”abc” 从标题中搜索abc。例:标题中有北京的网站。
- header=”abc” 从http头中搜索abc。例:jboss服务器。
- body=”abc” 从html正文中搜索abc。例:正文包含Hacked by。
- domain=”qq.com” 搜索根域名带有qq.com的网站。例: 根域名是qq.com的网站。
- host=”.gov.cn” 从url中搜索.gov.cn,注意搜索要用host作为名称。
- port=”443” 查找对应443端口的资产。例: 查找对应443端口的资产。
- ip=”1.1.1.1” 从ip中搜索包含1.1.1.1的网站,注意搜索要用ip作为名称。
- protocol=”https” 搜索制定协议类型(在开启端口扫描的情况下有效)。例: 查询https协议资产。
- city=”Beijing” 搜索指定城市的资产。例: 搜索指定城市的资产。
- region=”Zhejiang” 搜索指定行政区的资产。例: 搜索指定行政区的资产。
- country=”CN” 搜索指定国家(编码)的资产。例: 搜索指定国家(编码)的资产。
- cert=”google.com” 搜索证书(https或者imaps等)中带有google.com的资产。
高级搜索:
- title=”powered by” && title!=discuz
- title!=”powered by” && body=discuz
- ( body=”content=”WordPress” || (header=”X-Pingback” && header=”/xmlrpc.php” && body=”/wp-includes/“) ) && host=”gov.cn”
9、Dnsdb 搜索引擎
dnsdb 搜索引擎是一款针对 dns 解析的查询平台。
地址:https://www.dnsdb.io/
搜索语法
DnsDB查询语法结构为条件1 条件2 条件3 …., 每个条件以空格间隔, DnsDB 会把满足所有查询条件的结果返回给用户.
域名查询条件
域名查询是指查询顶级私有域名所有的DNS记录, 查询语法为domain:.
例如查询google.com 的所有DNS记录: domain:google.com.
域名查询可以省略domain:.
主机查询条件
查询语法:host:
例如查询主机地址为mp3.example.com的DNS记录: host:map3.example.com
主机查询条件与域名查询查询条件的区别在于, 主机查询匹配的是DNS记录的Host值
按DNS记录类型查询
查询语法: type:.
例如只查询A记录: type:a
使用条件:必须存在domain:或者host:条件,才可以使用type:查询语法
按IP限制
查询语法: ip:
查询指定IP: ip:8.8.8.8, 该查询与直接输入8.8.8.8进行查询等效
查询指定IP范围: ip:8.8.8.8-8.8.255.255
CIDR: ip:8.8.0.0/24
IP最大范围限制65536个
条件组合查询的例子
查询google.com的所有A记录: google.com type:a
最后
以上就是英勇石头最近收集整理的关于google、bing、baidu、shodan、censys、ZoomEye 搜索引擎 高级用法1、有哪些好用的搜索引擎?2、google 搜索 高级指令3、baidu 高级搜索4、bing 高级搜索5、shodan 搜索引擎6、censys 搜索引擎7、钟馗之眼8、FoFa搜索引擎9、Dnsdb 搜索引擎的全部内容,更多相关google、bing、baidu、shodan、censys、ZoomEye内容请搜索靠谱客的其他文章。







.rar: http://www.t00y.com/file/10072590; X3 R9 N9 H+ r [黑客基地:C语言编程特训班].毒宫玫瑰.共26讲.iso: http://www.t00y.com/file/100725913 T9 z8 J% G# a( B( m b [黑客基地:Linux操作系统特训班].毒宫玫瑰.共32讲.rar:+ _1 }+ t9 @$ \ http://www.t00y.com/file/10072](https://www.shuijiaxian.com/files_image/reation/bcimg8.png)
发表评论 取消回复