????欢迎来到机器学习的世界
????博客主页:卿云阁????欢迎关注????点赞????收藏⭐️留言????
????本文由卿云阁原创!
????本阶段属于练气阶段,希望各位仙友顺利完成突破
????首发时间:????2021年3月12日????
✉️希望可以和大家一起完成进阶之路!
????作者水平很有限,如果发现错误,请留言轰炸哦!万分感谢!
目录
???? 模块和包
????什么是包
????常见的python模块

???? 一、模块和包
什么是模块
在 Python 中,⼀个 .py ⽂件就可以称之为 ⼀个模块(Module )模块分类模块分为三种:内置标准模块(⼜称标准库)执⾏ help(‘modules’) 查看所有 python ⾃带模块列表第三⽅开源模块可通过 pip install 模块名 联网安装其中plotly是我需要安装的模块名。pip install -i https://pypi.tuna.tsinghua.edu.cn/simple plotly⾃定义模块
test.py
import my_module my_module.sayhi("qinyun")my_module.py
print("my first module") def sayhi(name): print("大家好,我的名字是{0}".format(name))结果
my first module 大家好,我的名字是qinyun模块导入 & 调用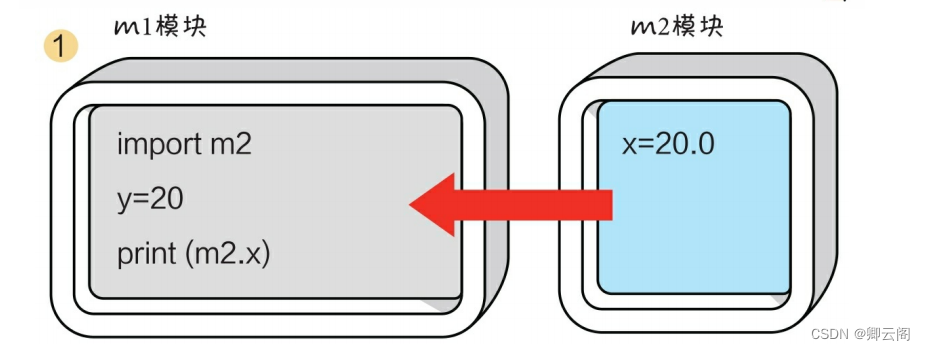
import+模块名,这种方式会导入m2模块的所有元素在访问时, 需要加上前缀"m2."。
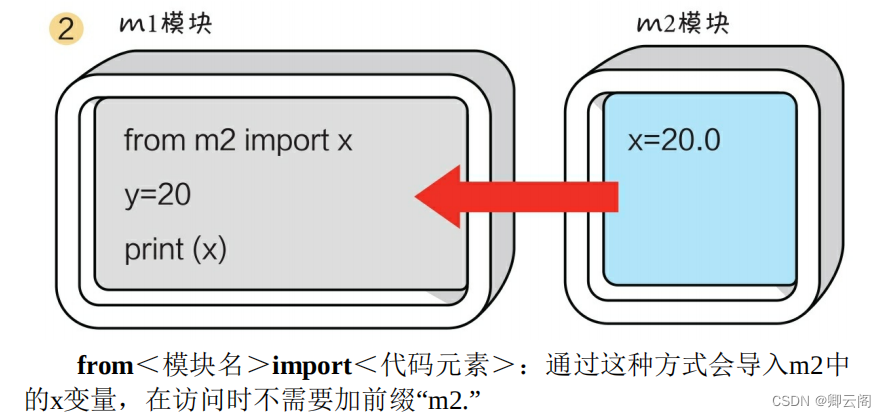
注意:模块⼀旦被调用,即相当于执行了另外⼀个py⽂件里的代码。# 导入sys整个模块 import sys # 使用sys模块名作为前缀来访问模块中的成员 print(sys.argv[0]) #结果 C:/Users/Administrator/Desktop/test.py sys 模块下的 argv 变量用于获取运行 Python 程序的命令行参数,其中 argv[0] 用于获取当前 Python 程序的存储路径 等价于 # 导入sys模块的argv成员 from sys import argv # 使用导入成员的语法,直接使用成员名访问 print(argv[0])模块的查找路径
有没有发现,⾃⼰写的模块只能在当前路径下的程序⾥才能导⼊,换⼀个目录再导⼊自己的模块就报错说找不到了, 这是为什么? 这与导⼊模块的查找路径有关模板的查找路径。import sys print(sys.path) ['C:\Users\Administrator\Desktop', 'C:\Users\Administrator\Desktop', 'C:\Program Files\Python37\python37.zip', 'C:\Program Files\Python37\DLLs', 'C:\Program Files\Python37\lib', 'C:\Program Files\Python37', 'C:\Users\Administrator\AppData\Roaming\Python\Python37\site-packages', 'C:\Program Files\Python37\lib\site-packages']输出(注意不同的电脑可能输出的不太⼀样)你导⼊⼀个模块时, Python 解释器会按照上⾯列表顺序去依次到每个目录下去匹配你要导⼊的模块名, 只要在⼀个目录下匹配到了该模块名,就⽴刻导入,不再继续往后找。注意列表第⼀个元素为空,即代表当前⽬录,所以你⾃⼰定义的模块在当前⽬录会被优先导⼊。 我们自己创建的模块若想在任何地方都能调⽤,那就得确保你的模块⽂件⾄少在模块路径的查找列表 中。 我们⼀般把自己写的模块放在⼀个带有“site-packages”字样的⽬录⾥,我们从网上下载安装的各种第三 方的模块⼀般都放在这个目录。第3方开源模块安装
可以直接通过 pip 安装pip3 install paramiko #paramiko 是模块名pip命令会⾃动下载模块包并完成安装。软件⼀般会被⾃动安装你 python 安装⽬录的这个⼦⽬录⾥/your_python_install_path/3.6/lib/python3.6/site-packagespip 命令默认会连接在国外的 python 官⽅服务器下载,速度⽐较慢,你还可以使⽤国内的⾖瓣源,数据 会定期同步国外官网,速度快好多 -i 后⾯跟的是⾖瓣源地址 —trusted-host 得加上,是通过⽹站 https 安全验证⽤的pip install -i http://pypi.douban.com/simple/sayhi --trusted-host pypi.douban.com #sayhi是模块名使用下载后,直接导⼊使用就可以,跟⾃带的模块调用的方法无差。
????包和库
其实,一个包就是一个文件目录,你可以把同一个业务线的文件放在一起
????常见的python模块
系统调用 OS 模块os 模块提供了很多允许你的程序与操作系统直接交互的功能>>> import os >>> os.getcwd()#当前项目的路径 'D:\pythonProject6' >>> os.listdir()#当前项目的文件 ['.idea', 'index.html', 'main.py', 'venv']import os 得到当前⼯作⽬录,即当前Python脚本⼯作的⽬录路径: os.getcwd() 返回指定⽬录下的所有⽂件和⽬录名:os.listdir() 函数⽤来删除⼀个⽂件:os.remove() 删除多个⽬录:os.removedirs(r“c:python”) 检验给出的路径是否是⼀个⽂件:os.path.isfile() 检验给出的路径是否是⼀个⽬录:os.path.isdir() 判断是否是绝对路径:os.path.isabs() 检验给出的路径是否真地存:os.path.exists() 返回⼀个路径的⽬录名和⽂件名:os.path.split() e.g os.path.split('/home/swaroop/byte/code/poem.txt') 结果: ('/home/swaroop/byte/code', 'poem.txt') 分离扩展名:os.path.splitext() e.g os.path.splitext('/usr/local/test.py') 结果:('/usr/local/test', '.py') 获取路径名:os.path.dirname() 获得绝对路径: os.path.abspath() 获取⽂件名:os.path.basename() 运⾏shell命令: os.system() 读取操作系统环境变量HOME的值:os.getenv("HOME") 返回操作系统所有的环境变量: os.environ 设置系统环境变量,仅程序运⾏时有效:os.environ.setdefault('HOME','/home/alex') 给出当前平台使⽤的⾏终⽌符:os.linesep Windows使⽤'rn',Linux and MAC使⽤'n' 指示你正在使⽤的平台:os.name 对于Windows,它是'nt',⽽对于Linux/Unix⽤户,它 是'posix' 重命名:os.rename(old, new) 创建多级⽬录:os.makedirs(r“c:pythontest”) 创建单个⽬录:os.mkdir(“test”) 获取⽂件属性:os.stat(file) 修改⽂件权限与时间戳:os.chmod(file) 获取⽂件⼤⼩:os.path.getsize(filename) 结合⽬录名与⽂件名:os.path.join(dir,filename) 改变⼯作⽬录到dirname: os.chdir(dirname) 获取当前终端的⼤⼩: os.get_terminal_size() 杀死进程: os.kill(10884,signal.SIGKILL)解释器交互“sys”“sys”即“system”,“系统”之意。该模块提供了一些接口,用于访问 Python 解释器自身使用和维护的变量,同时模块中还提供了一部分函数,可以与解释器进行比较深度的交互import sys print("-----获取环境变量-----") print(sys.path) print("-----获取当前脚本的参数-----") print(sys.argv) 结果 -----获取环境变量----- ['D:\pythonProject6', 'D:\pythonProject6', 'D:\pycharm\PyCharm 2021.2.3\plugins\python\helpers\pycharm_display', 'D:\anaconda\python38.zip', 'D:\anaconda\DLLs', 'D:\anaconda\lib', 'D:\anaconda', 'C:\Users\qingyun\AppData\Roaming\Python\Python38\site-packages', 'D:\anaconda\lib\site-packages', 'D:\anaconda\lib\site-packages\locket-0.2.1-py3.8.egg', 'D:\anaconda\lib\site-packages\win32', 'D:\anaconda\lib\site-packages\win32\lib', 'D:\anaconda\lib\site-packages\Pythonwin', 'D:\pycharm\PyCharm 2021.2.3\plugins\python\helpers\pycharm_matplotlib_backend'] -----获取当前脚本的参数----- ['D:/pythonProject6/main.py']datetime 模块相比于time模块,datetime模块的接⼝则更直观、更容易调⽤
datetime 模块定义了下⾯这⼏个类:datetime.date :表示⽇期的类。常⽤的属性有 year, month, day ;datetime.time :表示时间的类。常⽤的属性有 hour, minute, second, microsecond ;datetime.datetime :表示⽇期时间。datetime.timedelta :表示时间间隔,即两个时间点之间的⻓度。datetime.tzinfo :与时区有关的相关信息。(这⾥不详细充分讨论该类,感兴趣的童鞋可以参考 python⼿册)我们需要记住的方法仅以下几个:1. d=datetime.datetime.now() 返回当前的 datetime ⽇期类型 , d.timestamp(),d.today(),d.year,d.timetuple() 等⽅法可以调⽤2. datetime.date.fromtimestamp(322222) 把⼀个时间戳转为 datetime ⽇期类型3. 时间运算>>> datetime.datetime.now() datetime.datetime(2017, 10, 1, 12, 53, 11, 821218) >>> datetime.datetime.now() + datetime.timedelta(4) #当前时间 +4天 datetime.datetime(2017, 10, 5, 12, 53, 35, 276589) >>> datetime.datetime.now() + datetime.timedelta(hours=4) #当前时间+4⼩时 datetime.datetime(2017, 10, 1, 16, 53, 42, 876275)4. 时间替换>>> d.replace(year=2999,month=11,day=30) datetime.date(2999, 11, 30)random随机数
程序中有很多地⽅需要用到随机字符,比如登录网站的随机验证码,通过 random 模块可以很容易生成 随机字符串。
>>> random.randrange(1,10) #返回1-10之间的⼀个随机数,不包括10 >>> random.randint(1,10) #返回1-10之间的⼀个随机数,包括10 >>> random.randrange(0, 100, 2) #随机选取0到100间的偶数 >>> random.random() #返回⼀个随机浮点数 >>> import random >>> random.choice('abcdefghi') 'i' >>> random.sample('abcdefghij',3) #从多个字符中选取特定数量的字符 ['h', 'c', 'f'] >>> import string >>> ''.join(random.sample(string.ascii_lowercase + string.digits, 6)) '4fvda1' #洗牌 >>> a [0, 1, 2, 3, 4, 5, 6, 7, 8, 9] >>> random.shuffle(a) >>> a [3, 0, 7, 2, 1, 6, 5, 8, 9, 4]序列化json模块
什么是 Json?Json的作用是用于不同语言接口间的数据交换,比如你把 python 的 list 、 dict 直接扔给 javascript, 它是解 析不了的。2 个语⾔互相谁也不认识。 Json 就像是计算机界的英语 ,可以帮各个语⾔之间实现数据类型的相互转换。python的序列化>>> names=["qingyun","wenzhu","猪猪侠"] >>> names ['qingyun', '猪猪侠', 'wenzhu'] >>> import json >>> json.dumps(names) '["qingyun", "wenzhu", "\u732a\u732a\u4fa0"]'JSON ⽀持的数据类型Python 中的字符串、数字、列表、字典、集合、布尔 类型,都可以被序列化成 JSON 字符串,被其它任何编程语⾔解析。什么是序列化?序列化是指把内存里的数据类型转变成字符串,以使其能存储到硬盘或通过⽹络传输到远程,因为硬盘 或网络传输时只能接受bytes为什么要序列化?你打游戏过程中,打累了,停下来,关掉游戏、想过 2 天再玩, 2 天之后,游戏⼜从你上次停⽌的地⽅继 续运⾏,你上次游戏的进度肯定保存在硬盘上了,是以何种形式呢?游戏过程中产⽣的很多临时数据是不规律的,可能在你关掉游戏时正好有10 个列表, 3 个嵌套字典的数据集合在内存⾥,需要存下来?你 如何存?把列表变成⽂件⾥的多⾏多列形式?那嵌套字典呢?根本没法存。所以,若是有种办法可以直 接把内存数据存到硬盘上,下次程序再启动,再从硬盘上读回来,还是原来的格式的话,那是极好的。⽤于序列化的两个模块json ,⽤于字符串 和 python 数据类型间进⾏转换pickle ,⽤于 python 特有的类型 和 python 的数据类型间进⾏转换pickle模块提供了四个功能: dumps 、 dump 、 loads 、loadimport pickle data = {'k1':123,'k2':'Hello'} # pickle.dumps 将数据通过特殊的形式转换位只有python语⾔认识的字符串 p_str = pickle.dumps(data) # 注意dumps会把数据变成bytes格式 print(p_str) # pickle.dump 将数据通过特殊的形式转换位只有python语⾔认识的字符串,并写⼊⽂件 with open('result.pk',"wb") as fp: pickle.dump(data,fp) # pickle.load 从⽂件⾥加载 f = open("result.pk","rb") d = pickle.load(f) print(d)jsonJson 模块也提供了四个功能: dumps 、 dump 、 loads 、 load ,⽤法跟 pickle ⼀致json vs pickle:JSON:优点:跨语⾔ ( 不同语⾔间的数据传递可⽤ json 交接 ) 、体积⼩缺点:只能⽀持 intstrlisttupledictPickle:优点:专为 python 设计,⽀持 python 所有的数据类型缺点:只能在 python 中使⽤,存储数据占空间大Python xlrd 读取 Excel 表格基础
安装
pip install -i https://pypi.tuna.tsinghua.edu.cn/simple openpyxl前面已经介绍了Python 第三方模块xlwt,将数据写入Excel表格的基础操作。从这篇博客开始来介绍 xlrd 模块读取 Excel 表格数据内容的操作。
本篇主要内容为:
1、获取工作簿、sheet表对象;
2、获取sheet表中行对象,列对象;
3、获取sheet表中所有数据;
4、获取工作簿对象所有sheet表数据。1、获取工作簿、sheet对象
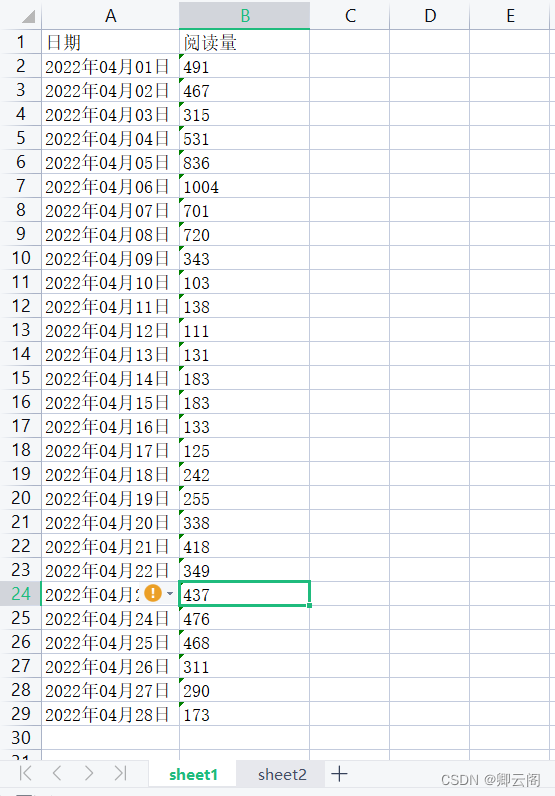
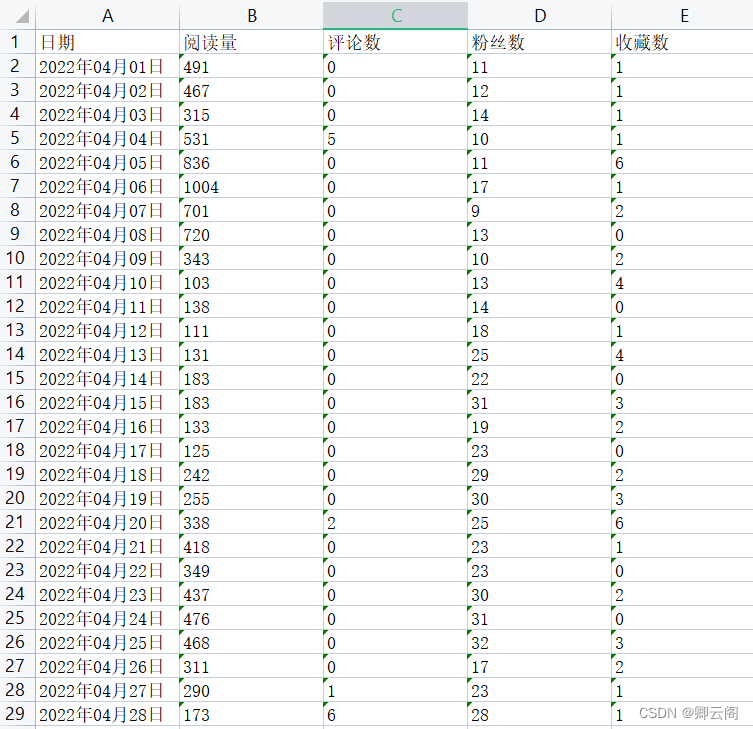
下面是示例所使用的两张表在CSDN创作中心的数据数据详情中下载了一个Excel表格文件,然后做成了两个sheet表,文件截图如下:
sheet1 截图:
sheet2 截图:
获取工作簿文件对象(打开文件):
# 导入模块 import xlrd # 打开文件方式1: work_book = xlrd.open_workbook(r'C:UsersqingyunDesktop全部文章分析.xlsx') # 获取工作簿中sheet表数量 print(work_book.nsheets) #结果 2获取工作簿对象属性:print("----------获取工作簿对象属性----------") print("1.-----获取工作簿中sheet表数量-----") print("获取工作簿中sheet表数量{0}".format(work_book.nsheets)) print("2.-----获得工作表中所有的sheet表对象-----") sheets=work_book.sheets() print("获得工作表中所有的sheet表对象{0}".format(sheets)) print("3.-----获取工作簿所有sheet表对象名称-----") sheets_name = work_book.sheet_names() print("获取工作簿所有sheet表对象名称-{0}".format(sheets_name)) #结果 ----------获取工作簿对象属性---------- 1.-----获取工作簿中sheet表数量----- 获取工作簿中sheet表数量2 2.-----获得工作表中所有的sheet表对象----- 获得工作表中所有的sheet表对象[<xlrd.sheet.Sheet object at 0x0000010F7585ACD0>, <xlrd.sheet.Sheet object at 0x0000010F7585AD60>] 3.-----获取工作簿所有sheet表对象名称----- 获取工作簿所有sheet表对象名称-['sheet1', 'sheet2']按索引、名称获取sheet表对象
# 导入模块 import xlrd # 打开文件方式1: work_book = xlrd.open_workbook(r'C:UsersqingyunDesktop全部文章分析.xlsx') print("----------按索引、名称获取sheet表对象:----------") print("1.-----按索引获取sheet对象-----") sheet_1 = work_book.sheet_by_index(0) print("按索引获取sheet对象{0}".format(sheet_1)) print("2.-----按sheet表名称获取sheet对象,名称分大小写-----") sheet_2 = work_book.sheet_by_name('sheet2') print("获得工作表中所有的sheet表对象{0}".format(sheet_2)) #结果 ----------按索引、名称获取sheet表对象:---------- 1.-----按索引获取sheet对象----- 按索引获取sheet对象<xlrd.sheet.Sheet object at 0x000002493F8DAD60> 2.-----按sheet表名称获取sheet对象,名称分大小写----- 获得工作表中所有的sheet表对象<xlrd.sheet.Sheet object at 0x000002493F8DAD00>
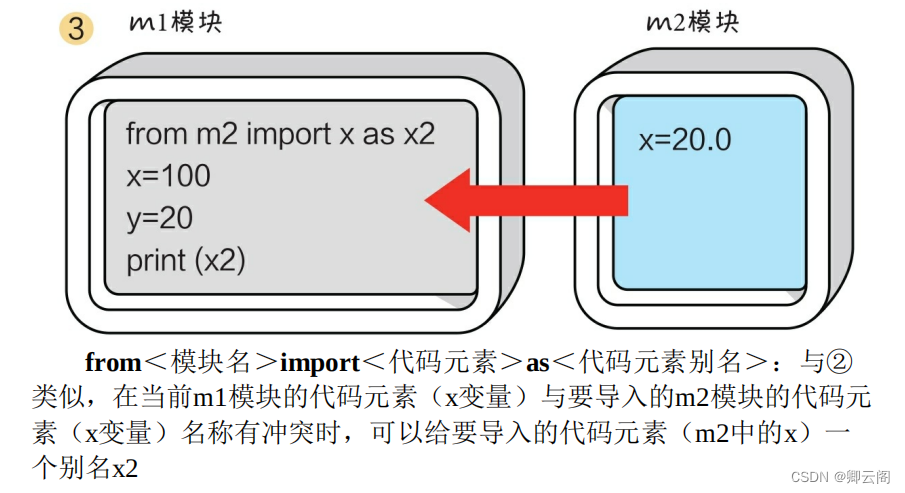
最后
以上就是仁爱手机最近收集整理的关于python中的模块和包的全部内容,更多相关python中内容请搜索靠谱客的其他文章。








发表评论 取消回复