一. 引言
Mysql 我们平常用的很多,目的是为了存储数据,离散地存储在硬盘上,在海量的数据面前我们如何能快速命中理想数据,此时我们主角索引就应运而生。
二. 索引是什么?
官方解释:索引是帮助MySQL高效获取数据的数据结构
原始的存储方式:文件系统主要包括【柱面 、 磁道和扇区】,那么每次查询都需要从每个柱面的每个磁道的每个扇区开始查询
索引的查询方式:把每条数据与对应的扇区地址对应起来,那么只要查到扇区地址就可以直接获取数据
使用索引的目标:尽可能减少磁盘IO操作
三. 如何选择满足这种快速查询的数据结构?
强调:首先我们要先申明一个概念,判断索引的标准是什么?是IO渐进复杂度(就是IO执行的次数)
Hash算法:用hash这种方式存储效率很高,但是涉及范围查询就无能为力
select * from user_t where id > 1 二分查找树(AVL):利用二分查找树可以快速找到我们要找的元素,
但二叉树是线性增加的,而且每个节点只能放一个数 据,每查询一个数据,都会从头到尾执行一次
如果查询一次算一个IO的话,查询第1万条数据就要执行1万次IO
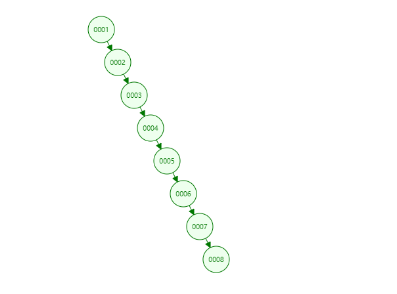
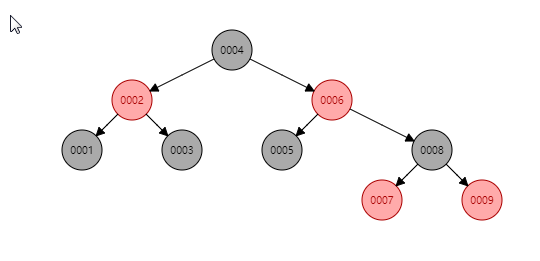
红黑树:利用红黑树可以快速找到我们要找的元素,虽然高度减少了,但是还是无法摆脱它是二分查找树的特点,高度还是不可控的,IO执行次数还是过多
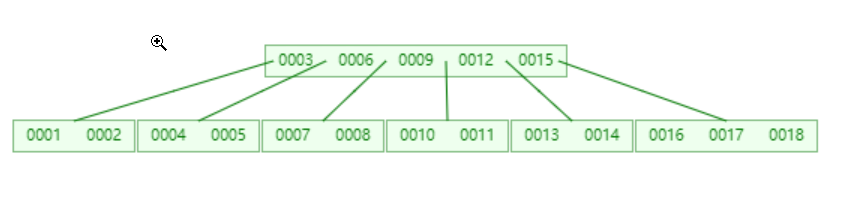
BTree:
- 针对减小树的深度,我们可以对树的节点做横向扩容,每个节点可以存储多个数据,而且可以拥有多个孩子节点,这样我们每次IO能加载很多数据到内存中,在内存中查找的时间和磁盘IO相比几乎可以忽略不计
- 但是横向扩容是有限度的,因为磁盘读写的单位是扇道,每个扇道的容量往往对应操作系统的一个页面的大小(一般是4K),即每次只能读取一个页面的数据,多了一次读不完,少了没有充分利用一次磁盘IO
- 所以一个节点不宜放太多数据,mysql默认一个节点大小是16K(固定值),这样树的高度在1~3之间,在大数据的规模下只需要极少次数的磁盘IO就能找到数据
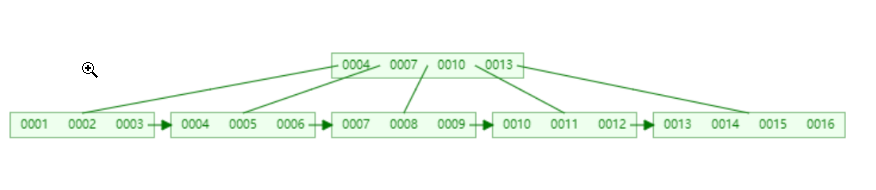
B+Tree
- mysql索引用得最多的其实还是B+Tree,因为他是对Btree做的优化
- B+Tree把所有数据放在叶子节点上,非叶子节点只放索引(冗余),这样我们可以在一个页面大小的限制下存下更多的key
- B+Tree用指针把叶子节点连到了一起,这样有利于做范围查询
四、使用
1>按存储引擎可以分:
MyISam(非聚集索引)--特点:
- 非聚集索引:索引与数据分开,索引对应的值是数据的地址
- 一张数据表分成三个文件
- xx.frm文件存放表结构
- xx.MYI文件存放表的索引
- xx.MYD文件存放表数据
- 主键索引和非主键索引(非主键索引的值是数据的地址)
InnoDB(聚集索引)--特点:
- 聚集索引:将表数据按照B+Tree结构存储,索引对应的值就是数据
- 一张数据表分成两个文件
- xx.frm文件存放表结构
- xx.idb存放数据+索引
- 主键索引和非主键索引(非主键索引的值是主键)
2>优化:
- 尽量选取区分度高的字段作为索引
- 仅仅使用最有效的过滤条件 -> key length
- 尽可能避免复杂的jion和子查询 -> 锁资源
- explan 命令:查询优化神器,查看执行计划(QEP, Query Execute Plain),查看每一列的属性,以优化SQL语句
explain 列属性:
- id: SELECT 查询的标识符. 每个 SELECT 都会自动分配一个唯一的标识符.
- select_type: SELECT 查询的类型.
- table: 查询的是哪个表
- partitions: 匹配的分区
- type: join 类型
- possible_keys: 此次查询中可能选用的索引
- key: 此次查询中确切使用到的索引.
- ref: 哪个字段或常数与 key 一起被使用
- rows: 显示此查询一共扫描了多少行. 这个是一个估计值.
- filtered: 表示此查询条件所过滤的数据的百分比
- extra: 额外的信息
join
- A join B where A.id=B.id 是先查询到A的id集,再拿A的id集去检索B
- 如果大于两个表 join,会将前边 jion 的结果放入 join_buffer,再继续 join 其他表,如果 join_buffer 不够大,join 结果会被放入磁盘,再 join 就需要进行磁盘IO
- 永远使用小结果集驱动大结果集,保证被驱动表的 join 字段能被索引到
- show variables like ‘join_%’ // 查看 join_buffer 的大小,加大 join_buffer_size
order by
- 在条件字段已经建立 B+Tree 索引情况下,数据已经有序,所以条件字段尽量命中索引
- 在条件字段没有名字索引的情况下,mysql 底层实现 order by 的两种方式(自动选择)
buffer 足够大时(一次磁盘批量IO):将所需字段全部取到内存,再取出条件字段和记录在内存中的地址,对条件字段进行排序,排好序后用指针从内存取数据返回
buffer 不够大时(两次磁盘批量IO):将条件字段与记录地址取到内存,根据条件字段进行排序,排好序后用指针从磁盘取出数据返回- - 对于2场景:需加大 max_length_for_sort_data,(以空间换时间),尽量减少不必要的返回字段,增大 sort_buffer 减少排序过程对排序数据的分段
最后
以上就是欢喜茉莉最近收集整理的关于MySQL-索引深入简出的全部内容,更多相关MySQL-索引深入简出内容请搜索靠谱客的其他文章。
本图文内容来源于网友提供,作为学习参考使用,或来自网络收集整理,版权属于原作者所有。








发表评论 取消回复