普遍问题
step function和reset function执行顺序
- ResetFunc (-1 Episode)
- StepFunc (0 step)
- ResetFunc (0 Episode)
- ResetFunc (1 Episode)
- StepFunc (1 step)
Discrete Action Space
当actions组合较少时,可以不用预分配cell空间,可以动态添加cell的数量或cell里的元素;
当actions的组合较多时,以递增方式动态增加cell的数量或元胞中元素的数量会导致 Out of Memory,需要预分配空间;
当actions的组合非常多时,预分配cell空间也会导致Out of Memory。
相关问题1: link.
相关问题2: link.
关于离散action设置: link.
关于并行训练(Parallel training with several workers)和RNN(LSTM)
两者不可以同时使用,因为RNN有状态。
下图是A3C使用LSTM的错误提示。
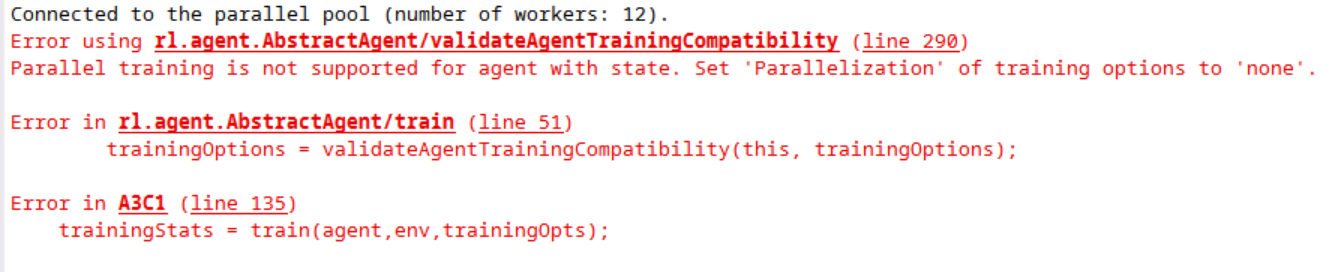
不同agent各自的问题
SAC
1.actor不可以useGPU
Caused by:
Error using rl.representation.rlAbstractRepresentation/gradient (line 183)
Unable to compute gradient from representation.
Error using nnet.internal.cnn.layer.util.CustomLayerVerifier>iThrow (line 686)
Incorrect type of ‘dLdX’ for ‘backward’ in Layer ‘rl.layer.ScalingLayer’. Expected to be
‘gpuArray’, but instead was ‘single’.
PPO
- Continuous Action Space:
UpperLimit和LowerLimit无法限制action范围(不同于DDPG)(可能会很大导致NaN)。将标准差standard deviation path的最后三层网络设置成如下,可以极大限制action范围。
tanhLayer(‘Name’,‘svp_tanh1’)
fullyConnectedLayer(numActions,‘Name’,‘svp_fc2’)
softplusLayer(‘Name’, ‘svp_out’)
- 关于继续训练之前训练的agent
因为rlPPOAgentOptions没有’ExperienceBufferLength’和’SaveExperienceBufferWithAgent’这两个选项,所以不用考虑这两项。参考代码:
agentOpts.ResetExperienceBufferBeforeTraining =true;
load(PRE_TRAINED_MODEL_FILE,‘saved_agent’);
agent = saved_agent;
trainingStats = train(agent,env,trainOpts);
- NormalizedAdvantageMethode参数选择moving
报错,错误提示如下图:
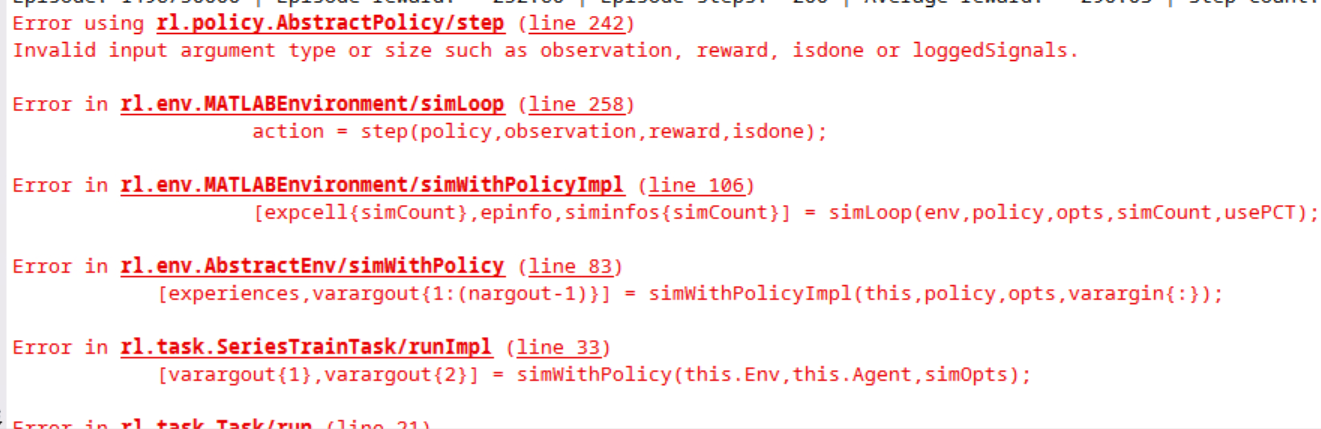
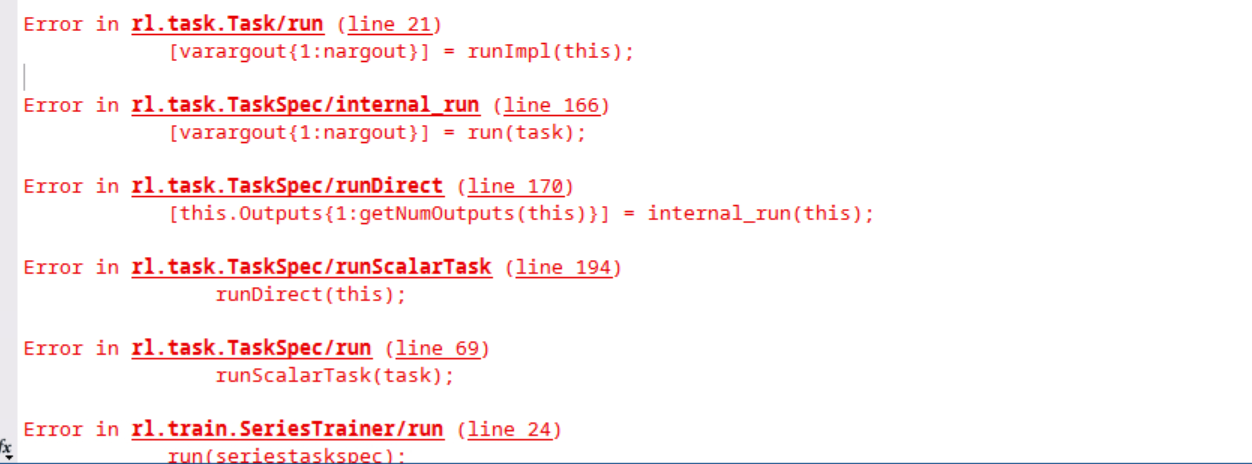
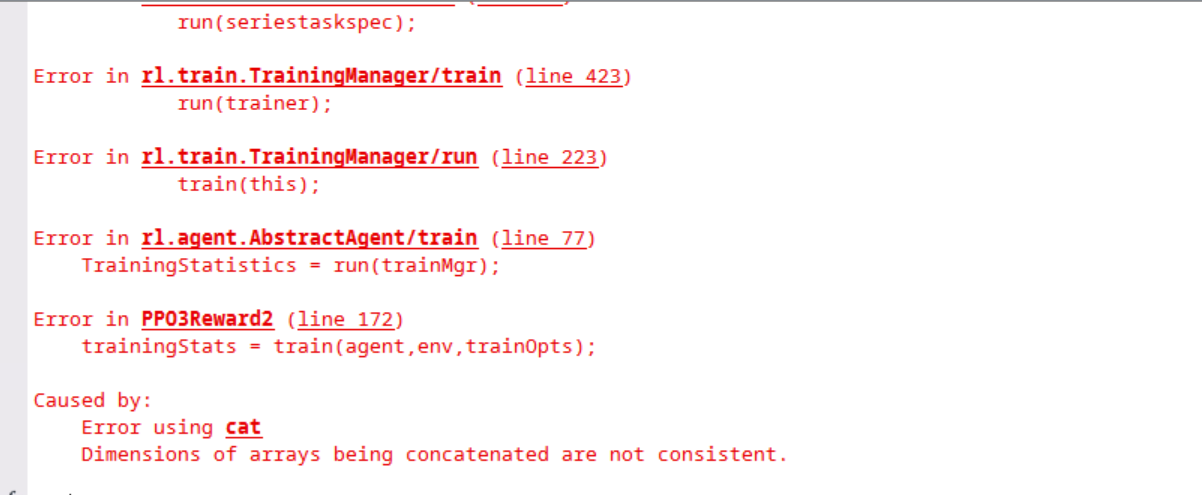
Discrete Action Space
AC(A2C/A3C)
For continuous action spaces, the rlACAgent object does not enforce the constraints set by the action specification, so you must enforce action space constraints within the environment.
AC的action space也需要在环境中限制。
(to be continued)
最后
以上就是无语钢铁侠最近收集整理的关于MATLAB的强化学习工具箱(Reinforcement Learning Toolbox)使用细节注意普遍问题不同agent各自的问题的全部内容,更多相关MATLAB的强化学习工具箱(Reinforcement内容请搜索靠谱客的其他文章。








发表评论 取消回复