博客推荐
Q-Learning
二维避障轨迹规划
目前我写的代码不够成熟,就不贴了。Agent的reward机制如下:走出图像reward为一个较大负数,撞上障碍也为一个较大负数,若不是前两者,则reward为当前点位与目标点位距离的反比函数(越近奖赏越大)。
state状态的划分是根据像素区域来的,等同于把图像分割成了若干像素块,这样可以减小state的数量,否则训练困难。Action根据移动方向的角度来分,比如10°划分的话一个state就有36个actions,这样Q表就是
s
t
a
t
e
s
×
a
c
t
i
o
n
s
statestimes actions
states×actions尺寸的矩阵。
结果
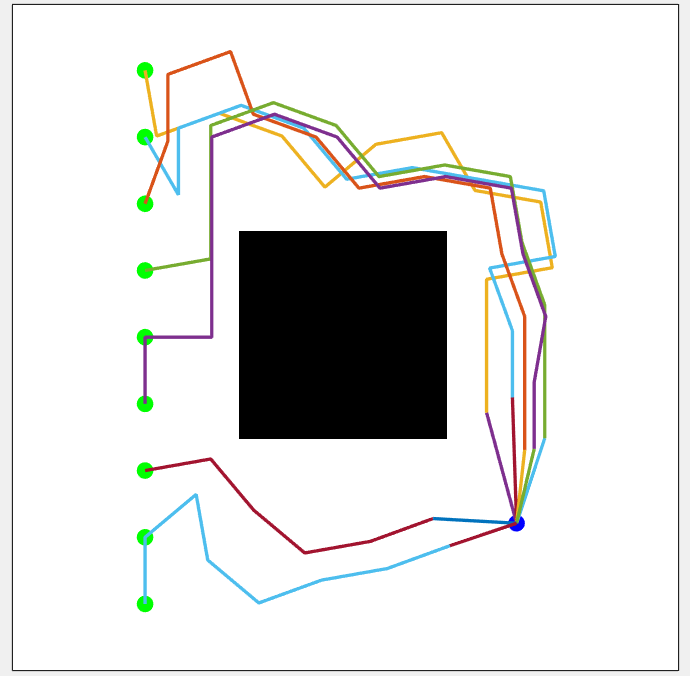
结果基本全图收敛。
代码
注:这只是个学习程序,实用价值不高。
clc;clf;clear;
%% 加载图片二值化(方形图片)
map=imbinarize(imread('test2.bmp')); % input map read from a bmp file. for new maps write the file name here
map = map(:,:,1); %三通道取前两个通道
%% 参数初始化
statePixSize = 100; %像素方格视为一个state
stateNumRow = size(map,1)/statePixSize;
stateNum = stateNumRow^2;
source = [192,263]; %初始点
goal = [757,779]; %目标点
iter1 = 100; %学习迭代次数
iter2 = 3000; %每次迭代内循环次数
state0 = calculateState(source(1),source(2),stateNumRow,statePixSize); %起始点的状态
stateGoal = calculateState(goal(1),goal(2),stateNumRow,statePixSize); %goal的状态
angle = 10; %一个action度数
actionNum = 360/angle;
Q = zeros(stateNum,actionNum);
e = 0.3; %解决探索和开发
gamma = 0.9; alpha = 0.5;
stepSize = 100;
threshold = 200;
%% 学习循环
for i = 1:iter1
% randXY = randperm(size(map,1),2);
% x = randXY(1); y = randXY(2);
% state = calculateState(x,y,stateNumRow,statePixSize);
state = state0;
x = source(1); y = source(2);
for j = 1:iter2
% 当前state下做出action决策
randNum = rand;
if(rand>e)
[~,action] = max(Q(state,:));
else
action = randperm(actionNum,1);
end
% 判断在该决策下到达的下一个state
xNext = x + stepSize * sin((action-1)*angle/180*pi);
yNext = y - stepSize * cos((action-1)*angle/180*pi);
if(xNext<=0 || xNext >= size(map,1) || yNext<=0 || yNext >=size(map,2))
Q(state,action) = -10000;
continue;
end
newState = calculateState(xNext,yNext,stateNumRow,statePixSize);
% 判断碰撞与否以及是否到达goal 并observe reward
if checkPath([x,y],[xNext,yNext],map)
reward = 2000/(1+distanceCost([xNext,yNext],goal));
if newState == stateGoal
reward = 1000;
end
Q(state,action) = Q(state,action) + alpha * (reward + gamma * max(Q(newState,:)) - Q(state,action));
else
reward = -5000;
Q(state,action) = Q(state,action) + alpha * (reward + gamma * max(Q(newState,:)) - Q(state,action));
end
state = newState;
x = xNext; y = yNext;
end
if ~mod(i,10)
str = sprintf('Q-Learning学习进度:%d%%',vpa(i/iter1*100,2));
disp(str);
end
end
%% 验证
imshow(map);
rectangle('position',[1 1 size(map)-1],'edgecolor','k'); hold on;
scatter(goal(1),goal(2),100,"filled","b");
testPoint = [200 100;200 200;200 300;200 400;200 500;200 600;200 700;200 800;200 900];
for i = 1 : size(testPoint,1)
scatter(testPoint(i,1),testPoint(i,2),100,"filled","g");
x = testPoint(i,1); y = testPoint(i,2);
state = calculateState(x,y,stateNumRow,statePixSize);
path = [x,y];
try
while distanceCost([x,y],goal) > threshold
[~,action] = max(Q(state,:));
xNext = x + stepSize * sin((action-1)*10/180*pi);
yNext = y - stepSize * cos((action-1)*10/180*pi);
newState = calculateState(xNext,yNext,stateNumRow,statePixSize);
if ~checkPath([x,y],[xNext,yNext],map)
break;
end
state = newState;
x = xNext; y = yNext;
path = [path;x,y];
end
plot(path(:,1),path(:,2),[path(end,1),goal(1)],[path(end,2),goal(2)],'LineWidth',2);
catch
disp("error!")
end
end
% for i = 1:50
% [~,action] = max(Q(state,:));
% xNext = x + stepSize * sin((action-1)*10/180*pi);
% yNext = y - stepSize * cos((action-1)*10/180*pi);
% newState = calculateState(xNext,yNext,stateNumRow,statePixSize);
% state = newState;
% x = xNext; y = yNext;
% path = [path;x,y];
% end
% plot(path(:,1),path(:,2));
calculateState.m
function state = calculateState(x,y,stateNumRow,statePixSize)
rowNum = ceil(y/statePixSize);
colNum = ceil(x/statePixSize);
state = (rowNum-1) * stateNumRow + colNum;
end
checkPath.m
%% checkPath.m
function feasible=checkPath(n,newPos,map)
feasible=true;
dir=atan2(newPos(2)-n(2),newPos(1)-n(1));
for r=0:0.5:sqrt(sum((n-newPos).^2))
posCheck=n+r.*[cos(dir) sin(dir)];
if ~(feasiblePoint(ceil(posCheck),map) && feasiblePoint(floor(posCheck),map) && ...
feasiblePoint([ceil(posCheck(1)) floor(posCheck(2))],map) && feasiblePoint([floor(posCheck(1)) ceil(posCheck(2))],map))
feasible=false;break;
end
if ~feasiblePoint(floor(newPos),map), feasible=false; end
end
end
distanceCost.m
function h=distanceCost(a,b) %% distanceCost.m
h = sqrt(sum((a-b).^2, 2));
end
feasiblePoint.m
%% feasiblePoint.m
function feasible=feasiblePoint(point,map)
feasible=true;
% check if collission-free spot and inside maps
if ~(point(1)>=1 && point(1)<=size(map,1) && point(2)>=1 && point(2)<=size(map,2) && map(point(1),point(2))==1)
feasible=false;
end
end
test2.bmp

最后
以上就是狂野眼睛最近收集整理的关于强化学习Q-Learning在二维轨迹规划应用(MATLAB)博客推荐二维避障轨迹规划结果代码的全部内容,更多相关强化学习Q-Learning在二维轨迹规划应用(MATLAB)博客推荐二维避障轨迹规划结果代码内容请搜索靠谱客的其他文章。








发表评论 取消回复