文章目录
- Basic Components
- Actor
- Critic
- 网络训练
- Q-learning
- Actor + Critic
- A2C Advantage Actor-Critic
- A3C Asynchtonous Advantage Actor-Critic
- Back propagation
- Inverse RL
- Policy Gradient
- Policy
- Example
- Gradient
Basic Components
-
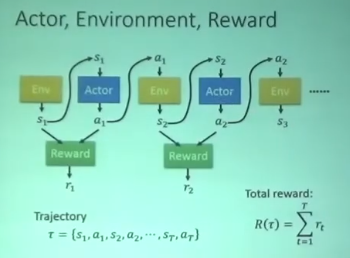
以Video Game为例
-
Actor:遥杆
-
Env:游戏界面
-
Reward Function:杀一个怪得20分
-
Actor
-
一个神经网络
-
输入游戏画面 输出action
Critic
-
给定一个actor的一个observation
-
Critic给出从现在到结束的reward的概率
-
Critic衡量Actor的好坏 但不决定action
-
example:打怪游戏:当当前的observation里面还很多怪 那给出的reward 概率就会高
当当前的observation剩一点点怪 那么reward就低 因为到游戏结束也不会获得很高的分数

网络训练
-
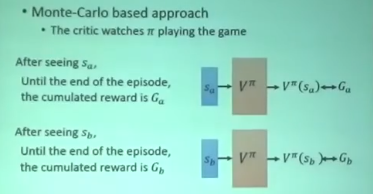
MC
- 给定一个state 得到这个state开始到游戏结束的reward G
- 然后将这个state输入到Vπ 得到的值跟G越接近越好
-
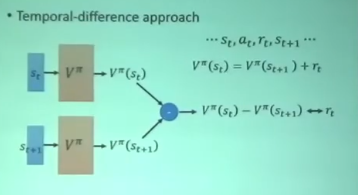
TD
- 给定相邻的两个state分别送进去网络
- 得到的差值越接近这个state后actor的得到的reward越好
Q-learning
-
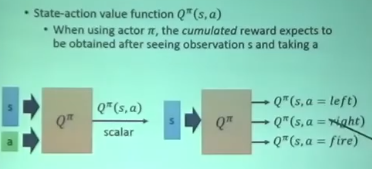
Q function
-
给定state 和 action
-
给出这个state采取这个action的reward
-
只适用于离散的action
-
-
-
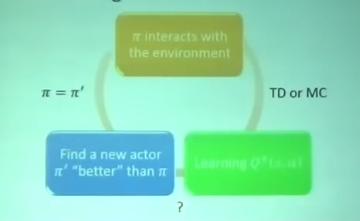
迭代过程
-
给定一个actor π
-
给出 state action 算出Q-value
-
通过TD/MC更新Q function
-
得到一个更好的actor π1
-
π1替换π
-
Actor + Critic
- 仅仅actor会根据当前observation得到一个reward 但这样子做随机性会很大
- 故提出AC Critic指导Actor的行动
A2C Advantage Actor-Critic
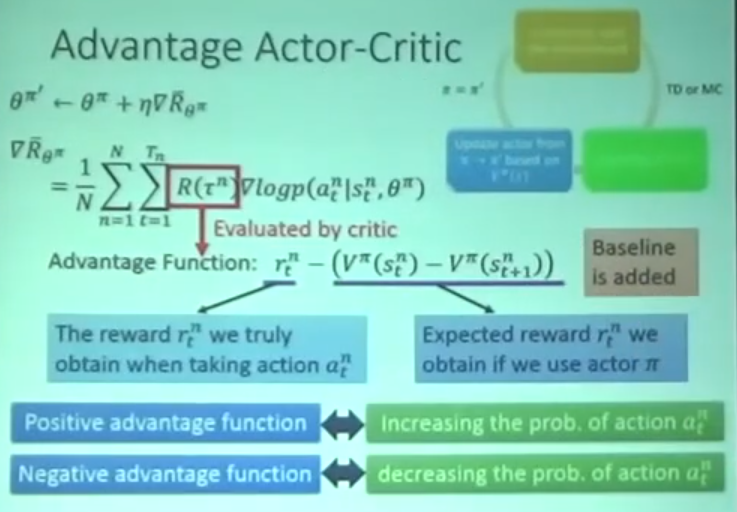
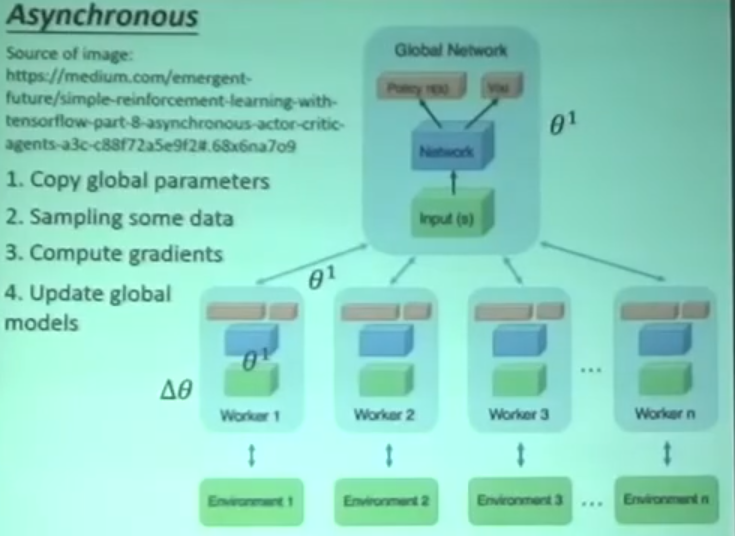
A3C Asynchtonous Advantage Actor-Critic
- 有一个global actor 和 critic
- 建立一些分身进行跟环境互动 平行运算
- 反馈参数到global
Back propagation
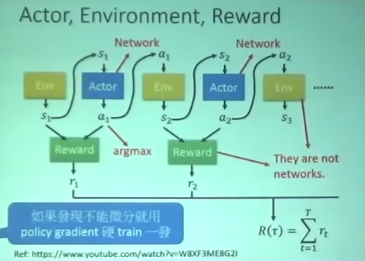
- 为了maximize R(涛) 需要反向传播到Reward,Env ,Actor
- 但是Reward,Env并不是网络
- 所以需要用Policy Gradient去实现反向传播
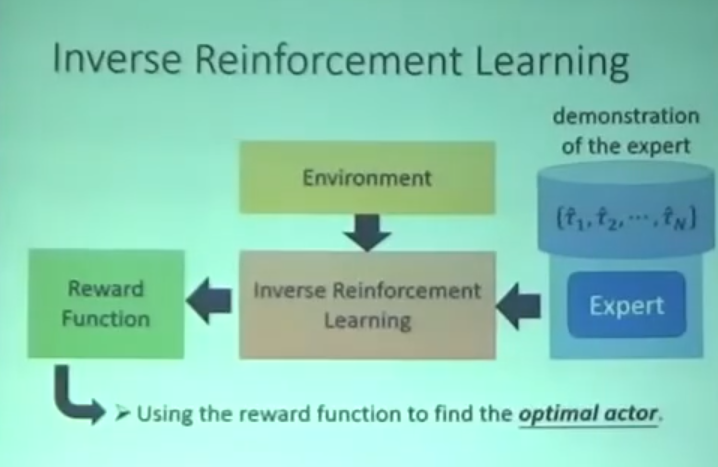
Inverse RL
- 很多时候并不知道reward function
- 需要一个跟环境互动过的专家Expert反推 reward function
- 使用reward function 找到最好的Actor
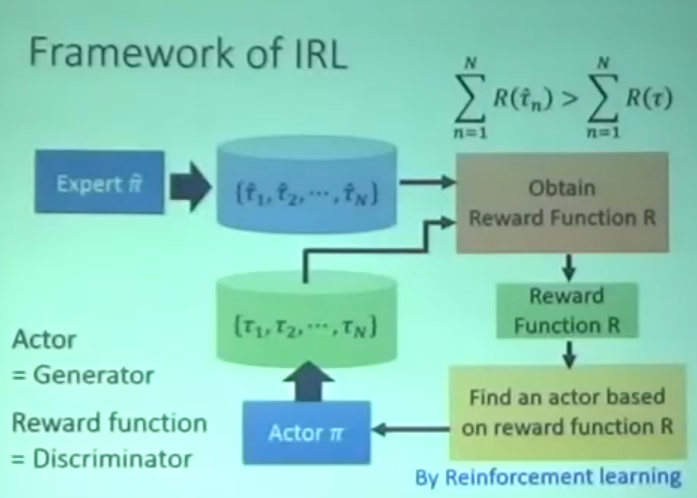
- 具体流程

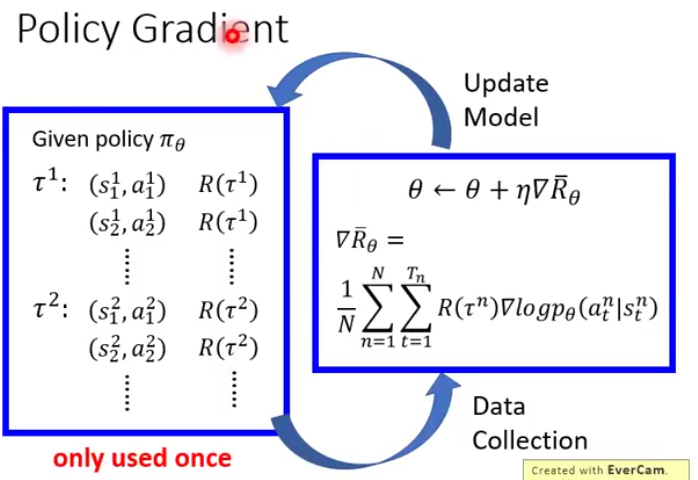
Policy Gradient
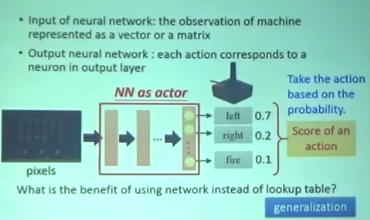
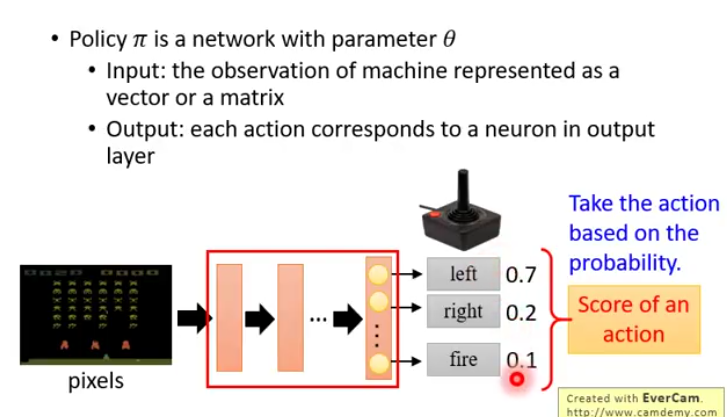
Policy
-
输入一个代表observation的矩阵或者向量
-
输出端每一个action对应输出层的一个神经元
Example
- Actor 得到 S1 放入 Policy
- 得到概率最高的action a1
- 采取action后获得这个action的reward r1
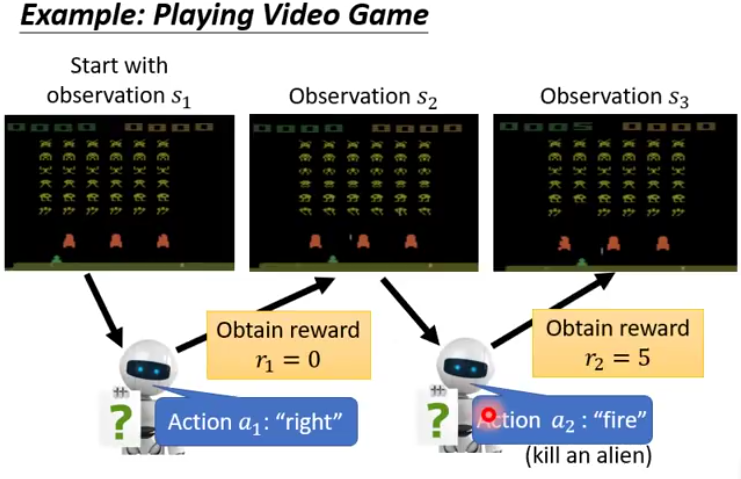
-
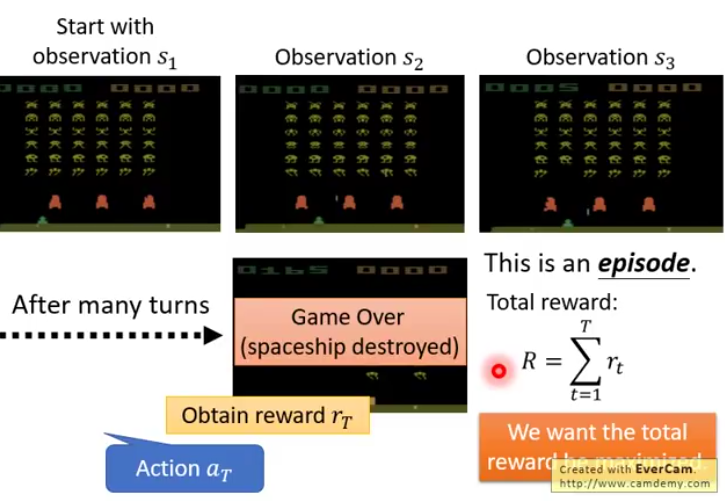
一直循环直到游戏结束 整个过程称为一个episode 所有reward的总和称为total reward
-
Actor的目的就是让total reward最大化
-
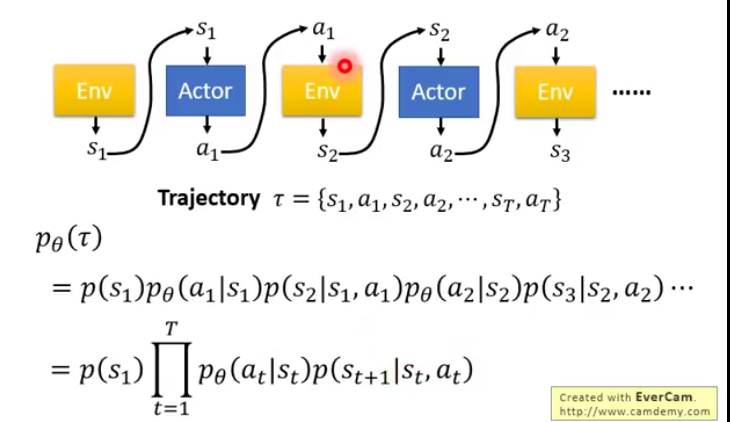
(s1,a1,s2,a2…)的集合称为trajectory
-
可以计算这个trajectory的概率
-
Expected Reward
-
sample 一个 trajectory 乘上这个trajectory的total reward
-
sample所有的trajectory 并以total reward为权值加权起来就是 Expected Reward
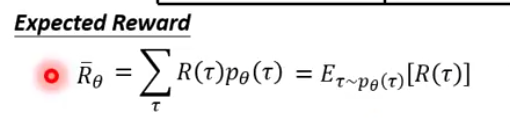
Gradient
-
-
目标是maximinze Expected Reward
-
gradient计算公式

-
具体流程
最后
以上就是疯狂薯片最近收集整理的关于(RL强化学习)强化学习基础知识Basic ComponentsBack propagationInverse RLPolicy Gradient的全部内容,更多相关(RL强化学习)强化学习基础知识Basic内容请搜索靠谱客的其他文章。








发表评论 取消回复