
这是 Java 爬虫系列博文的第三篇,在上一篇 Java 爬虫遇到需要登录的网站,该怎么办? 中,我们简单的讲解了爬虫时遇到登录问题的解决办法,在这篇文章中我们一起来聊一聊爬虫时遇到数据异步加载的问题,这也是爬虫中常见的问题。
现在很多都是前后端分离项目,这会使得数据异步加载问题更加突出,所以你在爬虫时遇到这类问题不必惊讶,不必慌张。对于这类问题的解决办法总体来说有以下两种:
1、内置一个浏览器内核
内置浏览器就是在抓取的程序中,启动一个浏览器内核,使我们获取到 js 渲染后的页面,这样我们就跟采集静态页面一样了。这种工具常用的有以下三种:
- Selenium
- HtmlUnit
- PhantomJs
这些工具都能帮助我们解决数据异步加载的问题,但是他们都存在缺陷,那就是效率不高而且不稳定。
2、反向解析法
什么是反向解析法呢?我们 js 渲染页面的数据是通过 Ajax 的方式从后端获取的,我们只需要找到对应的 Ajax 请求连接就 OK,这样我们就获取到了我们需要的数据,反向解析法的好处就是这种方式获取的数据都是 json 格式的数据,解析起来也比较方便,另一个好处就是相对页面来说,接口的变化概率更小。同样它有两个不足之处,一个是在 Ajax 时你需要有耐心有技巧,因为你需要在一大推请求中找到你想要的,另一个不足的地方就是对 JavaScript 渲染的页面束手无策。
上面就是异步数据加载的两种解决办法,为了加深大家的理解和在项目中如何使用,我以采集网易要闻为例,网易新闻地址:https://news.163.com/ 。利用上诉的两种方式来获取网易要闻的新闻列表。
内置浏览器 Selenium 方式
Selenium 是一个模拟浏览器,进行自动化测试的工具,它提供一组 API 可以与真实的浏览器内核交互。在自动化测试上使用的比较多,爬虫时解决异步加载也经常使用它,我们要在项目中使用 Selenium ,需要做两件事:
- 1、引入 Selenium 的依赖包,在 pom.xml 中添加
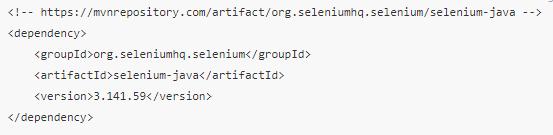
- 2、下载对应的 driver,例如我下载的 chromedriver,下载地址为:https://npm.taobao.org/mirrors/chromedriver/,下载后,需要将 driver 的位置写到 Java 的环境变量里,例如我直接放在项目下,所以我的代码为:

完成上面两步之后,我们就可以来编写使用 Selenium 采集网易要闻啦。具体代码如下:

运行该方法,得到结果如下:
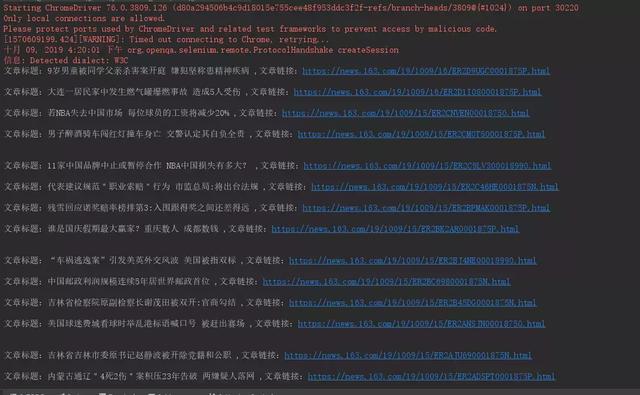
我们使用 Selenium 已经正确的提取到了网易要闻的列表新闻。
反向解析法
反向解析法就是获取到 Ajax 异步获取数据的链接,直接获取到新闻数据。如果没有技巧的话,查找 Ajax 的过程将非常痛苦,因为一个页面加载的链接太多了,看看网易要闻的 network:
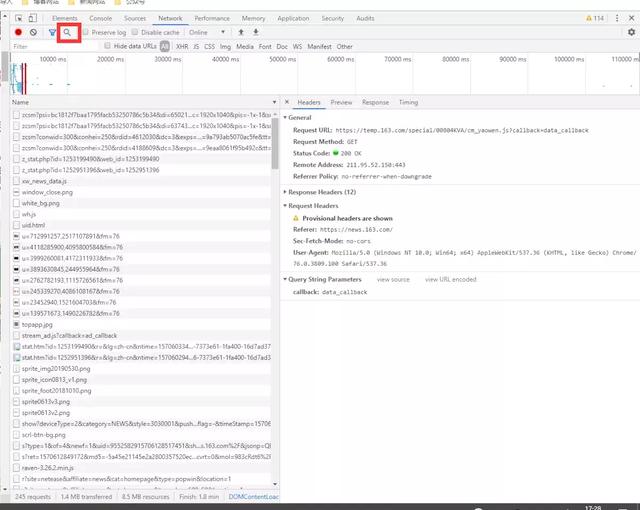
有几百条的请求,该如何查找到是哪条请求获取的要闻数据呢?你不嫌麻烦的话,可以一个一个的去点,肯定能够查找到的,另一种快捷的办法是利用 network 的搜索功能,如果你不知道搜索按钮,我在上图已经圈出来啦,我们在要闻中随便复制一个新闻标题,然后检索一下,就可以获取到结果,如下图所示:
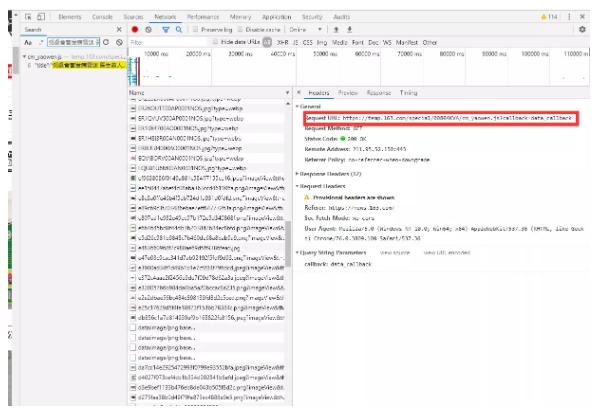
这样我们就快速的获取到了要闻数据的请求链接,链接为https://temp.163.com/special/00804KVA/cm_yaowen.js?callback=data_callback访问该链接,查看该链接返回的数据,如下图所示:

从数据我们可以看出,我们需要的数据都在这里啦,所以我们只需要解析这段数据接可以啦,要从这段数据中解析出新闻标题和新闻链接,有两种方式,一种是正则表达式,另一种是将该数据转成 json 或者 list。这里我选择第二种方式,利用 fastjson 将返回的数据转换成 JSONArray 。所以我们是要引入 fastjson ,在 pom.xml 中引入 fastjson 依赖:
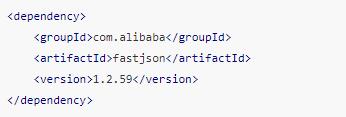
除了引入 fastjson 依赖外,我们在转换前还需要对数据进行简单的处理,因为现在的数据并不符合 list 的格式,我们需要去掉 data_callback( 和最后面的 )。具体反向解析获取网易要闻的代码如下:
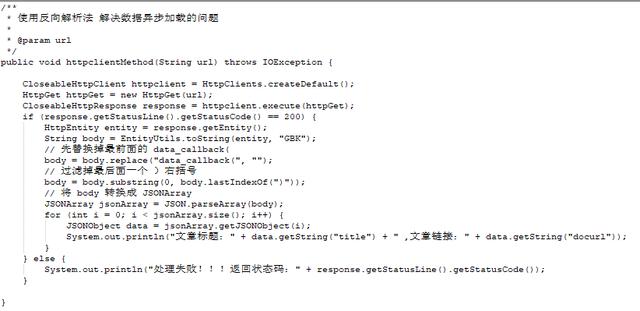
编写 main 方法,执行上面的方法,需要注意的地方是:这时候传入的链接为
https://temp.163.com/special/00804KVA/cm_yaowen.js?callback=data_callback 而不是
https://news.163.com/得到如下结果:
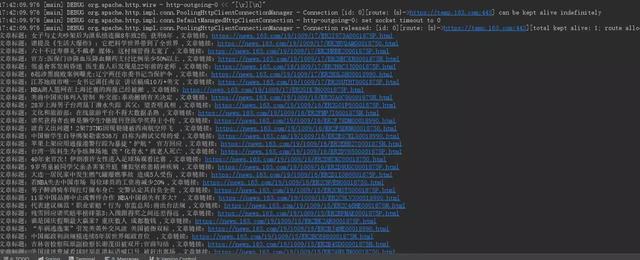
两种方法都成功的获取到了网易要闻异步加载的新闻列表,对于这两种方法的选取,我个人的倾向是使用反向解析法,因为它的性能和稳定是都要比内置浏览器内核靠谱,但是对于一些使用 JavaScript 片段渲染的页面,内置浏览器又更加靠谱。所以根据具体情况选择吧。
希望这篇文章对你有所帮助,下一篇是关于 爬虫IP 被封的问题。如果你对爬虫感兴趣,不妨关注一波,相互学习,相互进步
源代码:
https://github.com/BinaryBall/java-base/blob/master/crawler/src/main/java/com/jamal/crawler/CrawlerNews.java作者:平头哥的技术博文来源:掘金商业用途请与原作者联系,本文只做展示分享,不妥侵删!最后
以上就是满意蓝天最近收集整理的关于java https请求_Java 爬虫遇上数据异步加载,试试这两种办法1、内置一个浏览器内核2、反向解析法反向解析法的全部内容,更多相关java内容请搜索靠谱客的其他文章。








发表评论 取消回复