文章目录
- 1、 OpenCV的结构
- 2、python - opencv基础
- 2.1 图像的表示
- 2.2 基本处理
- 读存图像:cv.imread() cv.imwrite()
- 缩放、裁剪、补边
- 色调、明暗、直方图、Gamma曲线
- 仿射变换
- 渲染文字、图形
- 3 录制视频
本博客还有多个超详细综述,感兴趣的朋友可以移步:
卷积神经网络:卷积神经网络超详细介绍
目标检测:目标检测超详细介绍
语义分割:语义分割超详细介绍
NMS:让你一文看懂且看全 NMS 及其变体
数据增强:一文看懂计算机视觉中的数据增强
损失函数:分类检测分割中的损失函数和评价指标
Transformer:A Survey of Visual Transformers
机器学习实战系列:决策树
YOLO 系列:v1、v2、v3、v4、scaled-v4、v5、v6、v7、yolof、yolox、yolos、yolop
1、 OpenCV的结构
和Python一样,当前的OpenCV也有两个大版本,OpenCV2和OpenCV3。相比OpenCV2,OpenCV3提供了更强的功能和更多方便的特性。不过考虑到和深度学习框架的兼容性,以及上手安装的难度,这部分先以2为主进行介绍。
根据功能和需求的不同,OpenCV中的函数接口大体可以分为如下部分:
- core:核心模块,主要包含了OpenCV中最基本的结构(矩阵,点线和形状等),以及相关的基础运算/操作。
- imgproc:图像处理模块,包含和图像相关的基础功能(滤波,梯度,改变大小等),以及一些衍生的高级功能(图像分割,直方图,形态分析和边缘/直线提取等)。
- highgui:提供了用户界面和文件读取的基本函数,比如图像显示窗口的生成和控制,图像/视频文件的IO等。
如果不考虑视频应用,以上三个就是最核心和常用的模块了。针对视频和一些特别的视觉应用,OpenCV也提供了强劲的支持:
- video:用于视频分析的常用功能,比如光流法(Optical Flow)和目标跟踪等。
- calib3d:三维重建,立体视觉和相机标定等的相关功能。
- features2d:二维特征相关的功能,主要是一些不受专利保护的,商业友好的特征点检测和匹配等功能,比如ORB特征。
- object:目标检测模块,包含级联分类和Latent SVM
- ml:机器学习算法模块,包含一些视觉中最常用的传统机器学习算法。
- flann:最近邻算法库,Fast Library for Approximate Nearest Neighbors,用于在多维空间进行聚类和检索,经常和关键点匹配搭配使用。
- gpu:包含了一些gpu加速的接口,底层的加速是CUDA实现。
- photo:计算摄像学(Computational Photography)相关的接口,当然这只是个名字,其实只有图像修复和降噪而已。
- stitching:图像拼接模块,有了它可以自己生成全景照片。
- nonfree:受到专利保护的一些算法,其实就是SIFT和SURF。
- contrib:一些实验性质的算法,考虑在未来版本中加入的。
- legacy:字面是遗产,意思就是废弃的一些接口,保留是考虑到向下兼容。
- ocl:利用OpenCL并行加速的一些接口。
- superres:超分辨率模块,其实就是BTV-L1(Biliteral Total Variation – L1
regularization)算法 - viz:基础的3D渲染模块,其实底层就是著名的3D工具包VTK(Visualization Toolkit)。
从使用的角度来看,和 OpenCV2 相比,OpenCV3的主要变化是更多的功能和更细化的模块划分。
2、python - opencv基础
2.1 图像的表示
已知单通道的灰度图像在计算机中的表示是一个8位无符号整形的矩阵,在oncv的C++代码中,表示图像有专门的结构cv::Mat,但python中有numpy这种强大的基础工具,所以该矩阵就用numpy的array表示,多通道就是红绿蓝(RGB)三通道。
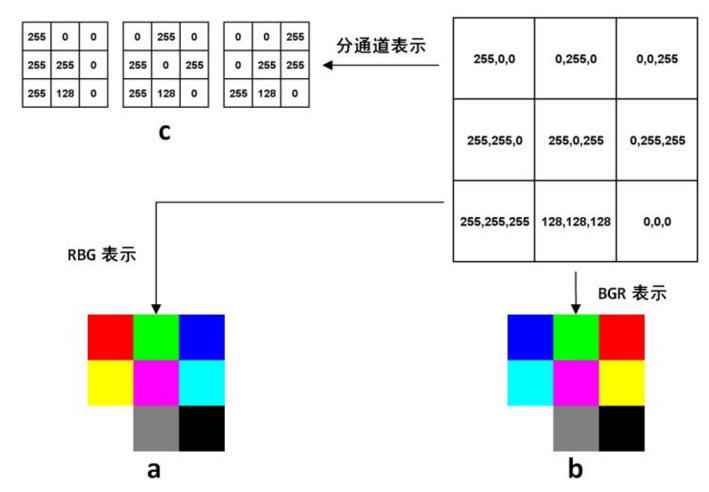
2.2 基本处理
读存图像:cv.imread() cv.imwrite()
可以按照不同模式读取,一般最常用到的是读取单通道灰度图,或者直接默认读取多通道
import cv2
color_img=cv2.imread('4.jpg')
print(color_img.shape)
# 读取单通道
gray_img=cv2.imread('4.jpg',cv2.IMREAD_GRAYSCALE)
print(gray_img.shape)
#把单通道图像保存后,再读取,仍然是3通道,相当于将单通道复制到3个通道保存
cv2.imwrite('grayscale_4.jpg',gray_img)
reload_grayscale=cv2.imread('grayscale_4.jpg')
print(reload_grayscale.shape)
# 指定jpg质量,范围从1~100,默认95,值越高画质越好,文件越大
cv2.imwrite('anglababy.jpg',color_img,(cv2.IMWRITE_JPEG_QUALITY,20))
缩放、裁剪、补边
-
缩放:cv2.resize()
-
裁剪:利用array下标截取实现
import cv2
img=cv2.imread('dog.jpg')
# 缩小为200x200的正方形
img_200x200=cv2.resize(img,(200,200))
# 不直接指定缩放后的大小,通过fx和fy指定缩放比例,0.5表示长宽各一半
# 插值方法默认为cv2.INTER_LINEAR,这里指定为最近邻插值
img_half=cv2.resize(img,(0,0),fx=0.5,fy=0.5,interpolation=cv2.INTER_NEAREST)
# 上下各贴50像素的黑边
img_add=cv2.copyMakeBorder(img,50,50,0,0,cv2.BORDER_CONSTANT,value=(0,0,0))
# 裁剪
patch_img=img[20:150,-180:-50]
cv2.imshow("image",img_200x200)
cv2.imshow("img_half",img_half)
cv2.imshow("img_add",img_add)
cv2.imshow("patch_img",patch_img)
cv2.waitKey(0)
色调、明暗、直方图、Gamma曲线
比如可以通过HSV空间对色调和明暗进行调节。HSV空间是由美国的图形学专家A. R. Smith提出的一种颜色空间,HSV分别是色调(Hue),饱和度(Saturation)和明度(Value)。在HSV空间中进行调节就避免了直接在RGB空间中调节是还需要考虑三个通道的相关性。OpenCV中H的取值是[0, 180),其他两个通道的取值都是[0, 256),下面例子接着上面例子代码,通过HSV空间对图像进行调整:
import cv2
img=cv2.imread('mushroom.jpg')
# 通过cv2.cvtcolor把图像从RGB转到HSV
img_hsv=cv2.cvtColor(img,cv2.COLOR_BGR2HSV)
# H空间中,绿色比黄色值高,所以给每个像素+15,黄色的就会变绿
turn_green_hsv=img_hsv.copy()
turn_green_hsv[:,:,0]=(turn_green_hsv[:,:,0]+15)
turn_green_img=cv2.cvtColor(turn_green_hsv,cv2.COLOR_HSV2BGR)
cv2.imshow("turn_green_img",turn_green_img)
# 减小饱和度会让图像损失鲜艳,变得更灰
colorless_hsv=img_hsv.copy()
colorless_hsv[:,:,1]=0.5*colorless_hsv[:,:,1]
colorless_img=cv2.cvtColor(colorless_hsv,cv2.COLOR_HSV2BGR)
cv2.imshow("colorless_img",colorless_img)
# 减小为原来的一半
darker_hsv=img_hsv.copy()
darker_hsv[:,:,2]=0.5*darker_hsv[:,:,2]
darker_img=cv2.cvtColor(darker_hsv,cv2.COLOR_HSV2BGR)
cv2.imshow("darker_img",darker_img)
cv2.waitKey(0)
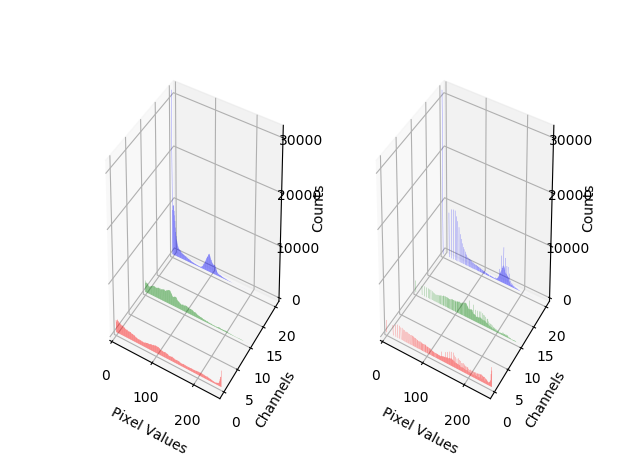
直方图:方便对图像的像素值分布了解更清晰,低的像素值表示暗的部分,高的值表示亮度大的部分,但是显示的时候可能就出现了暗部细节不足或者亮部细节丢失的情况。
Gamma变换:提升暗部细节,Gamma变换是矫正相机直接成像和人眼感受图像差别的一种常用手段,简单来说就是通过非线性变换让图像从对曝光强度的线性响应变得更接近人眼感受到的响应。
import numpy as np
import cv2
import matplotlib.pylab as plt
from mpl_toolkits.mplot3d import Axes3D
img=cv2.imread('4.jpg')
# 分通道计算每个通道的直方图
hist_b=cv2.calcHist([img],[0],None,[256],[0,256])
hist_g=cv2.calcHist([img],[1],None,[256],[0,256])
hist_r=cv2.calcHist([img],[2],None,[256],[0,256])
# Gamma变换的函数
def gamma_trans(img,gamma):
# 先归一化到1,之后利用gamma作为指数求出新值,再还原
gamma_table=[np.power(x/255.0,gamma)*255.0 for x in range(256)]
gamma_table=np.round(np.array(gamma_table)).astype(np.uint8)
# 用opencv的查表函数实现该映射
return cv2.LUT(img,gamma_table)
# 执行Gamma变换,小于1的值让暗细节大量提升,同时亮部细节少量提升
img_corrected=gamma_trans(img,0.5)
cv2.imshow("img",img)
cv2.imshow("img_corrected",img_corrected)
# cv2.waitKey(0)
# 分通道计算Gamma矫正后的直方图
hist_b_corrected=cv2.calcHist([img_corrected],[0],None,[256],[0,256])
hist_g_corrected=cv2.calcHist([img_corrected],[1],None,[256],[0,256])
hist_r_corrected=cv2.calcHist([img_corrected],[2],None,[256],[0,256])
# 直方图可视化
fig=plt.figure()
pix_hists=[
[hist_b,hist_g,hist_r],
[hist_b_corrected,hist_g_corrected,hist_r_corrected]
]
pix_vals=range(256)
for sub_plt,pix_hist in zip([121,122],pix_hists):
ax=fig.add_subplot(sub_plt,projection='3d')
for c,z,channel_hist in zip(['b','g','r'],[20,10,0],pix_hist):
cs=[c]*256
ax.bar(pix_vals,channel_hist,zs=z,zdir='y',color=cs,alpha=0.618,
edgecolor='none',lw=0)
ax.set_xlabel('Pixel Values')
ax.set_xlim([0,256])
ax.set_ylabel('Channels')
ax.set_zlabel('Counts')
plt.show()


仿射变换
图像的仿射变换涉及到图像的形状位置角度的变化,是深度学习预处理中常到的功能,在此简单回顾一下。仿射变换具体到图像中的应用,主要是对图像的缩放,旋转,剪切,翻转和平移的组合。在OpenCV中,仿射变换的矩阵是一个2×3的矩阵,其中左边的2×2子矩阵是线性变换矩阵,右边的2×1的两项是平移项:
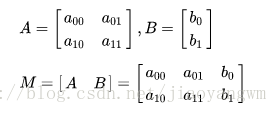
对于图像上的任一位置(x,y),仿射变换执行的是如下的操作:
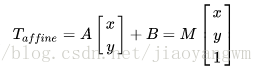
需要注意的是,对于图像而言,宽度方向是x,高度方向是y,坐标的顺序和图像像素对应下标一致。所以原点的位置不是左下角而是右上角,y的方向也不是向上,而是向下。在OpenCV中实现仿射变换是通过仿射变换矩阵和cv2.warpAffine()这个函数:
import numpy as np
import cv2
img = cv2.imread('dog.jpg')
# 沿着横纵轴放大1.6倍,之后平移(-150,-240),最后沿原图大小截取,等效于剪裁并放大
M_crop_dog = np.array([
[1.6, 0, -150],
[0, 1.6, -240]
], dtype=np.float32)
# cv2.warpAffine(原始图像, 变换矩阵,变换后的图像大小)
img_dog = cv2.warpAffine(img, M_crop_dog,(400, 400))
cv2.imshow("img_dog", img_dog)
# x轴的剪切变换,逆时针旋转角度15°
theta=15*np.pi/180
M_shear=np.array([
[1,np.tan(theta),0],
[0,1,0]
],dtype=np.float32)
img_sheared=cv2.warpAffine(img,M_shear,(400,600))
cv2.imshow("img_sheared",img_sheared)
# 顺时针旋转,角度15°
M_rotate=np.array([
[np.cos(theta),-np.sin(theta),0],
[np.sin(theta),np.cos(theta),0]
],dtype=np.float32)
im_rotate=cv2.warpAffine(img,M_rotate,(400,600))
cv2.imshow("im_rotate",im_rotate)
# 旋转+缩放+旋转组合,可以通过SVD分解理解
M=np.array([
[1,1.5,-400],
[0.5,2,-100]
],dtype=np.float32)
img_transformed=cv2.warpAffine(img,M,(400,600))
cv2.imshow("img_transformed",img_transformed)
cv2.waitKey(0)



渲染文字、图形
if __name__ == '__main__':
frames = 300
font = cv2.FONT_HERSHEY_SIMPLEX
blueColor = (255, 0, 0)
for fid in range(frames):
img = cv2.imread("truck.jpg")
cv2.putText(img, str(fid), (10, 50), font, 1.5, blueColor, 3)
cv2.imwrite(str(fid) + ".jpg", img)

3 录制视频
# -*- coding:utf8 -*-
import os
import cv2
from utils import load_coefficients
if __name__ == "__main__":
vidcap = cv2.VideoCapture(0)
vidcap.set(cv2.CAP_PROP_FRAME_WIDTH, 1920)
vidcap.set(cv2.CAP_PROP_FRAME_HEIGHT, 1080)
vidcap.set(cv2.CAP_PROP_FPS, 30)
vidcap.set(cv2.CAP_PROP_FOURCC, cv2.VideoWriter_fourcc('M', 'J', 'P', 'G'))
# 参数文档
# https://blog.csdn.net/m0_37605642/article/details/121045914
# https://docs.opencv.org/4.6.0/d4/d15/group__videoio__flags__base.html#ggaeb8dd9c89c10a5c63c139bf7c4f5704da95753013fd8f0c0af3f743dc0293844b
# 以下参数设置参考软件,AMCap.exe,对该设备的默认设置读取
# 亮度
vidcap.set(cv2.CAP_PROP_BRIGHTNESS, 0)
# 对比度
vidcap.set(cv2.CAP_PROP_CONTRAST, 32)
# 饱和度
vidcap.set(cv2.CAP_PROP_SATURATION, 64)
# 色调
vidcap.set(cv2.CAP_PROP_HUE, -4)
# 图像增益
vidcap.set(cv2.CAP_PROP_GAIN, 0)
# 伽马
vidcap.set(cv2.CAP_PROP_GAMMA, 100)
# 逆光对比
vidcap.set(cv2.CAP_PROP_BACKLIGHT, 0)
# 自动曝光开启
# vidcap.set(cv2.CAP_PROP_AUTO_EXPOSURE, 3)
# 自动白平衡开启
vidcap.set(cv2.CAP_PROP_AUTO_WB, 3)
# 自动聚焦开启
# vidcap.set(cv2.CAP_PROP_AUTOFOCUS, 3)
frame_count = int(3000000000)
frame_height = int(vidcap.get(cv2.CAP_PROP_FRAME_HEIGHT))
frame_width = int(vidcap.get(cv2.CAP_PROP_FRAME_WIDTH))
fps = vidcap.get(cv2.CAP_PROP_FPS) # 视频平均帧率
print(fps)
save_path = os.path.join("./output_vis_3")
os.makedirs(save_path, exist_ok=True)
outcap = cv2.VideoWriter(os.path.join(save_path, "output.mp4"),
cv2.VideoWriter_fourcc('M', 'P', '4', 'V'), fps, (frame_width, frame_height))
# Load coefficients
mtx, dist = load_coefficients('calibration_chessboard.yml')
count = 0
while vidcap.isOpened():
ret, image_bgr = vidcap.read()
# image_bgr = cv2.undistort(image_bgr, mtx, dist, None, None)
count += 1
if count > frame_count:
break
if not ret:
continue
cv2.imshow("img", image_bgr)
# 录屏可视化逻辑
if cv2.waitKey(1) == ord('q'):
break
# 标定保存图片逻辑
# if cv2.waitKey(1) == ord('c'):
# img_file = os.path.join(save_path, 'pose_{:08d}.jpg'.format(count))
# cv2.imwrite(img_file, image_bgr)
outcap.write(image_bgr)
vidcap.release()
outcap.release()
最后
以上就是拉长火最近收集整理的关于【基础知识】4、python-opencv 入门基础知识1、 OpenCV的结构2、python - opencv基础3 录制视频的全部内容,更多相关【基础知识】4、python-opencv内容请搜索靠谱客的其他文章。








发表评论 取消回复