一直想写篇度量指标的文章,梳理一下这块的知识点,可能想了太多次,总以为自己已经写过了,今天看文章列表,竟然没有相关的内容,刚好最近在做多分类模型,借此机会整理一下。
混淆矩阵(confusion matrix)
在介绍各种指标前,先介绍混淆矩阵,基本所有的评价指标都是基于混淆矩阵计算得来的。
混淆矩阵每一行代表数据的真实类别,每一列代表预测类别。
以下是一个三分类问题的混淆矩阵:
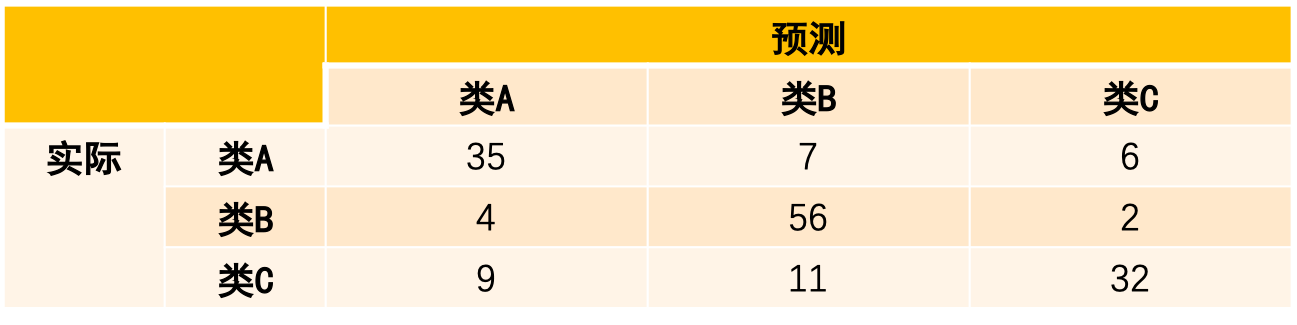
二分类和多分类都有混淆矩阵,为了后面介绍指标时参数含义容易理解,我们以二分类的混淆矩阵为例。

- TP:True Positive,真阳性, 正样本分类为正样本
- FP:False Positive,假阳性,负样本分类为正样本
- TN:True Negative,真阴性, 负样本分类为负样本
- FN:False Negative,假阴性,正样本分类为负样本
二分类常用指标
- 准确率(Accuracy)
分类正确的样本占总样本的比例
Accuracy =(TP+TN)/(TP+FP+TN+FN)
但是,准确率在不均衡的样本集上度量效果很差。比如,一个二分类的样本中,有90个????类别,10个????类别,模型把所有样本都分类为????,此时,模型的准确率为90%,但显然模型的实际分类性能很差。
因此,引出以下指标。 - 精确率/查准率(Precision)/阳性预测值(positive predictive value,PPV)
预测为正且实际为正的样本占预测为正的样本的比例
Precision =TP/(TP+FP) - 召回率/查全率(Recall)/真阳性率(true positive rate,TPR)/敏感度(Sensitivity)
预测为正且实际为正的样本占实际为正的样本的比例;换句话说,它是正样本中被预测为正的比例。
Recall = TP/(TP+FN) - F1-score
召回率和精确率之间往往存在此消彼长的关系,当模型能找出更多的正样本时,往往也会导致将更多的负样本分类为正样本,即recall高时,precision往往较低,而precision高时,recall往往较低。为了在这两个指标之间取得平衡,发明了F1指标,它是上述两者的调和平均数。
F1 = 2Precision*Recall/(Precision+Recall)
除了这四个最常用的指标,还有几个值得了解。
- 特异度(Specificity)/真阴性率(true negative rate,TNR)
和recall类似,它是负样本中被预测为负样本的比例。
TNR = TN/(TN+FP) - 误报率(False discovery rate, FDR)
预测为正的样本中,实际为负的样本所占比例。
FDR = FP/(FP+TP) = 1- Precision - 阴性预测值(Negative Predictive Value,NPV )
预测为负的样本中负样本的比例。
NPV = TN/(TN+FN) - kappa系数
Kappa系数是一个用于一致性检验的指标,也可以用于衡量分类的效果。对于分类问题,所谓一致性就是模型预测结果和实际分类结果是否一致。
kappa系数的提出也是因为准确率指标存在的问题,因此它能够惩罚模型的“偏向性”,根据kappa的计算公式(下图),越不平衡的混淆矩阵,Pe越高,kappa值就越低,正好能够给“偏向性”强的模型打低分。
kappa系数的取值为-1到1之间,通常大于0。可分为五组来表示不同级别的一致性:0.0~0.20极低的一致性(slight)、0.21~0.40一般的一致性(fair)、0.41~0.60 中等的一致性(moderate)、0.61~0.80 高度的一致性(substantial)和0.81~1几乎完全一致(almost perfect)。
考虑到一个数据集中正负样本的比例可能随着时间(/阈值)的改变而发生变化,且实际数据集常存在样本分布不均衡的情况,因此又有一个新的指标被发明出来。
- ROC曲线/AUC(Area Under the Curve,曲线下面积)
ROC曲线(receiver operating characteristic curve), 是反映敏感性和特异性连续变量的综合指标,曲线下面积越大,诊断准确性越高。
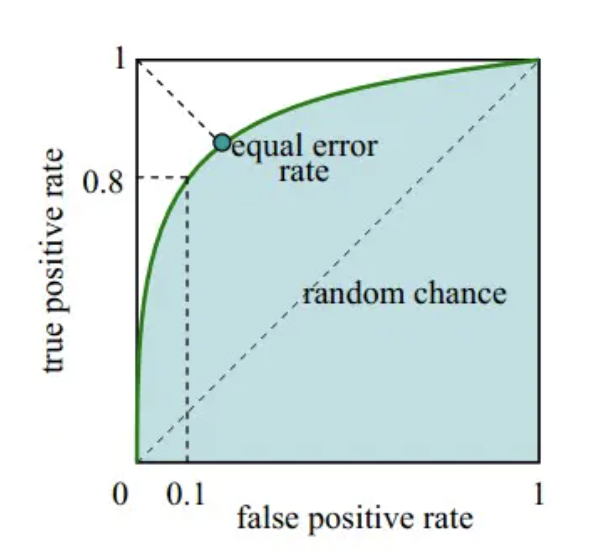
- 横坐标:1-Specificity,伪正类率(False positive rate,
FPR),预测为正但实际为负的样本占所有负例样本的比例; - 纵坐标:Sensitivity,真正类率(True positive rate,
TPR),预测为正且实际为正的样本占所有正例样本的比例。
这条线到底是如何画出来的呢?
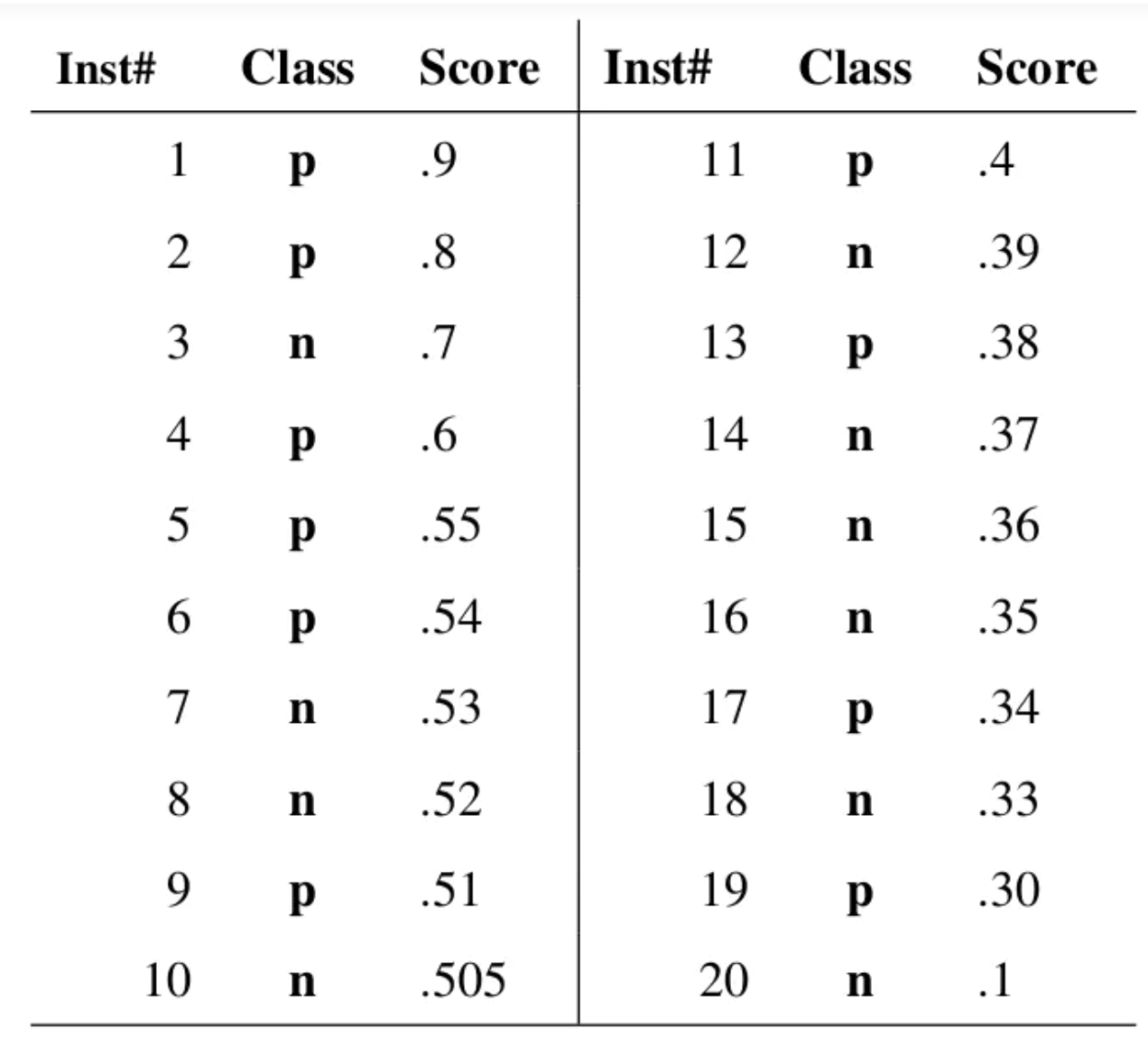
假如有上面这样一组数据,score是将该样本分为正样本的阈值,我们取不同的阈值就会得到不同的分类结果,对应多组FPR和TPR,即ROC曲线上的一点,这样就可以画出曲线了。
由于不受阈值影响,roc曲线可以用来评价一个分类器。而Precision-Recall曲线则会随着正负样本数量的变化而变化较大。
多分类常用指标
以上的计算公式一般只适用于二分类模型,对于多分类模型的评价方法,通常是先将其转换为多个二分类模型,分别对其进行指标计算,然后使用一些规则来把这些指标汇总起来。
比如一个多分类模型的样本标签有A、B、C三类,则先把它看作三个二分类器,分类器1的标签为A,非A;分类器2的标签为B,非B;分类器3的标签为C,非C。对每个二分类器的评估我们已经知道了,但要评估分类器的总体功能,就需要考虑三个类别的综合预测性能。
下面有三种常用的汇总准则:
- Macro-average方法
对各个二分类器的评估指标求平均。该方法受样本量小的类别影响大。 - Weighted-average方法
对各个二分类器的评估指标求加权平均,权重为该类别在总样本中的占比。该方法受样本量大的类别影响大。 - Micro-average方法
把每个类别的TP, FP, FN先相加之后,在根据二分类的公式进行计算。
参考链接:
二分类和多分类问题的评价指标总结
多分类模型Accuracy, Precision, Recall和F1-score的超级无敌深入探讨
详解多分类模型的Macro-F1/Precision/Recall计算过程
kappa系数简介
机器学习之分类性能度量指标 : ROC曲线、AUC值、正确率、召回率
最后
以上就是秀丽未来最近收集整理的关于常用分类评估指标(二分类&多分类)的全部内容,更多相关常用分类评估指标(二分类&多分类)内容请搜索靠谱客的其他文章。








发表评论 取消回复