随着IT企业的发展,很多企业、政府机构、组织机构都部署有自己的数据中心,用来满足自己的存储、计算等IT需求。在数据中心网络当中,典型的存在着以下两种流量:
存储数据流:要求无丢包;
普通数据流:允许一定的丢包和时延。
很显然两种数据流对服务的要求是不同的,因而传统的数据中心也往往会部署两个网络来满足对数据中心的这些需求。这种网络在一定意义上来说是冗余的,会造成资源的浪费,当数据中心规模扩大时,这种方案就变的不可接受了。因此急需一种可以将两种网络统一起来的网络技术。
当将这两个网络进行融合时,需要对两个网络进行考察:
普通数据流:它没什么特殊要求
存储数据流:存储网一般采用FC协议,存储也是传统数据中心最主要的业务,因而对两个网络进行融合,最重要的就是要保护客户在存储上的投资。为此一些IT厂商提交了一个协议规范FCoE,FCoE(Fibre Channel over Ethernet)技术标准可以将光纤通道映射到以太网,从而可以在以太网上传输SAN数据。它能够在保护客户在现有FC-SAN上的投资(如FC-SAN的各种工具、员工的培训、已建设的FC-SAN设施及相应的管理架构)的基础上,提供一种以FC存储协议为核心的I/O整合方案。由于FC不允许丢包,因而在采用FCoE时,必须对以太网进行增强以使得以太网不丢包。
当不考虑上层承载业务,并且考虑以当今最普遍的以太网为基础进行网络融合时,需要考虑的最主要就是不能丢包。为此IEEE定义了DCB,DCB是IEEE 提出的数据中心桥接技术,主要包含:
IEEE 802.1Qbb Priority-based Flow Control(PFC):用于满足两种流量在以太网中共存时,存储流量无丢包,且对其它的流量无影响的要求。
IEEE 802.1Qaz Enhanced Transmission Selection(ETS):用于避免一种流量类型的大规模流量猝发影响其它流量类型,为不同的流量类型提供最小带宽保证。一种流量类型只有在其它流量类型带宽不占用的情况下,才能使用分配带宽之外的额外带宽。这使多种流量类型可在同一网络中和谐共存。
Data Center Bridging eXchange(DCBX):它是基于LLDP(Link Layer Discovery Protocol)的扩展协议,用于在设备间自动协商并配置PFC、ETS及CN等。
IEEE 802.1Qau Congestion Notification:用于降低引起拥塞的端点站的报文发送速率,从根源上避免拥塞,以保持网络的畅通,解决因拥塞引发报文重传或流量控制,导致报文时延增加的问题。
DCB使得以太网可以承载两种不同类型的数据流。同时由于ETS可以为某种流量提供最小带宽保证,因而除了将普通数据流和存储数据流融合到一起之外,采用了DCB技术的网络还可以用来承载计算业务(用ETS在网络中为计算业务分配相应的带宽即可保证计算业务所需的时延保证)。
一. PFC
1. 概述
PFC(Priority Flow Control)是DCB的一部分,它适用于DCB网络中的全双工的点到点链路。PFC是对IEEE 802.3定义的流控机制的增强,用于在一个链路上消除由于拥塞而导致的丢包。它的增强在于它是基于优先级的。传统的流控机制中,当某条链路出现拥塞时流控会阻止该链路上的所有流量。而PFC允许在一条以太网链路上创建8个虚拟通道,并为每条虚拟通道指定一个IEEE 802.1P优先等级(cos),允许单独暂停和重启其中任意一条虚拟通道,同时不影响其它虚拟通道的流量。比如下图
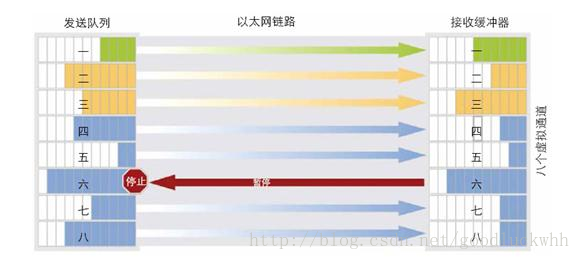
该图中虚拟通道六的流量将被暂停,而其它通道的服务不会受到影响。
PFC使得网络管理员可以将其中一些优先级(最多8个)用于对丢包敏感的上层协议(比如FC),而另一些优先级用于常规的以太网服务。
2. 报文格式
PFC的报文就是一个以太网报文,其格式如下:
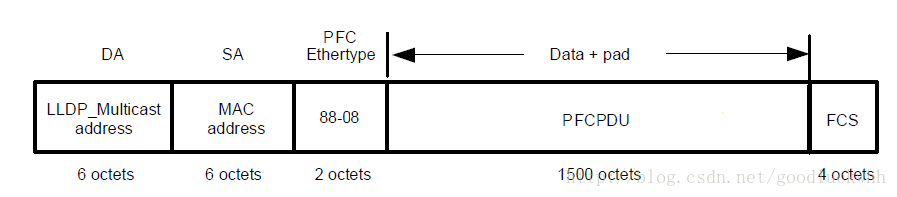
- DA:目的 MAC地址,为固定的组播 MAC地址 01-80-c2-00-00-01。
- SA:源 MAC地址。
- Type:报文类型,为 0x8808。
- Data:数据,为 PFCPDU。
- FCS:帧检验序列。
其中PFCPDU不包括pad部分的格式如下:
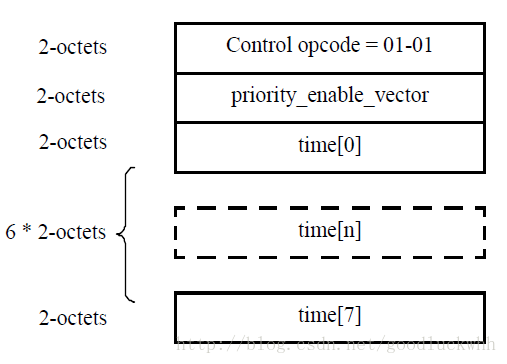
- Control opcode:MAC控制操作码,2字节。PFC PAUSE帧仅是MAC控制帧的一种,对于PFC PAUSE帧,其在MAC控制帧中的操作码为01-01;
- priority_enable_vector:2字节,高字节置0,低字节的每个位代表相应的time[n]是否有效。priority_enable_vector[n]代表优先级n,当priority_enable_vector[n]为1时,表示time[n]有效;当priority_enable_vector[n]为0,表示time[n]无效。
- time:包含time[0] 至time[7]的8个数组单元,每个数组单元为2字节。当priority_enable_vector[n]为0时,time[n]没有意义。当priority_enable_vector[n]为1时,time[n]代表接收站点应该停止优先级为n的报文的发送的时间,时间的单位为物理层芯片发送512位数据所需要的时间。所以发送一次PFC PAUSE帧,要求对端设备暂停发送的时间长度最长为:65535 ×物理层芯片发送512位数据所需要的时间。
3. 工作机制
3.1 支持PCF设备的要求
如果一个设备支持PCF,则它要:
- 支持在一个或多个端口上至少在一个优先级上使能PFC
- 只能在受DCBX管理的域上使能PFC
- 提供PFC aware的系统排队功能(即排队系统需要了解PFC信息并且根据PFC的状态做出是否发送的决策)
- 遵守PFC的延迟限制
3.2 典型的工作过程
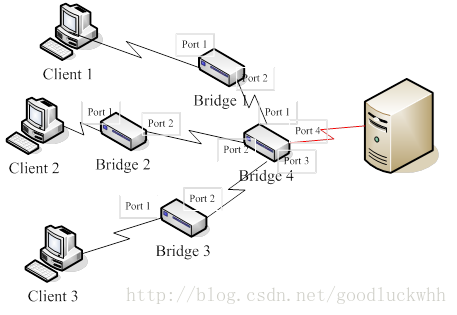
以图中拓扑为例,假设向红色链路转发的数据量超过了该链路的最大速率,则最终会导致Bridge 4上向该链路转发的数据无法被转发,此时即出现了拥塞。根据网桥的工作原理,这最终会反映在某些输入端口的输入队列变满上,在此图中由于Bridge 4的port 1,2,3都用于向红色链路转发数据,因而它们的输入队列都会逐渐变满。此时port 1,2,3都会通过各自的链路向上游发送拥塞指示,上游收到拥塞指示后,就会停止往该链路发送数据,以Bridge 1为例,它就会停止从port 2发送数据,这又进一步会导致Bridge 1的port 1的输入队列逐渐被填满,此时Bridge 1又会向其上游发送拥塞指示,该过程一直持续直到到达数据的源头,对于例子中的拓扑,最终结果就是Client 1,2,3都会收到拥塞指示(更确切的说不一定所有的都会收到,一个链路的上游是否会收到拥塞指示关键取决于该链路的下游的输入队列是否逐渐变满)。
3.3 工作机制
PFC是用于数据中心的一种技术,它是对IEEE 802.3定义的流控机制的增强,它使得一个链路不会由于出现拥塞而丢包。但是PFC也有缺点,它可能会导致拥塞信息被一直向上游传递,如果使用PFC的同时也使能了CN,则会降低PFC被使用的频率。
在实际的网络中PFC经常结合ETS功能一起使用,做法是使用ETS为某种流分配一定的带宽,同时给该类流分配一个优先级并启用PFC,这样就既能保证该类流不丢包又能保证其带宽。
PFC被设计仅用于点到点的全双工链路,一个典型的使用PFC的点到点链路如下图所示:
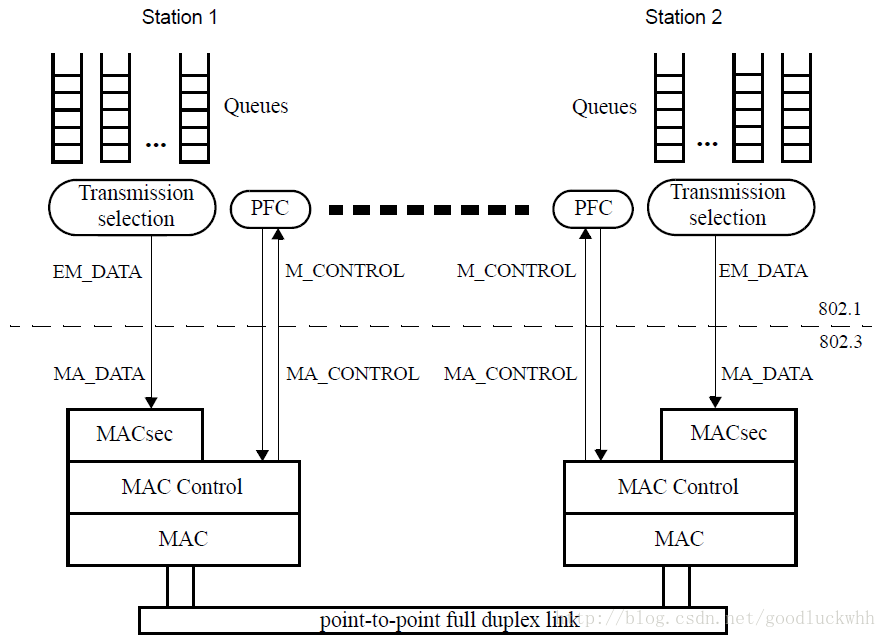
与传统的(802.3定义的)流控相比,PFC可以基于优先级工作。这就使得它可以单独禁止与某(些)个优先级相关联的流的发送而不影响其它优先级的流,传统的流控则无法做到这一点。
标准建议对于默认优先级不要使能PFC功能。
3.3.1 发送拥塞通知:
在点到点的全双工链路中:
如果一端发现其在某个优先级上出现了拥塞,并且该优先级上启用了PFC,就向另一端发送PFC帧来通知另一端在一段时间内不要再(在某个优先级上)发送数据;
如果发现其在某个优先级上的拥塞解除了,并且该优先级上启用了PFC,就向另一端发送PFC帧来通知另一端可以重新(在某个优先级上)发送数据;
简单的说就是在点到点的全双工链路中,如果一端发现其在某个优先级上的拥塞状态发生了变化,并且在该优先级上启用了PFC功能,就向另一端发送PFC帧来通告这个变化。
3.3.2 接收拥塞通告
在点到点的全双工链路中如果一端收到了一个PFC帧,则它首先解析8个优先级对应的信息:
如果本端在某个优先级上没有启用PFC,则忽略该优先级的信息,否则
如果priority_enable_vector向量中对应该优先级的比特为1,且time[该优先级]不为0,则如果该优先级的发送没有停止就停止它,同时根据时间值启动一个定时器,在该定时器到期之前,该优先级的发送会被停止
如果priority_enable_vector向量中对应该优先级的比特为1,且time[该优先级]为0,则如果该优先级的发送是被停止的,就启动它,并停止相应的定时器
如果priority_enable_vector向量中对应该优先级的比特为0,则如果该优先级的发送是被停止的,就启动它,并停止相应的定时器
3.3.3 延迟限制
PFC的目地是消除链路由于拥塞而出现的丢包,因而PFC帧的发送必须满足一定的时间要求。如果发送端在自己的接收队列满之后再发送拥塞通告,则在PFC帧从发送端到接收端传输过程中,另一端发送的数据就会因为没有接收缓存而被丢弃;如果发送端过早的发送了PFC帧,虽然不会丢包但是却会导致网络利用率下降。最合适的发送拥塞通告的时机是接收缓存还有存储空间可以存储一段时间内另一端能发送的所有数据,所谓的一段时间是指发送PFC帧的一端从判断是否要发送PFC帧到对端接收到PFC帧并决定停止新的数据发送之间的时间。具体如图所示:
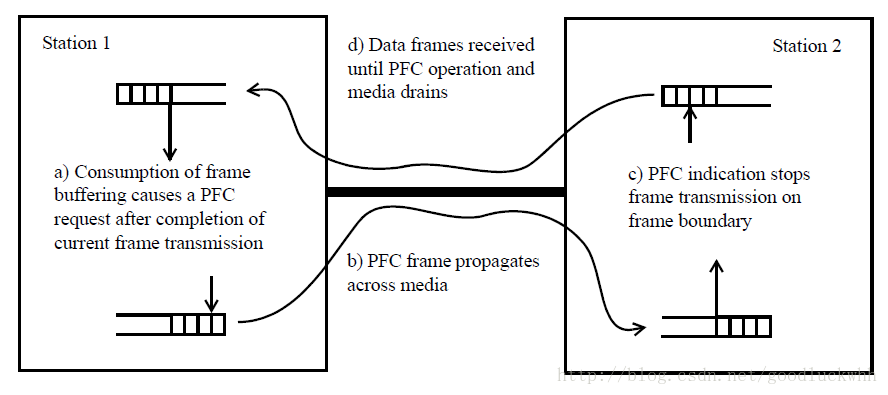
如图可以看出所谓的一段时间由四部分组成:
- 发送端产生PFC请求以及PFC帧的排队时间
- PFC帧被发送到另一端的时间
- PFC帧在接收端排队时间
- PFC帧被接收端处理并最终停止发送新数据的时间
对比广域网中的拥塞处理,比如TCP的拥塞检测、避免算法, 其中很关键的一部分是计算RTT,但是在DCB好像没有计算RTT的部分,这正是局域网与广域网的不同之处,在广域网中,你无法知道你的数据需要经过多少条物理链路,以及这些物理链路具有什么样的特性(比如速率,带宽等等),因而RTT必须经过探测才能知道(为了尽可能准确还要取平均数,进行平滑计算等等),但是在DCB中,PFC是在一条具体的物理链路上生效的,而这个物理链路的速率,带宽,队列深度都是可知的,因而无需通过收发报文来探测RTT,完全可以通过估算来获取比较准确的RTT。
从网络基础理论上来说,数据在分组交换网路中传输需要经历四种时延:处理时延,排队时延,传输时延和传播时延,对于一个接口芯片来说,处理时延、排队时延、传输时延必须保证接口能够达到它所声明的带宽(如果接口芯片的时延不能保证这一段,则无论如何接口也无法达到它所声明的速率),因此如果我们知道了接口的速率就可以知道这三种时延的最大值,而传播时延取决于物理线路的材质,只要材质确定,线路长度可知,这个时延也是可知的,因此说在一条具体的物理线路上我们是可以知道这几个时延的,也就无需计算RTT。简单的说,局域网中的拥塞探测方法之所以和广域网不同(没那么复杂)是因为具体的物理线路上的时延是可估算的,而且对于芯片来说处理逻辑越简单越好,因为这样可以简单芯片的设计复杂度。
转载自:https://blog.csdn.net/goodluckwhh/article/details/11539111?utm_source=blogxgwz1
最后
以上就是怕黑电话最近收集整理的关于DCB工作机制解析一(PFC)的全部内容,更多相关DCB工作机制解析一(PFC)内容请搜索靠谱客的其他文章。








发表评论 取消回复