YOLO同样是经典论文,后续很多论文以此为基础,例如YOLO9000、YOLOv3等, 如果有写的不对、有问题或者看不懂的地方,还望指正。如果有了新的理解,我会持续更新。
文章2016年发表,当时的视觉检测模型有两个问题,一个是速度快但是准确率差,另一种是准确率高但是速度很慢(faster rcnn 当时只有 3 - 5 FPS)。这类,无论在学术界还是工程界,都有很大的改进空间。作者为此提出了YOLO。
不说没用的,还是主要看目标检测的部分和YOLO本身的特点。
首先看YOLO的工作流程:

上图是原文中的,工作流程分成三个步骤:
- 缩放图像
- 将图像过全卷积神经网络
- 利用极大值抑制(NMS)进行筛选
然后来看算法的具体流程。
一 、图像分割
在YOLO中,一张输入图像首先被分成了 S × S 个均等大小的栅格,每一个格子都称作一个 grid cell。
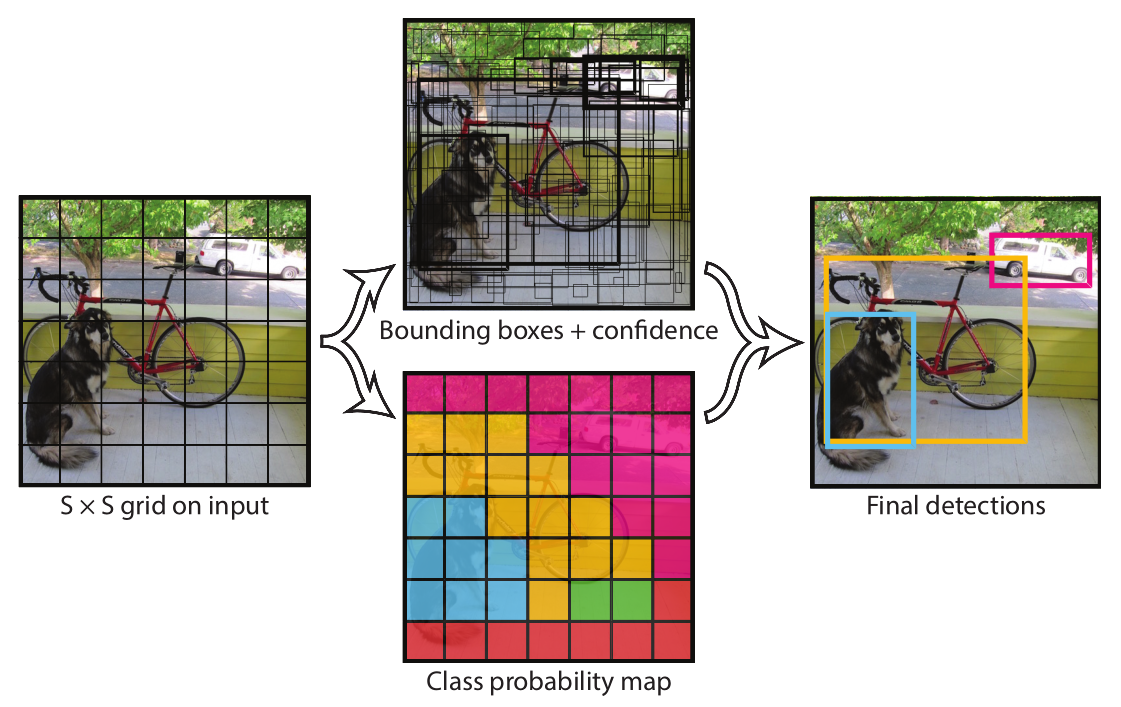
上图中左图作为输入图像,被分成了 7 × 7 个小的栅格,后续的工作和这些栅格息息相关。
二、 Bounding boxes 预测
从上图中也能看出,分割后的图像分成两路来处理,
1. 先看 bounding boxes + confidence 。在这一步中,YOLO 为每一个栅格给出了两个预测框,这里有点像faster rcnn 的anchor ,但不完全相同。YOLO给出的预测框,是基于栅格中心点的,大小自定义。每一个栅格预测 B 个bounding boxes,每个bounding boxes 有四个坐标和一个置信度,所以最终的预测结果是 S × S × (B ∗ 5 + C)个向量。原文中的 B= 2,意思是有两个预选框,C = 20,表示有20种类别,S = 7。
2. 再看第二个class probablity map,这一路的工作其实是和上一部一同进行的,负责的是栅格的类别,预测的结果一样是放在 最后的 7 × 7 × 30 的结果中
三、网络结构:
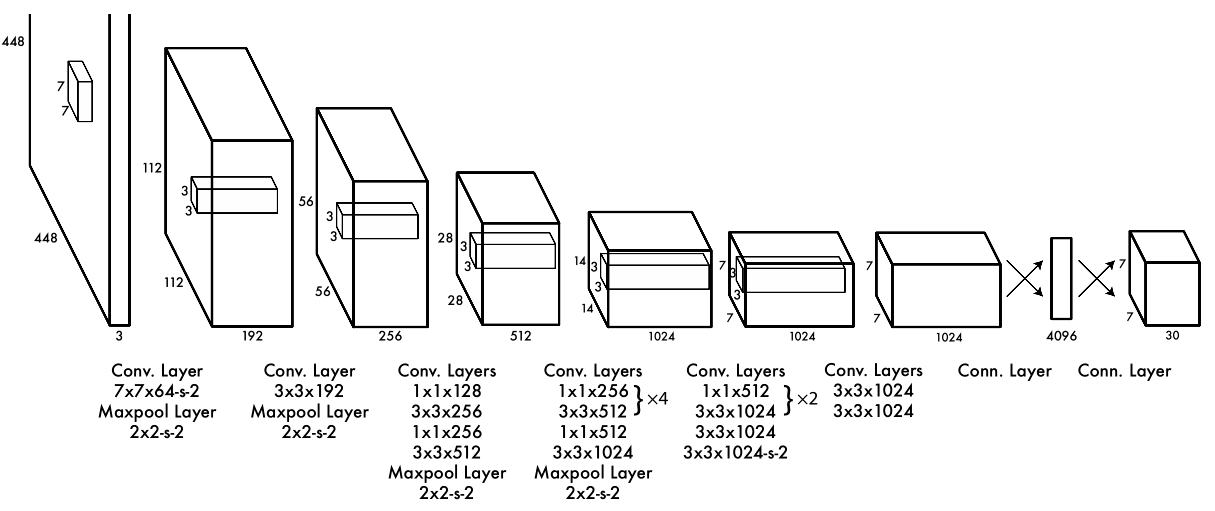
YOLO的网络结构很简单,前面是一个已经预训练的全卷积网络,后面又增加了4个卷积层,最后加了两个全连接网络,生成的结果就是刚才提到的 7 × 7 × 30 。7 × 7 × 30 的结果分成30个向量,结果的含义如下图(画图太麻烦了,就手写了):

3. 结果怎么来的?
我们知道了整个模型处理数据的流程,那这些坐标值和置信度包括训练方式是什么样的呢?
3.1 坐标值、置信度:
在YOLO中,预测结果中含有 这几个数据,其中:
是bounding box 的中心相对于单元格的偏移量
这篇博客中讲的比较清楚:https://blog.csdn.net/u011974639/article/details/78208773
看完应该知道,所有的参数最后都是归一化的,也就是说 x,y,w,h,C 这些参数的值都在0 - 1之间。有了这些参数就能定义Loss function 然后开始训练了。
3.2 Loss function

上面的损失函数分成了三个部分
- 坐标值偏差
- 置信度偏差
- 预测概率偏差
中心点偏差使用的是均方差(因为简单),宽高使用的是先开根号再求误差(为了减小偏差太大导致的预测框偏离目标,先开根号可以减小这种影响)
以上,目标检测的流程基本就结束了,总结一下就是:
训练过程:首先将图像分成 S × S 栅格、然后将图像送入网络,生成S × S × (B ∗ 5 + C)个结果,根据结果求Loss并反向传播梯度下降。
预测过程:首先将图像分成 S × S 栅格、然后将图像送入网络,生成S × S × (B ∗ 5 + C)个结果,用NMS选出合适的预选框。
至于为什么要用栅格:1. 每一条结果和划分的栅格对应。 2. 结果归一化以栅格为基础,分类也是以栅格为基础
最后
以上就是朴实冥王星最近收集整理的关于深度学习 -- YOLO 算法流程详解的全部内容,更多相关深度学习内容请搜索靠谱客的其他文章。








发表评论 取消回复