基本数据类型
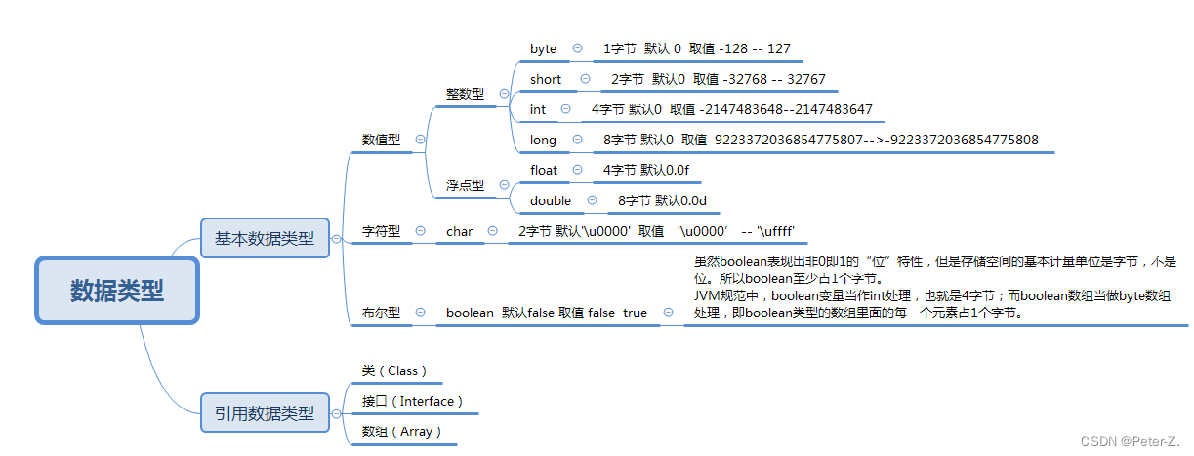
1B(Byte字节)=8bit
1000个汉字—utf-8编码格式—占用2.95k,接近3k。
这是因为utf-8编码格式下1个字符占3字节(占3000*8个位,64位操作系统一次处理字节宽可达64位),相当于3000B,接近3k。
Java类
初始化顺序
无继承情况:
先执行静态代码(多处静态代码的,先到先得)——非静态属性(字段、方法,先到先得)——构造方法
有继承情况: 由父及子,静态先行
父类静态代码——子类静态代码——父类非静态代码——父类构造函数——子类非静态代码——子类构造函数
https://blog.csdn.net/qq_55627064/article/details/121793316
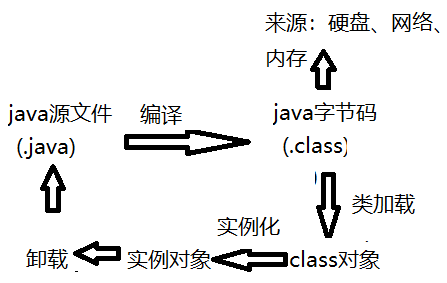
类的生命周期
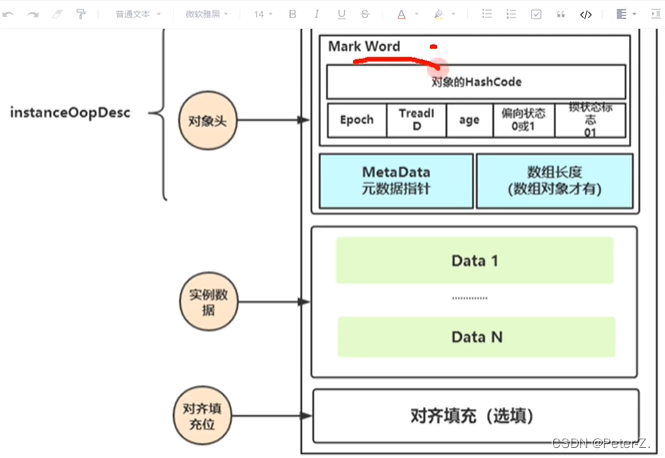
类的组成结构:对象头、成员变量/方法、对齐填充位
字符数组初始化
char a[]={'1','2','3'};//可以不指定char类型的个数,
char []b={'1','2','3'};
char []c=new char[]{'1','2','3'};
char []d=new char[3];
d[0]='1';
d[1]='2';
d[2]='3';
String、StringBuffer、StringBuilder
Stirng:final修饰,存放在字符串常量池或堆中
StringBuffer(内存中为字符串数组):线程安全,append()方法加了一个synchronized锁,所以保证了线程的安全性,StringBuffer的性能也比StringBuilder低
StringBuilder:速度快,线程不安全
String s = "hello"和String s2 = new String(“hello”)区别?
先看方法区中常量池“hello”是否存在,不存在,先会在在常量池创建常量对象,然后在堆中创建对象(new)
public class TestMem {
public static void main(String[] args) {
String s1 = "hello";
String s2 = "world";
String s3 = "helloworld";
String s4 = s1+s2;
System.out.println(s3==s4);
System.out.println(s3.hashCode());
System.out.println(s4.hashCode());
System.out.println(System.identityHashCode(s3));
System.out.println(System.identityHashCode(s4));
}
}
======结果======
false
-1524582912
-1524582912
1329552164
363771819
s3和s4的hashCode一样,但是内存地址不一样。
由此可知,要想获取对象的内存地址应使用System.identityHashCode()方法
字符串、json对象、javaBean转换

JSON字符串、对象数组转换
try catch finally执行顺序
结论:
- 不管有木有出现异常,finally块中代码都会执行;
- 当try和catch中有return时,finally仍然会执行;
- finally是在return后面的表达式运算后执行的(此时并没有返回运算后的值,而是先把要返回的值保存起来,管finally中的代码怎么样,返回的值都不会改变,任然是之前保存的值),所以函数返回值是在finally执行前确定的;
- finally中最好不要包含return,否则程序会提前退出,返回值不是try或catch中保存的返回值。
举例:
- 情况1:try{} catch(){}finally{} return;
显然程序按顺序执行。 - 情况2:try{ return; }catch(){} finally{} return;
程序执行try块中return之前(包括return语句中的表达式运算)代码;
再执行finally块,最后执行try中return;
finally块之后的语句return,因为程序在try中已经return所以不再执行。 - 情况3:try{ } catch(){return;} finally{} return;
程序先执行try,如果遇到异常执行catch块,
有异常:则执行catch中return之前(包括return语句中的表达式运算)代码,再执行finally语句中全部代码,
最后执行catch块中return. finally之后也就是4处的代码不再执行。
无异常:执行完try再finally再return. - 情况4:try{ return; }catch(){} finally{return;}
程序执行try块中return之前(包括return语句中的表达式运算)代码;
再执行finally块,因为finally块中有return所以提前退出。 - 情况5:try{} catch(){return;}finally{return;}
程序执行catch块中return之前(包括return语句中的表达式运算)代码;
再执行finally块,因为finally块中有return所以提前退出。 - 情况6:try{ return;}catch(){return;} finally{return;}
程序执行try块中return之前(包括return语句中的表达式运算)代码;
有异常:执行catch块中return之前(包括return语句中的表达式运算)代码;
则再执行finally块,因为finally块中有return所以提前退出。
无异常:则再执行finally块,因为finally块中有return所以提前退出。
https://blog.csdn.net/kavensu/article/details/8067850
异常
Serializable序列化/反序列化接口
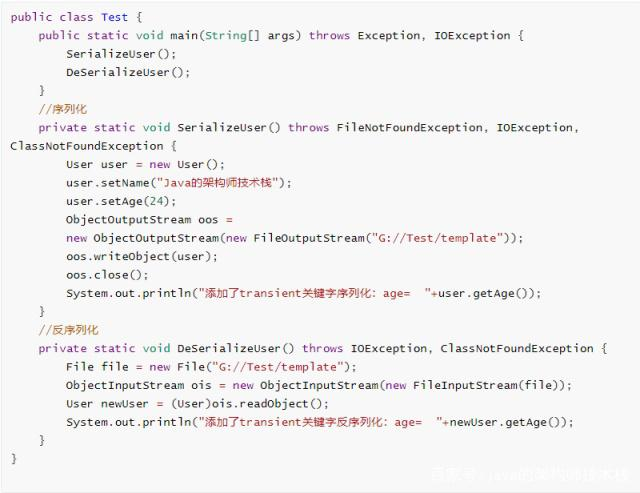
1、序列化与反序列
把对象转化为字节序列的过程称为序列化(保存到硬盘,持久化)
把字节序列转化为对象的过程称为反序列化(存放于内存)
2、序列化的用途
把对象的字节序列永久保存到硬盘上,通常放到一个文件中。
把网络传输的对象通过字节序列化,方便传输本节作业
volatile
volatile是Java虚拟机提供的轻量级同步机制。
消息总线缓存一致性协议:
cpu总线嗅探机制: 监听总线中数据是否有更新,有更新则让工作内存中数据立马失效。
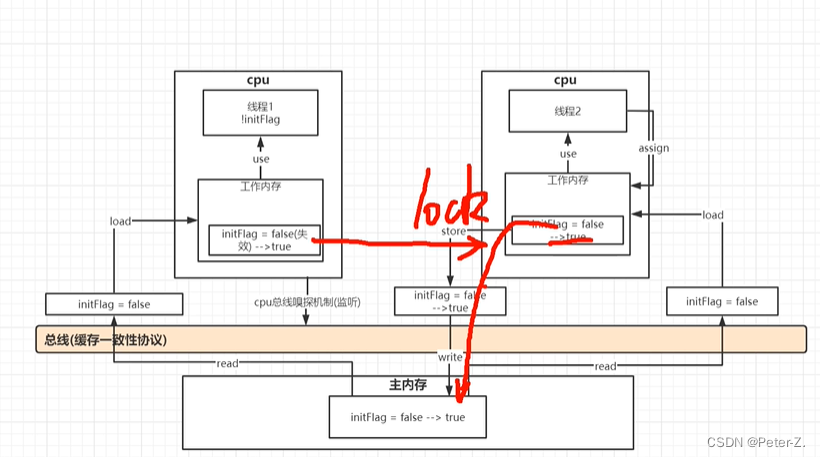
- 保证可见性
- 不保证原子性
- 禁止指令重排(保证有序性,在汇编代码层面加了内存屏障指令)(as-if-serial和happens-before原则)
用法及原理:
https://www.cnblogs.com/dolphin0520/p/3920373.html
一旦一个共享变量(类的成员变量、类的静态成员变量)被volatile修饰之后,那么就具备了两层语义:
- 保证了不同线程对这个变量进行操作时的可见性,即一个线程修改了某个变量的值,这新值对其他线程来说是立即可见的。
- 禁止进行指令重排序。(当程序执行到volatile变量的读操作或者写操作时,在其前面的操作的更改肯定全部已经进行,且结果已经对后面的操作可见;在其后面的操作肯定还没有进行;在进行指令优化时,不能将在对volatile变量访问的语句放在其后面执行,也不能把volatile变量后面的语句放到其前面执行。)


https://www.cnblogs.com/dolphin0520/p/3920373.html
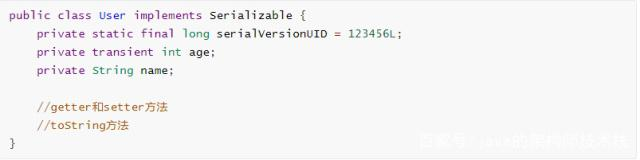
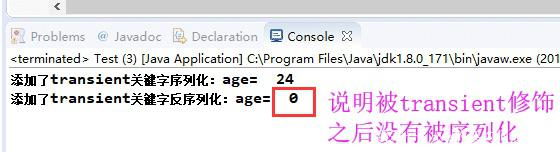
transient
将不需要序列化的属性前添加关键字transient,序列化对象的时候,这个属性就不会被序列化
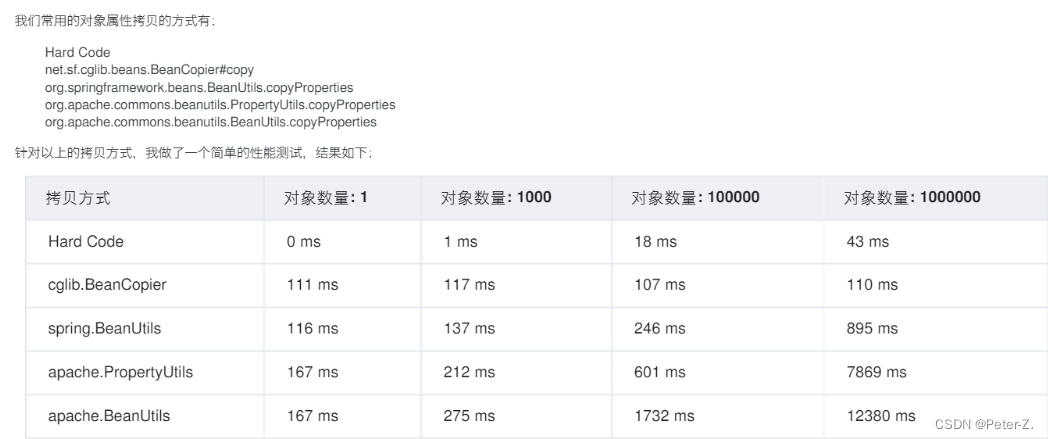
bean copy
https://wenku.baidu.com/view/923d9eae6b0203d8ce2f0066f5335a8103d26650.html
浅复制、深复制
方法:
(1)将A对象的值分别通过set方法加入B对象中;(浅复制)
(2)通过重写java.lang.Object类中的方法clone();(可深可浅,如果引用类型里面还包含很多引用类型,或者内层引用类型的类里面又包含引用类型,使用clone方法就会很麻烦。这时我们可以用序列化的方式来实现对象的深克隆。)
class Student implements Cloneable{
private int number;
public int getNumber() {
return number;
}
public void setNumber(int number) {
this.number = number;
}
@Override
public Object clone() {
Student stu = null;
try{
stu = (Student)super.clone();
}catch(CloneNotSupportedException e) {
e.printStackTrace();
}
return stu;
}
}
public class Test {
public static void main(String args[]) {
Student stu1 = new Student();
stu1.setNumber(12345);
Student stu2 = (Student)stu1.clone();
System.out.println("学生1:" + stu1.getNumber()); //12345
System.out.println("学生2:" + stu2.getNumber()); //12345
stu2.setNumber(54321);
System.out.println("学生1:" + stu1.getNumber()); //12345
System.out.println("学生2:" + stu2.getNumber()); //54321
}
}
(3)通过org.apache.commons中的工具类BeanUtils和PropertyUtils进行对象复制;

这种写法无论多少种属性都只需要一行代码搞定,很方便吧!除BeanUtils外还有一个名为PropertyUtils的工具类,它也提供copyProperties()方法,作用与BeanUtils的同名方法十分相似,主要的区别在于BeanUtils提供类型转换功能,即发现两个JavaBean的同名属性为不同类型时,在支持的数据类型范围内进行转换,而PropertyUtils不支持这个功能,但是速度会更快一些。在实际开发中,BeanUtils使用更普遍一点,犯错的风险更低一点。
(4)通过序列化实现对象的复制。
接口和抽象类的区别?
接口:公开的,对事务固有属性、行为的抽象
public interface TestInterface {
String a;//会被隐式地指定为public static final变量(并且只能是),一般情况下不在接口中定义变量
public void beforeHandle();//会被隐式地指定为public abstract方法(并且只能是)
}
抽象类:对公共的功能的抽象,抽象类不一定必须含有抽象方法
public abstract class AbstractDoor {
String a;
public abstract void open();//抽象方法必须为public或者protected(因为如果为private,则不能被子类继承,子类便无法实现该方法),缺省情况下默认为public
}
区别:
-
抽象类中的成员变量可以是各种类型的,而接口中的成员变量只能是public static final类型的;
-
接口中不能含有静态代码块以及静态方法,而抽象类可以有静态代码块和静态方法;
-
一个类只能继承一个抽象类,而一个类却可以实现多个接口。
-
接口不能有构造方法,抽象类可以有。
因为抽象类中可以有普通变量,构造方法用来初始化这些变量,而接口中只有静态常量,构造方法没有意义。
抽象类的应用场景:
a. 在某些情况下,某个父类只是知道其子类应该包含怎样的方法,但无法准确知道这些子类如何实现这些方法。
b. 从多个具有相同特征的类中抽象出一个抽象类,以这个抽象类作为子类的模板,从而避免了子类设计的随意性。
接口的应用场景:
a. 一般情况下,实现类和它的抽象类之前具有 “is-a” 的关系,但是如果我们想达到同样的目的,但是又不存在这种关系时,使用接口。
b. 由于 java 中单继承的特性,导致一个类只能继承一个类,但是可以实现一个或多个接口,此时可以使用接口。
在使用中抽象类和接口我们该如何选择?
- 如果你拥有一些方法并且想让它们中的一些有默认实现,那么使用抽象类吧。
- 如果你想实现多重继承,那么你必须使用接口。由于Java不支持多继承,子类不能够继承多个类,但可以实现多个接口。因此你就可以使用接口来解决它。
- 如果基本功能在不断改变,那么就需要使用抽象类。如果不断改变基本功能并且使用接口,那么就需要改变所有实现了该接口的类 。
内部类
https://blog.csdn.net/vcliy/article/details/85235363
什么是内部类呢?简单的说就是在一个类的内部又定义了一个类,这个类就称之为内部类(Inner Class)。看一个简单的例子:
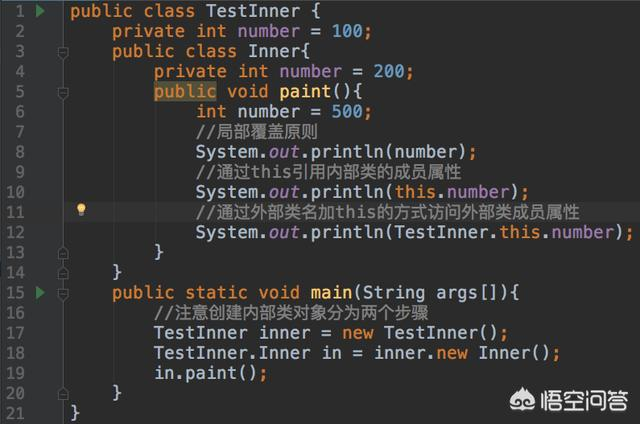
内部类有以下几个主要的特点
第一,内部类可以访问其所在类的属性(包括所在类的私有属性),内部类创建自身对象需要先创建其所在类的对象,看一个例子:
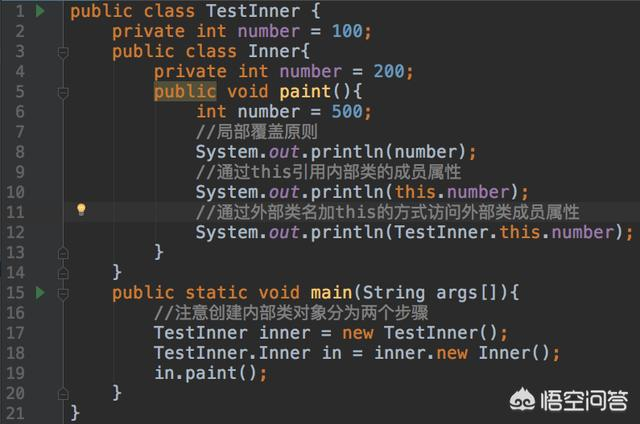
第二,可以定义内部接口,且可以定义另外一个内部类实现这个内部接口,看一个例子:
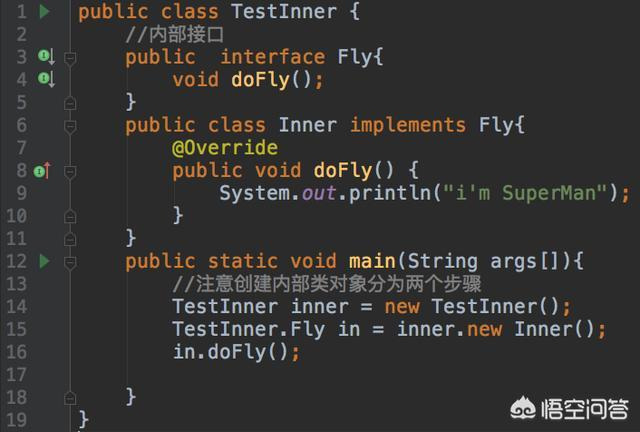
第三,可以在方法体内定义一个内部类,方法体内的内部类可以完成一个基于虚方法形式的回调操作,看一个例子:
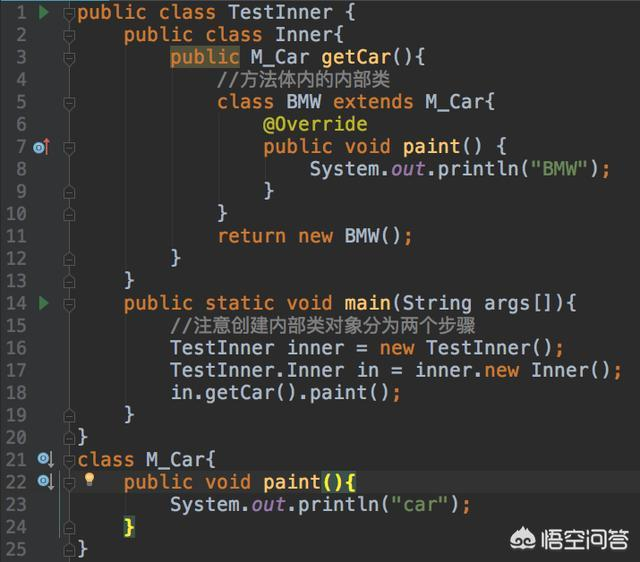
第四,内部类不能定义static元素,看一个例子:
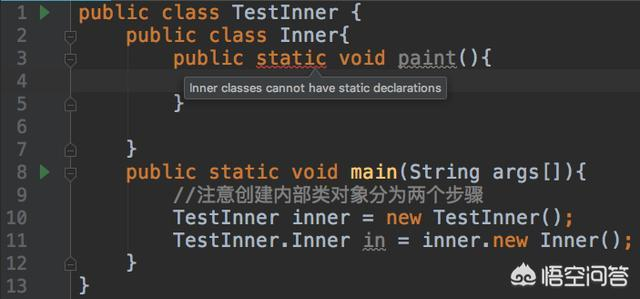
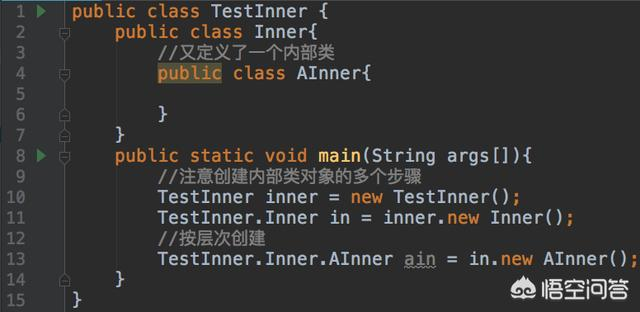
第五,内部类可以多嵌套,看一个例子:
static内部类是内部类中一个比较特殊的情况,Java文档中是这样描述static内部类的:一旦内部类使用static修饰,那么此时这个内部类就升级为顶级类。
也就是说,除了写在一个类的内部以外,static内部类具备所有外部类的特性,看一个例子:
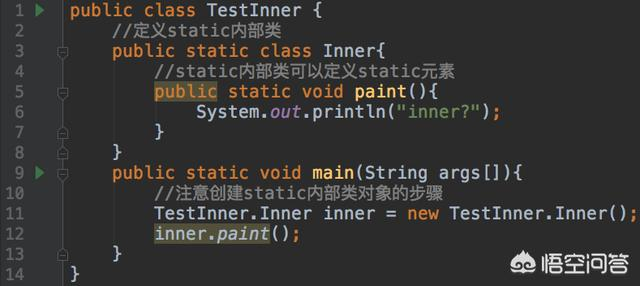
通过这个例子我们发现,static内部类不仅可以在内部定义static元素,而且在构建对象的时候也可以一次完成。从某种意义上说,static内部类已经不算是严格意义上的内部类了。
与static内部类不同,内部接口自动具备静态属性,也就是说,普通类是可以直接实现内部接口的,看一个例子:
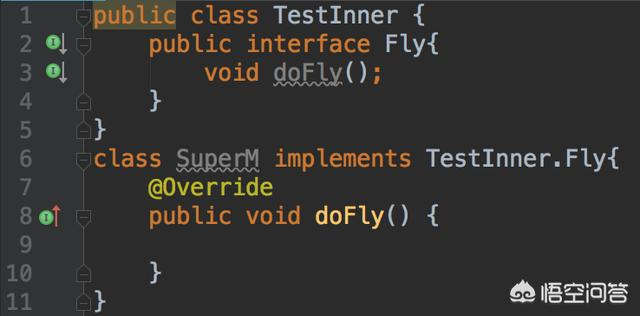
内部类的作用
1、内部类可以很好的实现隐藏。
非内部类是不可以使用 private和 protected修饰的,但是内部类却可以,从而达到隐藏的作用。同时也可以将一定逻辑关系的类组织在一起,增强可读性。
2、间接的实现多继承。
每个内部类都能独立地继承自一个(接口的)实现,所以无论外部类是否已经继承了某个(接口的)实现,对于内部类都没有影响。如果没有内部类提供的可以继承多个具体的或抽象的类的能力,一些设计与编程问题就很难解决。所以说内部类间接的实现了多继承。
集合
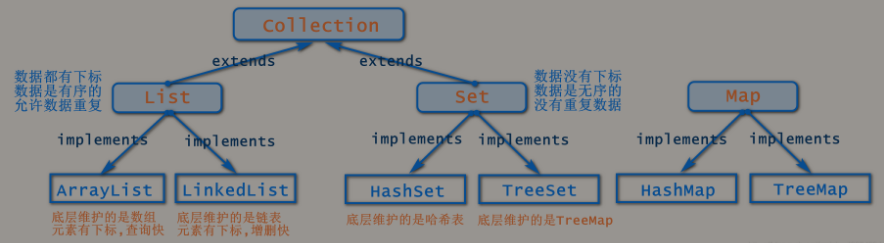
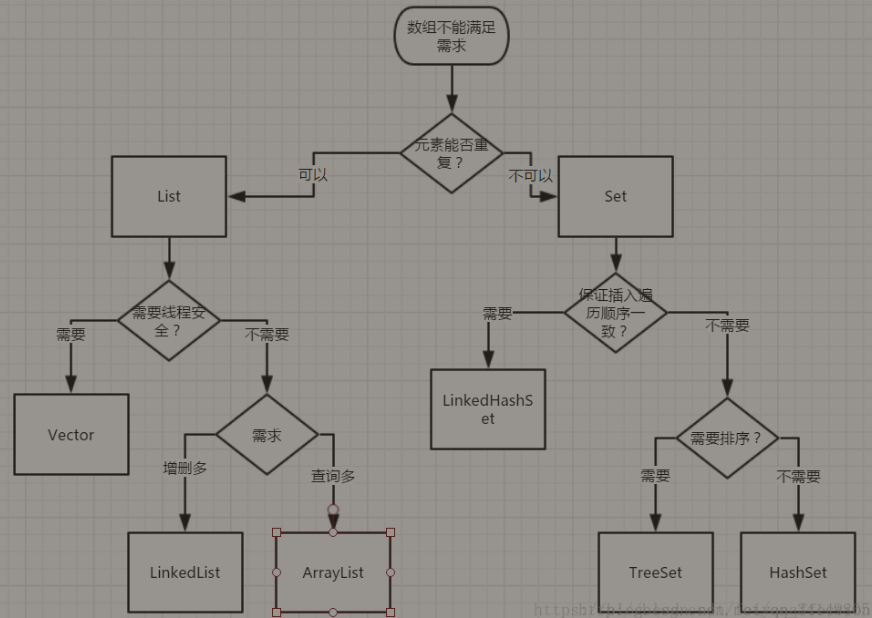
list
| 特点 | 线程安全 | 效率速度 | 底层原理 | |
|---|---|---|---|---|
| ArrayList | 有序、查询快,增删慢、允许元素为null ,可重复 | 不安全 | 数组 | |
| LinkedList | 有序、查询慢,增删快、允许元素为null,可重复 | 不安全 | 双链表 |
数组在地址上是连续的,查询速度快,链表在逻辑上是连续 的,增删速度快。
Set
| 特点 | 线程安全 | 效率速度 | 底层原理 | |
|---|---|---|---|---|
| HashSet | 无序、元素不可重复、允许元素为null | 不安全 | HashSet较HashMap来说比较慢 | |
| LinkedHashSet | 插入元素有序 | 不安全 | 效率高 | 链表和哈希表 |
| TreeSet | 有序 | 二叉树 |
Map
| 特点 | 线程安全 | 效率速度 | 底层原理 | |
|---|---|---|---|---|
| hashMap | 无序、key不可重复、键值均可空 | 不安全 | 红黑树(数组+链表) | |
| hashtable | 无序、不允许key、value为空 | 线程安全 | 即任一时刻只有一个线程能写Hashtable,效率慢 | |
| LinkedHashMap | 1、有序:插入顺序有序(); 2、key不可重复、键值均可空; | 不安全 | HashMap 多维护了一个双向链表,它的内存相比而言要比 HashMap 大,并且性能会差一些,但是如果需要考虑到元素插入的顺序的话,LinkedHashMap 不失为一种好的选择 | 红黑树(数组+链表) |
| treeMap | 1、有序:Key的自然顺序(如整数从小到大),也可以指定比较函数。但不是插入的顺序 | |||
| ConcurrentHashMap | 安全 | 与hashMap相同,jdk7:segment分段锁, jdk8:CAS+synchronized |
HashMap
HashMap中的put()和get()的实现原理
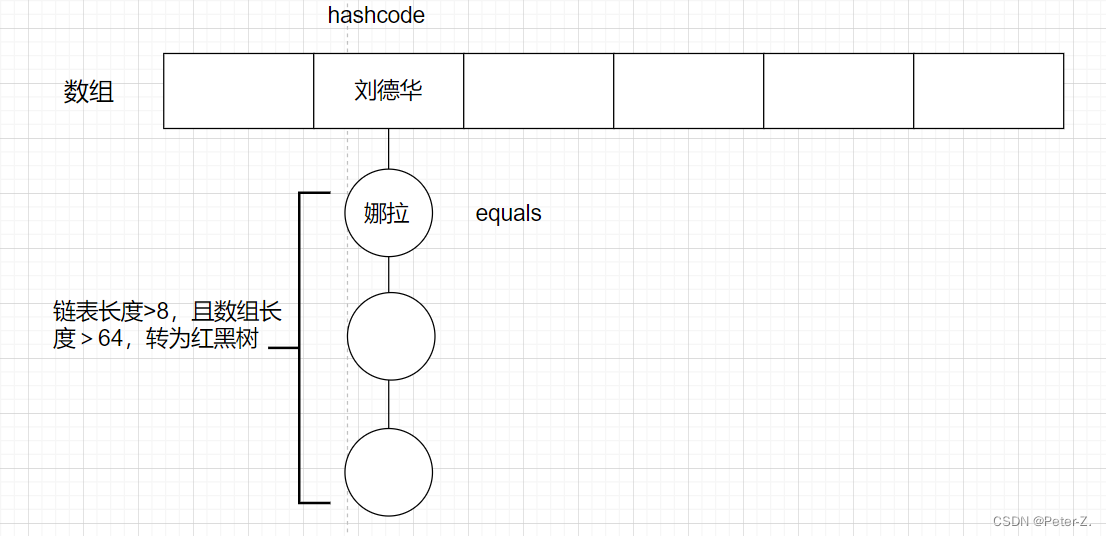
- map.put(k,v)实现原理
(1)首先将k,v封装到Node对象当中(节点)。
(2)然后它的底层会调用K的hashCode()方法得出hash值。
(3)通过哈希表函数/哈希算法,将hash值转换成数组的下标,下标位置上如果没有任何元素,就把Node添加到这个位置上。如果说下标对应的位置上有链表。此时,就会拿着k和链表上每个节点的k进行equal。如果所有的equals方法返回都是false,那么这个新的节点将被添加到链表的末尾。如其中有一个equals返回了true,那么这个节点的value将会被覆盖。
- map.get(k)实现原理
(1)先调用k的hashCode()方法得出哈希值,并通过哈希算法转换成数组的下标。
(2)通过上一步哈希算法转换成数组的下标之后,在通过数组下标快速定位到某个位置上。如果这个位置上什么都没有,则返回null。如果这个位置上有单向链表,那么它就会拿着K和单向链表上的每一个节点的K进行equals,如果所有equals方法都返回false,则get方法返回null。如果其中一个节点的K和参数K进行equals返回true,那么此时该节点的value就是我们要找的value了,get方法最终返回这个要找的value。
为何随机增删、查询效率都很高的原因是?
原因: 增删是在链表上完成的,而查询只需扫描部分,则效率高。
HashMap集合的key,会先后调用两个方法,hashCode and equals方法,这两个方法都需要重写。
为什么放在hashMap集合key部分的元素需要重写equals方法?
因为equals方法默认比较的是两个对象的内存地址
HashMap红黑树原理分析?
相比 jdk1.7 的 HashMap 而言,jdk1.8最重要的就是引入了红黑树的设计,当hash表的单一链表长度超过 8 个的时候,链表结构就会转为红黑树结构。
为什么要这样设计呢?好处就是避免在最极端的情况下链表变得很长很长,在查询的时候,效率会非常慢。
HashMap的扩容机制以及默认大小为何是2次幂?
当元素数量超过阈值时便会触发扩容,每次扩容的容量都是之前容量的2倍。这里的容量是指数组长度。
- 保证散列均匀,尽量减少hash碰撞。
- 方便扩容时数据迁移计算。
应用:
- hashMap遍历:
//方式1
for(Map.Entry entry:map.entrySet()){//遍历键和值
...}
//方式2:利用entrySet 键值对映射
Map map = new HashMap();
Iterator it = map.entrySet().iterator();
while(it.hashNext()){
Map.Entry s = (Map.Entry)it.next();
System.out.println(s.getKey());
System.out.println(s.getValue());
}
- hashMap结果排序:
Comparator可以对集合对象或者数组进行排序的比较器接口,实现该接口的public compare(T o1,To2)方法即可实现排序,该方法主要是根据第一个参数o1,小于、等于或者大于o2分别返回负整数、0或者正整数。如下:()
public class TreeMapTest {
public static void main(String[] args) {
Map<String, String> map = new TreeMap<String, String>(
new Comparator<String>() {//类型可以为对象
//此处可以定义(重写)自己的compare比较方法
public int compare(String obj1, String obj2) {
// 降序排序
return obj2.compareTo(obj1);
}
});
map.put("c", "ccccc");
map.put("a", "aaaaa");
map.put("b", "bbbbb");
map.put("d", "ddddd");
Set<String> keySet = map.keySet();
Iterator<String> iter = keySet.iterator();
while (iter.hasNext()) {
String key = iter.next();
System.out.println(key + ":" + map.get(key));
}
}
}
参考上述treeMap对hashMap结果排序:
按key排序:
public class HashMapTest {
public static void main(String[] args) {
Map<String, String> map = new HashMap<String, String>();
map.put("c", "ccccc");
map.put("a", "aaaaa");
map.put("b", "bbbbb");
map.put("d", "ddddd");
List<Map.Entry<String,String>> list = new ArrayList<Map.Entry<String,String>>(map.entrySet());
Collections.sort(list,new Comparator<Map.Entry<String,String>>() {
@Override
public int compare(Entry<String, String> o1,Entry<String, String> o2) {
return o1.getValue().compareTo(o2.getValue());// 升序排序
}
});
for(Map.Entry<String,String> mapping:list){
System.out.println(mapping.getKey()+":"+mapping.getValue());
}
}
}
================
按value排序:
class Demo{
public static void main(String[] args){
HashMap<Integer,String> map = new HashMap<Integer,String>();
map.put(new Integer(2), "a");
map.put(new Integer(5), "c");
map.put(new Integer(1), "b");
map.put(new Integer(3), "aa");
List<Map.Entry<Integer,String>> li = new ArrayList<Map.Entry<Integer,String>>(
map.entrySet());
Collections.sort(li,new Comparator<Map.Entry<Integer,String>>(){undefined
public int compare(Entry<Integer,String> a,Entry<Integer,String> b){undefined
return a.getValue().compareTo(b.getValue());
}
});
for(Map.Entry<Integer,String> me : li){undefined
System.out.println(me.getKey()+":"+me.getValue());
}
https://www.cnblogs.com/chenssy/p/3264214.html
比较器参考
ConcurrentHashMap
- ConcurrentHashMap 线程安全。分段锁
原理分析
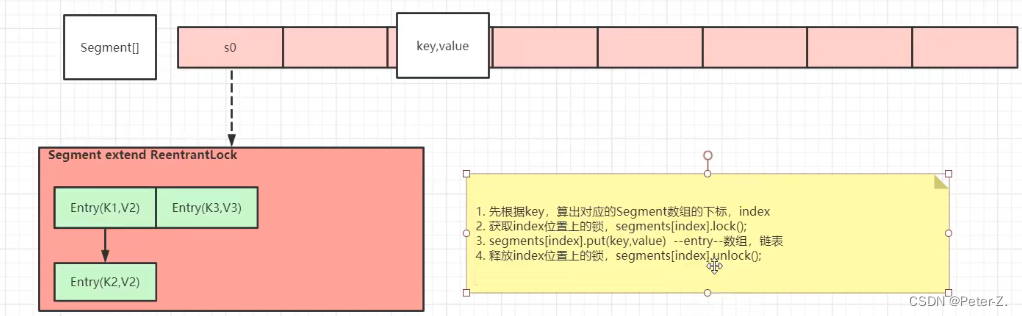
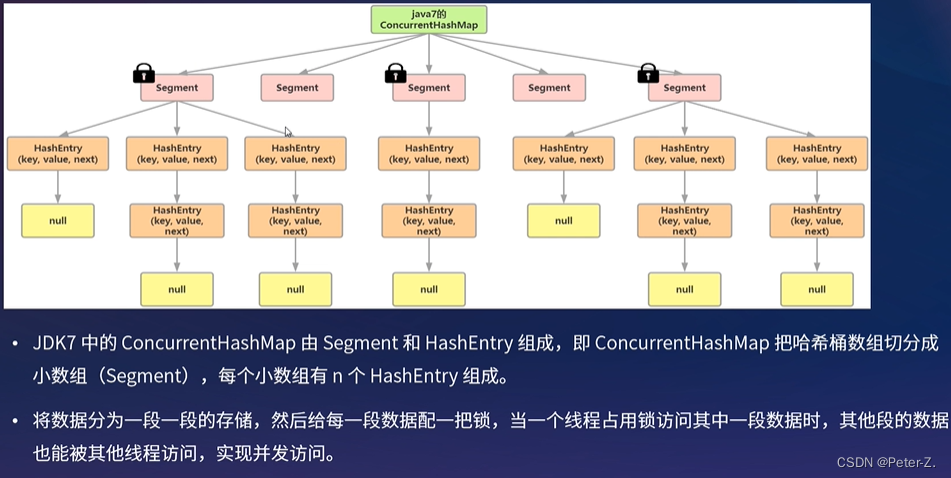
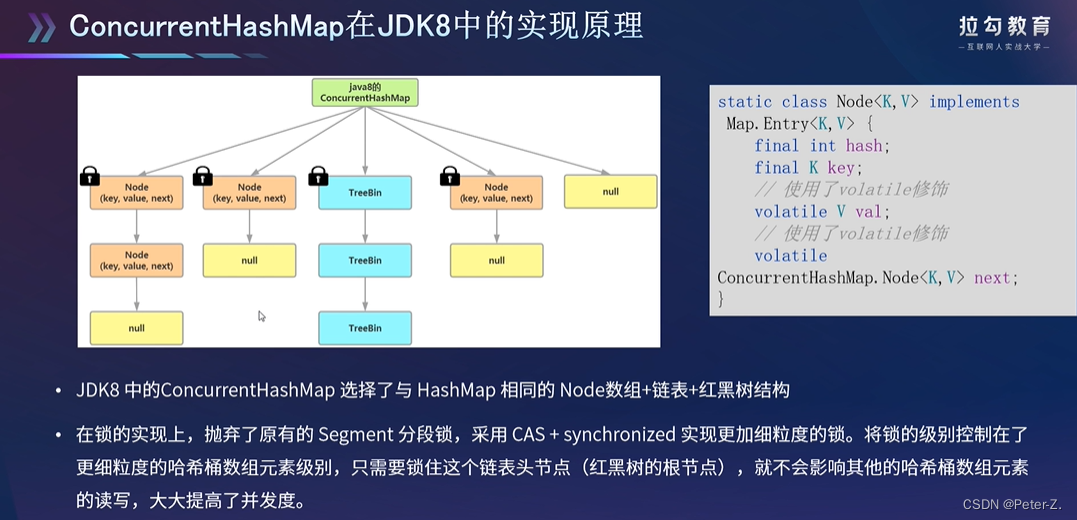




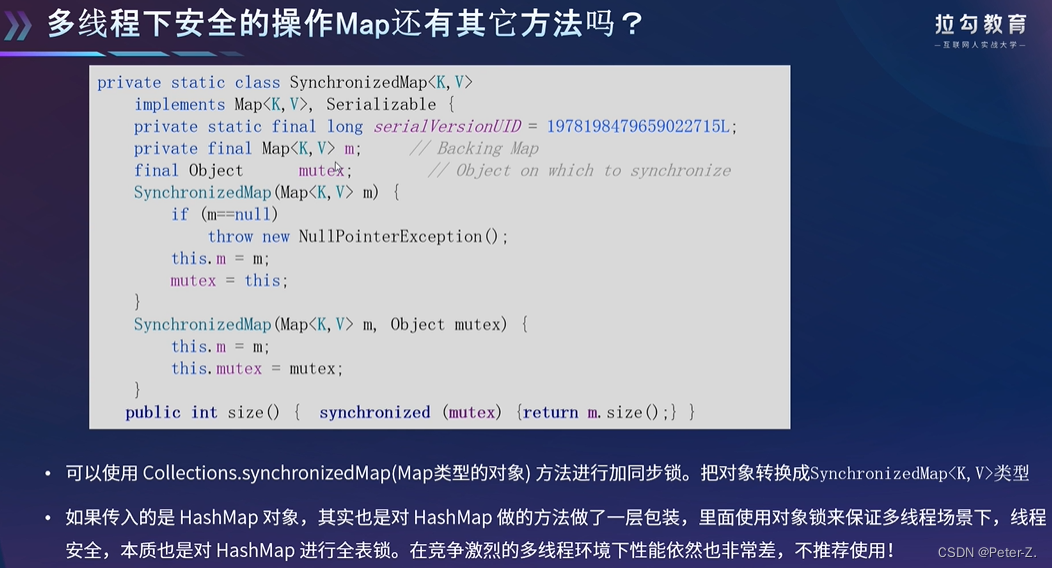
加粗样式
ConcurrentHashMap中的数组是一个对象数组(segment[ ]),该对象继承了ReentrantLock,可以进行加锁,内部相当于一个hashMap
TreeMap
- 基于红黑树实现,非线程安全(非同步的)。
- 不允许key的值为null。
- 有序,能够把它保存的记录根据key排序,默认是按升序排序,也可以指定排序的比较器,当用Iterator 遍历TreeMap时,得到的记录是排过序的。
hashtable
- key和value的值均不允许为null
- 支持线程同步,即任一时刻只有一个线程能写Hashtable,每次同步执行的时候都要锁住整张hash表来实现线程安全,因此也导致了Hashtale在写入时会比较慢。(比HashMap慢,已经淘汰)
doublefloat运算
返回double型的
1.能四舍五入
double d = 114.145;
d = (double) Math.round(d * 100) / 100;
System.out.println(d);
2. BigDecimal
BigDecimal.ROUND_HALF_UP表示四舍五入,BigDecimal.ROUND_HALF_DOWN也是五舍六入,BigDecimal.ROUND_UP表示进位处理(就是直接加1),BigDecimal.ROUND_DOWN表示直接去掉尾数。
double d = 114.145;
BigDecimal b = new BigDecimal(d);
d = b.setScale(2, BigDecimal.ROUND_HALF_UP).doubleValue();
System.out.println(d);
返回String型的
1.#.00表示保留后两位,它的处理方式是直接截掉不要的尾数,不四舍五入。
double d = 114.145;
DecimalFormat df = new DecimalFormat("#.00");
String str = df.format(d);
System.out.println(str);
2.%.2f表示保留后两位,能四舍五入。
double d = 114.145;
String.format("%.2f", d);
3.RoundingMode.HALF_DOWN表示 五舍六入,负数先取绝对值再五舍六入再负数,RoundingMode.HALF_UP:表示四舍五入,负数先取绝对值再五舍六入再负数。
double d = 114.145
NumberFormat nf = NumberFormat.getNumberInstance();
// 保留两位小数
nf.setMaximumFractionDigits(2);
// 如果不需要四舍五入,可以使用RoundingMode.DOWN
nf.setRoundingMode(RoundingMode.UP);
System.out.println(nf.format(d));
java中保留2位小数的四种方法
public class Test {
public static void main(String[] args) {
double d = 756.2345566;
//方法一:最简便的方法,调用DecimalFormat类
DecimalFormat df = new DecimalFormat(".00");
System.out.println(df.format(d));
//方法二:直接通过String类的format函数实现
System.out.println(String.format("%.2f", d));
//方法三:通过BigDecimal类实现
BigDecimal bg = new BigDecimal(d);
double d3 = bg.setScale(2, BigDecimal.ROUND_HALF_UP).doubleValue();
System.out.println(d3);
//方法四:通过NumberFormat类实现
NumberFormat nf = NumberFormat.getNumberInstance();
nf.setMaximumFractionDigits(2);
System.out.println(nf.format(d));
}
}
https://blog.csdn.net/weixin_32626635/article/details/114209116
io流
**在使用IO流之前都会明确分析如下四点:
(1)明确要操作的数据是数据源还是数据目的(也就是要读(输入)还是要写(输出))
源:
InputStream Reader
目的:
OutputStream Writer
(2)明确要操作的设备上的数据是字节还是文本
源:
字节: InputStream
文本: Reader
目的:
字节: OutputStream
文本: Writer
(3)明确数据所在的具体设备
源设备:
硬盘:文件 File开头
内存:数组,字符串
键盘:System.in
网络:Socket
对应目的设备:
硬盘:文件 File开头
内存:数组,字符串
键盘:System.out
网络:Socket
(4)明确是否需要额外功能(比如是否需要转换流、高效流等)
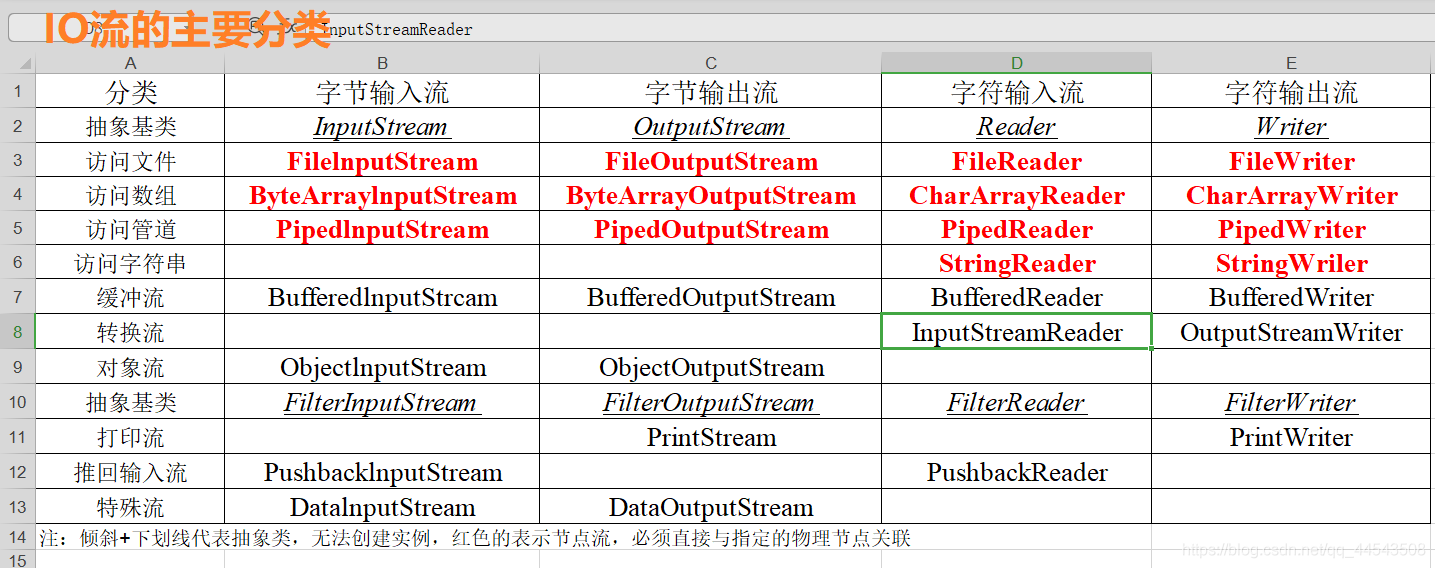
https://blog.csdn.net/qq_44543508/article/details/102831084
反射
应用1:获取类对象(字节码对象)三种方式
字节码对象:描述类、类的实例信息的对象,包括构造器,字段,方法。
获取字节码对象就可以知道类的构造器,字段,方法等信息。
- 类名.class
- 类的对象.getClass()
- Class.forName(“类的全限定名”)

创建类的对象
- Class.newInstance()
public class ObjectPoolFactory {
//定义一个对象池,前面是对象名,后面是实际对象
private Map<String, Object> objectPool = new HashMap<> ();
//定义一个创建对象的方法
//该方法只要传入一个字符串类名,程序可以根据该类名生成Java对象
private Object createObject(String clazzName) throws ClassNotFoundException, IllegalAccessException, InstantiationException {
Class<?> clazz = Class.forName(clazzName);
return clazz.newInstance();
}
Class.newInstance()方式创建类对象的对象实例,本质是执行了类对象的默认的空参的构造函数,如果类对象含有非空的构造函数,并且没有显式的声明空参的构造函数,通过Class.newInstance()方式来创建类对象的实例时,会抛出java.lang.NoSuchMethodException异常。
- 调用类对象的构造方法
Class.getConstructors():获取类对象的所有构造函数
Class.getConstructor(Class… paramTypes):获取指定的构造函数
public class ConstructorInstance {
public static void main(String[] args) throws Exception {
Class p = Person.class;
Constructor constructor = p.getConstructor(String.class,int.class);
Person person = (Person) constructor.newInstance("Likly",23);
System.out.println(person); }
}
通过Class.getConstructor(Class… paramTypes)即可获取类对象指定的构造方法,其中paramTypes为参数类型的Class可变参数,当不传paramTypes时,获取的构造方法即为默认的构造方法
https://blog.csdn.net/weixin_30685047/article/details/95244838
应用2:java遍历实体类的属性和值
https://www.cnblogs.com/ynxrsoft/p/7444453.html

实体类:
package com.example.demo;
public class User {
private String uname;
private int age;
private int id;
public User(String uname, int age, int id) {
this.uname = uname;
this.age = age;
this.id = id;
}
public String getUname() {
return uname;
}
public void setUname(){
this.uname="test";
}
public void setUname(String uname) {
this.uname = uname;
}
public int getAge() {
return age;
}
public void setAge(int age) {
this.age = age;
}
public int getId() {
return id;
}
public void setId(int id) {
this.id = id;
}
}
package cn.tx.reflect;
import java.lang.reflect.Constructor;
import java.lang.reflect.Field;
import java.lang.reflect.Method;
import java.util.Arrays;
/**
* 一、反射获取类的属性,方法,构造器
* @author Administrator
*
*/
public class ReflectLearn1 {
private static String className = "java.lang.String";
public static void main(String[] args) throws Exception {
// <?>中的问号为泛型,表示不知道后面list对象 中存放的实际类型是什么,用?表示
// List<?> list = new ArrayList();
// 1.根据一个类的全路径名获取一个类的类对象:Class对象
Class<?> clazz = Class.forName(className);
// 2.获得传递过来的类(上面的String类)的所有声明方法——目的就是为了调用获得的方法
Method[] methods = clazz.getDeclaredMethods();
for (Method m : methods) {
System.out.println(m);
}
// 3.获得类的所有声明的属性——目的:设置属性或者是获取属性值,或者是获取属性上的注解!
System.out.println("-------------获得类的所有声明的属性---------------");
Field[] fields = clazz.getDeclaredFields();
for (Field field : fields) {
System.out.println(field);
}
// 4.获得类的所有构造器——创建对象
System.out.println("--------------获得类的所有构造器--------------");
Constructor<?>[] constructors = clazz.getDeclaredConstructors();
for (Constructor<?> constructor : constructors) {
System.out.println(constructor);
}
//5.获取一个类的Class对象的三种方式:
//(1)知道类的全路径名,Class<?> clazz = Class.forName("类的全路径名");
//(2)知道该类的一个对象 Class<?> clazz = 对象名.getClass();
//(3)知道类的名字: Class<?> clazz = 类名.class;
System.out.println("----------获取Person类的信息-------------");
Person p = new Person();
test(p);
/* test(p);打印结果如下
* ----------获取Person类的信息-------------
public java.lang.String cn.tx.Person.toString()
public java.lang.String cn.tx.Person.getAddress()
public java.lang.String cn.tx.Person.getName()
public java.lang.Integer cn.tx.Person.getId()
public void cn.tx.Person.setName(java.lang.String)
public void cn.tx.Person.setId(java.lang.Integer)
public void cn.tx.Person.setAddress(java.lang.String)
-------------获得类的所有声明的属性---------------
private java.lang.Integer cn.tx.Person.id
private java.lang.String cn.tx.Person.name
private java.lang.String cn.tx.Person.address
--------------获得类的所有构造器--------------
public cn.tx.Person()
public cn.tx.Person(java.lang.Integer,java.lang.String,java.lang.String)
* */
//(3)
}
/**
* Class<? extends Object>
* @param obj
*/
public static void test(Object obj){
//Class<? extends Object>表示通过反射获取的对象的类型不确定,但是一定是Object类的子类
//等价于Class<?> clazz = obj.getClass();
Class<? extends Object> clazz = obj.getClass();
// 2.获得传递过来的类(上面的String类)的所有方法——目的就是为了调用获得的方法
Method[] methods = clazz.getDeclaredMethods();
for (Method m : methods) {
System.out.println(m);
}
// 3.获得类的所有声明的属性——目的:设置属性或者是获取属性值
System.out.println("-------------获得类的所有声明的属性---------------");
Field[] fields = clazz.getDeclaredFields();
for (Field field : fields) {
System.out.println(field);
}
// 4.获得类的所有构造器——创建对象
System.out.println("--------------获得类的所有构造器--------------");
Constructor<?>[] constructors = clazz.getDeclaredConstructors();
for (Constructor<?> constructor : constructors) {
System.out.println(constructor);
}
}
}
泛型
泛型参数类型可以用在类、接口和方法中,分别被称为泛型类、泛型接口、泛型方法
泛型类
public class 类名 <泛型类型1,...> {
}
注意事项:泛型类型必须是引用类型(非基本数据类型)
通常类型参数我们都使用大写的单个字母表示:
T:任意类型 type
E:集合中元素的类型 element
K:key-value形式 key
V: key-value形式 value
示例代码:
public class GenericClass<T> {
private T value;
public GenericClass(T value) {
this.value = value;
}
public T getValue() {
return value;
}
public void setValue(T value) {
this.value = value;
}
}
测试类:
//TODO 1:泛型类
GenericClass<String> name = new GenericClass<>("mikechen的互联网架构");
System.out.println(name.getValue());
GenericClass<Integer> number = new GenericClass<>(123);
System.out.println(number.getValue());
泛型接口
泛型接口与泛型类的定义及使用基本相同。泛型接口常被用在各种类的生产器中,可以看一个例子:
//定义一个泛型接口
public interface Generator<T> {
public T next();
}
当实现泛型接口的类,未传入泛型实参时:
/**
* 未传入泛型实参时,与泛型类的定义相同,在声明类的时候,需将泛型的声明也一起加到类中
* 即:class FruitGenerator<T> implements Generator<T>{
* 如果不声明泛型,如:class FruitGenerator implements Generator<T>,编译器会报错:"Unknown class"
*/
class FruitGenerator<T> implements Generator<T>{
@Override
public T next() {
return null;
}
}
当实现泛型接口的类,传入泛型实参时:
/**
- 传入泛型实参时:
- 定义一个生产器实现这个接口,虽然我们只创建了一个泛型接口Generator<T>
- 但是我们可以为T传入无数个实参,形成无数种类型的Generator接口。
- 在实现类实现泛型接口时,如已将泛型类型传入实参类型,则所有使用泛型的地方都要替换成传入的实参类型
- 即:Generator<T>,public T next();中的的T都要替换成传入的String类型。
*/
public class FruitGenerator implements Generator<String> {
private String[] fruits = new String[]{"Apple", "Banana", "Pear"};
@Override
public String next() {
Random rand = new Random();
return fruits[rand.nextInt(3)];
}
}
泛型方法
与泛型类区别:泛型类,是在实例化类的时候指明泛型的具体类型;泛型方法,是在调用方法的时候指明泛型的具体类型 。
/**
* 非泛型类中定义泛型方法
* @author Administrator
*
*/
public class Method {
// 泛型方法,在返回类型前面使用泛型字母
public static <T> void test1(T t){
System.out.println(t);
}
// T 只能是list 或者list 的子类
public static <T extends List> void test2(T t){
t.add("aa");
}
// T... 可变参数 ---> T[]
public static <T extends Closeable> void test3(T...a) {
for (T temp : a) {
try {
if (null != temp) {
temp.close();
}
} catch (Exception e) {
e.printStackTrace();
}
}
}
public static void main(String[] args) throws FileNotFoundException {
test1("java 是门好语言");
test3(new FileInputStream("a.txt"));
}
}
泛型通配符
-
T、K、V、E 等泛型字母为有类型,类型参数赋予具体的值
-
?未知类型 类型参数赋予不确定值,任意类型
-
只能用在声明类型、方法参数上,不能用在定义泛型类上
/**
* 泛型的通配符 类型不确定,用于声明变量或者形参上面
*
* 不能使用在类上 或者 new 创建对象上
* @author Administrator
*
*/
public class Demo04 {
// 用在形参上
public static void test(List<?> list) {
List<?> list2; // 用在声明变量上
list2 = new ArrayList<String>();
list2 = new ArrayList<Integer>();
list2 = new ArrayList<Object>();
}
public static void main(String[] args) {
test(new ArrayList<String>());
test(new ArrayList<Integer>());
}
}
此处’?’是类型实参,而不是类型形参 !再直白点的意思就是,此处的?和Number、String、Integer一样都是一种实际的类型,可以把?看成所有类型的父类。是一种真实的类型。
1. 无边界的通配符(Unbounded Wildcards), 就是<?>, 比如List<?>
无边界的通配符的主要作用就是让泛型能够接受未知类型的数据.
2. 固定上边界的通配符(Upper Bounded Wildcards),采用<? extends E>的形式
使用固定上边界的通配符的泛型, 就能够接受指定类及其子类类型的数据。
要声明使用该类通配符, 采用<? extends E>的形式, 这里的E就是该泛型的上边界。
注意: 这里虽然用的是extends关键字, 却不仅限于继承了父类E的子类, 也可以代指显现了接口E的类
3. 固定下边界的通配符(Lower Bounded Wildcards),采用<? super E>的形式
使用固定下边界的通配符的泛型, 就能够接受指定类及其父类类型的数据.。
要声明使用该类通配符, 采用<? super E>的形式, 这里的E就是该泛型的下边界.。
注意: 你可以为一个泛型指定上边界或下边界, 但是不能同时指定上下边界。
https://segmentfault.com/a/1190000014824002
https://blog.csdn.net/s10461/article/details/53941091
ThreadLocal
ThreadLocal是除了加锁这种同步方式之外的一种保证一种规避多线程访问出现线程不安全的方法,当我们在创建一个变量后,如果每个线程对其进行访问的时候访问的都是线程自己的变量这样就不会存在线程不安全问题。
ThreadLocal是存放在其Thread对象中的ThreadLocalMap中。
强引用、软引用、弱引用、虚引用
①强引用:Java中默认的引用类型,一个对象如果具有强引用那么只要这种引用还存在就不会被GC。
②软引用:简言之,如果一个对象具有弱引用,在JVM发生OOM(内存溢出)之前(即内存充足够使用),是不会GC这个对象的;只有到JVM内存不足的时候才会GC掉这个对象。软引用和一个引用队列联合使用,如果软引用所引用的对象被回收之后,该引用就会加入到与之关联的引用队列中
③弱引用(这里讨论ThreadLocalMap中的Entry类的重点):如果一个对象只具有弱引用,那么这个对象就会被垃圾回收器GC掉(被弱引用所引用的对象只能生存到下一次GC之前,当发生GC时候,无论当前内存是否足够,弱引用所引用的对象都会被回收掉)。弱引用也是和一个引用队列联合使用,如果弱引用的对象被垃圾回收期回收掉,JVM会将这个引用加入到与之关联的引用队列中。若引用的对象可以通过弱引用的get方法得到,当引用的对象呗回收掉之后,再调用get方法就会返回null
④虚引用:虚引用是所有引用中最弱的一种引用,其存在就是为了将关联虚引用的对象在被GC掉之后收到一个通知。(不能通过get方法获得其指向的对象)
https://baijiahao.baidu.com/s?id=1678416974972333944&wfr=spider&for=pc
hash一致性算法
https://www.zsythink.net/archives/1182
线程
生命周期
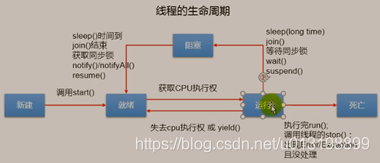
start()方法是启动一个线程,此时的线程处于就绪状态,但并不一定就会执行,还需要等待CPU的调度。
run()方法才是线程获得CPU时间,开始执行的点。
多线程
wait()与sleep()区别
整体的区别其实是有四个:
1、sleep是线程中的方法,但是wait是Object中的方法。
2、sleep方法不会释放lock,但是wait会释放,而且会加入到等待队列中。
3、sleep方法不依赖于同步器synchronized,但是wait需要依赖synchronized关键字。
4、sleep不需要被唤醒(休眠之后推出阻塞),但是wait需要(不指定时间需要被别人中断)。
https://baijiahao.baidu.com/s?id=1647423693517849309&wfr=spider&for=pc
join()
调用者等待被调用者执行完后才能继续执行,调用者进入阻塞状态
// JoinTest.java的源码
public class JoinTest{
public static void main(String[] args){
try {
ThreadA t1 = new ThreadA("t1"); // 新建“线程t1”
t1.start(); // 启动“线程t1”
t1.join(); // 将“线程t1”加入到“主线程main”中,并且“主线程main()会等待它的完成”
System.out.printf("%s finishn", Thread.currentThread().getName());
} catch (InterruptedException e) {
e.printStackTrace();
}
}
static class ThreadA extends Thread{
public ThreadA(String name){
super(name);
}
public void run(){
System.out.printf("%s startn", this.getName());
// 延时操作
for(int i=0; i <1000000; i++)
;
System.out.printf("%s finishn", this.getName());
}
}
}
=============================
运行结果:
t1 start
t1 finish
main finish
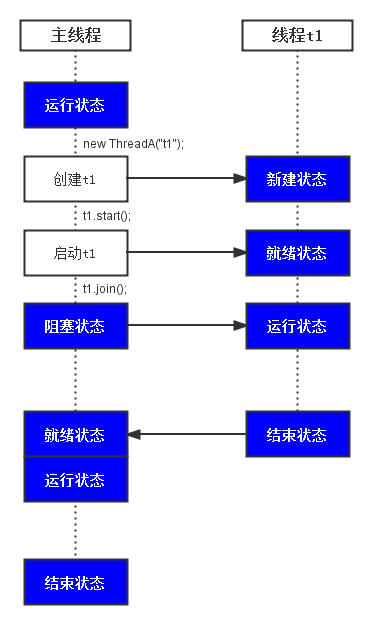
运行流程如图
(1) 在“主线程main”中通过 new ThreadA(“t1”) 新建“线程t1”。 接着,通过 t1.start() 启动“线程t1”,并执行t1.join()。
(2) 执行t1.join()之后,“主线程main”会进入“阻塞状态”等待t1运行结束。“子线程t1”结束之后,会唤醒“主线程main”,“主线程”重新获取cpu执行权,继续运行。
CountDownLatch
yeild
线程池

线程池的工作原理:
线程池判断核心线程池里的线程是否都在执行任务。 如果不是,创建一个新的工作线程来执行任务。如果核心线程池里的线程都在执行任务,则进入下个流程。
线程池判断阻塞队列是否已满。 如果阻塞队列没有满,则将新提交的任务存储在阻塞队列中。如果阻塞队列已满,则进入下个流程。
线程池判断线程池里的线程是否都处于工作状态。 如果没有,则创建一个新的工作线程来执行任务。如果已满,则交给饱和策略来处理这个任务。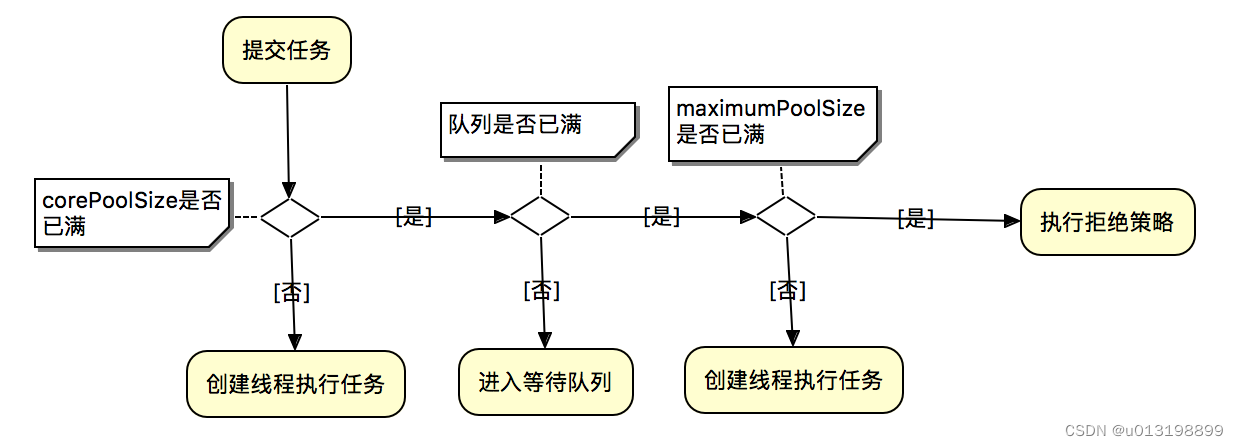
(1)jdk自带线程池

(1)newCachedThreadPool
创建一个可缓存的线程池,一个可以无限扩大的线程池,适用于负载较轻的场景,执行短期异步任务。(可以使得任务快速得到执行,因为任务时间执行短,可以很快结束,也不会造成cpu过度切换)
(2)newFixedThreadPool
创建一个固定大小的线程池,因为采用无界的阻塞队列,所以实际线程数量永远不会变化,适用于负载较重的场景,对当前线程数量进行限制。(保证线程数可控,不会造成线程过多,导致系统负载更为严重)
(3)newSingleThreadExecutor
创建一个单线程的线程池,适用于需要保证顺序执行各个任务。
(4)newScheduledThreadPool
适用于执行延时或者周期性任务。
https://blog.csdn.net/belongtocode/article/details/109272880
(2)spring线程池
将jdk自带线程池封装到spring框架中。
(3)Quartz线程池

参考:
多线程参数
https://www.cnblogs.com/kyleinjava/p/10432168.html
https://blog.csdn.net/leo3070/article/details/77915463
并发名词解释
- QPS: ( Queries Per Second )每秒查询率
- TPS:(Transactions Per Second )每秒事务数
- 并发数:系统同时处理的request/事务数
- RT:(response time)响应时间
qps、tps是用来描述系统吞吐量的指标。
QPS(TPS)=并发数/平均响应时间
qps、tps区别:对于一个页面的一次访问,形成一个Tps;但一次页面请求,可能产生多次对服务器的请求,服务器对这些请求,就可计入“Qps”之中。
-
PV(Page View):页面访问量,即页面浏览量或点击量,用户每次刷新即被计算一次。可以统计服务一天的访问日志得到。
-
UV (Unique Visitor):独立访客,统计1天内访问某站点的用户数。可以统计服务一天的访问日志并根据用户的唯一标识去重PV得到。
-
DAU(Daily Active User),日活跃用户数量。常用于反映网站、互联网应用或网络游戏的运营情况。DAU通常统计一日(统计日)之内,登录或使用了某个产品的用户数(去除重复登录的用户),与UV概念相似
BIO、NIO、AIO
BIO
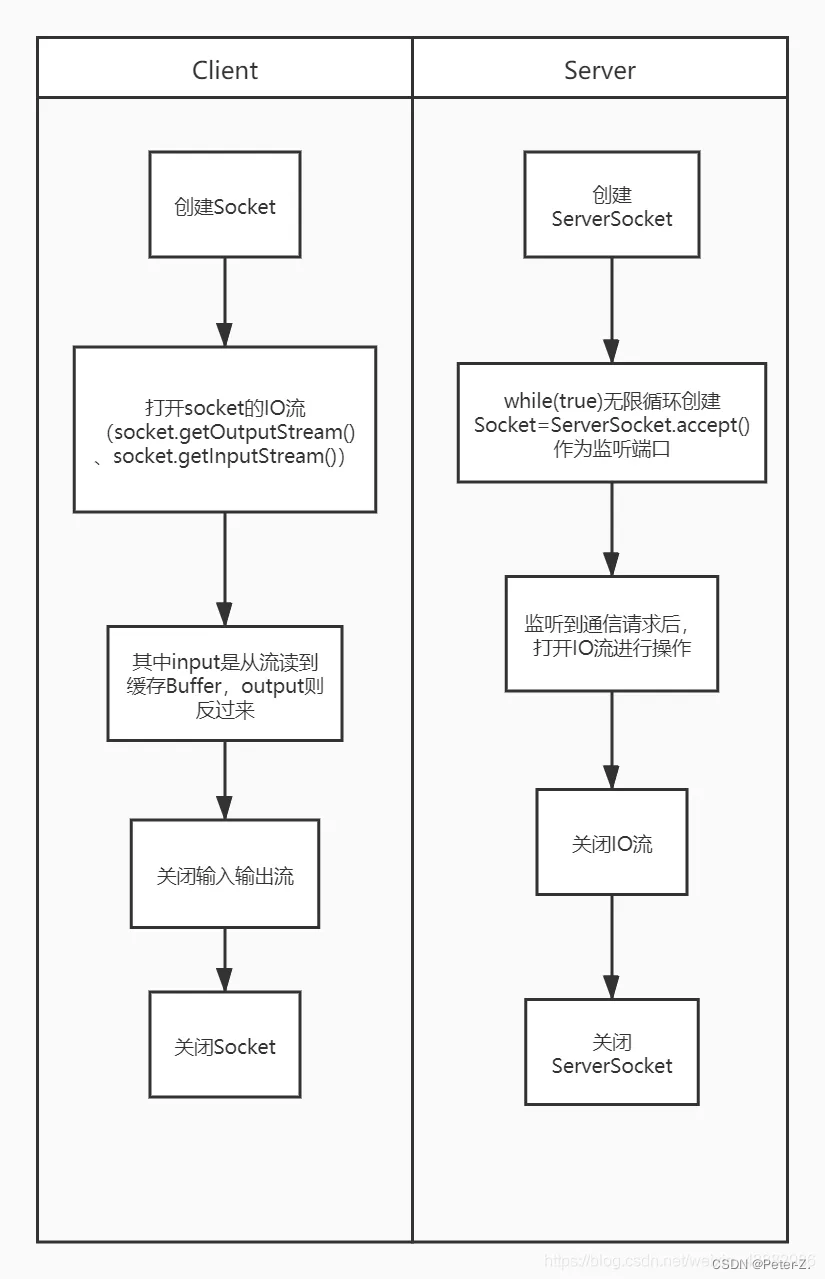
BIO全称是Blocking IO,是JDK1.4之前的传统IO模型,本身是同步阻塞模式。
线程发起IO请求后,一直阻塞IO,直到缓冲区数据就绪后,再进入下一步操作。针对网络通信都是一请求一应答的方式,虽然简化了上层的应用开发,但在性能和可靠性方面存在着巨大瓶颈,试想一下如果每个请求都需要新建一个线程来专门处理,那么在高并发的场景下,机器资源很快就会被耗尽。
NIO
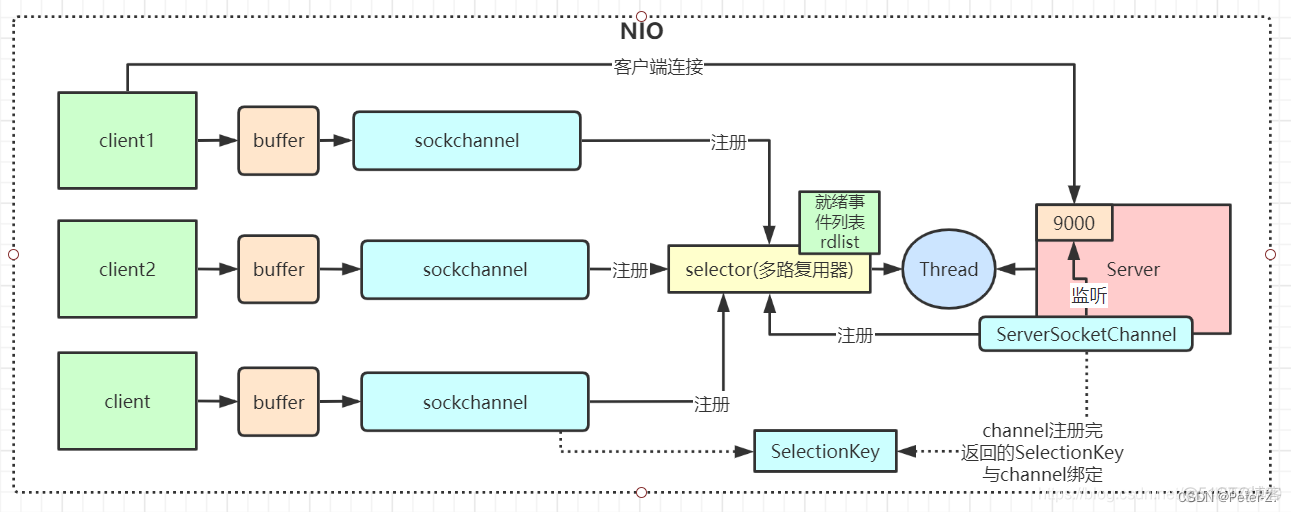
NIO也叫Non-Blocking IO 是同步非阻塞的IO模型。线程发起io请求后,立即返回(非阻塞io)。同步指的是必须等待IO缓冲区内的数据就绪,而非阻塞指的是,用户线程不原地等待IO缓冲区,可以先做一些其他操作,但是要定时轮询检查IO缓冲区数据是否就绪。Java中的NIO 是new IO的意思。其实是NIO加上IO多路复用技术。普通的NIO是线程轮询查看一个IO缓冲区是否就绪,而Java中的new IO指的是线程轮询地去查看一堆IO缓冲区中哪些就绪,这是一种IO多路复用的思想。IO多路复用模型中,将检查IO数据是否就绪的任务,交给系统级别的select或epoll模型,由系统进行监控,减轻用户线程负担。
NIO主要有buffer、channel、selector三种技术的整合,通过零拷贝的buffer取得数据,每一个客户端通过channel在selector(多路复用器)上进行注册。服务端不断轮询channel来获取客户端的信息。channel上有connect,accept(阻塞)、read(可读)、write(可写)四种状态标识。根据标识来进行后续操作。所以一个服务端可接收无限多的channel。不需要新开一个线程。大大提升了性能。
缓冲区:即Buffer,Buffer是一个对象,它包含一些要写入或者要读出的数据,在NIO库中,所有数据读写操作都是用缓冲区处理的。具体一些实现就不说了,通常它是一个字节数组(ByteBuffer)。
通道:即Channel,通过它读取和写入数据,就像电话线一样。这里大家是不是有想到流(Stream),区别在于Stream是单向,而Channel是双向的。主要实现呢有以下:FileChannel、DatagramChannel、SocketChannel,通过英文名是不是可以看出个大概意思:文件IO、UDP和TCP。
多路复用器:即Selector,说白了是用来管理Channel的,Channel注册在Selector中,如果某个Channel上面有TCP连接接入,会被Selector轮询出来,通过相关处理进行后续的I/O操作。
服务端通信步骤:
1.创建ServerSocketChannel实例、并且绑定端口;
2.创建selector实例;
3.将ServerSocketChannel实例注册到选择器上,并监听accept事件;
4.有请求(accept)进来获取客户端的socketChannel的连接,将连接实例注册到选择器上;
5.IO操作(进入缓冲区Buffer);
6.关闭ServerSocketChannel实例
客户端通信步骤:
1.创建SocketChannel实例和Selector选择器;
2.连接服务器;
3.将SocketChannel注册到selector选择器;
4.发送数据;
5.关闭SocketChannel;
AIO
AIO是真正意义上的异步非阻塞IO模型。
上述NIO实现中,需要用户线程定时轮询,去检查IO缓冲区数据是否就绪,占用应用程序线程资源,其实轮询相当于还是阻塞的,并非真正解放当前线程,因为它还是需要去查询哪些IO就绪。而真正的理想的异步非阻塞IO应该让内核系统完成,用户线程只需要告诉内核,当缓冲区就绪后,通知我或者执行我交给你的回调函数。
AIO可以做到真正的异步的操作,但实现起来比较复杂,支持纯异步IO的操作系统非常少,目前也就windows是IOCP技术实现了,而在Linux上,底层还是是使用的epoll实现的。
BIO是一个链接一个线程。
NIO是一个请求一个线程。
AIO是一个有效请求一个线程。
https://blog.51cto.com/u_15281317/3007764
http://www.javashuo.com/article/p-sqmzvpaz-nh.html
https://zhuanlan.zhihu.com/p/375762987
锁
分类
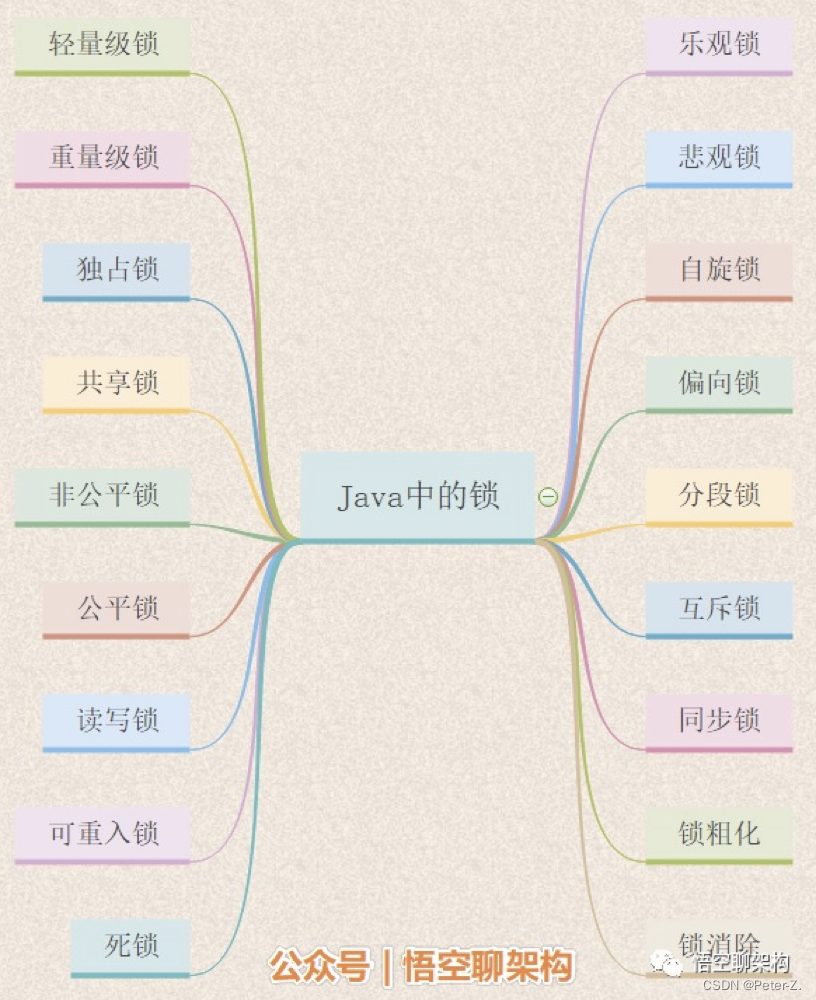

https://baijiahao.baidu.com/s?id=1665575583637127352&wfr=spider&for=pc
https://blog.csdn.net/qq3164069700/article/details/121789342
乐观锁
乐观锁认为更新数据的时候不会冲突。
实现方式:
1. 使用数据版本(Version)/ 时间戳
(1)先读task表的数据(实际上这个表只有一条记录),得到version的值为versionValue
(2)每次更新task表中的value字段时,为了防止发生冲突,需要这样操作
update task set value = newValue,version =
versionValue + 1 where version = versionValue;
上述sql通过 version = versionValue 条件实现乐观锁。
只有这条语句执行了,才表明本次更新value字段的值成功 。(时间戳原理类似)
若在高并发下,总让用户感知到失败显然是不合理的。所以,还是要想办法减少乐观锁的粒度。一个比较好的建议,就是减小乐观锁力度,最大程度的提升吞吐率,提高并发能力!如下: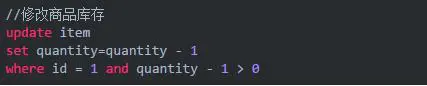
以上 SQL 语句中,如果用户下单数为 1,则通过quantity - 1 > 0的方式进行乐观锁控制。在执行过程中,会在一次原子操作中查询一遍 quantity 的值,并将其扣减掉 1。
2. CAS算法 (无锁、轻量级锁、乐观锁、自旋锁)
即 compare and swap(比较与交换),是一种有名的无锁算法。无锁编程,即不使用锁(没有线程被阻塞)的情况下实现多线程之间的变量同步,所以也叫非阻塞同步(Non-blocking Synchronization)。CAS 算法涉及到三个操作数:
需要读写的内存值 V、进行比较的值 A、拟写入的新值 B
当且仅当 V 的值等于 A 时,CAS 通过原子方式用新值 B 来更新 V 的值,否则不会执行任何操作(比较和替换是一个 native 原子操作)。一般情况下,这是一个自旋操作,即不断的重试。
**优点:**线程无阻塞,不用切换线程,执行效率高。
**缺点:**线程竞争激烈时耗时长,cpu占有率会很高。
乐观锁会引入ABA问题,解决方案:增加版本号。
CAS应用:Atomic 原子类
//import java.util.concurrent.atomic.AtomicInteger;
public static void main(String[] args) {
public static AtomicInteger count = new AtomicInteger(0);
public static void increase() {
count.incrementAndGet();
}
}
悲观锁(数据库自带)
悲观锁:总是假设最坏的情况,每次去拿数据的时候都认为别人会修改,所以每次在拿数据的时候都会上锁,这样别人想拿这个数据就会阻塞,直到它拿到锁。
悲观锁主要分为共享锁和排他锁
举例:
- synchronized关键字就是一个悲观锁(排他锁)
- 数据库里面也用到了这种悲观锁的机制。比如行锁,表锁等,读锁,写锁等,都是在做操作之前先上锁。这样其他的线程就不能同步操作,必须要等到他释放才可以。
在数据库管理系统中提供了两种锁:共享锁(S)和排它锁(X),也称为读锁和写锁。
一个事务对数据 A 加了 X 锁,就可以对 A 进行读取和更新,加锁期间其它事务不能对 A 加任何锁。
一个事务对数据 A 加了 S 锁,可以对 A 进行读取操作,但是不能进行更新操作,加锁期间其它事务能对 A 加 S 锁,但是不能加 X 锁。
MySQL 的 InnoDB 存储引擎可以使用以下方法分别加 S 锁和 X 锁:
SELECT ... LOCK In SHARE MODE;
SELECT ... FOR UPDATE;
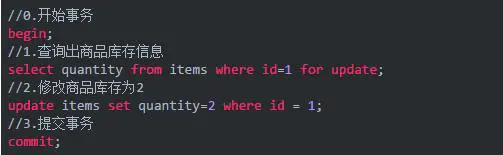
在对 id = 1 的记录修改前,先通过 for update 的方式进行加锁,然后再进行修改。select…for update是比较典型的悲观锁策略。
如果发生并发,同一时间只有一个线程可以开启事务并获得 id=1 的锁,其它的事务必须等本次事务提交之后才能执行。这样可以保证当前的数据不会被其它事务修改。
使用 select…for update 锁数据,需要注意锁的级别,MySQL InnoDB 默认行级锁。行级锁都是基于索引的,如果一条 SQL 语句用不到索引是不会使用行级锁的,会使用表级锁把整张表锁住,这点需要注意。
应用场景:扫码场景,如果码已经被人扫过,未释放前,不允许其他人扫码。
如何选择乐观锁/悲观锁
在乐观锁与悲观锁的选择上面,主要看下两者的区别以及适用场景就可以了。
1️⃣响应效率:如果需要非常高的响应速度,建议采用乐观锁方案,成功就执行,不成功就失败,不需要等待其他并发去释放锁。乐观锁并未真正加锁,效率高。一旦锁的粒度掌握不好,更新失败的概率就会比较高,容易发生业务失败。
2️⃣冲突频率:如果冲突频率非常高,建议采用悲观锁,保证成功率。冲突频率大,选择乐观锁会需要多次重试才能成功,代价比较大。
3️⃣重试代价:如果重试代价大,建议采用悲观锁。悲观锁依赖数据库锁,效率低。更新失败的概率比较低。
4️⃣乐观锁如果有人在你之前更新了,你的更新应当是被拒绝的,可以让用户从新操作。悲观锁则会等待前一个更新完成。这也是区别。
随着互联网 三高架构(高并发、高性能、高可用)的提出,悲观锁已经越来越少的被应用到生产环境中了,尤其是并发量比较大的业务场景。
https://blog.csdn.net/jiazhipeng12/article/details/108889692
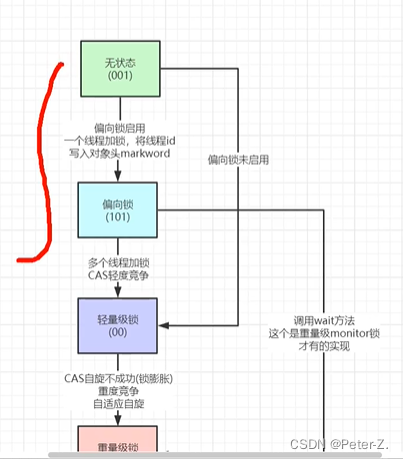
锁升级
原子操作
AtomicReference
底层原理:CAS
LongAdder
底层原理:分段锁,将初始对象复制多份放在数组里,在最后多项相加。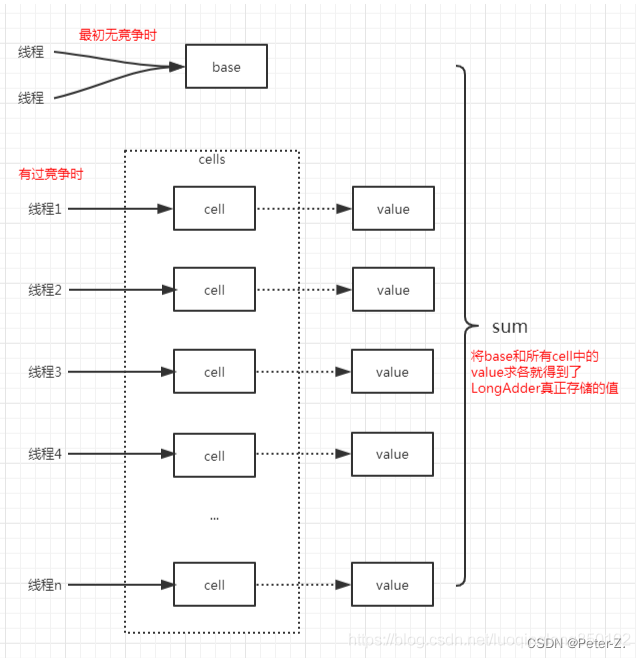
AQS
Http
cookie
web会话:从浏览器第一次请求服务器开始到浏览器关闭结束,之间发生的多次请求与响应过程就叫会话过程。
会话的数据,http协议不会进行保存,http协议是无状态。会话的数据需要保存,保存在哪里?
答:会话数据可以保存到客户端、服务器端,专门有会话对象进行保存。
客户端会话对象是cookie,服务器端会话对象是session
会话专属于唯一的客户端与服务器端,不同的浏览器会话数据不一样。
小结:cookie存储的数据存放在客户端,可减少服务器压力
应用场景:记住用户名、自动登录,过程分析、
操作cookie存取数据,
cookie特点:是服务器写入cookie,客户端存储数据,浏览器每次访问服务器器都会携带cookie的数据到服务器(cookie数据来源与服务器)
cookie的相关api方法
写入cookie的api方法
Cookie cookie = new Cookie(string,string); //创建cookie写入一个键值对数据
cookie.setMaxAge(秒数);//设置cookie的有效期
response.addCookie(cookie);//将cookie数据输出给浏览器去保存
读取cookie的api方法,服务器读取cookie数据
Cookie[] cookies = request.getCookies();
cookie.getName(),获取cooke的key
cookie.getValue(),获取cookie的value
https://www.cnblogs.com/qinjunlin/p/13651841.html
session
- session使用缺点
1.这种模式最大的问题是,没有分布式架构,无法支持横向扩展。
2.如果使用一个服务器,该模式完全没有问题。
3.但是,如果它是服务器群集或面向服务的跨域体系结构的话,则需要一个统一的session数据库库来保存会话数据实现共享,
4.这样负载均衡下的每个服务器才可以正确的验证用户身份。
- 常用解决session方法
1.一种解决方式是通过持久化session数据,写入数据库或文件持久层等。
2.收到请求后,验证服务从持久层请求数据
3.依赖于持久层的数据库或者问题系统,会有单点风险 ,如果持久层失败,整个认证体系都会垮掉
JWT
一种认证机制,让后台知道请求是来自于受信的客户端, 把用户信息通过加密后生成的一个字符串。
JWT架构有三个主体: user, application server和authentication server
非常常见的一个架构,首先用户需要 通过登录等手段向authentication server发送一个认证请求,authentication会返回给用户一个JWT(这个JWT的具体内容格式是啥后面会说,先理解成一个简单的字符串好了)
此后用户向application server发送的所有请求都要捎带上这个JWT,然后application server会验证这个JWT的合法性,验证通过则说明用户请求时来自合法守信的客户端。
JVM
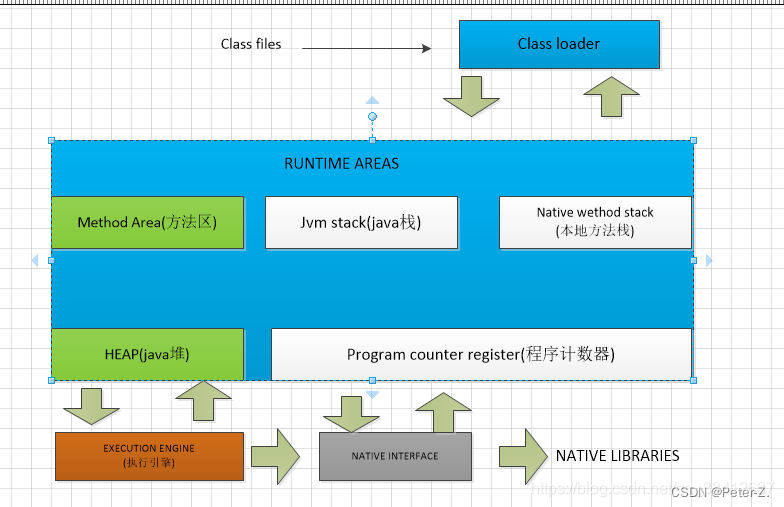
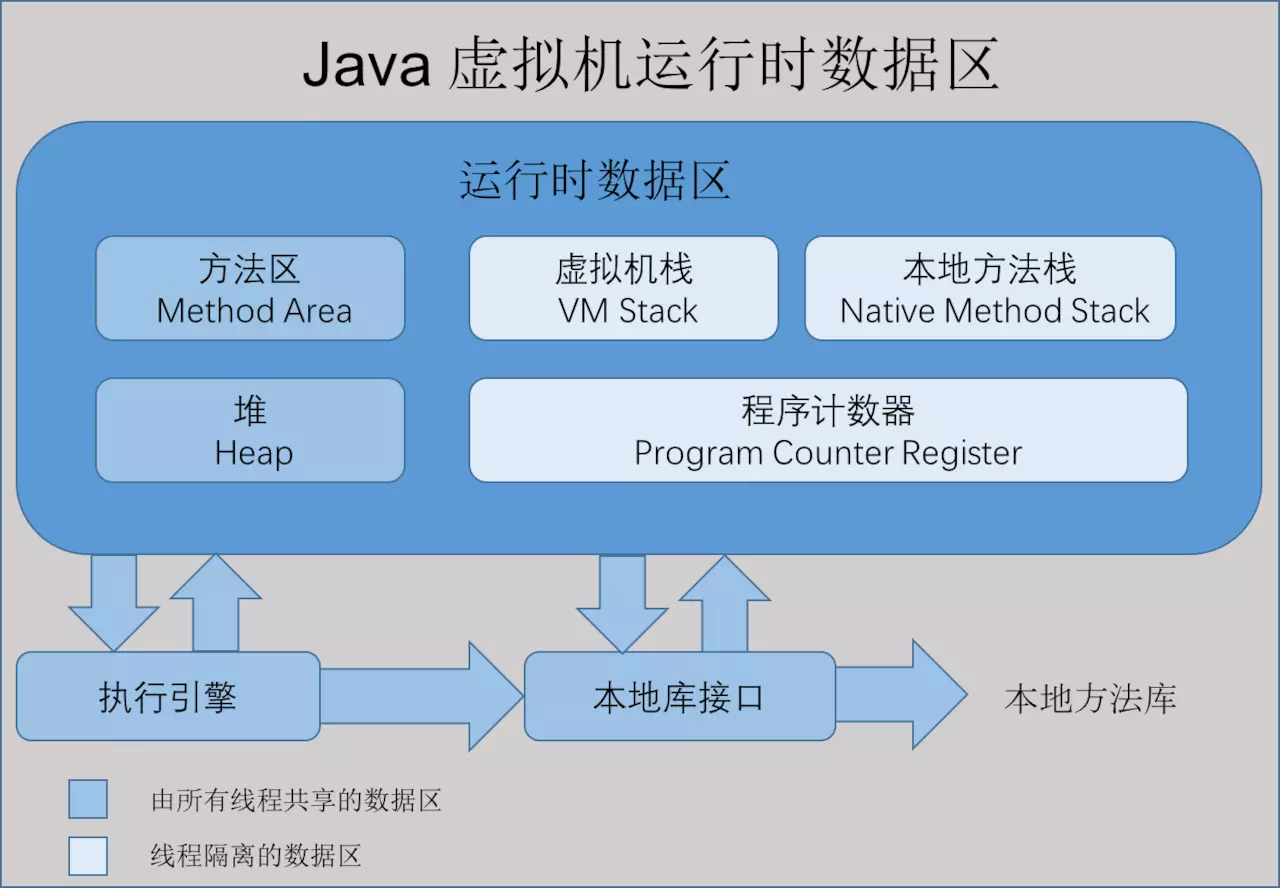
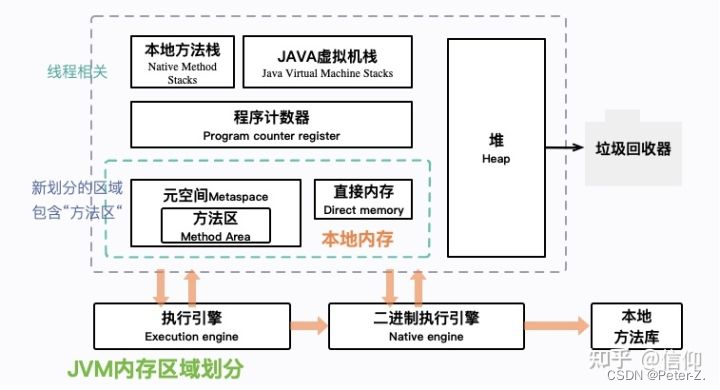
- 从图中可以看出 classloader类加载器,就是将class文件加载到内存,就是把描述类的元数据 以及信息加载到内存 并进行校验,初始化 并最终形成可被虚拟机使用的java类型,这就是java类加载器的作用
- RUNTIME AREA(运行时数据区) 就是我们常说的虚拟机管理的内存模型了。所写的程序都被加载到这里,之后才开始运行。
Java 程序的具体执行过程
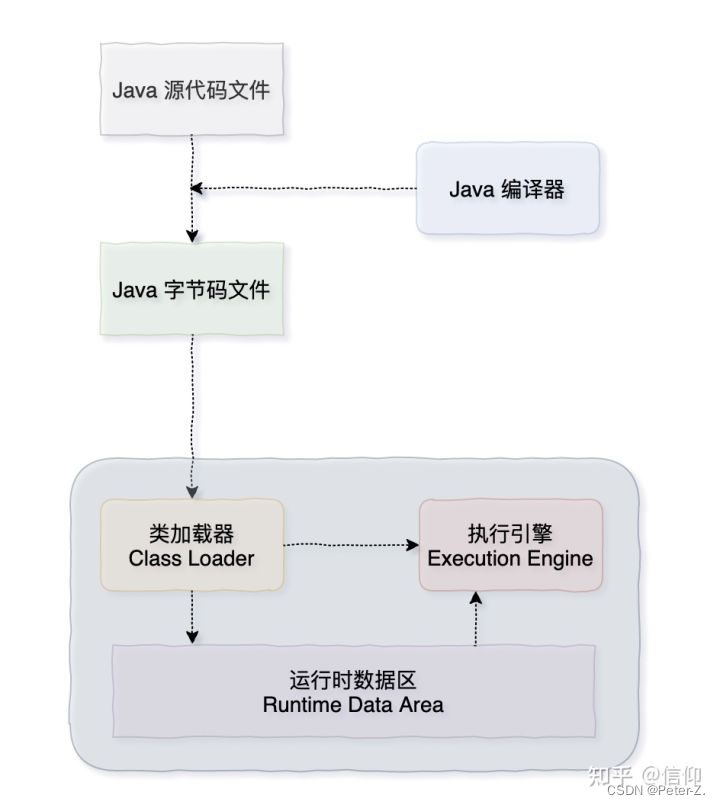
Java 源代码文件经过编译器编译后生成字节码文件,然后交给 JVM 的类加载器,加载完毕后,交给执行引擎执行。在整个执行的过程中,JVM 会用一块空间来存储程序执行期间需要用到的数据,这块空间一般被称为运行时数据区,也就是常说的 JVM 内存。
所以,当我们在谈 JVM 内存区域划分的时候,其实谈的就是这块空间——运行时数据区
堆
线程共享的内存区域,也是最重要的内存区域,存放我们对象的实例,GC垃圾回收器主要在这里工作,基本采用的是分代收集算法,细分为新生代和老年代,更细致的一点又Eden空间 from survivor to survivor 空间 ,所有的对象实例和数组都要在堆中分配
栈区
java栈,java虚拟机栈,线程私有 生命周期和线程生命周期相同,每个方法被执行的时候都会创建一个栈帧,用于存储局部变量表,操作栈 动态链接,方法出口
-
主要保存基本类型(或者叫内置类型)(char、byte、short、int、long、float、double、boolean)和对象的引用,数据可以共享,速度仅次于寄存器(register),快于堆
-
每个栈中的数据(原始类型和对象引用)都是私有的,其他栈不能访问。
-
栈分为3个部分:基本类型变量区、执行环境上下文、操作指令区(存放操作指令)。
先入后出
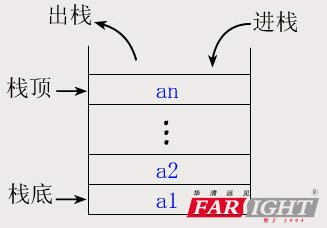
Java 虚拟机栈会出现两种错误:
StackOverFlowError:当方法在进行递归调用时,调用的深度超过虚拟机栈的最大深度时抛出。
OutOfMemoryError:如果 Java 虚拟机栈允许动态扩容,当栈扩容时无法申请到足够的内存时抛出。
最有名的 HotSpot 虚拟机的栈容量是不允许动态扩容的,所以在 HotSpot 虚拟机上是不会出现 OOM 的。
方法区
方法区,存放加载的类信息,常量,静态变量 static 也包括即时编译的信息和利用反射创建的class信息,该部分能够实现线程共享。
-
运行时常量池,在方法区中,每个类型都对应一个常量池存放该类型所用的所有常量,常量池中存储了诸如,常量字符串,flnal变量值,类名及方法名常量,它们以数组形式存储并通过索引被访问,是外部调用与类联系及类型对象化的桥梁,(存的可能是个普通字符串,然后通过常量池解析最后变成指向某个类的引用)
-
字段信息,字段信息存放类中声明的每一个字段的信息,包括字段的名 类型 修饰符字段名称指的是类或接口的实例变量或类变量,字段的描述符是一个指定字段类型的字符串
-
方法信息,类中声明的每一个方法的信息,包括方法名,返回值类型,参数类型,修饰符异常,方法的字节码,(编译的时候,就已经将方法的局部变量,操作数栈大小确定并存放在class字节码中,在装载的时候,随着类一起装入方法区。)
-
静态变量,就是类变量,类的所有实例都共享,在方法去中有一个静态区,静态区专门存放静态变量和静态块
-
jvm为每个加载的类型(包括类和接口)都创建一个java.lang.class的实例,而jvm必须以某种方式把class的这个实例和存储在方法区中的内存数据联系起来。
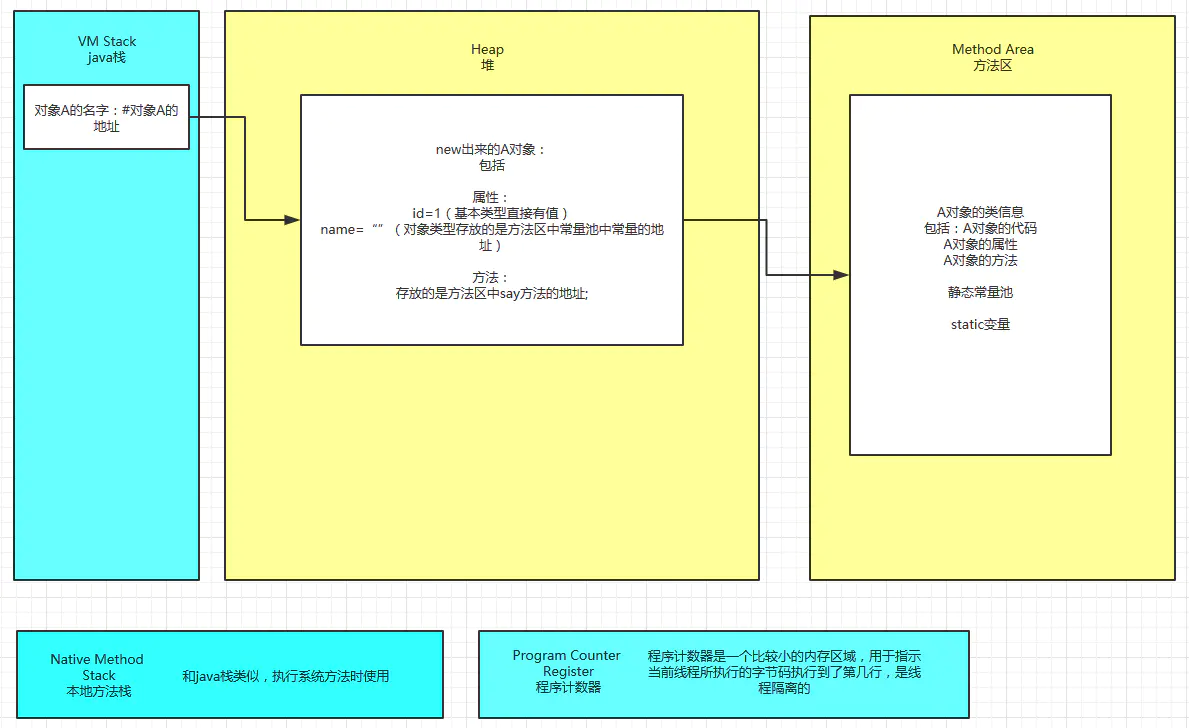
本地方法栈
本地方法栈与 Java 虚拟机栈类似,区别是本地方法栈执行的是本地方法,也就是带有 native 关键字修饰的方法。
在 HotSpot 虚拟机中,本地方法栈和 Java 虚拟机栈不做区分
程序计数器
所占的内存空间不大,很小一块,可以看作是当前线程所执行的字节码指令的行号指示器。字节码解释器会在工作的时候改变这个计数器的值来选取下一条需要执行的字节码指令,像分支、循环、跳转、异常处理、线程恢复等功能都需要依赖这个计数器来完成。
内存调优
https://mikechen.cc/3321.html
堆分类
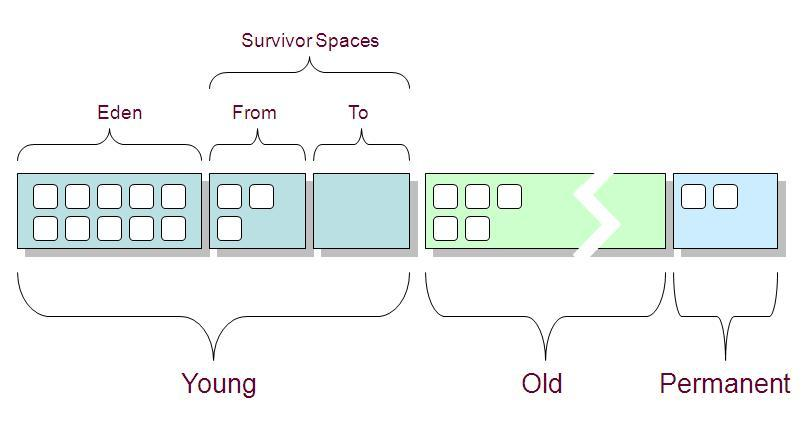
新生代:主要是用来存放新生的对象。
老年代:主要存放应用程序中生命周期长的内存对象。
持久代:是指内存的永久保存区域,主要存放Class和Meta的信息,Class在被 Load的时候被放入PermGen space区域.
调优主要的目的:减少GC的频率和Full GC的次数。
**Minor GC触发条件:**当Eden区满时,触发Minor GC。
Full GC触发条件:
(1)调用System.gc时,系统建议执行Full GC,但是不必然执行
(2)老年代空间不足
(3)方法区空间不足
(4)通过Minor GC后进入老年代的平均大小大于老年代的可用内存
(5)由Eden区、From Space区向To Space区复制时,对象大小大于To Space可用内存,则把该对象转存到老年代,且老年代的可用内存小于该对象大小
常用调优参数:
https://zhuanlan.zhihu.com/p/91223656
https://www.cnblogs.com/wuhg/p/9707974.html
GC回收
堆内存就是GC管理的主要区域(知识点,重点)
JVM又把堆内存分三代,新生代,老年代,持久代.
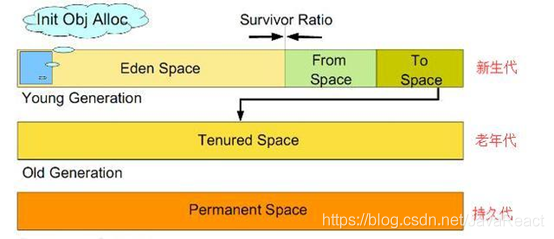
Minor GC:新生代GC。
Major GC/Full GC:老年代GC,指发生在老年代的GC。
https://www.cnblogs.com/E-star/p/5556188.html
机制
寻根: 把所有对象组成一个集合,或可以理解为树状结构,从树根开始找,只要可以找到的都是活动对象,如果找不到,这个对象就被回收了
垃圾回收分为两个阶段:
标记 --> 压缩标记的过程,其实就是判断对象是否可达的过程。当所有的根都检查完毕后,堆中将包含可达(已标记)与不可达(未标记)对象。标记完成后,进入压缩阶段。在这个阶段中,垃圾回收器线性的遍历堆,以寻找不可达对象的连续内存块。并把可达对象移动到这里以节约内存空间
回收算法
标记清理算法:对堆进行遍历,活动对象做好标记,未标记的对象进行回收。(存在内存碎片)
复制算法(eden区gc用 的算法):将堆空间分为大小相同的两个空间,每次使用其中一个,当其中对象存满了,将就其中存活对象复制到另一块未用空间,然后把前面使用过的堆空间一次清理掉。
标记整理算法:先清除需要回收的对象,然后再对内存进行压缩操作,移至连续内存块。
分代收集算法:上面几个算法的综合, Java 堆分为新生代和老年代,这样就可以根据各个年代的特点采用最适当的收集算法。 在新生代中,每次垃圾收集时都发现有大批对象死去,只有少量存活,那就选用复制算法,只需要付出少量存活对象的复制成本就可以完成收集。 而老年代中因为对象存活率较高、没有额外的空间对它进行分配担保,就必须使用“标记-清除”或者“标记-整理”算法来回收。
内存泄漏和内存溢出
1、内存泄漏memory leak :是指程序在申请内存后,无法释放已申请的内存空间,一次内存泄漏似乎不会有大的影响,但内存泄漏堆积后的后果就是内存溢出。
内存泄漏是指你向系统申请分配内存进行使用(new),可是使用完了以后却不归还(delete)。
2、内存溢出 out of memory :指程序申请内存时,没有足够的内存供申请者使用,或者说,给了你一块存储int类型数据的存储空间,但是你却存储long类型的数据,那么结果就是内存不够用,此时就会报错OOM,即所谓的内存溢出。
内存溢出就是你要的内存空间超过了系统实际分配给你的空间,此时系统相当于没法满足你的需求,就会报内存溢出的错误。
二者的关系
内存泄漏的堆积最终会导致内存溢出。
内存溢出的原因及解决方法:
内存溢出原因:
1.内存中加载的数据量过于庞大,如一次从数据库取出过多数据;
2.集合类中有对对象的引用,使用完后未清空,使得JVM不能回收;
3.代码中存在死循环或循环产生过多重复的对象实体;
4.使用的第三方软件中的BUG;
5.启动参数内存值设定的过小
内存溢出的解决方案:
第一步,修改JVM启动参数,直接增加内存。(-Xms,-Xmx参数一定不要忘记加。)
第二步,检查错误日志,查看“OutOfMemory”错误前是否有其 它异常或错误。
第三步,对代码进行走查和分析,找出可能发生内存溢出的位置。

JMM (java内存模型)
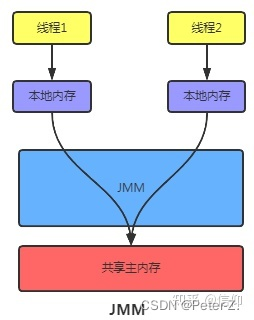
结构
JMM 分为工作内存和主内存,线程无法对主存储器直接进行操作,一个线程要和另外一个线程通信,只能通过主内存进行交换。
主内存:所有线程共享的内存空间。
工作内存:每个线程特有的内存空间。
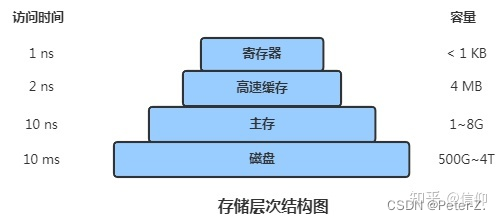
随着CPU、内存、磁盘的高速发展,它们的访问速度差别很大。为了提速就引入了L1、L2、L3三级缓存。以后程序运行获取数据就是如下的步骤了。

这样虽然提速了但是会导致缓存一致性问题跟内存可见性问题。同时编译器和CPU为了加速也引入了指令重排。
重排序:JVM 允许在不影响代码最终结果的情况下,可以乱序执行。
- 编译器优化的重排序:编译器在不改变单线程程序语义的前提下,可以重新安排语句的执行顺序。
- 指令级并行的重排序:现代处理器采用了指令级并行技术在不影响数据依赖性前提下重排。
- 内存系统的重排序:处理器使用缓存和读/写缓冲区 进程重排。
指令重排这种机制会导致有序性问题,而在并发编程时经常会涉及到线程之间的通信跟同步问题,一般说是可见性、原子性、有序性。这三个问题对应的底层就是 缓存一致性、内存可见性、有序性。
原子性:原子性就是指该操作是不可再分的。不论是多核还是单核,具有原子性的变量,同一时刻只能有一个线程来对它进行操作。在整个操作过程中不会被线程调度器中断的操作,都可认为是原子性。比如 a = 1。
可见性:指当多个线程访问同一个变量时,一个线程修改了这个变量的值,其他线程能够立即看得到修改的值。
有序性:程序执行的顺序按照代码的先后顺序执行。
线程间通信
每个线程创建时JVM都会为其创建一个工作内存,工作内存是每个线程的私有数据区域,而JMM 所有变量都存储在主内存,主内存是共享内存区域,所有线程都可以访问。线程对变量的操作在工作内存中进行,首先要将变量从主内存拷贝到自己的工作内存,然后对变量进行操作,操作完成后再将变量写回主内存,不能直接操作主内存中的变量。不同的线程间无法访问对方的工作内存,线程间的通信必须通过主内存来完成。
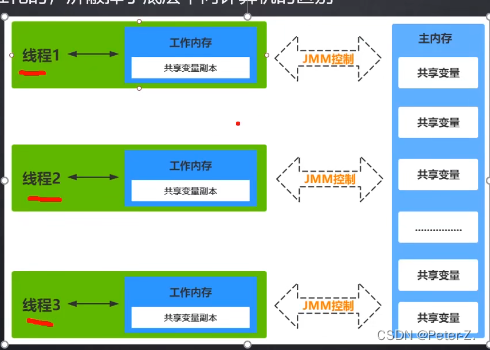
在JMM中,有两条规定:
- 线程对共享变量的所有操作都必须在自己的工作内存中进行,不能直接从主内存中读写。
- 不同线程之间无法访问其他线程工作内存中的变量,线程间变量值的传递需要通过主内存来完成。
共享变量要实现可见性,必须经过如下两个步骤:
- 把工作内存1中更新过的共享变量刷新到主内存中。
- 把主内存中最新的共享变量的值更新到工作内存2中。
同时人们提出了内存屏障、happen-before、af-if-serial这三种概念来保证系统的可见性、原子性、有序性。
内存屏障(Memory Barrier)
内存屏障是一种CPU指令,用于控制特定条件下的重排序和内存可见性问题。Java编译器也会根据内存屏障的规则禁止重排序。Java编译器在生成指令序列的适当位置会插入内存屏障指令来禁止特定类型的处理器重排序,从而保证特定操作的执行顺序。
happen-before
因为有指令重排的存在会导致难以理解CPU内部运行规则,JDK用 happens-before 的概念来阐述操作之间的内存可见性。在JMM 中如果一个操作执行的结果需要对另一个操作可见,那么这两个操作之间必须要存在happens-before关系 。其中CPU的happens-before无需任何同步手段就可以保证的。
程序顺序规则:单线程内,按照程序代码顺序执行操作;
锁定规则:一个unlock操作先行发生于对同一个锁的lock操作;
volatile变量规则:对一个volatile变量的写操作先行发生于对这个变量的读操作;
线程启动规则:Thread对象的start()方法先行发生于此线程的其他动作;
线程中断规则:对线程interrupt()方法的调用先行发生于被中断线程的代码检测到中断事件的发生;
线程终止规则:线程中所有的操作都先行发生于线程的终止检测,我们可以通过Thread.join()方法结束、Thread.isAlive()的返回值手段检测到线程已经终止执行;
对象终结规则:一个对象的初始化完成先行发生于它的finalize()方法的开始;
传递规则:如果操作A先行发生于操作B,而操作B又先行发生于操作C,则可以得出操作A先行发生于操作C;
af-if-serial
af-if-serial 的含义是不管怎么重排序(编译器和处理器为了提高并行度),单线程环境下程序的执行结果不能被改变且必须正确。该语义使单线程环境下程序员无需担心重排序会干扰他们,也无需担心内存可见性问题。
https://zhuanlan.zhihu.com/p/358186481
最后
以上就是魁梧乌冬面最近收集整理的关于Java基础基本数据类型Java类字符数组初始化String、StringBuffer、StringBuilder字符串、json对象、javaBean转换try catch finally执行顺序异常Serializable序列化/反序列化接口volatiletransientbean copy浅复制、深复制接口和抽象类的区别?内部类集合double\float运算io流反射泛型ThreadLocal强引用、软引用、弱引用、虚引用hash一致性算法线程BIO、NIO、AIO锁HttpJVMJM的全部内容,更多相关Java基础基本数据类型Java类字符数组初始化String、StringBuffer、StringBuilder字符串、json对象、javaBean转换try内容请搜索靠谱客的其他文章。








发表评论 取消回复