1.决策树的概念
决策树算法以树状结构表示数据分类的结果,每个决策点实现一个具有离散输出的测试函数,记为分支;
决策树的元素有:根节点、非叶子节点、分支、叶节点四种元素,其代表的含义如下图所示;
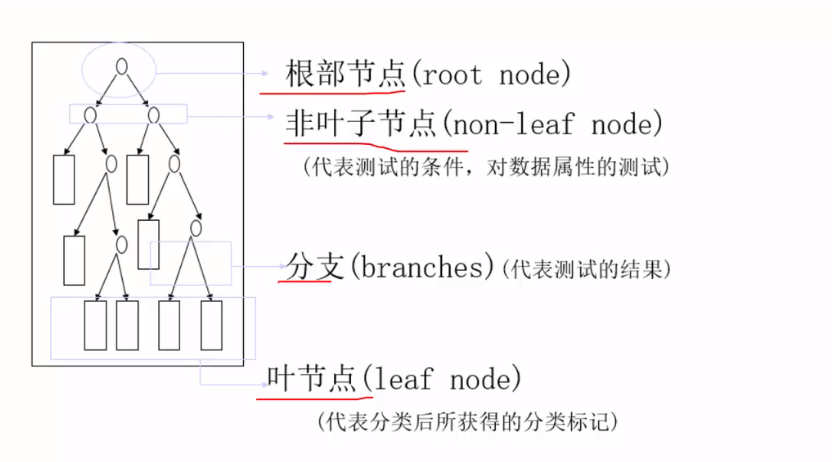
决策树的工作分为两个阶段:
1.训练阶段:给定训练数据集DB,构造出一棵决策树;
2.分类阶段:从根开始,按照决策树的分类属性逐层往下划分,直到叶节点,获得分类结果;
2.熵原理解读
P(XY)=P(X)*P(Y),X和Y这两个事件相互独立,log(XY)=log(X)+log(Y)
设事件X和Y发生的不确定性分别为H(X),H(Y)
对于分类问题而言,就是要尽量使得分类出的样本尽量属于同一个类别,也就是说分出来的类越纯越好,如果一个集合中种类比较纯的话,则集合纯度就比较高,熵值就会比较低,反之如果集合中种类很杂,那熵值就会比较高。我们引入“信息熵”这个概念来衡量特征的纯度,
信息熵的定义:
假如当前样本D中第i类样本所占比例为Pi,n为类别总数,则样本集的信息熵为:
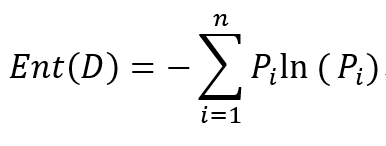
Ent(D)值越小,则D的纯度就越高。
这个公式也决定了信息增益的一个缺点:即信息增益对可取值数目多的特征有偏好(即该属性能取得值越多,信息增益,越偏向这个),因为特征可取的值越多,会导致“纯度”越大,即Ent(D)会很小,如果一个特征的离散个数与样本数相等,那么Ent(D)值会为0
Gini系数计算公式:
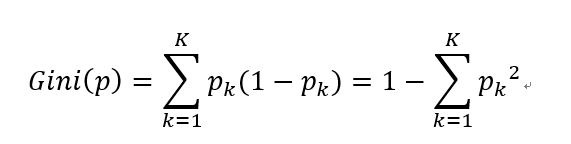
3.决策树构造实例
构造决策树的基本思想是:随着树深度的增加,节点的熵迅速地降低,熵降低的速度越快越好,这样我们有希望得到一个高度最矮的决策树。
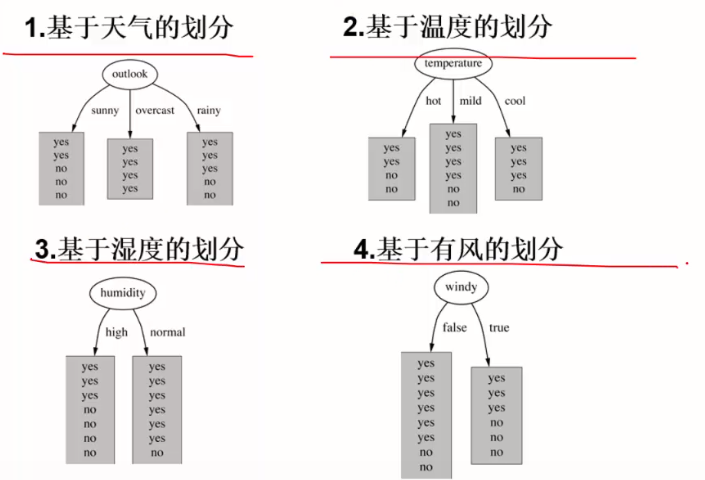
现在有14个样本,有4种不同的环境状况:温度、湿度、有没有风、天气情况,以及最终是否出门,是否出门即为样本标签:
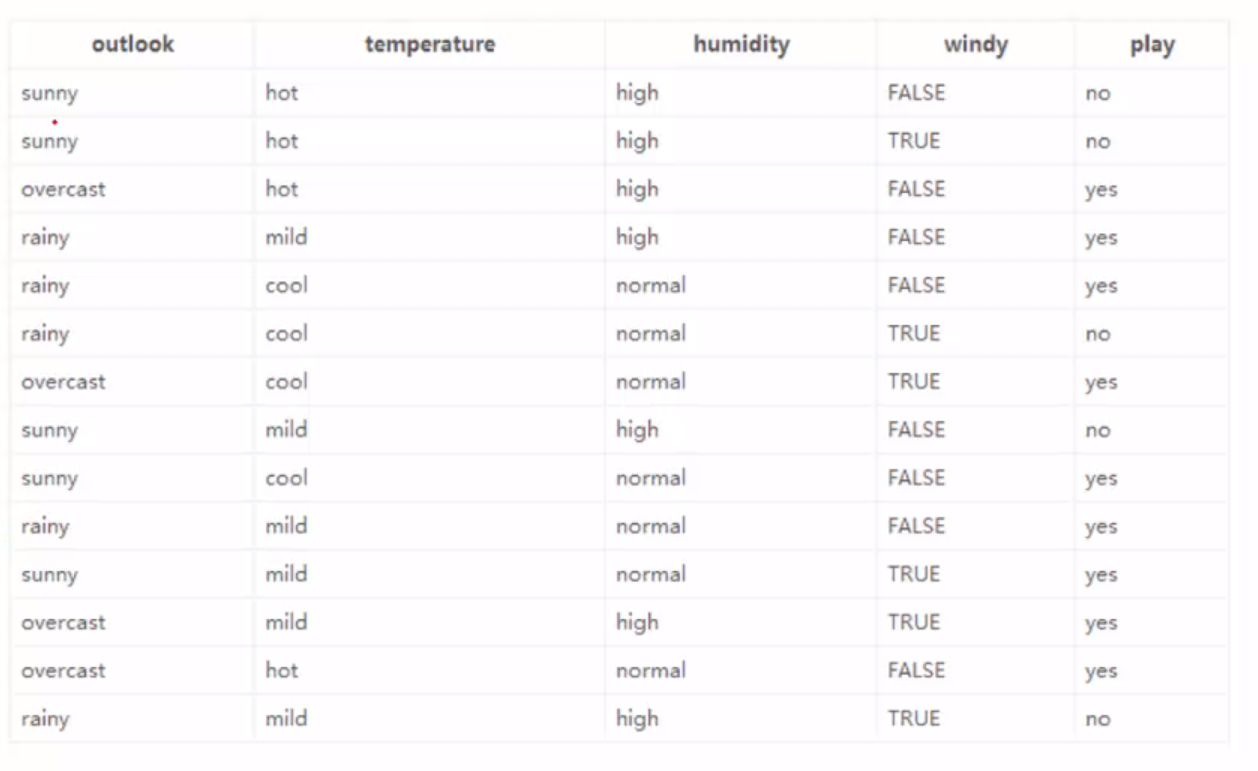
目前有四个属性。根据这4个属性来预测是否出门打球:
在没有给定任何天气信息时,打球概率为9/14,不打的概率为5/14,我们如果什么都不做,那么此时的熵为:
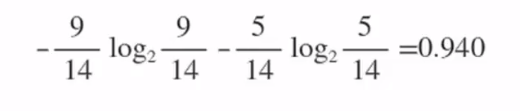
现在要决定将哪个属性作为树的根节点:
我们先引入信息增益的概念:
假设离散属性a有V个可能的取值:
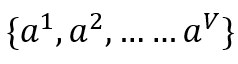
即我们使用特征a来对样本D进行划分,则会有V个分支节点,其中第v个节点包含了数据集D在a特征上取值为av的样本总数,记为Dv,考虑到不同分支节点所包含的样本数量不同,故给所有分支节点加以权重,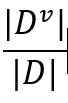
即样本数量越多的分支影响越大,最终得到信息增益的公式如下:
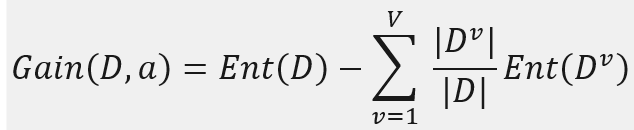
一般来说,信息增益越大,则代表用特征a来对样本D进行分类所获得的“纯度提升”就越大。
我们继续上面的例子进行分析:

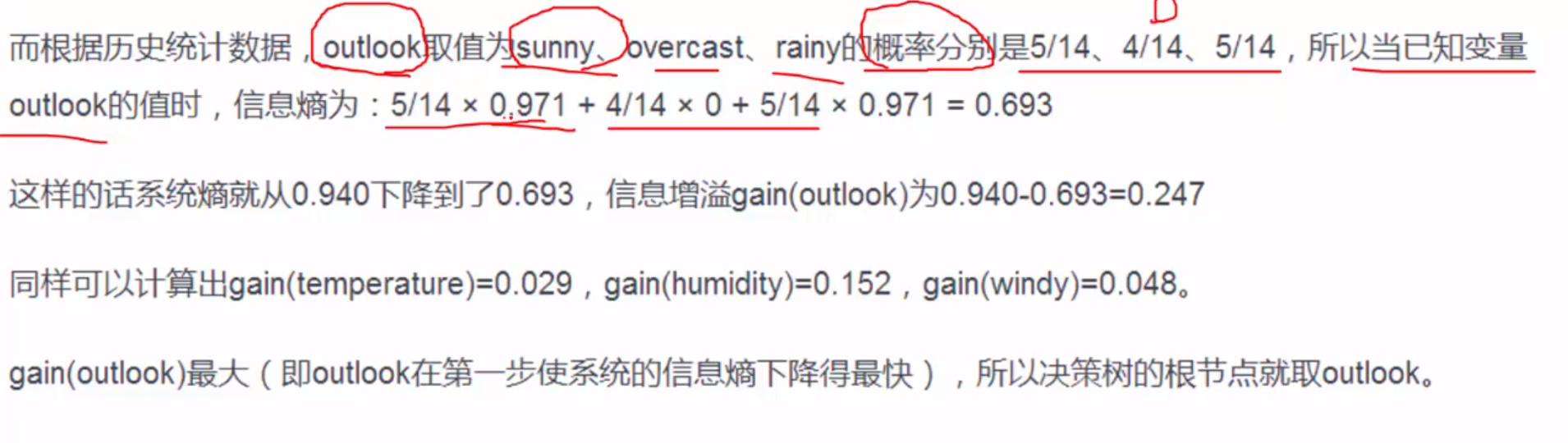
选择根节点的标准:信息增益最大
如果只依赖信息增益作为评价指标的话,可能会出现这种问题:
如果存在一种特征,这种特征对应的属性很多,但是每一个属性对应的样本数量却很少,这种情况下信息增益就会很大。故我们引入信息增益率这个概念:
ID3:信息增益
C4.5:信息增益率
C4.5算法能够处理连续值的属性,需要将连续属性离散化,把连续性属性的值分为不同的区间,其依据是比较各个分裂点信息增益值的大小。
决策树避免过拟合方法:
1.预剪枝:在构建决策树的过程时,提前停止;
2.后剪枝:决策树构建好后,才开始裁剪。
于是我们改变损失函数:
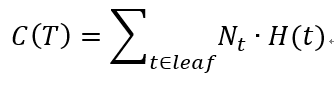
最后
以上就是无聊微笑最近收集整理的关于决策树详解(一)1.决策树的概念2.熵原理解读3.决策树构造实例的全部内容,更多相关决策树详解(一)1.决策树内容请搜索靠谱客的其他文章。








发表评论 取消回复