机器学习算法——决策树相关面试问题及参考答案。
题目列表:
1、写一下信息增益、信息增益率、基尼系数三个公式?
2、C4.5(信息增益率)比较ID3(信息增益)的优点?
3、决策树如何防止过拟合?
4、决策树相比其他算法有什么优势?
5、连续值和缺失值的处理?
-
写一下信息增益、信息增益率、基尼系数三个公式?(参考西瓜书)
1)信息熵的定义:
 2)信息增益公式
2)信息增益公式
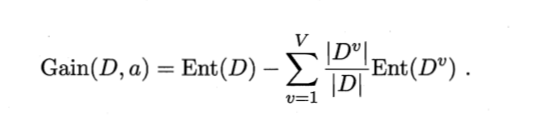
3)信息增益率公式
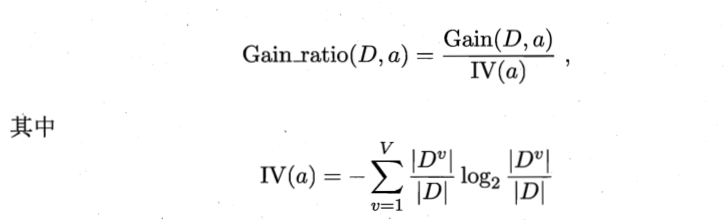
4)基尼指数公式
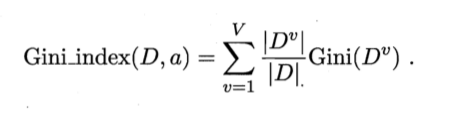 其中,基尼值定义为:
其中,基尼值定义为:

-
C4.5(信息增益率)比较ID3(信息增益)的优点?
ID3算法也暴露出一些问题,具体如下:(1) 信息增益的计算依赖于特征数目较多的特征,而属性取值最多的属性并不一定最优(分类可能会较多)。
(2) ID3是非递增算法。
(3) ID3是单变量决策树(在分枝节点上只考虑单个属性),许多复杂概念的表达困难,属性相互关系强调不够,容易导致决策树中子树的重复或有些属性在决策树的某一路径上被检验多次。
(4) 抗噪性差,训练例子中正例和反例的比例较难控制。C4.5算法继承了ID3算法的优点,并在以下几方面对ID3算法进行了改进(相当于在ID3上加了正则):
- 用信息增益率来选择属性,克服了用信息增益选择属性时偏向选择取值多的属性的不足;
- 在树构造过程中进行剪枝;
- 能够完成对连续属性的离散化处理;
- 能够对不完整数据进行处理。
C4.5算法有如下优点:产生的分类规则易于理解,准确率较高。其缺点是:在构造树的过程中,需要对数据集进行多次的顺序扫描和排序,因而导致算法的低效。此外,C4.5只适合于能够驻留于内存的数据集,当训练集大得无法在内存容纳时程序无法运行。
另外,无论是ID3还是C4.5最好在小数据集上使用,决策树分类一般只试用于小数据。当属性取值很多时最好选择C4.5算法,ID3得出的效果会非常差。 -
决策树如何防止过拟合?
预剪枝,后剪枝,随机森林,添加正则 -
决策树相比其他算法有什么优势?
–决策树易于理解和实现. 人们在通过解释后都有能力去理解决策树所表达的意义。
–对于决策树,数据的准备往往是简单或者是不必要的 . 其他的技术往往要求先把数据一般化,比如去掉多余的或者空白的属性。
–能够同时处理数据型和常规型属性。其他的技术往往要求数据属性的单一。
– 在相对短的时间内能够对大型数据源做出可行且效果良好的结果。
–对缺失值不敏
– 可以处理不相关特征数据
–效率高,决策树只需要一次构建,反复使用,每一次预测的最大计算次数不超过决策树的深度。缺点:对连续性的字段比较难预测;在处理特征关联性比较强的数据时表现得不是太好
决策树是基础,在此之上会紧接着问RF,GBDT
最后
以上就是拼搏过客最近收集整理的关于决策树相关知识点整理(持续更新...)的全部内容,更多相关决策树相关知识点整理(持续更新内容请搜索靠谱客的其他文章。








发表评论 取消回复