前言
Python期末实训周,在做基于随机森林的气温预测时,遇到了决策树可视化中文乱码的问题,在一番折腾后找到了一个解决方法,于是尝试写博客分享。作为新人小白,第一次写博客,有什么不足的地方望指出,非常感谢!
发现问题的过程
在用export_graphviz函数生成tree.dot文件后,用graph = pydotplus.graph_from_dot_file(‘tree.dot’)绘制决策树图,用graph.write_png(‘tree.png’)将该决策图命名为tree.png并保
存到项目文件。
这里借鉴了大佬的博客中“可视化展示与特征重要性”部分的代码
本文链接:https://blog.csdn.net/qq_42549612/article/details/105304889
# 导入工具包
from sklearn.tree import export_graphviz
import pydotplus
# 拿到其中的一棵树
tree = rf.estimators_[5]
# 将图像导出为 dot 文件
export_graphviz(tree, out_file='tree.dot', feature_names=feature_list, rounded=True, precision=1)
# feature_names 每个特征名
# rounded 设置为True时,绘制带有圆角的节点框,并使用Helvetica字体代替Times-Roman
# precision 每个节点的杂质值,阈值和值属性中浮点数的精度位
# 绘图
graph = pydotplus.graph_from_dot_file('tree.dot')
# 展示
graph.write_png('tree.png')
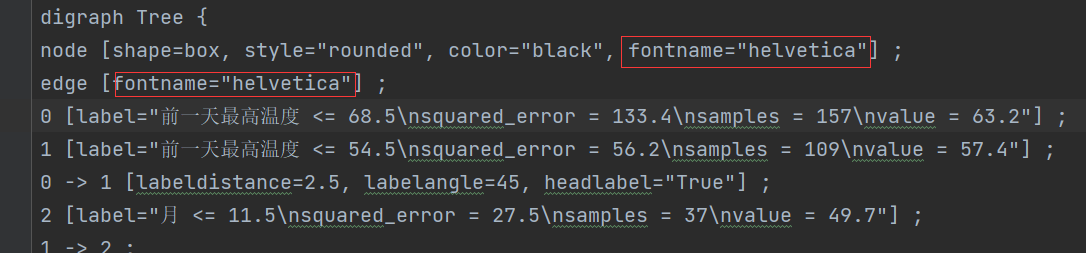 生成的tree.dot文件内容大致如上图,export_graphviz中的rounded=True让该文件的字体,从Times-Roman(支持英文)变成了Helvetica(支持中文),tree.dot文件的中文(如“前一天最高温度”)可以正常显示。
生成的tree.dot文件内容大致如上图,export_graphviz中的rounded=True让该文件的字体,从Times-Roman(支持英文)变成了Helvetica(支持中文),tree.dot文件的中文(如“前一天最高温度”)可以正常显示。
问题描述
接下来思路明确,只要用graph.write_png(‘tree.png’),就可以获得一个tree.png文件了,但是出现了问题,tree.png文件是有了,但该文件里的中文乱码了。
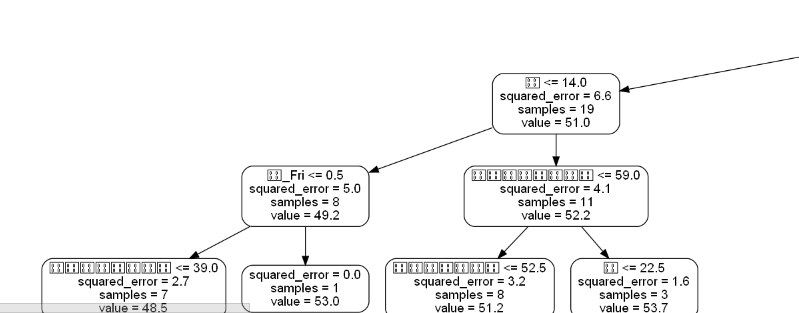 截取到tree.png文件的部分内容如上图
截取到tree.png文件的部分内容如上图
解决问题的过程
遇到问题当然得解决,我也尝试了通过修改Graphviz配置文件解决,但是发现我的2.5版本的Graphviz配置文件里没有fonts这个文件,卸载重装到默认路径也没有(已经配置好了环境变量)

在觉得这个方法折腾不下去后,我又去找其他方法,在这过程里,了解到决策树图中文乱码和tree.dot文件的字体有关系。
虽然Helvetica字体支持在tree.dot里显示中文,但是在tree.png(决策树图)里会乱码。
考虑到export_graphviz()函数不能随意更改文件的字体
于是我尝试了手动修改tree.dot文件的字体为Microsoft YaHei(微软雅黑)

并将代码中生成tree.dot文件的部分注释掉,这样在重新运行该程序时就不会生成新的字体为Helvetica的tree.dot文件,覆盖掉我修改好字体的文件了。
# 导入工具包
from sklearn.tree import export_graphviz
import pydotplus
# 拿到其中的一棵树
# tree = rf.estimators_[5]
# 将图像导出为 dot 文件
# export_graphviz(tree, out_file='tree.dot', feature_names=feature_list, rounded=True, precision=1)
# feature_names 每个特征名
# rounded 设置为True时,绘制带有圆角的节点框,并使用Helvetica字体代替Times-Roman
# precision 每个节点的杂质值,阈值和值属性中浮点数的精度位数
# 绘图
graph = pydotplus.graph_from_dot_file('tree.dot')
# 展示
graph.write_png('tree.png')
如此一来,graph = pydotplus.graph_from_dot_file(‘tree.dot’)中的tree.dot文件就是已经被修改好字体的了
运行后得到的tree.png如下图
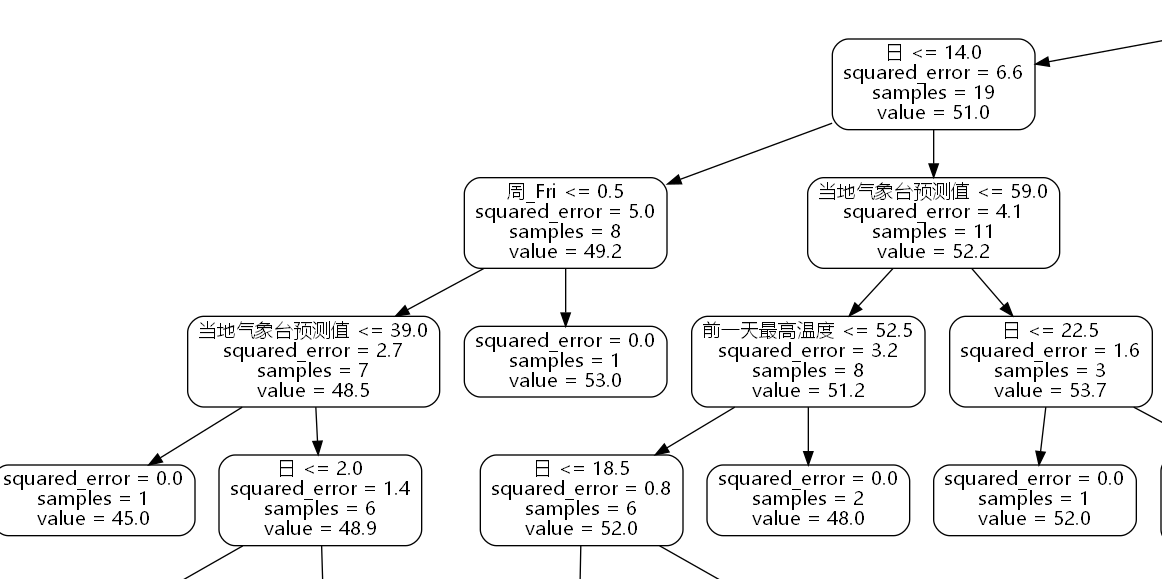
中文可以正常显示了
解决方法
问题虽然解决了,但是这样等于要另外添加一个手动修改字体的tree.dot文件进去,为了把这个手动修改的操作自动化并且不将这个功能与原来的.py文件分开,我尝试用函数将tree.dot文件中的fontname="Helvetica"改为fontname=“Microsoft YaHei”
代码如下
# 导入工具包
from sklearn.tree import export_graphviz
import pydotplus
# 新添一个os库
import os
# 创建一个改字体的函数
def typeface(file):
old = 'helvetica'
new = 'Microsoft YaHei'
with open(file, "r+", encoding='UTF-8') as filedot:
lines = filedot.read()
filedot.seek(0)
lines = lines.replace(old, new)
filedot.write(lines)
# 判断tree文件是否存在 如果不存在则先生成该文件
if not os.path.exists('tree.dot'):
# 拿到其中的一棵树
tree = rf.estimators_[5]
# 将图像导出为 dot 文件
export_graphviz(tree, out_file='tree.dot', feature_names=feature_list, rounded=True, precision=1)
# feature_names 每个特征名
# rounded 设置为True时,绘制带有圆角的节点框,并使用Helvetica字体代替Times-Roman
# precision 每个节点的杂质值,阈值和值属性中浮点数的精度位数
# 调用函数改字体
typeface('tree.dot')
# 绘图
graph = pydotplus.graph_from_dot_file('tree.dot')
# 展示
graph.write_png('tree.png')
其中函数部分借鉴了博主的代码
本文链接:https://blog.csdn.net/nuanfeng_/article/details/102907463
可以得到微软雅黑字体的tree.dot文件和能正常显示中文的决策树(tree.png图片文件)
结尾
至此我的分享就结束了,非常感谢大家
最后
以上就是机智石头最近收集整理的关于决策树结果可视化中文乱码问题 用函数解决前言发现问题的过程问题描述解决问题的过程解决方法结尾的全部内容,更多相关决策树结果可视化中文乱码问题内容请搜索靠谱客的其他文章。








发表评论 取消回复