文章目录
- 构造数据
- 决策树解决
- 报错解决
- 源码地址
构造数据
我们用pandas生成20条数据,其中标签为bad的数据有6条,标签为good的数据有14条,代码如下:
import pandas as pd
import numpy as np
bad_df = pd.DataFrame(data={
"sex":['男', '男', '女', '男', '女', '男'],
"status":['单身', '已婚', '已婚', '单身', '已婚', '单身'],
"age":[39, 25, 26, 26, 21, 27],
"month":[15, 12, 12, 42, 30, 48],
"amount":[1271, 1484, 609, 4370, 3441, 10961],
"y":["bad"]*6,
})
good_df = pd.DataFrame(data={
"sex":['男','女','女','男','男','女','男','男','女','男','女','男','男','男'],
"status":['单身','已婚','已婚','单身','单身','已婚','单身','单身','已婚','单身','已婚','单身','单身','单身'],
"age":[29, 26, 26, 47, 32, 59, 56, 51, 31, 23, 28, 45, 36, 36],
"month":[24, 12, 24, 15, 48, 15, 12, 6, 21, 13, 24, 6, 36, 12],
"amount":[2333,763,2812,1213,7238,5045,618,1595,2782,882,1376,1750,2337,1542],
"y":["good"]*14,
})
df = pd.concat(objs=[bad_df,good_df],ignore_index=True)
数据中包括:sex(性别)、status(婚姻状况)、age(年龄)、month(贷款年限)、amount(贷款金额)、y(客户标签:good未逾期,bad逾期)。
数据预览如下:
| sex | status | age | month | amount | y | |
|---|---|---|---|---|---|---|
| 0 | 男 | 单身 | 39 | 15 | 1271 | bad |
| 1 | 男 | 已婚 | 25 | 12 | 1484 | bad |
| 2 | 女 | 已婚 | 26 | 12 | 609 | bad |
| 3 | 男 | 单身 | 26 | 42 | 4370 | bad |
| 4 | 女 | 已婚 | 21 | 30 | 3441 | bad |
| 5 | 男 | 单身 | 27 | 48 | 10961 | bad |
| 6 | 男 | 单身 | 29 | 24 | 2333 | good |
| 7 | 女 | 已婚 | 26 | 12 | 763 | good |
| 8 | 女 | 已婚 | 26 | 24 | 2812 | good |
| 9 | 男 | 单身 | 47 | 15 | 1213 | good |
| 10 | 男 | 单身 | 32 | 48 | 7238 | good |
| 11 | 女 | 已婚 | 59 | 15 | 5045 | good |
| 12 | 男 | 单身 | 56 | 12 | 618 | good |
| 13 | 男 | 单身 | 51 | 6 | 1595 | good |
| 14 | 女 | 已婚 | 31 | 21 | 2782 | good |
| 15 | 男 | 单身 | 23 | 13 | 882 | good |
| 16 | 女 | 已婚 | 28 | 24 | 1376 | good |
| 17 | 男 | 单身 | 45 | 6 | 1750 | good |
| 18 | 男 | 单身 | 36 | 36 | 2337 | good |
| 19 | 男 | 单身 | 36 | 12 | 1542 | good |
- 根据上面的信息,并没有直接的答案,比如:当age<20,y就是bad。找不到类似这样的结论。
- 可以选用决策树算法来判断,如下图。从上往下走,最后结果为1(bad)
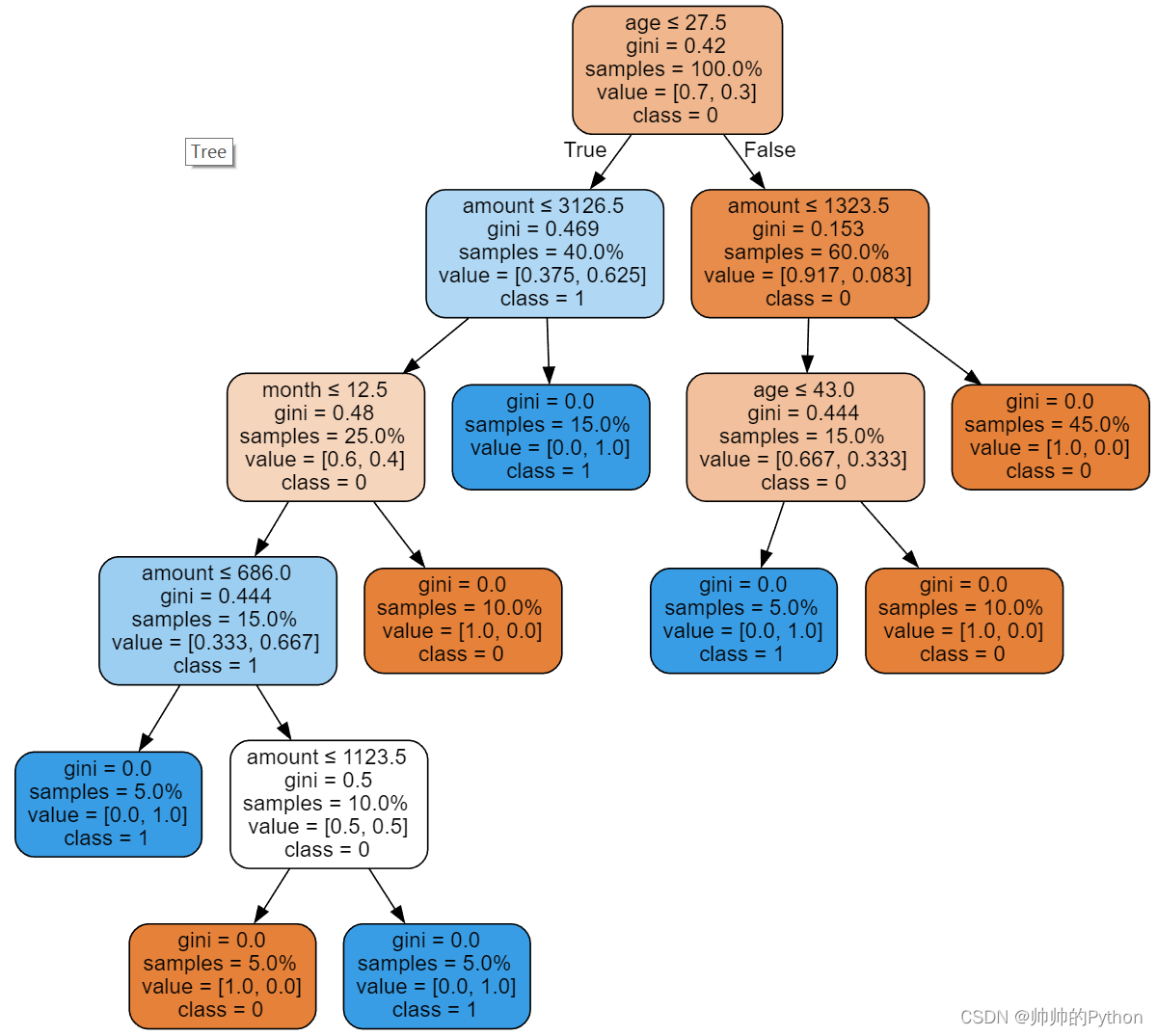
决策树解决
优点:通俗易懂,便于理解
缺点:随着样本的改变而出现不同的树
sklearn地址:https://scikit-learn.org/stable/modules/tree.html
简单了解一下CART(Classification And Regression Tree)
- 最核心的一个概念,GINI系数。
G I N I k = T k T ∗ ( 2 ∗ T k 0 T k ∗ T k 1 T k ) + S T ∗ ( 2 ∗ T s 0 S ∗ T s 1 S ) GINI_k=frac{T_k}{T}*(2*frac{T_{k0}}{T_{k}}*frac{T_{k1}}{T_k})+frac{S}{T}*(2*frac{T_{s0}}{S}*frac{T_{s1}}{S}) GINIk=TTk∗(2∗TkTk0∗TkTk1)+TS∗(2∗STs0∗STs1)
T
:
总样本数
T:总样本数
T:总样本数
T
k
:
第
k
个分组的样本数
T_k:第k个分组的样本数
Tk:第k个分组的样本数
T
k
0
:
第
k
个分组的样本中
y
=
0
的样本数
T_{k0}:第k个分组的样本中y=0的样本数
Tk0:第k个分组的样本中y=0的样本数
T
k
1
:
第
k
个分组的样本中
y
=
1
的样本数
T_{k1}:第k个分组的样本中y=1的样本数
Tk1:第k个分组的样本中y=1的样本数
S
=
T
−
T
k
,
去掉
k
个分组之后的所有样本数据
S=T-T_k,去掉k个分组之后的所有样本数据
S=T−Tk,去掉k个分组之后的所有样本数据
T
s
0
:
S
中
y
=
0
的样本数
T_{s0}:S中y=0的样本数
Ts0:S中y=0的样本数
T
s
1
:
S
中
y
=
1
的样本数
T_{s1}:S中y=1的样本数
Ts1:S中y=1的样本数
- 步骤:(数值型数据,比如收入)
- 对收入数据去重排序后,相邻的数据取平均数,得到A1,A2,A3,…
- 以A1,A2,A3,…为分界线,计算每一个A对应的GINI系数,
- 选择最小的GINI系数为分割点,继续第1,2步,直到达到条件结束。
- 最小的GINI系数小于阈值,结束。
- 数的深度(划分的区间)大于指定的区间,结束。
- 步骤:(分类型数据,比如婚姻)
- 分类型数据,数据已经分好,比如分为单身(A1),已婚(A2),离婚(A3),其他(A4)
- 计算所有组合的GINI系数
- 选择最小的GINI系数为分割点,继续第1,2步,直到达到条件结束
- 最小的GINI系数小于阈值,结束。
- 数的深度(划分的区间)大于指定的区间,结束。
- 决策树步骤:
- 计算所有特征每一个分组的GINI系数,最小的GINI系数为根节点,划分好数据
- 继续计算每个划分好的GINI系数,找出最小的GINI系数,为根节点,继续重复
- 最小的GINI系数小于阈值,结束。
- 数的深度(划分的区间)大于指定的区间,结束。
代码如下:
df2 = df.copy()
# 修改一下数据类型,
# sex:0(男),1(女)
# status:0(单身),1(已婚)
# y:0(good),1(bad)
df2["sex"] = df2["sex"].map(lambda x:0 if x=="男" else 1)
df2["status"] = df2["status"].map(lambda x:0 if x=="单身" else 1)
df2["y"] = df2["y"].map(lambda x:0 if x=="good" else 1)
from sklearn import tree
X, y = df2.iloc[:,:-1],df2.iloc[:,-1]
clf = tree.DecisionTreeClassifier()
clf = clf.fit(X, y)
import graphviz
dot_data = tree.export_graphviz(clf, out_file=None)
graph = graphviz.Source(dot_data)
# graph.render("tree") pdf
iris = load_iris()
dot_data = tree.export_graphviz(clf, out_file=None,proportion=True,
feature_names=['sex', 'status', 'age', 'month', 'amount',],
class_names=["0","1"],
filled=True, rounded=True,
special_characters=True)
graph = graphviz.Source(dot_data)
jupyter中查看graph结果如下:
graph
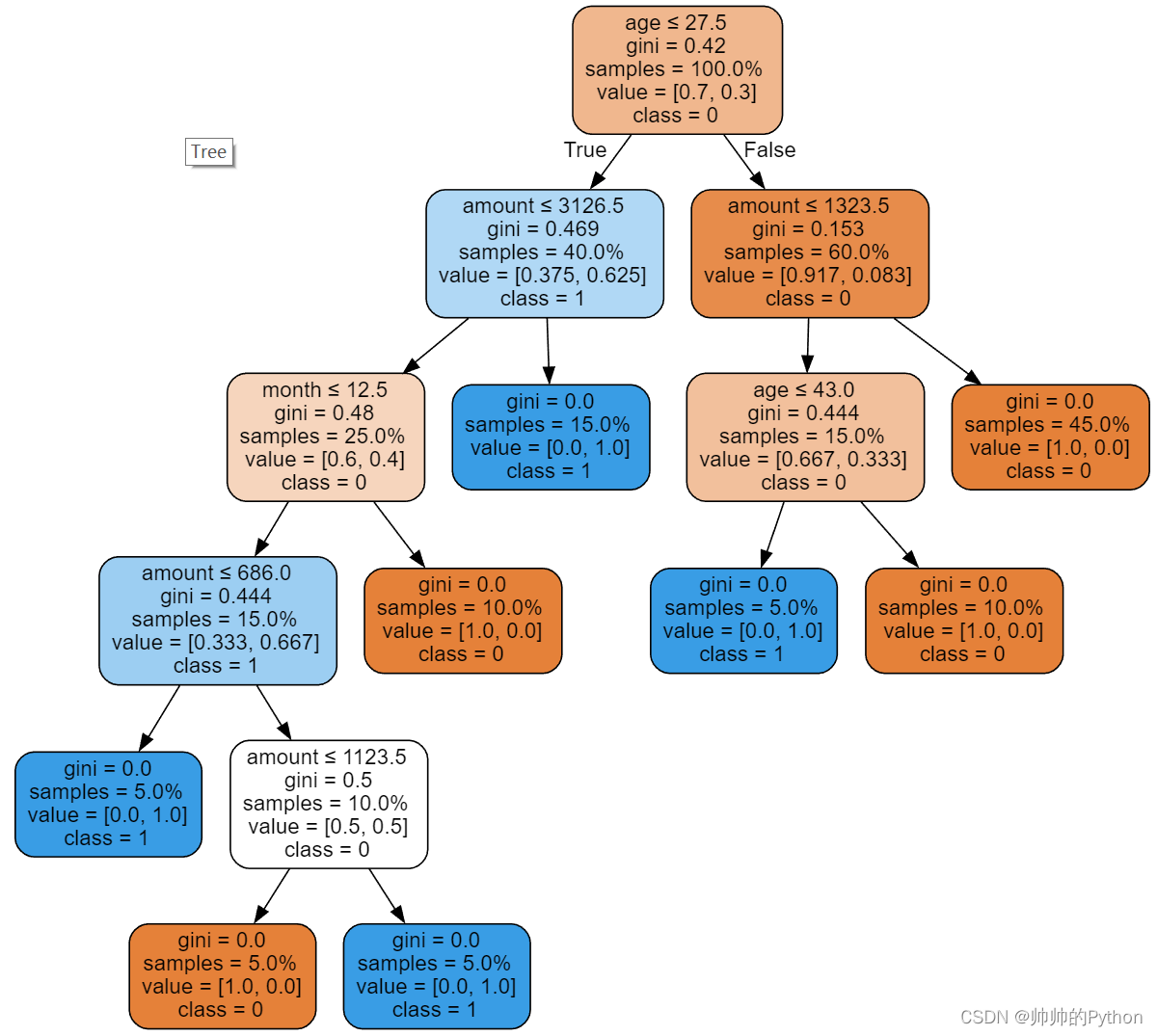
# 预测sex=男,status=单身,age=24,month=12,amount=2000,的结果
clf.predict(X=[[0,0,24,12,2000]])
# array([1])
预测结果为1,(bad),所以sex=男,status=单身,age=24,month=12,amount=2000的客户,可能为逾期用户。
报错解决
- failed to execute WindowsPath(‘dot‘), make sure the Graphviz executables are on your systems‘ PATH
1、安装graphviz
pip install graphviz
2、打开 https://graphviz.org/download/ 官网下载对应的版本,例如:windows_10_cmake_Release_graphviz-install-8.0.3-win64.exe
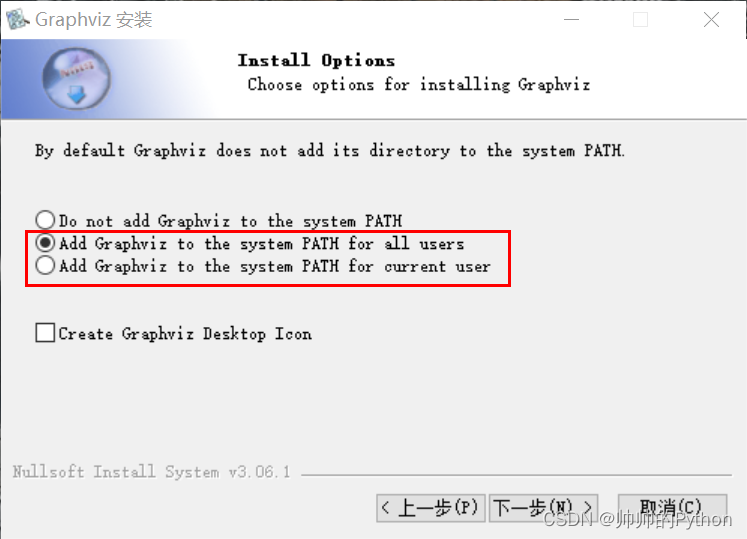
3、安装时勾选 Add Graphviz to the system PATH for all users,点击下一步直到安装成功即可。
4、重启电脑即可解决
源码地址
链接:https://pan.baidu.com/s/1G2agrUMALP6oPfBeHdqRaQ?pwd=ogn3
提取码:ogn3
最后
以上就是甜蜜夏天最近收集整理的关于机器学习决策树算法案例实战更多好玩的内容,欢迎关注微信公众号《帅帅的Python》的全部内容,更多相关机器学习决策树算法案例实战更多好玩内容请搜索靠谱客的其他文章。








发表评论 取消回复