第二章
1.归类八元组

归类输入对应信息提供者,归类输出对应学习者。
划分矩阵
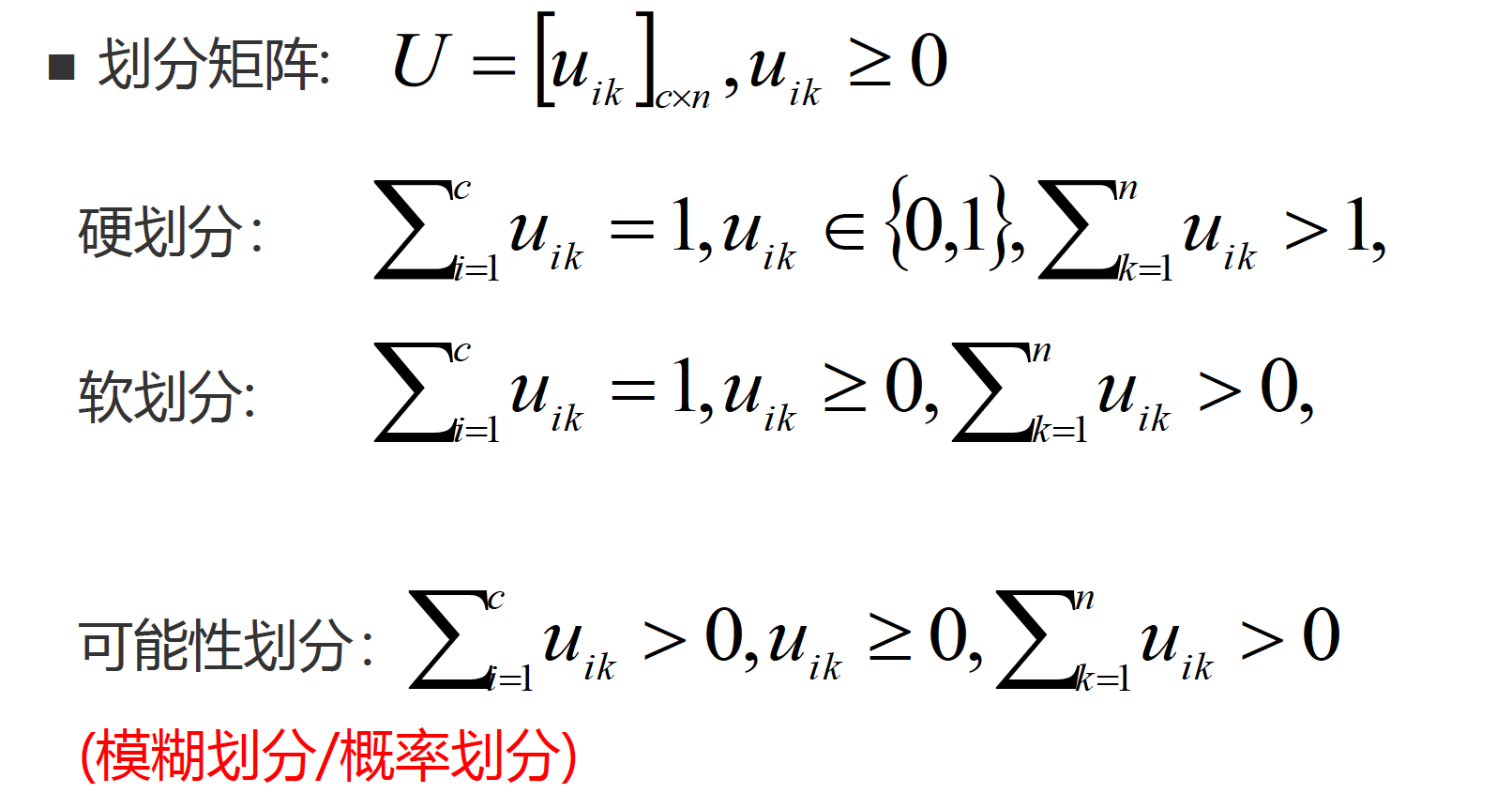
2.类表示
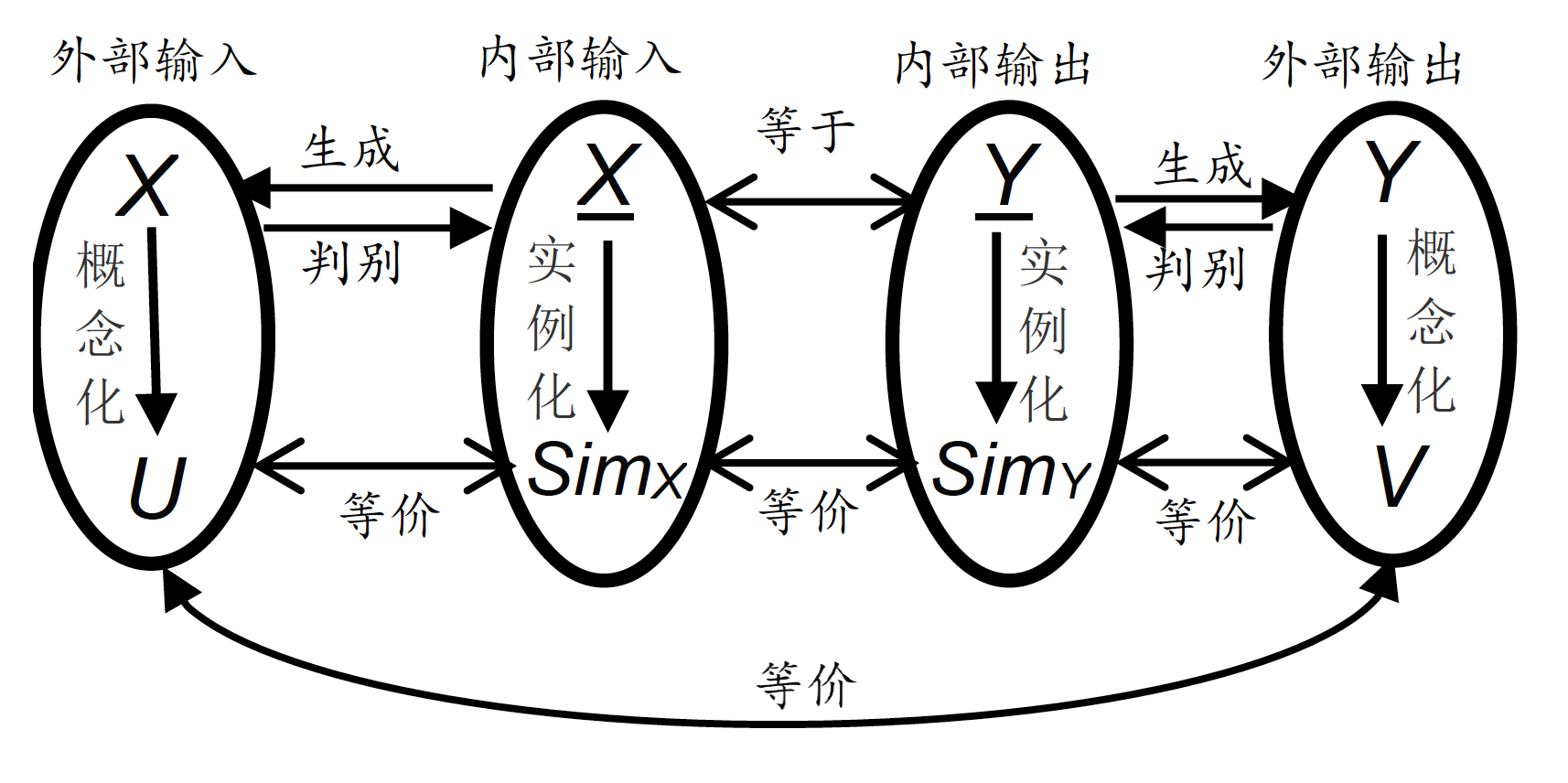
类表示存在公理: 对一个归类算法,外显输入为
(
X
,
U
)
(X,U)
(X,U),外显输出为
(
Y
,
V
)
(Y,V)
(Y,V),则一定存在对应的内在输入
(
X
‾
,
S
i
m
X
)
(underline{X},Sim_X)
(X,SimX)和内在输出
(
Y
‾
,
S
i
m
Y
)
(underline{Y},Sim_Y)
(Y,SimY)
类表示唯一公理: 对一个归类算法,如果其输入为
(
X
,
U
,
X
‾
,
S
i
m
X
)
(X,U,underline{X},Sim_X)
(X,U,X,SimX),其输出为
(
Y
,
V
,
Y
‾
,
S
i
m
Y
)
(Y,V,underline{Y},Sim_Y)
(Y,V,Y,SimY),则
(
X
⃗
,
X
‾
,
X
~
)
=
(
Y
⃗
,
Y
‾
,
Y
~
)
(vec{X},underline{X},widetilde{X}) = (vec{Y},underline{Y},widetilde{Y})
(X,X,X
)=(Y,Y,Y
)(指派算子,认知表示,相似算子)。
如果
Y
‾
underline{Y}
Y(输出类认知表示)被归类算法显式输出,则算法称为白箱算法。在白箱算法中,
Y
‾
underline{Y}
Y对于使用者和设计者都是可见的。(如回归模型)
如果
Y
‾
underline{Y}
Y不被归类算法显式输出,则算法称为黑箱算法。在黑箱算法中,
Y
‾
underline{Y}
Y对于使用者是不可见的,但对于设计者可见。(如深度神经网络,CNN)
3.三大归类公理
(1)样本可分性公理:
∀
k
,
∃
i
,
(
y
~
k
=
i
)
forall{k},exist{i},(widetilde{y}_{k}=i)
∀k,∃i,(y
k=i),一个对象总有唯一一个类与其最相似。
(2)类可分性公理:
∀
i
,
∃
k
,
(
y
~
k
=
i
)
forall{i},exist{k},(widetilde{y}_{k}=i)
∀i,∃k,(y
k=i),一个类至少有一个对象与其最相似。
(3)归类等价公理:
Y
⃗
=
Y
~
vec{Y}=widetilde{Y}
Y=Y
,对于任意一个类,其认知表示和外延表示的归类能力等价。
4.归类准则
(1)类一致性准则: 类表示唯一公理要求太高,设计归类算法时应使得归类结果尽量接近类表示唯一公理。
类紧致准则: 每个对象与最相似类和其次相似类的相似程度差别要大。即类内相似度最大、类内方差最小。
类分离性准则: 一个好的归类结果应该使不同类表示的差异最大。
生成式模型: 输出类的认知表示
Y
‾
underline{Y}
Y理论上可以生成外部输出表示
Y
Y
Y,则该输出类的认知表示为生成式,由该认知表示导出的归类模型为生成式模型
判别式模型:
Y
Y
Y可以得到类认知表示
Y
‾
underline{Y}
Y,但由
Y
‾
underline{Y}
Y理论上不能生成外部输出表示
Y
Y
Y,则该输出类的认知表示为判别式,由该认知表示导出的归类模型为判别式模型。
奥卡姆剃刀原则: 对于性能相同或者相近的模型或理论,选择简单的。
作业第8题:

作业第9题:
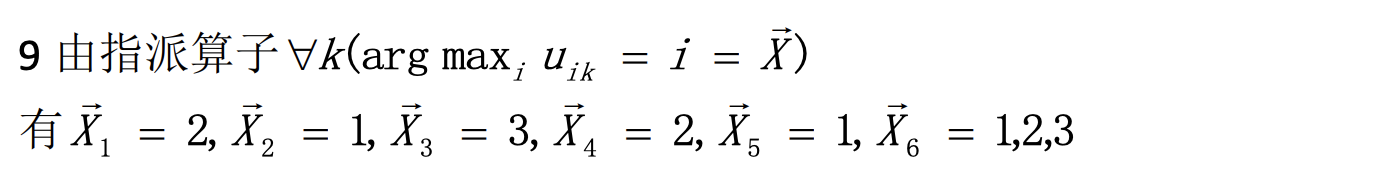
第三章
1.参数估计
密度估计问题可看作具有归类输入
(
X
,
U
,
X
‾
,
S
i
m
X
)
(X,U,underline{X},Sim_X)
(X,U,X,SimX)和归类输出
(
Y
,
V
,
Y
‾
,
S
i
m
Y
)
(Y,V,underline{Y},Sim_Y)
(Y,V,Y,SimY)的归类问题(单类归类问题)
对于密度估计问题,
X
‾
=
Y
‾
underline{X}=underline{Y}
X=Y一般不成立。
参数估计: 若知道
p
(
x
)
p(x)
p(x)的部分信息,比如
p
(
x
)
p(x)
p(x)属于某个概率分布族(高斯),计算
p
^
(
x
)
hat p(x)
p^(x)就是参数估计。
非参数估计: 若除????外,对
p
(
x
)
p(x)
p(x)一无所知,此时计算
p
^
(
x
)
hat p(x)
p^(x)就是非参数估计。
1.1最大似然估计

1.2 高斯密度估计(掌握)

由公式(3.2),得如下目标函数:
min
L
=
∑
k
=
1
N
−
ln
(
p
(
x
k
∣
θ
^
)
)
=
∑
k
=
1
N
(
1
2
(
∥
x
k
−
μ
^
∥
σ
^
p
)
2
+
ln
(
(
2
π
)
p
o
^
2
p
)
)
.
min quad L=sum_{k=1}^{N}-ln left(pleft(x_{k} | hat{theta}right) right)=sum_{k=1}^{N}left(frac{1}{2}left(frac{left|x_{k}-hat{mu}right|}{hat{sigma}^{p}}right)^{2}+ln (sqrt{(2 pi)^{p} hat{o}^{2 p}})right) .
minL=k=1∑N−ln(p(xk∣θ^))=k=1∑N(21(σ^p∥xk−μ^∥)2+ln((2π)po^2p)).
1.3贝叶斯估计(了解)
基于历史经验,不仅知道分布形式,甚至对????的信息有所了解,但会随着观察的积累增多而改变,具有不确定性。


2.非参数估计(了解)
2.1直方图
基本思想: 利用极限思想,将空间划分成合适的等大区域,通过统计区域内的密度来得到
p
^
(
x
)
hat p(x)
p^(x)。

优点:计算简单;适用于本身离散型的随机变量。
缺点: 估计的函数不连续。没有样本点的区域密度估计直接为零,有样本点的区域估计密度很大,显然误差很大。维数灾难!
2.2核密度估计

K近邻
固定划分区域内的样本点个数为K,划分区域的体积大小自适应确定。

在样本密度比较高的区域的体积就会比较小,而在密度低的区域的体积则会自动增大,这样就能够较好的兼顾在高密度区域估计的分辨率和在低密度区域估计的连续性。
课后第2题:
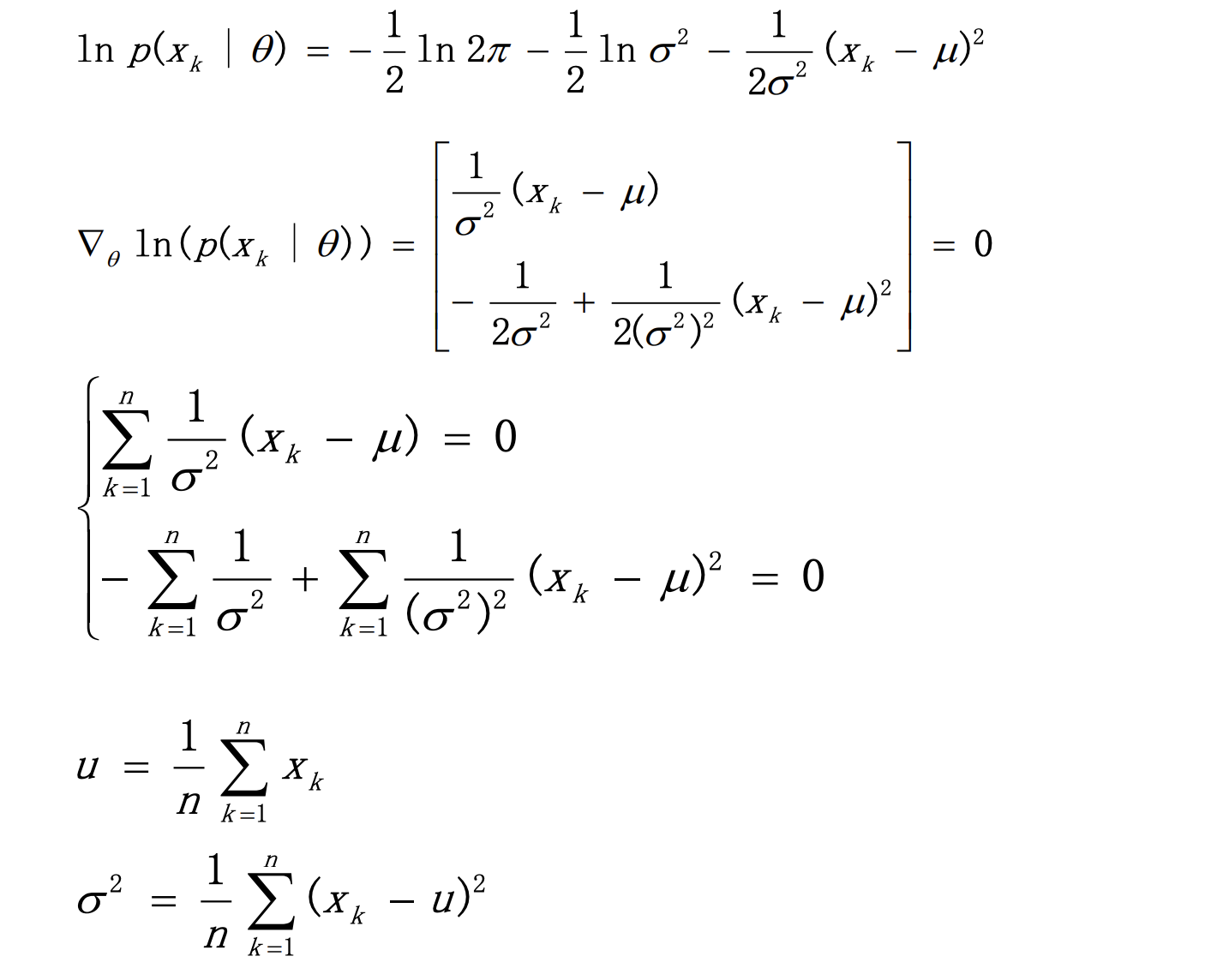
第四章
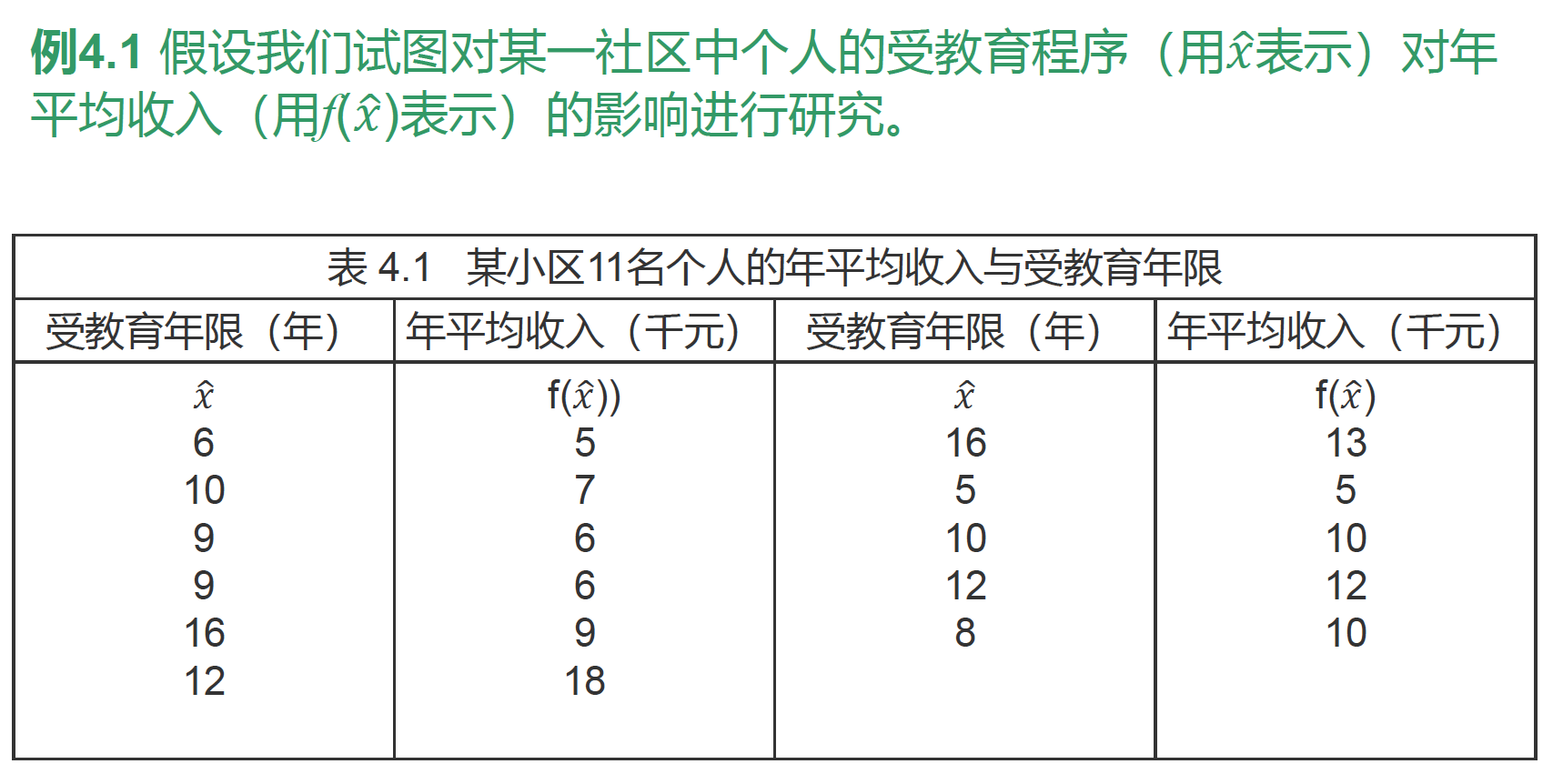
1.线性回归
已知
x
=
(
x
^
,
f
(
x
^
)
)
x=(hat x,f(hat x))
x=(x^,f(x^))的N个观测值
(
x
^
1
,
f
(
x
^
1
)
)
(hat x_1,f(hat x_1))
(x^1,f(x^1)),
(
x
^
2
,
f
(
x
^
2
)
)
(hat x_2,f(hat x_2))
(x^2,f(x^2)) …
(
x
^
N
,
f
(
x
^
N
)
)
(hat x_N,f(hat x_N))
(x^N,f(x^N)), 但不知
(
x
^
,
f
(
x
^
)
)
(hat x,f(hat x))
(x^,f(x^)),这里
f
f
f 称为期望回归函数,试求
(
x
^
,
f
(
x
^
)
)
(hat x,f(hat x))
(x^,f(x^)) 。
假设学到的输出类内部表示为
(
x
^
,
F
(
x
^
)
)
(hat x,F(hat x))
(x^,F(x^)),其中
F
F
F称为学到的回归函数。

最小二乘法损失函数
D
(
f
(
X
)
,
F
(
X
)
)
=
L
(
ω
,
b
)
=
1
N
∑
k
=
1
N
(
ω
x
^
k
+
b
−
f
(
x
^
k
)
)
2
D(f(X), F(X))=L(omega, b)=frac{1}{N} sum_{k=1}^{N}left(omega hat{x}_{k}+b-fleft(hat{x}_{k}right)right)^{2}
D(f(X),F(X))=L(ω,b)=N1k=1∑N(ωx^k+b−f(x^k))2

其中2N是为了计算方便


L0范数是指向量中非零元素的个数;
L1范数是指向量中各个元素的绝对值之和;
L2范数是指向量各元素的平方和然后开方。
第五章
5.1 主成分分析(PCA)

最后
以上就是善良红牛最近收集整理的关于于剑《机器学习》复习总结的全部内容,更多相关于剑《机器学习》复习总结内容请搜索靠谱客的其他文章。








发表评论 取消回复