给定任意的文本文件,统计文件中的文字信息。
#wordstats.py
#包含所有要保留的字符集
keep={'a','b','c','d','e',
'f','g','h','i','j',
'k','l','m','n','o',
'p','q','r','s','t',
'u','v','w','x','y',
'z',' ','-',"'"}
def normalize(s):
"""
将字符串转化成标准字符
"""
result=' '
for c in s.lower():
if c in keep:
result += c
return result
def make_freq_dict(s):
"""
返回每个单词的频率数
"""
s=normalize(s)
words=s.split()
d={}
for w in words:
if w in d: #如果W出现过,就将其出现的次数加1
d[w] += 1
else:
d[w] = 1 #如果w是第一次出现,就将其出现次数设置为1
return d
def print_file_stats(fname):
"""
打印统计信息
"""
s=open(fname,'r').read()
num_chars=len(s) #规范化S之前计算字符数
num_lines=s.count('n') #在规范化s之前计算行数
d=make_freq_dict(s)
num_words=sum(d[w] for w in d) #计算s包含多少单词
#创建一个列表,其中的元素为单词及其出现次数的元组,并根据单词出现的次数由高到低排列
lst=[(d[w],w) for w in d]
lst.sort() #排序
lst.reverse() #反转
#屏幕上打印信息
print("The file '%s' has: "%fname)
print(" %s characters" %num_chars)
print(" %s lines" %num_lines)
print(" %s words" %num_words)
print("nThe top 10 most frequent words are:")
i=1 #循环变量
for count,word in lst[:10]:
print('%2s. %4s %s' %(i,count,word))
i += 1
def main():
print_file_stats('D:\Python3.4\82208.txt')
if __name__ == '__main__':
main()
执行结果:
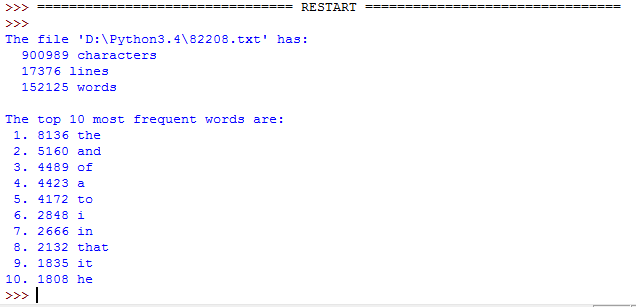
注:读取之前应该确保文件是可读的,并且解除文件的保护属性。否则读取会异常。
参考文献:
Toby Donaldson著,袁国忠译.Python 编程入门(第三版).人民邮电出版社.2013.12
最后
以上就是无私黑夜最近收集整理的关于python文本统计_基于Python的文本统计的全部内容,更多相关python文本统计_基于Python内容请搜索靠谱客的其他文章。








发表评论 取消回复