作为一个学完Python基础知识的测试,暗喜终于可以像RD们自己写脚本处理任何场景吧,如何优雅地写出来代码,接下来开启进阶版的Python。
本期浅谈一下,collection模块关于键值常用的方法,跟着我一起涨知识吧~
1. 问题背景
在LeetCode刷题时候,经常会创建哈希表来辅助存储数据操作,一说哈希表,小白的我一马无脑就打出了一行tmp = {}。如果在高级点的可以写成 tmp = dict()。
直到有一天,遇到1个key存在多个value的问题。那要创建一个value是列表类型的字典,怎么创建呐?(基础太差,知道一对一的)。思考许久删了写写了删,终于使用for循环判断,搞定字典存储key-多个value的值,代码如下:
tmp = {}
students = ["C","A","B","C","D","A","A"]
for index,st in enumerate(students):
if st not in tmp:
tmp[st] = []
tmp[st].append(index)
###
{'C': [0, 3], 'A': [1, 5, 6], 'B': [2], 'D': [4]}
###
复制代码饭后找大佬show code,可想而知被大佬的神通广大的见识,直呼涨知识了!。
在 Python内置库中,其实是有一个collection模块提供defaultdict() 方法来专门处理上述遇到的问题,使用defaultdict()实现如上需求,for循环中只需要一行代码即可
from collections import defaultdict
tmp2 = defaultdict(list)
for index,st in enumerate(students):
tmp2[st].append(index)
##
defaultdict(<class 'list'>, {'C': [0, 3], 'A': [1, 5, 6], 'B': [2], 'D': [4]})
###
复制代码听大佬说collection模块可不止这个,还有很多好玩的。带着疑问,去认识collection模块学习。
2. collections 概述
2.1 什么是collections ?
Python 内置collection模块对普通数据类型(如dict,list,tuple和set)进行扩展和补充。
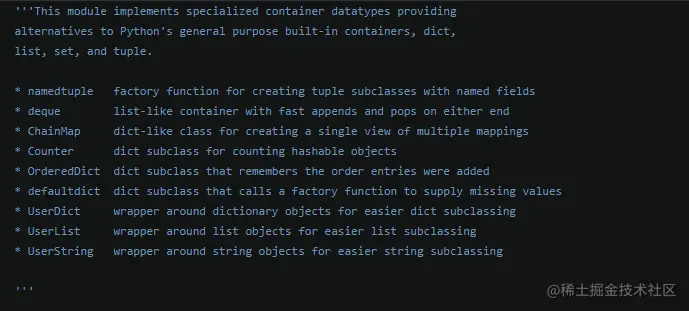
Collection 模块提供9种扩展的数据类型对象,其中对dict字典扩展的就有5个对象(OrderedDict、ChainMap、defaultdict、UserDict、Counter)。
2.2 Collections 内部结构
Collections模块是集中了collections.abc模块和扩展数据类型如UserDict的容器集合模块, Python中内置的dict存在一些限制,不适合一些场景,因此collections模块提供一些扩展方法。
Collections.abc是从adc抽象基类中导出ABCMeta,abstractmethod进行二次封装成一系列关于集合类的接口如关于映射的mapping和mutilmapping抽象基类,用于判断是映射关系抽象类。
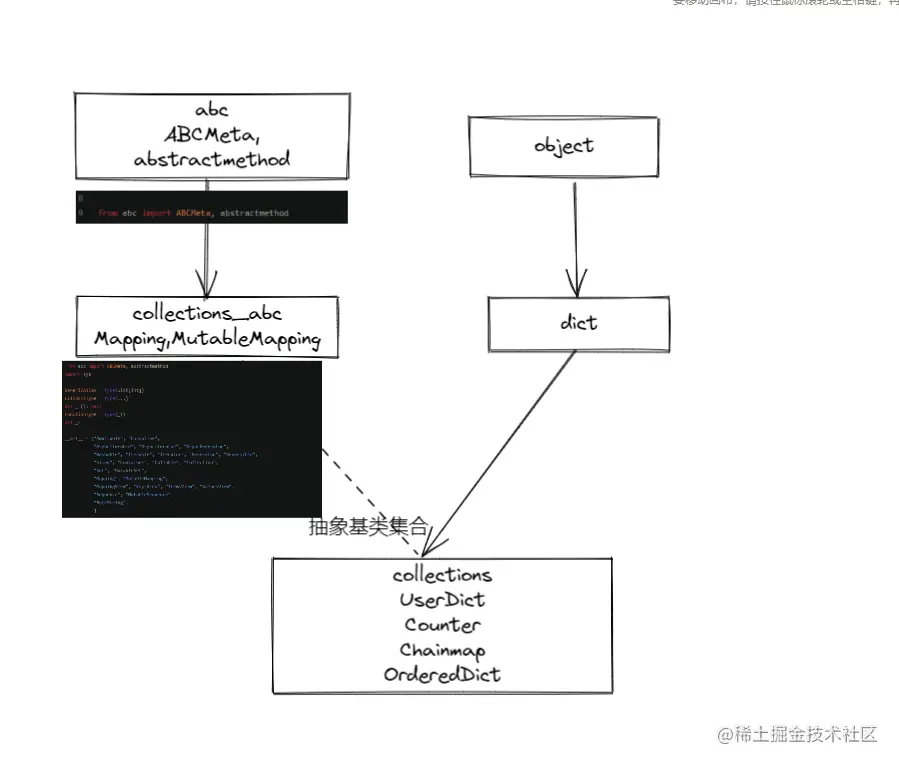
实例化映射方法,一般不会直接继承collections.abc抽象基类的,而是是继承Python内置的dict类对象或者collections.UserDict进行拓展。抽象基类作为一个定义映射关系的基本接口。 同时也可以对isinstance来判断该接口是不是映射类型。
port _collections_abc
tmp = {}
print(isinstance(tmp,collections.abc.Mapping))
###
True
###
复制代码2.3 collections 使用方法
Collections 模块提供多种场景的集合类型,在特定场景下,使用它内部的方法可以提高我们代码的运行效率。 collections 模块文档介绍,已经实现对Python 内置数据类型 list,set,tuple和dict都实现的了拓展。
Collections 模块使用时,需要进行提前导入
from collections import xxxxx
复制代码3. defaultdict 方法
回到第一节问题,当tmp[st]值不存在时,Python内部会抛出异常KeyError。
我们遇到该问题时,总想的可以对tmp[st]赋值为一个默认值default,即tmp.get(st,default)来消除异常情况。
但是当tmp[st]更新某个值时,需要再次不必要的get查询,导致代码低效。
因此collections模块提供针对快速处理的找不键的情况,提供两种方法:
setdefault(),对字典key值赋默认值
- 针对第一节,if判断部分可以直接改写为:
# if st not in tmp:
# tmp[st] = []
# tmp[st].append(index)
#
tmp.setdefault(st,[]).append(index)
复制代码- 虽然提前赋值后,从查询键值次数2到3次,减少一次,但是仍然还要进行插入操作
defaultdict(),对字典进行查找取值
- Defaultdict()实现了专门在读取健值就能获取到一个默认值的方法,是通过继承dict进行定义的一个子类,在子类中__missing__方法处理keyerror异常
- 在第一节中,通过使用defaultdict()来优化,Python内部是怎么运行呢?
-
比如 tmp2 = defaultdict(list) 当 key- value 不存在tmp2时,tmp2[key]会被进行操作:
- 调用list()来建立一个new list,作为default_factory实例属性
- 把new list 作为value,赋值给key键,放在tmp2中 最后返回这个new list的引用
- 需要注意是,当defaultdict每天指定default_factory时,重新不存在的键会触发keyerror
- 然而,专门处理keyerror异常的是__missing__()方法,dict类中没有被定义,当__getitem__找不键时候,Python会自动调用__missing__()方法。
4. Counter 方法
在有些时候,我们需要对列表中元素出现的次数进行统计,按照常规思路,仍然要使用for循环查询更新,代码运行效率大大降低。
在 collections模块中提供了Counter()方法,相等于计数器。
那么,Python内部是怎么运行的呢?
Counter 会给键准备一个整数计数器 每更新一个键的时候都会增加这个计数器
Counter 支持对4种形式的写法:
- 创建空计数器:
tmp = Counter()
- 支持迭代对象如字符串:
tmp = Counter("juejin")
- 支持映射对象如字典:
tmp = Counter({"a":3,"b":4})
- 支持key=value形式:
tmp = Counter(jue=1,jin=2)
Counter对象还支持求出most_common([n])求前n最大的key-value字典等方法
总结
Collections 模块提供对可变序列映射类型高性能方法,OrderedDict、ChainMap和Counter方法可以直接进行调用使用。如果需要重新定义则组需要继承UserDict来实现个性化。
本期,我们只学习了collections模块中关于处理键映射类型的相关方法,后续继续对collections模块关于set、list提供的扩展方法进行学习研究。
以上是本期内容,欢迎大家对上述内容拍砖、点赞,下期见~~
最后
以上就是老实花卷最近收集整理的关于Python 处理键映射值操作1. 问题背景2. collections 概述3. defaultdict 方法4. Counter 方法总结的全部内容,更多相关Python内容请搜索靠谱客的其他文章。








发表评论 取消回复