目录
1. 读取excel文件
2. 写入excel文件
假如有个excel表的数据如下:

1. 读取excel文件
先导包
import pandas as pd读取文件 , shee_name是指定表单
fr = pd.read_excel('data.xlsx',sheet_name='people')data=df.head()#默认读取前5行的数据
data=df.values#获取所有的数据
data = df.columns.values #获取所有的列名
data = df.index.values #获取所有的行号
data=df.iloc[0].values #0表示第一行 这里读取数据并不包含表头,要注意哦!
data = df.iloc[1,2] #读取第一行第二列的值
data=df.loc[[1,2],['sex','city']].values #读取第一行第二行的sex以及city列的值
data=df.loc[:,['sex','city']].values #读所有行的sex以及city列的值
如果Excel文件数据很多,这个时候我们就需要使用循环遍历Excel文件
import pandas as pd
df = pd.read_excel('data.xlsx')
for index, row in df.iterrows():# 这个方法就类似于 for 循环中的enumerate遍历
print(index) # 就会得到每一行的下标值
print(row) # 就会得到每一行的值
sex_value = row['sex'] #就会得到sex这个列的值
city_value = row['city'] #就会得到city这个列的值2. 写入excel文件
通常使用DataFrame 进行写入excel文件,数据可以是numpy 数组,可以是字典,也可以是 DataFrame型字典,类似于{‘A’:[1,2,3]} 这种
pandas使用DataFrame向文件中写,index表示行索引,columns表示列名,随机生成4,4的数向文件中写入。
pd.DataFrame(np.random.random((4,4)),
index=['exp1','exp2','exp3','exp4'],
columns=['jan2015','Fab2015','Mar2015','Apr2005'])
print(frame)
frame.to_excel("data2.xlsx") #写到文件中输出的结果如下:
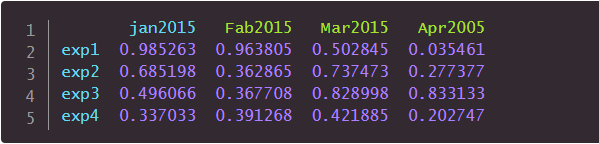
输出的文件如下:
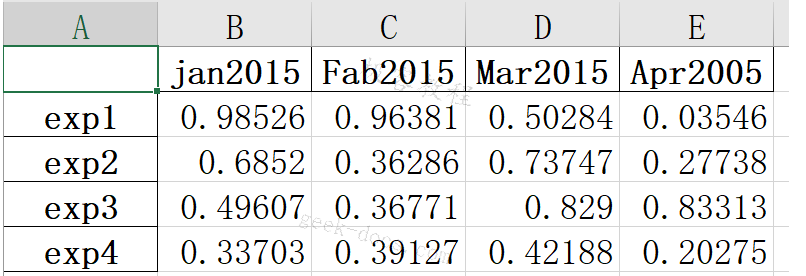
如果不想要行索引,可以设为index=False
fw = pd.DataFrame([2,3])
fw.to_excel('../data/test.xlsx',sheet_name='demo',index=False)
如果是字典的形式存放,键就是列名,值是内容
fw = pd.DataFrame({'A':[2,3]})
fw.to_excel('../data/test.xlsx',sheet_name='demo',index=False)
这就是pandas处理Excel读写的基本操作!
参考:
https://www.cnblogs.com/liulinghua90/p/9935642.html
https://blog.csdn.net/qq_21578125/article/details/81111651?depth_1-utm_source=distribute.pc_relevant.none-task&utm_source=distribute.pc_relevant.none-task
https://blog.csdn.net/brucewong0516/article/details/79097909?depth_1-utm_source=distribute.pc_relevant.none-task&utm_source=distribute.pc_relevant.none-task
最后
以上就是呆萌高跟鞋最近收集整理的关于详细教学 Pandas 对excel 文件读写的基本操作!1. 读取excel文件2. 写入excel文件的全部内容,更多相关详细教学内容请搜索靠谱客的其他文章。








发表评论 取消回复