一、创建策略和价值函数表达式(Policy and Value Function):
1、函数近似器(Function Approximation)

2、Table Representations

① 使用 rlTable创建 value table 或者 Q table ② 用 rlRepresentation为表格创建一个表达式 (representation)③ rlRepresentationOptions配置学习率(learning rate)等参数。
3、Deep Neural Network Representations (可以使用深度学习工具箱)
3.1 Network Input and Output Dimensions
☆ actor 和 critic 网络的维度必须和环境的 observations 和 action 相匹配,获取环境(env)的action和observation的维度,使用 getActionInfo 和 getObservationInfo ,然后访问 dimension 属性。
actInfo = getActionInfo(env);actDimensions = actInfo.Dimensions;obsInfo = getObservationInfo(env);obsDimensions = observationInfo.Dimensions;☆ 对于 AC 或者 PG等只需要 observations 作为输入的 critic network,输入层的维度必须匹配环境观测规范尺寸(environment observation specifications),critic输出层的维度必须是一个标量值函数。
☆ 对于DQN或者DDPG等需要 observations 和 actions作为输入的 critic networks,输入层的维度必须匹配environment observation and action specifications。Critic 输出层的维度也必须是一个标量值函数。
☆ actor networks 输入层的维度必须匹配环境观测规范的维度
①如果 actor 有离散的动作空间,他的输出维度必须等于离散动作的数量。
②如果 actor 有连续的动作空间,它的输出维度必须是一个标量或者向量值,就像 observation specification中定义的那样。
3.2 Build Deep Neural Network
下表列出强化学习常用的深度学习网络层

☆ 注意:lstmLayer,bilstmLayer和 batchNormalizationLayer不支持强化学习。当然也可以自定义网络层。
scalingLayer线性缩放或者偏置输入数组。对于非线性层(tanhLayer 和 sigmoid)输出的缩放和移动(shifting)很有用
quadraticLayer从输入数组的元素构建二次单项式向量。当需要一个输出,它的输入是一些二次函数(例如LQR控制器),这个层会非常有用。
☆ scalingLayer 和 quadraticLayer 自定义层不包含可调参数,在训练过程中不可改变。
☆ 每一个输入路径(input path)通过 connectLayers 函数连接,构成一个深度神经网络。也可以用 Deep Network Designer app创建。对于 observation 和 action 输入路径,必须指定路径的第一个层是 imageInputLayer层。
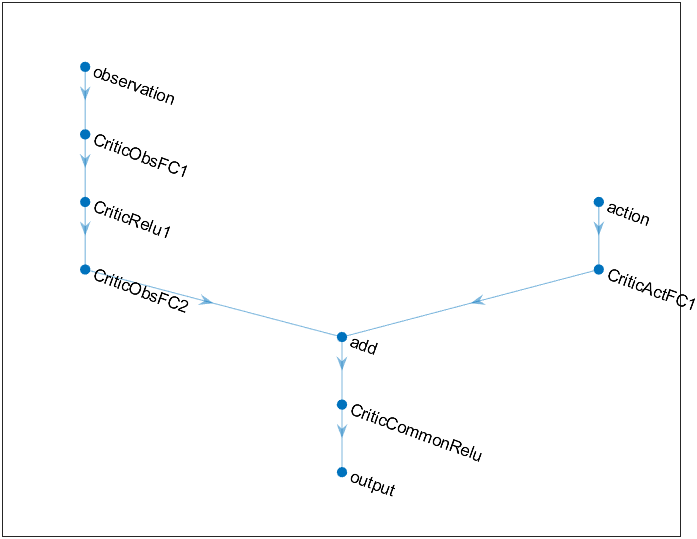
observationPath = [ imageInputLayer([4 1 1],'Normalization','none','Name','observation') fullyConnectedLayer(24,'Name','CriticObsFC1') reluLayer('Name','CriticRelu1') fullyConnectedLayer(24,'Name','CriticObsFC2')];actionPath = [ imageInputLayer([1 1 1],'Normalization','none','Name','action') fullyConnectedLayer(24,'Name','CriticActFC1')];commonPath = [ additionLayer(2,'Name','add') reluLayer('Name','CriticCommonRelu') fullyConnectedLayer(1,'Name','output')];criticNetwork = layerGraph(observationPath);criticNetwork = addLayers(criticNetwork,actionPath);criticNetwork = addLayers(criticNetwork,commonPath);criticNetwork = connectLayers(criticNetwork,'CriticObsFC2','add/in1');criticNetwork = connectLayers(criticNetwork,'CriticObsFC1','add/in2');☆ 通过 plot(criticNetwork) 查看深度神经网络的结构。
☆对于 PG 和 AC 代理,深度神经网络 actor representation 的最终输出层是一个fullyConnectedLayer 和softmaxLayer。必须指定 fullyConnectedLayer ,因为当你省略softmaxLayer时,系统会自动添加一个 softmaxLayer。对于任何函数近似器最重要的是该函数能够逼近最优策略或者折扣价值函数(optimal policy or discounted value function),也就是说能否正确获取 observation,action 和 reward 三个信号的特征(features)。
☆当构建网络的时候必须考虑下面几点:
① 对于连续的动作空间,用 tanhLayer 后面接 ScalingLayer 结构限制动作(bound actions)。
② 带有 reluLayers 的深度密集网络(Deep dense network)能够很好的近似许多不同的函数。因此可以作为构建网络的第一选择。
③ 当逼近强非线性(strong nonlinearities)系统或者带有代数约束(algebraic constraints)的系统,增加更多的层(more layers)往往好于增加每层输出的数量(increase number of outputs per layer)。增加更多的层提高指数搜索能力(exponential exploration),增加每层的输出提高多项式探索能力(polynomial exploration)。
④ 对于 on-policy 代理,例如 AC 和 PG ,如果网络非常大(例如网络具有两个隐藏层,每个隐藏层有32个节点,每个节点有上百个参数)parallel training 训练效率更高。On-policy parallel updates 假设每个 worker 更新网络的不同部分(例如探索 observation space 不同的区域)。如果网络比较小,worker 更新会互相关联,导致训练不稳定。
3.3 Create and Configure Representation
☆ 为深度神经网络创建 actor 或者 critic representation object,使用 rlRepresentation 函数。用 rlRepresentationOptions 配置学习率等参数。

☆ 当创建自己的深度神经网络并且配置 representation object,初始考虑使用下面的方法:
① 最开始采用最小的网络和较大的学习率(0.01)。训练初始网络看一下是否代理很快收敛到很差的策略(poor policy)或者以随机的方式动作。如果出现这些问题,增加层或者增加输出的数量。你的目标是找到一个足够大的网络结构(而不是追求网络学习很快),并且在初步训练后显示学习的迹象(奖励的改进轨迹)
② 初始通过设置小的学习率使得网络训练缓慢。通过慢慢训练,可以检查代理是否在正确的轨迹上,这样可以判断网络结构是否满足问题的要求。对于复杂的问题,优秀的网络结构会使调整参数变得容易。
☆ 当配置深度神经网络时考虑下面的技巧:
① 对 DDPG和DQN要有耐心,因为他们可能在早期阶段一段时间内没有学到任何东西,他们通常在训练过程的早期表现出累积奖励的下降。最终,他们可以在头几千迭代(episode)之后表现出学习的迹象。
② 对于具有 actor 和 critic 网络的代理,设置相同的初始学习率。对于一些问题,将 critic 的学习率设置的大一些可以改善学习效果。
4 Specify Agent Representations
☆ 当创建 actor 和 critic 表达式(representation)以后,可以用这些表达式创建一个强化学习代理。

☆ 可以通过 getActor 和 getCritic 命令获得已有代理的 actor and critic representations。也可以通过 setActor 和 setCritic 设置已存在代理的 actor and critic 。
最后
以上就是高挑白猫最近收集整理的关于matlab显示函数表达式_【Matlab】创建策略和价值函数表达式(Policy and Value Function))...的全部内容,更多相关matlab显示函数表达式_【Matlab】创建策略和价值函数表达式(Policy内容请搜索靠谱客的其他文章。








发表评论 取消回复