这里写目录标题
- 起因
- 配置环境
- 问题探索
- 一、由近及远
- 二、追根溯源
- 三、问题总结
- 本文源码
起因
近日,博主在学习《动手学深度学习》(PyTorch版)时,用fashion_mnist复现LeNet时想知道这个for循环运行了多少次:
代码如下:(在文末会给出整个代码)
for X, y in train_iter:
X = X.to(device)
y = y.to(device)
y_hat = net(X)
l = loss(y_hat, y)
optimizer.zero_grad()
l.backward()
optimizer.step()
train_l_sum += l.cpu().item()
train_acc_sum += (y_hat.argmax(dim=1) == y).sum().cpu().item()
n += y.shape[0]
batch_count += 1
test_acc = evaluate_accuracy(test_iter, net)
这段代码的意思就是从train_iter读取样本X和标签y,但是奇怪的是这个for循环执行次数为235次,但是设置的batch_size 为256。这引起了我的兴趣,这个235的数从何而来,本代码自始至终从未定义过235这个数
通过Debug注意到:
更吊轨的是train_iter长度为40,40 在此代码中也从未出定义过。
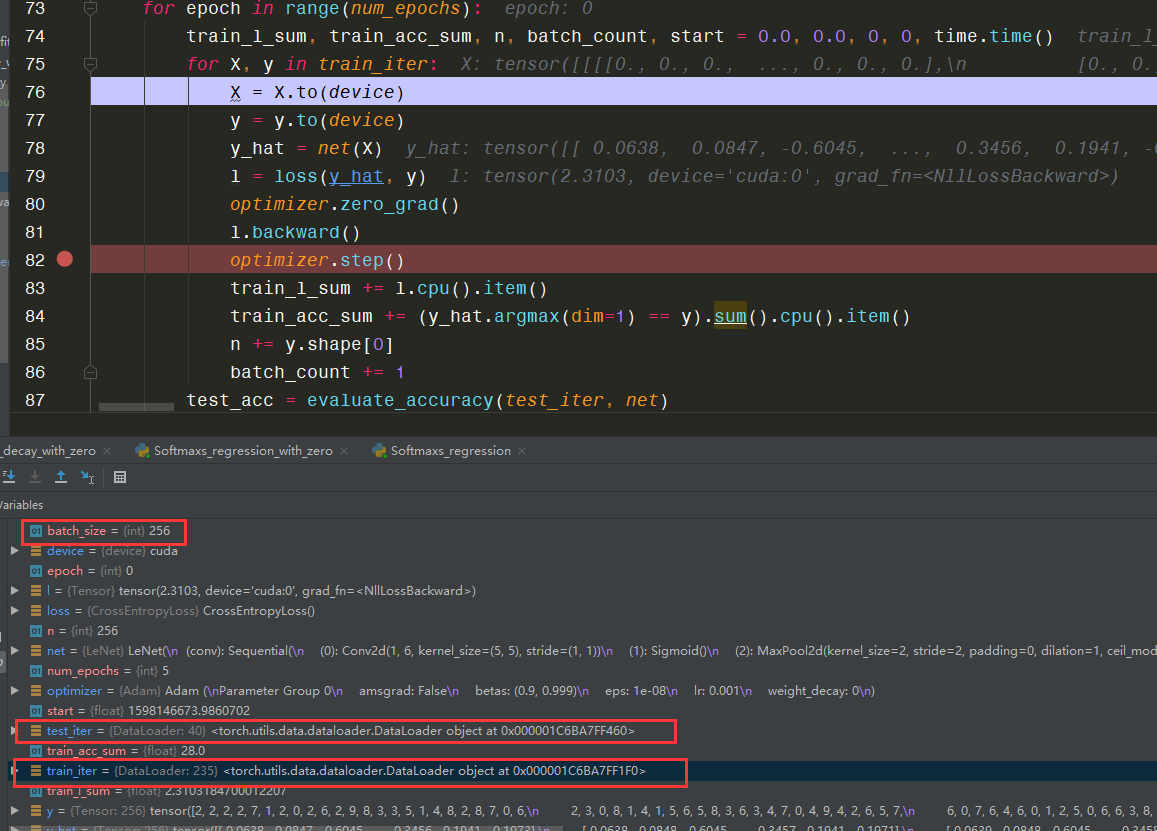
如果你和我有一样的困惑,并感兴趣的话请往下继续观看,这或许会对你理解源代码有所帮助
配置环境
使用环境:python3.8
平台:Windows10
IDE:PyCharm
问题探索
一、由近及远
-
这个疑问发生的地方在函数
def train_ch5(net, train_iter, test_iter, batch_size, optimizer, device, num_epochs):中 -
这个函数传入的数据被用于for循环:
for X, y in train_iter:在于 train_iter变量 -
train_iter是通过函数
train_ch5(net, train_iter, test_iter, batch_size, optimizer, device, num_epochs)传入的 -
即train_ch5函数外部的train_iter将其数据传给了train_ch5函数内部的train_ite
-
train_ch5函数外部的train_iter的由来是通过赋值:
train_iter, test_iter = d2l.load_data_fashion_mnist(batch_size=batch_size)得到的
最终定位到问题关键:d2l.load_data_fashion_mnist(batch_size=batch_size)函数
二、追根溯源
d2l.load_data_fashion_mnist()
的源码如下:
def load_data_fashion_mnist(batch_size, resize=None, root='~/Datasets/FashionMNIST'):
"""Download the fashion mnist dataset and then load into memory."""
trans = []
if resize:
trans.append(torchvision.transforms.Resize(size=resize))
trans.append(torchvision.transforms.ToTensor())
transform = torchvision.transforms.Compose(trans)
mnist_train = torchvision.datasets.FashionMNIST(root=root, train=True, download=True, transform=transform)
mnist_test = torchvision.datasets.FashionMNIST(root=root, train=False, download=True, transform=transform)
if sys.platform.startswith('win'):
num_workers = 0 # 0表示不用额外的进程来加速读取数据
else:
num_workers = 4
train_iter = torch.utils.data.DataLoader(mnist_train, batch_size=batch_size, shuffle=True, num_workers=num_workers)
test_iter = torch.utils.data.DataLoader(mnist_test, batch_size=batch_size, shuffle=False, num_workers=num_workers)
return train_iter, test_iter
可以看到,里面涉及到train_iter数据的内容关键为这三句代码:
transform = torchvision.transforms.Compose(trans)
mnist_train = torchvision.datasets.FashionMNIST(root=root, train=True, download=True, transform=transform)
train_iter = torch.utils.data.DataLoader(mnist_train, batch_size=batch_size, shuffle=True, num_workers=num_workers)
而其中第一句
transform = torchvision.transforms.Compose(trans)
意义再远转换图片格式为张量
第二句为第三句通过支撑,所以关键在于第三句
train_iter = torch.utils.data.DataLoader(mnist_train, batch_size=batch_size, shuffle=True, num_workers=num_workers)
第三句的意思为按照要求(传入参数)加载数据,其实就是老生常谈的DataLoader问题了,DataLoader源码如下(删去了源码中大部分的注释):
class DataLoader(object):
__initialized = False
def __init__(self, dataset, batch_size=1, shuffle=False, sampler=None,
batch_sampler=None, num_workers=0, collate_fn=None,
pin_memory=False, drop_last=False, timeout=0,
worker_init_fn=None, multiprocessing_context=None):
torch._C._log_api_usage_once("python.data_loader")
if num_workers < 0:
raise ValueError('num_workers option should be non-negative; '
'use num_workers=0 to disable multiprocessing.')
if timeout < 0:
raise ValueError('timeout option should be non-negative')
self.dataset = dataset
self.num_workers = num_workers
self.pin_memory = pin_memory
self.timeout = timeout
self.worker_init_fn = worker_init_fn
self.multiprocessing_context = multiprocessing_context
if isinstance(dataset, IterableDataset):
self._dataset_kind = _DatasetKind.Iterable
if shuffle is not False:
raise ValueError(
"DataLoader with IterableDataset: expected unspecified "
"shuffle option, but got shuffle={}".format(shuffle))
elif sampler is not None:
# See NOTE [ Custom Samplers and IterableDataset ]
raise ValueError(
"DataLoader with IterableDataset: expected unspecified "
"sampler option, but got sampler={}".format(sampler))
elif batch_sampler is not None:
# See NOTE [ Custom Samplers and IterableDataset ]
raise ValueError(
"DataLoader with IterableDataset: expected unspecified "
"batch_sampler option, but got batch_sampler={}".format(batch_sampler))
else:
self._dataset_kind = _DatasetKind.Map
if sampler is not None and shuffle:
raise ValueError('sampler option is mutually exclusive with '
'shuffle')
if batch_sampler is not None:
# auto_collation with custom batch_sampler
if batch_size != 1 or shuffle or sampler is not None or drop_last:
raise ValueError('batch_sampler option is mutually exclusive '
'with batch_size, shuffle, sampler, and '
'drop_last')
batch_size = None
drop_last = False
elif batch_size is None:
# no auto_collation
if shuffle or drop_last:
raise ValueError('batch_size=None option disables auto-batching '
'and is mutually exclusive with '
'shuffle, and drop_last')
if sampler is None: # give default samplers
if self._dataset_kind == _DatasetKind.Iterable:
# See NOTE [ Custom Samplers and IterableDataset ]
sampler = _InfiniteConstantSampler()
else: # map-style
if shuffle:
sampler = RandomSampler(dataset)
else:
sampler = SequentialSampler(dataset)
if batch_size is not None and batch_sampler is None:
# auto_collation without custom batch_sampler
batch_sampler = BatchSampler(sampler, batch_size, drop_last)
self.batch_size = batch_size
self.drop_last = drop_last
self.sampler = sampler
self.batch_sampler = batch_sampler
if collate_fn is None:
if self._auto_collation:
collate_fn = _utils.collate.default_collate
else:
collate_fn = _utils.collate.default_convert
self.collate_fn = collate_fn
self.__initialized = True
self._IterableDataset_len_called = None
其中传入参数的意义可以参考这篇博客:传送门
好了继续回到我们的问题
我们来理一下思路:我们找到了torch.utils.data.DataLoader()源代码,通过阅读源代码,我们期望找到该源码返回的train_iter为什么是235的长度
通过Debug进入dataloader.py:发现
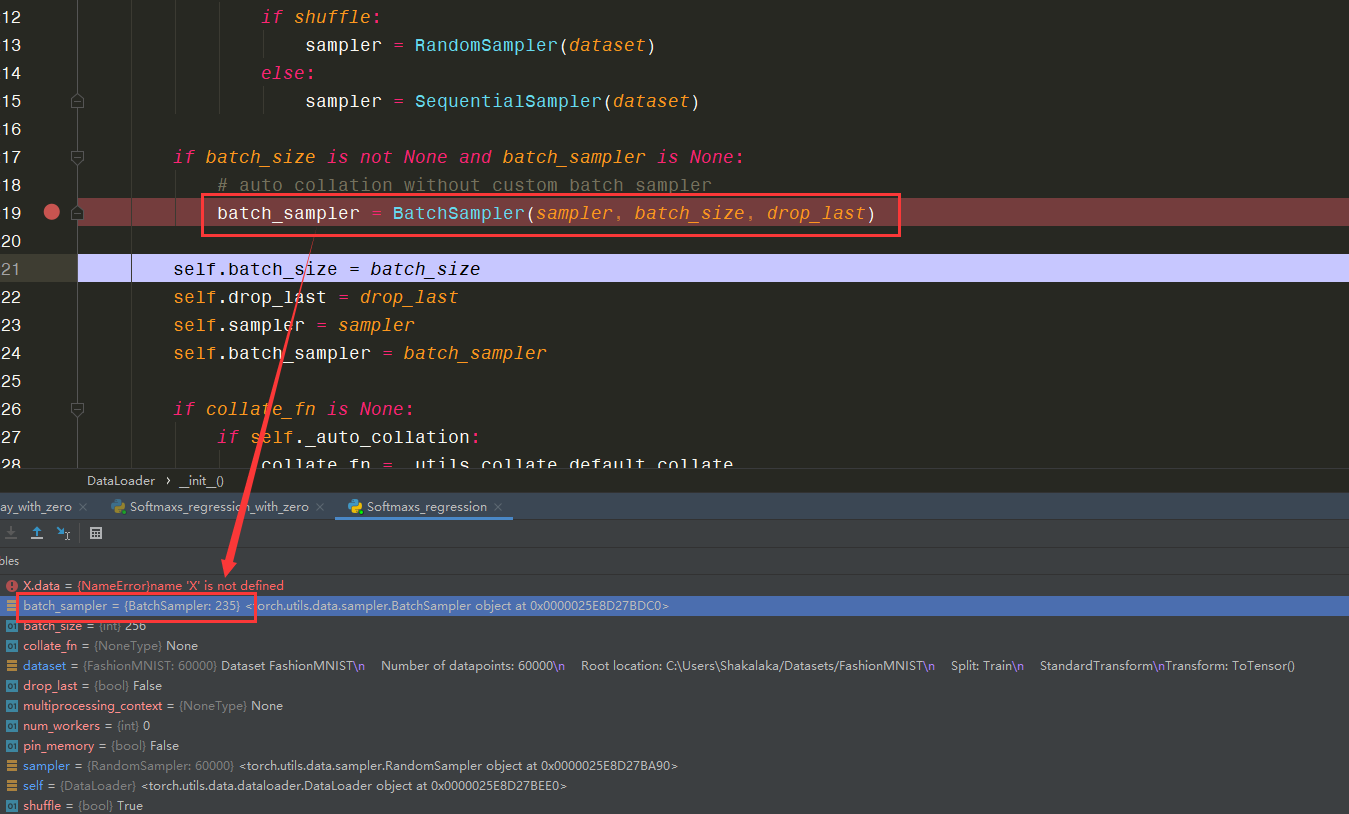
可以看到,235这个数字首先出现在batch_sampler中,那么问题转到了命令
batch_sampler = BatchSampler(sampler, batch_size, drop_last)
即函数BatchSampler(sampler, batch_size, drop_last)
我们理一下这个函数传入的参数意思
- sampler:读取的fashion_mnist训练数据集,长度为60000
- batch_size:小批量的大小,设定值为256
- drop_last:一个为False的bool型
好了,我们继续对BatchSampler()进行Debug,进入sampler.py发现BatchSampler()函数相对简单,其源码(同样的,删去了部分注释)如下:
class BatchSampler(Sampler)
def __init__(self, sampler, batch_size, drop_last):
if not isinstance(sampler, Sampler):
raise ValueError("sampler should be an instance of "
"torch.utils.data.Sampler, but got sampler={}"
.format(sampler))
if not isinstance(batch_size, _int_classes) or isinstance(batch_size, bool) or
batch_size <= 0:
raise ValueError("batch_size should be a positive integer value, "
"but got batch_size={}".format(batch_size))
if not isinstance(drop_last, bool):
raise ValueError("drop_last should be a boolean value, but got "
"drop_last={}".format(drop_last))
self.sampler = sampler
self.batch_size = batch_size
self.drop_last = drop_last
# print("**")
def __iter__(self):
batch = []
for idx in self.sampler:
batch.append(idx)
if len(batch) == self.batch_size:
yield batch
batch = []
if len(batch) > 0 and not self.drop_last:
yield batch
def __len__(self):
if self.drop_last:
return len(self.sampler) // self.batch_size
else:
return (len(self.sampler) + self.batch_size - 1) // self.batch_size
在Debug中会发现,BatchSampler()源码真正执行的部分就只有这一块儿:
def __init__(self, sampler, batch_size, drop_last):
if not isinstance(sampler, Sampler):
raise ValueError("sampler should be an instance of "
"torch.utils.data.Sampler, but got sampler={}"
.format(sampler))
if not isinstance(batch_size, _int_classes) or isinstance(batch_size, bool) or
batch_size <= 0:
raise ValueError("batch_size should be a positive integer value, "
"but got batch_size={}".format(batch_size))
if not isinstance(drop_last, bool):
raise ValueError("drop_last should be a boolean value, but got "
"drop_last={}".format(drop_last))
self.sampler = sampler
self.batch_size = batch_size
self.drop_last = drop_last
# print("**")
在Debug的时候会解开print("**")的注释,来查看运行进程
运行完上面一段后最后一句print("**")就会跳出BatchSampler()
但是上面打码中根本没有return回去任何东西,真是让人头大的情况
及时将下面的
def __iter__(self):
和
def __len__(self):
代码打上断点也直接跳出BatchSampler()
为了解决上面的 问题,查看
def __iter__(self):
和
def __len__(self):
将这段代码:到底有没有运行,在二者下第一节加上一个print函数,具体如下:
def __iter__(self):
print("***")
batch = []
for idx in self.sampler:
batch.append(idx)
if len(batch) == self.batch_size:
yield batch
batch = []
if len(batch) > 0 and not self.drop_last:
yield batch
def __len__(self):
print("****")
if self.drop_last:
return len(self.sampler) // self.batch_size
else:
return (len(self.sampler) + self.batch_size - 1) // self.batch_size
再运行代码,发现在Console打印出如下:
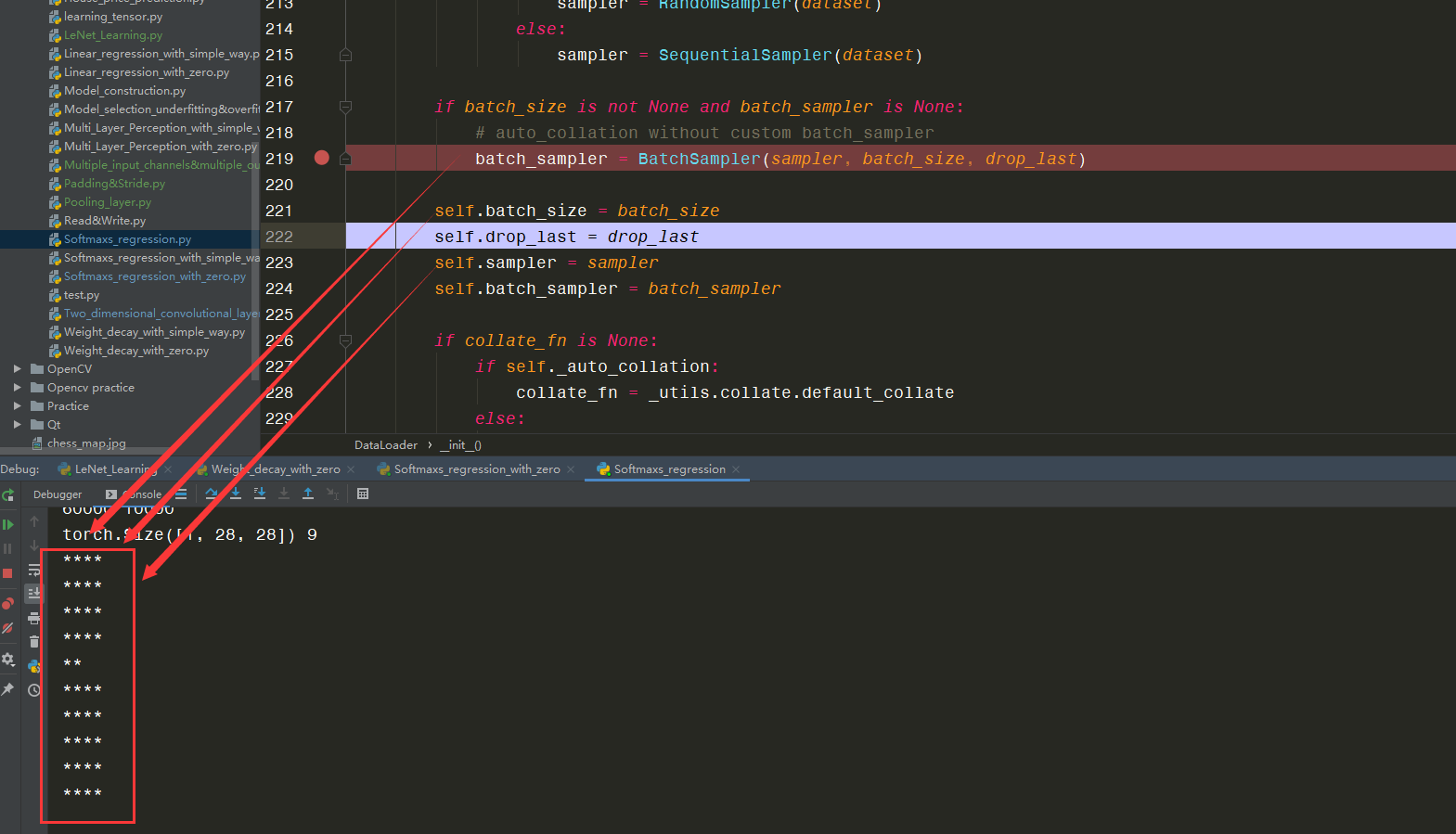
可以知道:BatchSampler()源码中运行了:
def __len__(self):
下的代码,即:
def __len__(self):
print("****")
if self.drop_last:
return len(self.sampler) // self.batch_size
else:
return (len(self.sampler) + self.batch_size - 1) // self.batch_size
我们来细细看一下这个函数下面的流程:
当self.drop_last为true时,返回len(self.sampler) // self.batch_size
当self.drop_last为false时,返回(len(self.sampler) + self.batch_size - 1) // self.batch_size
在Debug时可以发现:
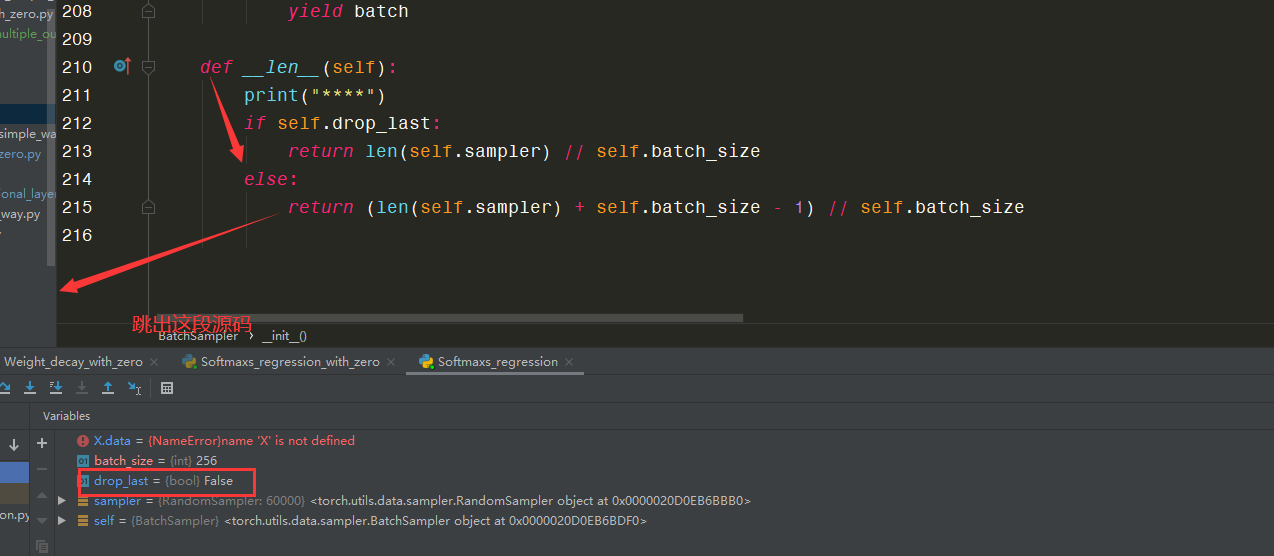
self.drop_last为false,所以返回的是:
self.sampler的长度+self.batch_size再减去1最后整除self.batch_size
以本案以为例:
(60000+256-1)//256 = 235
哇哦!我们终于得到了235的来源了
好了,到这里我们就探清了235的来源;
同理,我们的test_iter为40的来源便是:
(10000+256-1)//256 = 40
有必要解释一下,为什么test_iter相较于train_iter从60000变成了10000
因为fashion_mnist数据集中训练集的长度为60000,测试集长度为10000
三、问题总结
我们的初衷是为了知道循环次数,知道循环次数的目的在于知道循环的原理,为什么要这样循环,这样循环的好处在于哪儿?
我们回到本文最开始的for循环(将其上面的迭代此处循环也加上)中:
for epoch in range(num_epochs):
train_l_sum, train_acc_sum, n, batch_count, start = 0.0, 0.0, 0, 0, time.time()
for X, y in train_iter:
X = X.to(device)
y = y.to(device)
y_hat = net(X)
l = loss(y_hat, y)
optimizer.zero_grad()
l.backward()
optimizer.step()
train_l_sum += l.cpu().item()
train_acc_sum += (y_hat.argmax(dim=1) == y).sum().cpu().item()
n += y.shape[0]
batch_count += 1
test_acc = evaluate_accuracy(test_iter, net)
print('epoch %d, loss %.4f, train acc %.3f, test acc %.3f, time %.1f sec'
% (epoch + 1, train_l_sum / batch_count, train_acc_sum / n, test_acc, time.time() - start))
面对这中循环,在训练网络中随处可见,不禁思考:这个循环的意义何在?
- 首先进入循环着,
epoch为循环迭代次数,第一次迭代epoch为0 - 在这个迭代中首先将误差项(
train_l_sum, train_acc_sum, n, batch_count)设为0 - 然后进入对数据处理的循环中,从训练集
train_iter中读取样本数据X和真实标签y,每次读入个数为256个,一共读取235次
- 随后进行向前传递
y_hat = net(X) - 再计算损失函数
l = loss(y_hat, y) - 再反向传播,采用优化算法进行对参数进行修正,以得到最优的网络参数
- 并且每次迭代中会计算偏差值,以得到每次循环之后的正确率
本文源码
# 本书链接https://tangshusen.me/Dive-into-DL-PyTorch/#/chapter03_DL-basics/3.8_mlp
# 5.5 卷积神经网络(LeNet)
#注释:黄文俊
#邮箱:hurri_cane@qq.com
import time
import torch
from torch import nn, optim
import sys
sys.path.append("..")
import d2lzh_pytorch as d2l
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
class LeNet(nn.Module):
def __init__(self):
super(LeNet, self).__init__()
# 卷积层块
self.conv = nn.Sequential(
nn.Conv2d(1, 6, 5), # in_channels, out_channels, kernel_size
nn.Sigmoid(),
nn.MaxPool2d(2, 2), # kernel_size, stride
nn.Conv2d(6, 16, 5),
nn.Sigmoid(),
nn.MaxPool2d(2, 2)
)
# 全连接层块
self.fc = nn.Sequential(
nn.Linear(16*4*4, 120),
nn.Sigmoid(),
nn.Linear(120, 84),
nn.Sigmoid(),
nn.Linear(84, 10)
)
def forward(self, img):
feature = self.conv(img)
output = self.fc(feature.view(img.shape[0], -1))
return output
net = LeNet()
print(net)
# 本函数已保存在d2lzh_pytorch包中方便以后使用。该函数将被逐步改进。
def evaluate_accuracy(data_iter, net, device=None):
if device is None and isinstance(net, torch.nn.Module):
# 如果没指定device就使用net的device
device = list(net.parameters())[0].device
acc_sum, n = 0.0, 0
with torch.no_grad():
for X, y in data_iter:
if isinstance(net, torch.nn.Module):
net.eval() # 评估模式, 这会关闭dropout
acc_sum += (net(X.to(device)).argmax(dim=1) == y.to(device)).float().sum().cpu().item()
net.train() # 改回训练模式
else: # 自定义的模型, 3.13节之后不会用到, 不考虑GPU
if('is_training' in net.__code__.co_varnames): # 如果有is_training这个参数
# 将is_training设置成False
acc_sum += (net(X, is_training=False).argmax(dim=1) == y).float().sum().item()
else:
acc_sum += (net(X).argmax(dim=1) == y).float().sum().item()
n += y.shape[0]
return acc_sum / n
# 本函数已保存在d2lzh_pytorch包中方便以后使用
def train_ch5(net, train_iter, test_iter, batch_size, optimizer, device, num_epochs):
net = net.to(device)
print("training on ", device)
loss = torch.nn.CrossEntropyLoss()
for epoch in range(num_epochs):
train_l_sum, train_acc_sum, n, batch_count, start = 0.0, 0.0, 0, 0, time.time()
for X, y in train_iter:
X = X.to(device)
y = y.to(device)
y_hat = net(X)
l = loss(y_hat, y)
optimizer.zero_grad()
l.backward()
optimizer.step()
train_l_sum += l.cpu().item()
train_acc_sum += (y_hat.argmax(dim=1) == y).sum().cpu().item()
n += y.shape[0]
batch_count += 1
test_acc = evaluate_accuracy(test_iter, net)
print('epoch %d, loss %.4f, train acc %.3f, test acc %.3f, time %.1f sec'
% (epoch + 1, train_l_sum / batch_count, train_acc_sum / n, test_acc, time.time() - start))
# 下面我们来实验LeNet模型。实验中,我们仍然使用Fashion-MNIST作为训练数据集。
batch_size = 256
train_iter, test_iter = d2l.load_data_fashion_mnist(batch_size=batch_size)
lr, num_epochs = 0.001, 5
optimizer = torch.optim.Adam(net.parameters(), lr=lr)
train_ch5(net, train_iter, test_iter, batch_size, optimizer, device, num_epochs)
print("*"*50)
最后
以上就是畅快自行车最近收集整理的关于深度学习中训练迭代次数理解【源码阅读技巧分享】【深度学习循环迭代理解】【for X, y in train_iter:】起因配置环境问题探索本文源码的全部内容,更多相关深度学习中训练迭代次数理解【源码阅读技巧分享】【深度学习循环迭代理解】【for内容请搜索靠谱客的其他文章。








发表评论 取消回复