欢迎star 该 github, IoT 服务器架构与设计 Blog????(后续该文章的优化修改只会在Github改)
本文来分析:【前端或Postman通过rpc API(http)控制mqtt设备】在分布式集群下的架构与流程
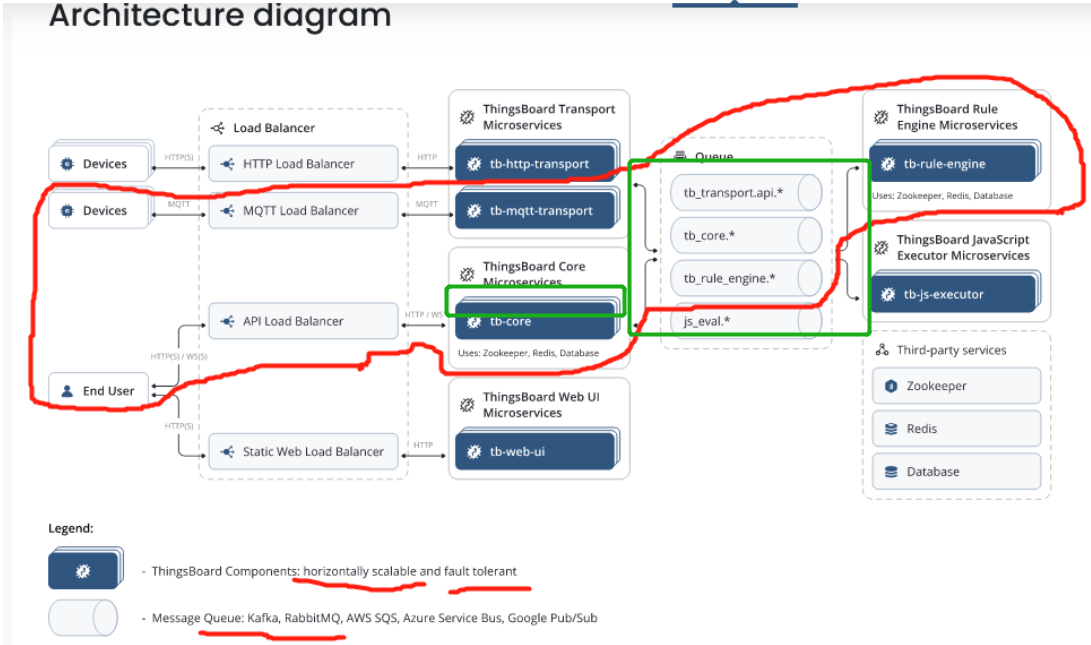
下图是官网的微服务架构图
问题:一般普通(没长连接+发布订阅)、理想而标准的微服务,应该设计为无状态(stateless)的且服务间单向调用。无状态就比如一个服务(后面用service表示,如图中的tb-core服务)的集群(cluster)由2个节点(后面用node表示)组成,那么每次请求一个service时,应该可以路由到service下的任意一个node去处理(不同node都应是一样的处理结果)。但thingsboard其实并不是一个stateless的微服务,也非单向rpc调用,从该图看不出数据在service间是怎么传递的。网络上也找不到有分析该过程的文章(如有请留言发给我),为此我画了下面的图去分析。
【前端或Postman通过rpc API(http)控制mqtt设备】分布式流程
下图的3个service和上图红线中的3个service对应,但细致到了node与node间通讯的topic与路径,后面针对该图进行分析
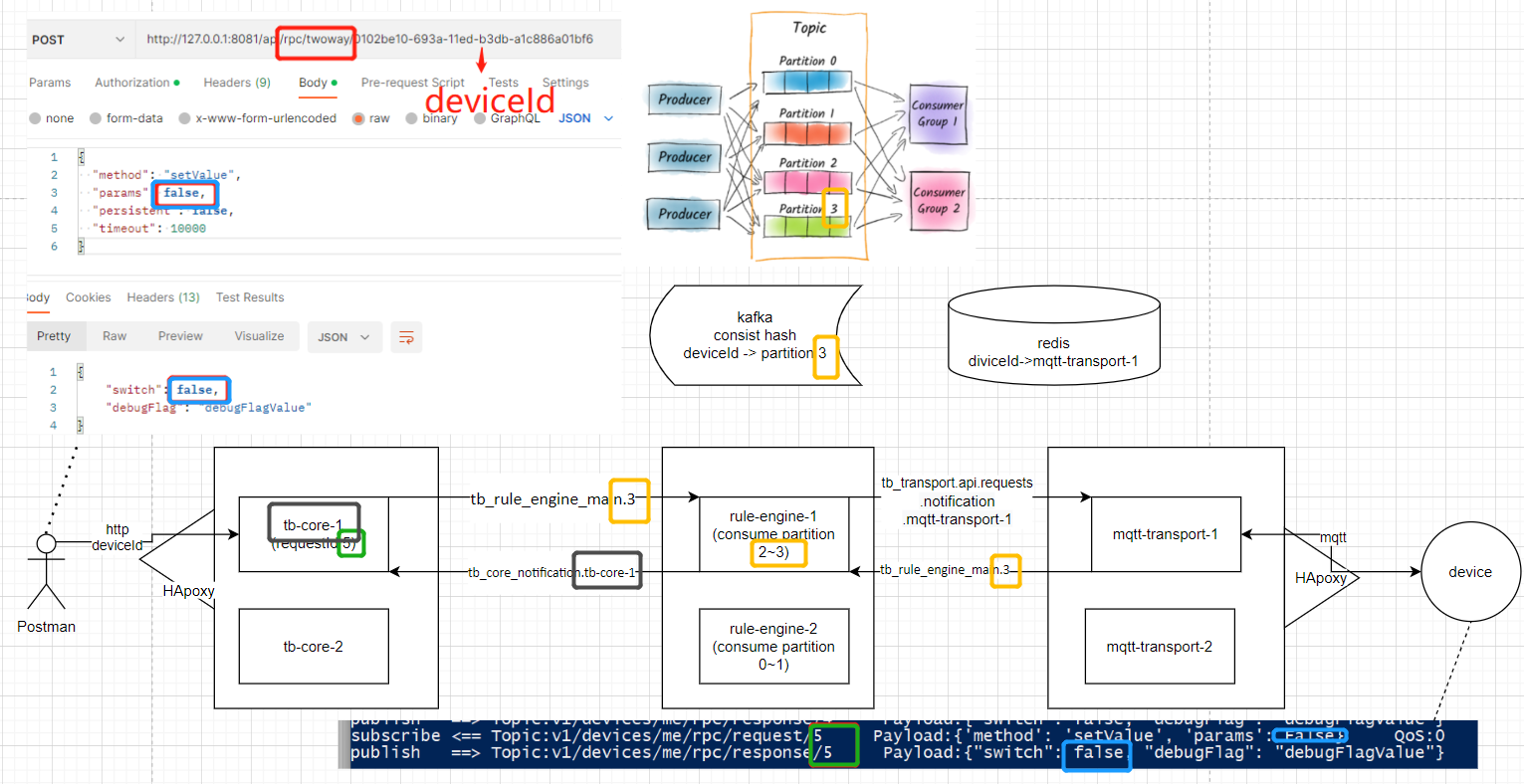
(图左边的topic是自己100%抓到的,右边的topic并没有完全debug,所以不敢100%确定,右边如有哪部分不对,请详细说明下流程给我):
1,右边的设备通过mqtt协议连接mqtt-transport服务,被LB(load balancer)随机分配到了mqtt-transport-1的node,并把该deviceId在哪个node的映射关系保存到了redis
2,左边的postman通过http协议,被LB随机分配到了tb-core-1的node,为该次请求生成一个requestId, 然后通过对deviceId进行hash % partition的数量4,计算得到该deviceId的partition是3,所以把控制数据发到了tb_rule_engine_main的第3个partition
3,rule-engine-1根据deviceId从redis查到该设备连接在mqtt-transport-1节点,将消息发给tb_transport.api.requests.notification.mqtt-transport-1的节点(注意,该topic没有partition,notification的topic就是每个node单独订阅自己的消息)
4,设备收到requestId 5的控制,响应控制成果,也带有requestId 5
5,mqtt-transport-1通过deviceId的一致性hash,该消息被rule-engine-1的node消费
6,rule-engine-1通过notification的topic把消息发给tb-core-1
7,tb-core-1通过deviceId和requestId,将http进行响应(kafka是异步,http是同步,此处异步转同步的代码实现其他文章分享)
重点1:HAproxy(和nginx一样)做负载均衡, 随机分配节点
使用了最小连接数的负载均衡策略,即HAproxy会把新的request分配给当前连接数最小的node。
左边postman每次http请求,都可能分配到和上次不同的node处理
右边设备device每次mqtt进行连接connect,都可能分配到和上次不同的node处理,但因为mqtt是长连接(用netty管理),connect后每次publish消息,都是同一个node在处理。但如果将该连接disconnect再connect,就可能分配到不同的node去处理。
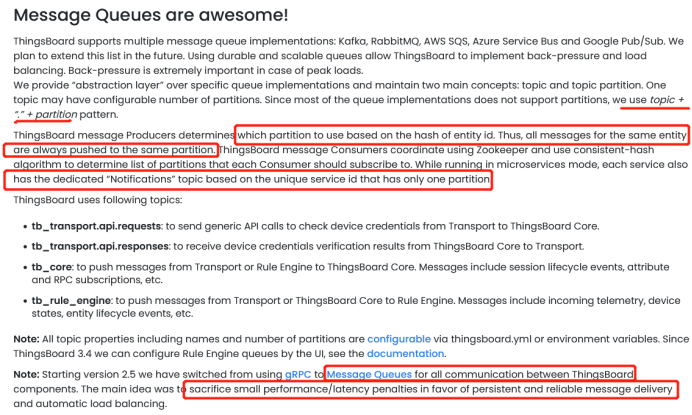
重点2:thingsboard后台节点之间通讯全是用的kafka。
kafka的基础理解:
1,一个topic有多个partition
2,一个消息只会被consumer group中的一个consumer消费
3,一个partition只会被一个consumer消费
重点3:一致性hash算法的应用,保证一个device的数据分配到同一个节点
作用:保证同一个设备的数据只会在一个node上处理
应用在何处:图中间的rule-engine
为什么要保证同一个设备的数据都在一个node处理:rule-engine是有状态的服务,同时用了actor模式,每一个device就是一个deviceActor对象,比如如图,只有rule-engine-1知道requestId为5的请求的原始请求node是tb-core-1从而完成response的业务,rule-engine-2并不知道(该信息应该是保存在内存中的,还没从源码100%确定);这样一个设备的数据只保存在一个node中,也防止了内存爆炸,其实mqtt-transport服务也一样,如果有10万netty管理的mqtt长连接,那5万在node1,5万在node2。
重点4:异步转同步的代码实现
kafka是异步,http是同步,此处异步转同步的代码实现其他文章分享
下图是官网对于消息队列queue(kafka)的文档说明(不想看可忽略)
增加节点后,如何re-hash?是否有一定时间的不可用?
https://stackoverflow.com/questions/74650502/for-microservice-how-to-add-nodes-for-kafka-and-tb-rule-engine-at-runtime-will
关于增加节点的操作与影响,官方文档并无说明,我提了个case,被thingsboard的架构师回答了,算是可靠答案了。
1,节点发生增删时,其他节点都会通过zookeeper得到通知,进行re-hash,所以partition或service的node数量在各node会得到更新
2,增加一个rule-engine节点,因为一部分partition会移到新的node上,而此时旧的node可能还没commit,可能就会出现一个消息被消费了2次。而因为旧的node会停止消费部分partition,新的node会开始消费,这中间可能会有短暂的处理速度的下降。
一个节点挂了后会怎样
比如mqtt-transport-1的node挂了,设备端的连接就断了,需要设备端有重连机制(为了防止大量设备断开服务器,同时向服务器进行connect,瞬时高峰可能会把其他node请求挂了形成雪崩效应,设备端应该有指数退避+随机数的设计,即5秒连不上服务器,下次10秒连接,不能连接失败就立刻重连)。
所以挂了对当前的连接和消息可能会有些影响的,但一般对业务影响不大,另外内部服务间有kafka的commit确认机制与重试机制,这些措施可以保证不会丢数据。
其他架构方案思考
在http和mqtt接入的node也可以使用一致性hash的设计,使同一deviceId的数据在同一节点处理,也就是client连接到任意一个node,该node计算hash后,如果不在该node自己,再将该设备的连接重定向到其一致性hash应该连接到node上。
大家都有什么想法或想讨论的,欢迎最下方点击留言!
部分重要定位日志截图:
1,一致性hash代码,根据deviceId算出hash再除以分区partition数量
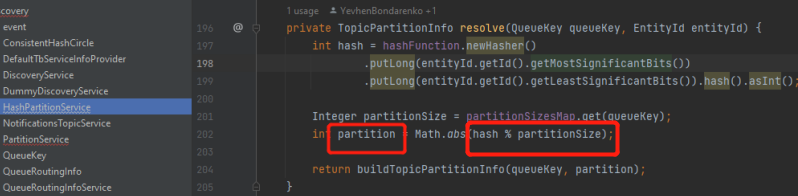
2,redis中device的session保存了该设备连接到了哪个node(因为用了非明文的protobuf,第二张图是proto骨架文件,所以看到的大部分是乱码)
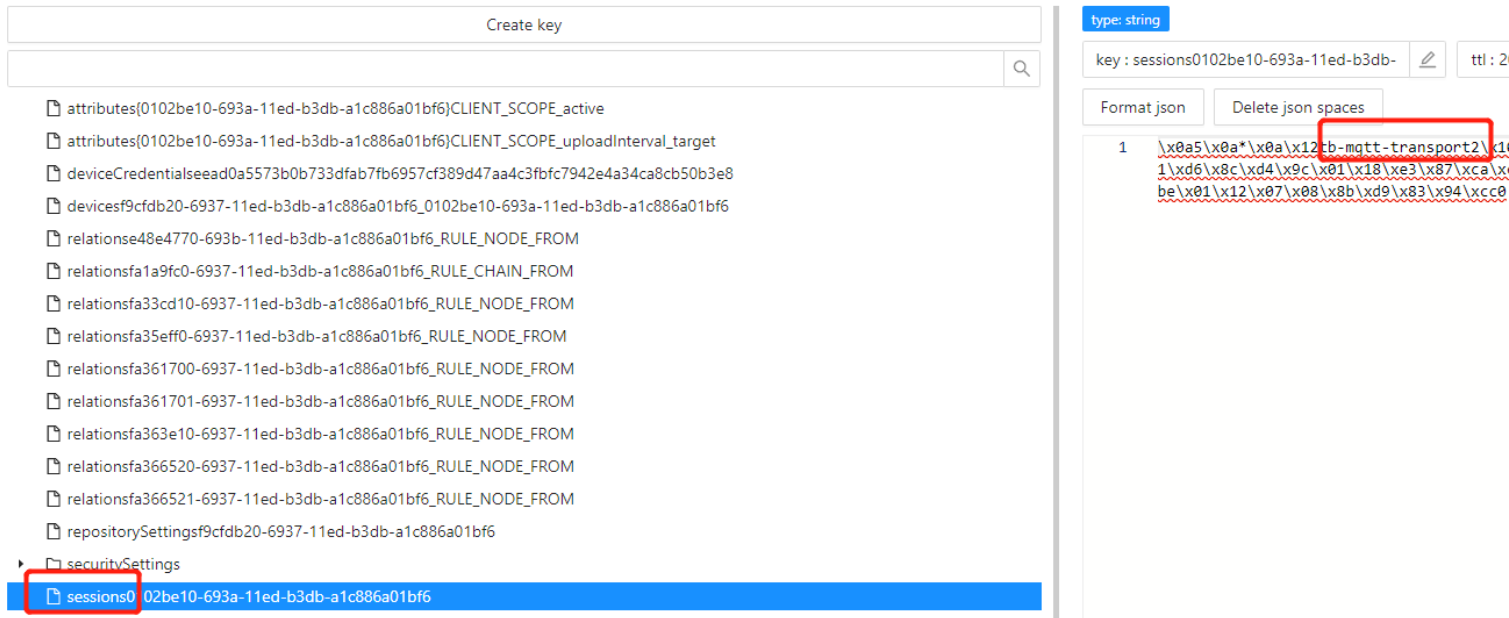
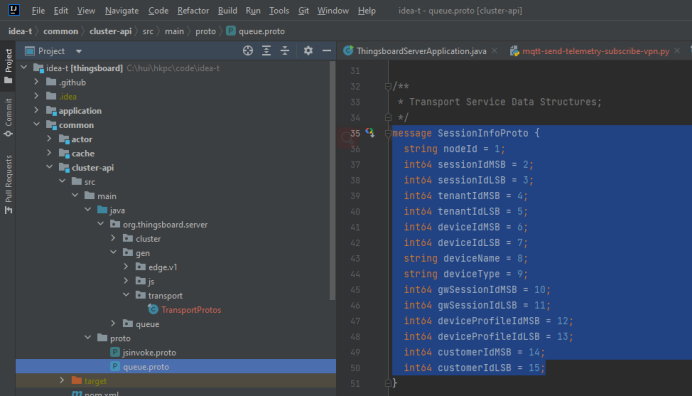
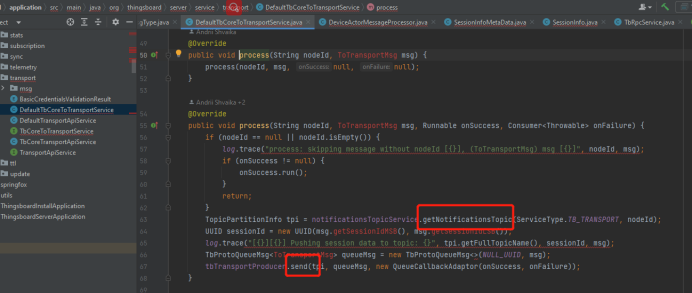
3,将节点通过notification的topic,发给指定的node
该文章的留言讨论区,欢迎留言相互讨论
最后
以上就是沉默滑板最近收集整理的关于IoT Thingsboard 微服务分布式 mqtt设备控制 架构与可用性分析【前端或Postman通过rpc API(http)控制mqtt设备】分布式流程增加节点后,如何re-hash?是否有一定时间的不可用?一个节点挂了后会怎样其他架构方案思考该文章的留言讨论区,欢迎留言相互讨论的全部内容,更多相关IoT内容请搜索靠谱客的其他文章。








发表评论 取消回复