1. ZooKeeper基本知识
1.1 概述
Zookeeper是一个分布式协调服务的开源框架。主要用来解决分布式集群中应用系统的一致性问题。ZooKeeper本质上是一个分布式的小文件存储系统。
1.2 特性
1.全局数据一致:集群中每个服务器保存一份相同的数据副本,client无论连接到哪个服务器,展示的数据都是一致的,这是最重要的特征;
2.可靠性:如果消息被其中一台服务器接受,那么将被所有的服务器接受。
3.顺序性:包括全局有序和偏序两种:全局有序是指如果在一台服务器上消息a在消息b前发布,则在所有Server上消息a都将在消息b前被发布;偏序是指如果一个消息b在消息a后被同一个发送者发布,a必将排在b前面。
4.数据更新原子性:一次数据更新要么成功(半数以上节点成功),要么失败,不存在中间状态;
5.实时性:Zookeeper保证客户端将在一个时间间隔范围内获得服务器的更新信息,或者服务器失效的信息。
1.3 角色
Leader: Zookeeper集群工作的核心
Follower:处理客户端非事务(读操作)请求,转发事务请求给Leader;参与集群Leader选举投票。
Observer:观察者角色,观察Zookeeper集群的最新状态变化并将这些状态同步过来,其对于非事务请求可以进行独立处理,对于事务请求,则会转发给Leader服务器进行处理。
2. ZooKeeper数据模型
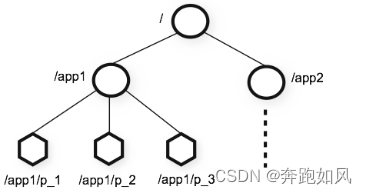
图中的每个节点称为一个Znode。 每个Znode由3部分组成:
ZooKeeper的数据模型,在结构上和标准文件系统的非常相似,拥有一个层次的命名空间,都是采用树形层次结构,ZooKeeper树中的每个节点被称为—Znode。和文件系统的目录树一样,ZooKeeper树中的每个节点可以拥有子节点。但也有不同之处:
1.Znode兼具文件和目录两种特点,既像文件一样维护着数据、元信息、ACL、时间戳等数据结构,又像目录一样可以作为路径标识的一部分,并可以具有子Znode。用户对Znode具有增、删、改、查等操作(权限允许的情况下)。
2.Znode具有原子性操作,读操作将获取与节点相关的所有数据,写操作也将替换掉节点的所有数据。另外,每一个节点都拥有自己的ACL(访问控制列表),这个列表规定了用户的权限,即限定了特定用户对目标节点可以执行的操作。
3.Znode存储数据大小有限制,ZooKeeper虽然可以关联一些数据,但并没有被设计为常规的数据库或者大数据存储,相反的是,它用来管理调度数据,比如分布式应用中的配置文件信息、状态信息、汇集位置等等。这些数据的共同特性就是它们都是很小的数据,通常以KB为大小单位。ZooKeeper的服务器和客户端都被设计为严格检查并限制每个Znode的数据大小至多1M,当时常规使用中应该远小于此值。
4.Znode通过路径引用,如同Unix中的文件路径。路径必须是绝对的,因此他们必须由斜杠字符来开头。除此以外,他们必须是唯一的,也就是说每一个路径只有一个表示,因此这些路径不能改变。在ZooKeeper中,路径由Unicode字符串组成,并且有一些限制。字符串"/zookeeper"用以保存管理信息,比如关键配额信息。
① stat:此为状态信息, 描述该Znode的版本, 权限等信息
② data:与该Znode关联的数据
③ children:该Znode下的子节点
3.Zookeeper节点类型
Znode有两种,分别为临时节点和永久节点。节点的类型在创建时即被确定,并且不能改变。
临时节点:该节点的生命周期依赖于创建它们的会话。一旦会话结束,临时节点将被自动删除,当然可以也可以手动删除。临时节点不允许拥有子节点。
永久节点:该节点的生命周期不依赖于会话,并且只有在客户端显示执行删除操作的时候,他们才能被删除。
Znode还有一个序列化的特性,如果创建的时候指定的话,该Znode的名字后面会自动追加一个不断增加的序列号。序列号对于此节点的父节点来说是唯一的,这样便会记录每个子节点创建的先后顺序。它的格式为“%10d”(10位数字,没有数值的数位用0补充,例如“0000000001”)。
这样便会存在四种类型的Znode节点,分别对应:
PERSISTENT:永久节点
EPHEMERAL:临时节点
PERSISTENT_SEQUENTIAL:永久节点、序列化
EPHEMERAL_SEQUENTIAL:临时节点、序列化
最后
以上就是怕黑奇迹最近收集整理的关于ZooKeeper基础学习【博学谷学习记录】的全部内容,更多相关ZooKeeper基础学习【博学谷学习记录】内容请搜索靠谱客的其他文章。








发表评论 取消回复